機器人影視對接
A simple question like ‘How do you find a compatible partner?’ is what pushed me to try to do this project in order to find a compatible partner for any person in a population, and the motive behind this blog post is to explain my approach towards this problem in a manner as clear as possible.
一個簡單的問題,例如“如何找到兼容的合作伙伴?” 是促使我嘗試執行此項目的原因,以便為人群中的任何人找到兼容的合作伙伴,而本博客文章的動機是,以盡可能清晰的方式解釋我對這一問題的解決方法。
You can find the project notebook here.
您可以在 此處 找到項目筆記本 。
If I asked you to find a partner, what would be your next step? And what if I had asked you to find a compatible partner? Would that change things?
如果我要您找到合作伙伴,下一步將是什么? 如果我要您找到兼容的合作伙伴怎么辦? 這會改變一切嗎?
A simple word such as compatible can make things tough, because apparently humans are complex.
諸如兼容之類的簡單詞會使事情變得艱難,因為顯然人類是復雜的。
數據 (The Data)
Since we couldn’t find any single dataset that could cover the variation in persona, we resorted to using the Big5 personality dataset, Interests dataset (also known as Young-People-Survey dataset) and Baby-Names dataset.
由于找不到任何可以覆蓋角色差異的數據集,因此我們訴諸使用Big5人格數據集 , 興趣數據集 (也稱為Young-People-Survey數據集)和Baby-Names數據集 。
Big5 personality dataset: The reason we are choosing Big5 dataset is solely because it provides an idea about any individual’s personality through the Big5/OCEAN personality test which asks a respondent 50 questions, 10 questions each for Openness, Conscientiousness, Extraversion, Agreeableness & Neuroticism to measure them on a scale of 1–5. You can read more about Big5 here.
Big5人格數據集 :我們之所以選擇Big5數據集,完全是因為它通過Big5 / OCEAN人格測驗提供了有關任何人的性格觀念,該測驗向被訪者詢問50個問題,每個問題中有10個問題涉及開放性,盡責性,性格外向,愉快和神經質。用1–5的比例尺測量它們。 您可以在此處閱讀有關Big5的更多信息。
Interests dataset: which covers the interests & hobbies of a person by asking them to rate 50 different areas of interest (such as art, reading, politics, sports etc.) on a scale of 1-5.
興趣數據集:涵蓋一個人的興趣和愛好 ,要求他們以1-5的等級對50個不同的興趣領域(例如藝術,閱讀,政治,體育等)進行評分。
Baby-Names dataset: helps in assigning a real and unique name to each respondent
嬰兒名字數據集:有助于為每個受訪者分配真實唯一的名字
The project is made in R language (version 4.0.0)With the help of dplyr and cluster packages
在dplyr和集群軟件包的幫助下,該項目以R語言(版本4.0.0)完成
處理中 (Processing)
Loading the Big5 dataset, which has 19k+ observations with 57 variables including Race, Age, Gender, Country besides the personality questions.
正在加載Big5數據集,該數據集具有19k +個觀察值,其中包括57個變量,包括種族,年齡,性別,國家/地區以及人格問題。
Removing the respondents who did not respond to few questions & some respondents with vague age values such as: 412434, 223, 999999999
刪除沒有回答幾個問題的受訪者和年齡值不明確的一些受訪者,例如:412434、223、99999999
Taking a healthy sample of 5000 respondents, since we don’t want the laptop go for a vacation when we want to find Euclidean distances between thousands of observations for clustering :)
對5000名受訪者進行了健康的抽樣調查,因為當我們想要找到成千上萬個觀測值之間的歐幾里得距離進行聚類時,我們不想讓筆記本電腦去度假:)
Loading the Baby-Names dataset and adding 5000 unique and real names to identify each observation as a person than just a number.
加載Baby-Names數據集并添加5000個唯一和真實的名稱,以將每個觀察值識別為一個人而不是一個數字。
Loading the Interests dataset, the dataset has 50 variables, each of them an interest or a hobby
加載興趣數據集后,該數據集包含50個變量,每個變量都是興趣或嗜好

After loading all of the datasets we combine them into one master dataframe and name it train, which has 107 column which are shown here:
加載所有數據集后,我們將它們組合到一個主數據框中并命名為train,該列具有107列,如下所示:

A few plots to see how our data lays out in terms of Age and Gender
一些圖表可以看出我們的數據在年齡和性別方面的布局


主成分分析 (Principal Component Analysis)
Remember we saw little correlation in the heatmap? Well this is where the Principal Component Analysis comes in. PCA combines the effect of some similar columns into a Principal Component column or PC.
還記得我們在熱圖中沒有看到多少相關性嗎? 好的,這就是進行主成分分析的地方。PCA將一些類似的列的效果合并到了“主成分”列或PC中。
For those who don’t know what Principal Component Analysis is; PCA is a dimension reduction technique which focuses on creating a totally new variable or a Principal Component(PC for short) from all of the variables through an equation to grasp most variation possible, from the data.
對于那些不知道什么是主成分分析的人; PCA是一種降維技術,其重點是通過方程式從所有變量中創建一個全新的變量或主成分(簡稱PC),以從數據中把握最大的變化。
In simple terms, PCA will help us in using only a few components which take into account the most important and most varying variables instead of using all 50 variables. You can learn more about PCA here.
簡而言之,PCA將幫助我們僅使用幾個考慮了最重要且變化最大的變量的組件,而不是全部使用50個變量。 您可以在此處了解有關PCA的更多信息。
Important: We run PCA on Interests columns and Big5 columns separately, since we don’t want to mix interests & personality.
重要提示 :由于我們不想混合興趣和個性,因此我們分別在興趣列和Big5列上運行PCA。
After running the PCA on Interest columns, what we get is 50 PCs. Now here is the fun part, we won’t be using all of them, here’s why: the first PC would be the strongest i.e a column that will grasp most of the variation in our data, the second PC would be weaker, and will grasp lesser variation and so on until 50th PC.
在“興趣”列上運行PCA之后,我們得到的是50臺PC。 現在這是有趣的部分, 我們不會使用所有這些 ,這是為什么:第一臺PC將是最強大的,即一列將掌握我們數據的大部分變化,第二臺PC將更弱,并且將掌握較小的變化,依此類推,直到第50臺PC。
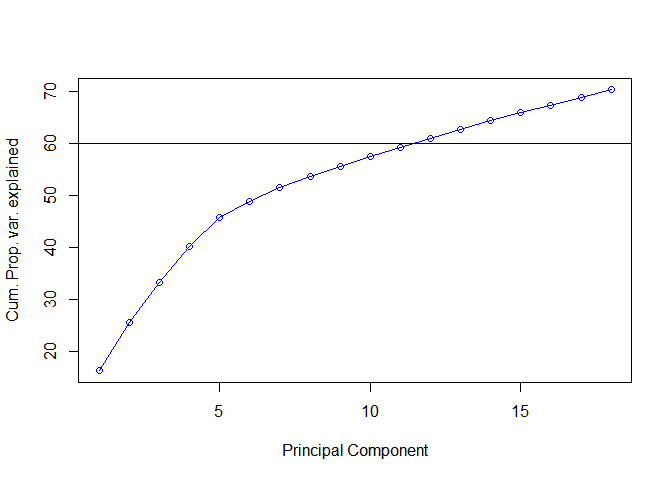
Our objective is to find the sweet spot between using 0 and 50 PCs and we will do that by plotting the variance explained by the PCs:
我們的目標是找到使用0到50臺PC之間的最佳點,我們將通過繪制PC解釋的方差來做到這一點:

Right: Cumulative version of the plot on the left.

But we will stretch it a little bit to cover 60% variance & take out 14 PCs.
The result? we just shrank number of columns from 50 to just 14, which explain 60% of the variation in the original Interest columns.
結果? 我們只是將列數從50縮減為14 ,這可以解釋原始興趣列的變化的60%。
Similarly, we do PCA on Big5 columns:
同樣,我們在Big5列上執行PCA:

Now that we have reduced the columns in Big5 from 50 to 14 , and in Interests from 50 to 12, we combine them into a dataframe different from train. We call it pcatrain.
現在,我們已將Big5中的列從50減少到14 ,將Interests從50減少到12 ,我們將它們組合成不同于train的數據幀。 我們稱它為pcatrain。
聚類 (Clustering)
As a good practice we first use Hierarchical Clustering to find a good value for k (the number of clusters)
作為一種好的做法,我們首先使用層次聚類為k (聚類數)找到一個好的值
層次聚類 (Hierarchical Clustering)
What is Hierarchical Clustering? Here is an example: Think of a house party of 100 people, now we start with every single person representing as a cluster of 1 person. The next step? We combine the two people/clusters standing closest into one cluster, then we label another two closest clusters as one, and so on. Finally we have gone from 100 clusters to 1 cluster. What Hierarchical Clustering does is form clusters on the basis of distance between the clusters and then we can see that process in a dendogram.
什么是層次聚類? 這是一個示例:假設有一個100人的家庭聚會,現在我們從每個人代表一個1人的集群開始。 下一步? 我們將最靠近的兩個人/集群合并為一個集群,然后將另外兩個最近的集群標記為一個,依此類推。 最終,我們從100個群集變為1個群集。 層次聚類所做的是基于聚類之間的距離形成聚類,然后我們可以在樹狀圖中看到該過程。

After doing Hierarchical Clustering we can see our own cluster dendogram here, as we go from bottom to top we see every cluster converging, the more distant each cluster is from the other, the longer steps it takes to converge; which you can see by looking at the vertical joins.
完成分層聚類后,我們可以在此處看到自己的聚類樹狀圖,當我們從下往上看時,每個聚類都在收斂,每個聚類之間的距離越遠,收斂所需的時間就越長; 您可以通過查看垂直聯接來看到。
Based on the distance we use the red line to divide a healthy group of 7 diverse clusters. The reason behind 7 is that, the 7 clusters take longer steps to converge, i.e the clusters are distant.
根據距離,我們使用紅線將健康的組劃分為7個不同的簇。 7背后的原因是,這7個聚類需要更長的時間才能收斂,即聚類較遠。
K均值聚類 (K-Means Clustering)

We use Elbow Method in K-Means to make sure that taking around 7 clusters is a good choice, we wont dive deep into it, but to summarize: The marginal sum of within-cluster distances between individuals & the marginal distance between the cluster centers is best at 6 clusters.
我們 在K-Means中 使用 Elbow方法 來確保大約7個聚類是一個不錯的選擇,我們不會深入研究它,而是總結一下:個人之間的聚類內距離的邊際總和以及聚類中心之間的邊際距離 最好 是 在6簇 。
具有6個聚類的K-Means聚類 (K-Means clustering with 6 clusters)
We run K-Means clustering with k=6; check the size of each cluster; what cluster the first 10 people are assigned. Finally we add this cluster column to our pcatrain dataframe, and now our dataframe has 33 columns.
我們以k = 6進行K-Means聚類; 檢查每個群集的大小; 前十個人被分配到哪個集群。 最后,我們將此簇列添加到我們的pcatrain數據幀中,現在我們的數據幀具有33列。
最后步驟 (Final steps)
Now that we have assigned clusters, we can start finding close matches for any individual.
現在,我們已經分配了集群,我們可以開始查找任何個體的緊密匹配項。
We select Penni as a random individual, for whom we will find matches from her cluster i.e cluster 2
我們選擇Penni作為隨機個體,我們將從其簇中找到匹配,即簇2
On left, we first find people from Penni’s cluster, then filter out people those who are in the same country as Penni’s, opposite gender, and belong to Penni’s age category.
在左側,我們首先從Penni的族群中找到人,然后過濾掉與Penni處于同一國家,性別相反并且屬于Penni的年齡類別的人。
Okay so now we have filtered out people, is that it?
好吧,現在我們已經濾除人員了,是嗎?
No. Remember the question we asked in the beginning?
否。還記得我們一開始提出的問題嗎?
‘How do you find a compatible partner?’
“您如何找到兼容的合作伙伴?”
Even though we have found people with same interests and age-group, we must find people who have personality most similar to Penni’s.
即使我們發現了具有相同興趣和年齡段的人 , 我們也必須找到與Penni的人格最相似的人。
This is where the Big5 personality columns come in handy.
這是Big5個性專欄派上用場的地方。
Through Big5, we will be able to find people who have the same level of Openness, Conscientiousness, Extraversion, Agreeableness and Neuroticism as Penni’s.
通過Big5,我們將能夠找到與Penni's具有相同程度的開放性,盡責性,性格外向,和gree可親和神經質的人。
What we did here is find the difference between the response of Penni and the response of filtered people for each personality column, and then added the differences of all the columns .
我們在這里所做的是找到每個個性列的Penni響應與被過濾人員的響應之間的差異 ,然后加上所有列的差異。
So now we know, if Penni is looking for a partner, she should first try to meet Brody.
因此,現在我們知道,如果Penni正在尋找伴侶,她應該首先嘗試與Brody見面。
我們為Penni尋找兼容人所做的工作的摘要: (A summary of what we did to find a compatible person for Penni:)
- Clustered people on the basis of their interests. 根據他們的興趣聚集人們。
- Found people who have similar interests, belong to same age-group as Penni’s. 發現興趣相似的人,與Penni屬于同一年齡段。
- Ranked those filtered people on the basis of how closely their personality matches Penni’s personality. 根據他們的人格與Penni的人格相匹配的程度對這些被過濾的人進行排名。
Thank you for sticking till the end!
感謝您堅持到底!
You can connect with me on:
您可以通過以下方式與我聯系:
Github
Github
領英
翻譯自: https://towardsdatascience.com/machine-learning-matchmaking-4416579d4d5e
機器人影視對接
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/389864.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/389864.shtml 英文地址,請注明出處:http://en.pswp.cn/news/389864.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

Android系統啟動系列----init進程

598. 范圍求和 II
簡析)
mysql 數據庫優化之執行計劃(explain)簡析

自我接納_接納預測因子


299. 猜數字游戲

mysql數據庫中case when 的用法

python中knn_如何在python中從頭開始構建knn


5920. 分配給商店的最多商品的最小值


unity第三人稱射擊游戲_在游戲上第3部分完美的信息游戲
--一文讀懂垃圾回收)
JVM(2)--一文讀懂垃圾回收

2058. 找出臨界點之間的最小和最大距離

tb計算機存儲單位_如何節省數TB的云存儲

nginx簡單代理配置

2059. 轉化數字的最小運算數
)
Django Rest Framework(一)

光落在你臉上,可愛一如往常
