tb計算機存儲單位
Whatever cloud provider a company may use, costs are always a factor that influences decision-making, and the way software is written. As a consequence, almost any approach that helps save costs is likely worth investigating.
無論公司使用哪種云提供商,成本始終是影響決策和軟件編寫方式的因素。 結果,幾乎所有有助于節省成本的方法都值得研究。
At Vendasta, we use the Google Cloud Platform. The software we maintain, design, and create, often makes use of Google Cloud Storage and Google CloudSQL; the team I am part of is no exception. The team works on a product called Website, which is a platform for website hosting. The product has two editions: Express (free, limited functionality), and Pro (paid, full functionality). Between the features that the product offers we find period backups of websites; these backups are archived as tar files. Each backup archive has an accompanying record stored in CloudSQL, which contains metadata such as the timestamp of the archive.
在Vendasta,我們使用Google Cloud Platform。 我們維護,設計和創建的軟件經常使用Google Cloud Storage和Google CloudSQL ; 我所在的團隊也不例外。 該團隊致力于開發一種名為“網站”的產品,該產品是用于網站托管的平臺。 該產品有兩個版本:Express(免費,功能有限)和Pro(付費,完整功能)。 在產品提供的功能之間,我們可以找到網站的定期備份; 這些備份被存檔為tar文件。 每個備份存檔都有一個隨附的記錄存儲在CloudSQL中,其中包含元數據,例如存檔的時間戳。
Recently, the team I am currently working in wanted to design and implement an approach to delete old backups in order to reduce costs. The requirements were:
最近,我目前正在工作的團隊希望設計并實施一種刪除舊備份的方法,以降低成本。 要求是:
- Delete archives and records older than 1 year; 刪除超過1年的檔案和記錄;
- For the Express edition, keep archives and records that were created in the last 10 days. In addition, keep the backups from the beginning of each month for the last year; 對于Express版本,請保留最近10天內創建的檔案和記錄。 此外,請保留上一年每個月初的備份;
- For the Pro edition, keep archives and records that were created in the last 60 days. In addition, keep the backups created at the beginning of each month for the last year; 對于專業版,請保留最近60天內創建的檔案和記錄。 另外,保留在去年的每個月初創建的備份;
- Perform steps 1–3 every day for all the sites the product hosts. 每天對產品托管的所有站點執行步驟1-3。
We are going to walk through how the requirements were satisfied for each step, and use Golang code, along with an SQL statement, to demonstrate how to execute the steps.
我們將逐步介紹如何滿足每個步驟的要求,并使用Golang代碼和SQL語句來演示如何執行這些步驟。
Google Cloud Storage offers the option of object lifecycle management, which allows users to set custom rules such as deleting bucket objects, or changing the storage option of a bucket, after a specific time period/age. While this may work for many use cases, it did not satisfy our requirements because of custom rules for product editions. In addition, transitioning the whole platform to use a different naming scheme for backups (no context of edition currently) to be able to use lifecycle management would have been an enormous amount of work. As a consequence, the team went ahead with a custom solution that is extensible as additional custom cleanups can be added to it in the future.
Google Cloud Storage提供了對象生命周期管理選項,允許用戶在特定時間段/年齡之后設置自定義規則,例如刪除存儲桶對象或更改存儲桶的存儲選項。 盡管這可能適用于許多用例,但由于產品版本的自定義規則,它不能滿足我們的要求。 此外,轉換整個平臺以使用不同的命名方案進行備份(當前沒有版本上下文)以能夠使用生命周期管理將是一項艱巨的工作。 因此,團隊繼續開發可擴展的自定義解決方案,因為將來可以在其中添加其他自定義清理功能。
The first thing that was implemented was the part that iterates over all the sites, and creates tasks for archive and record cleanups. We chose Golang Machinery, a library for asynchronous job scheduling and parsing. Our team often uses Memorystore, which was the storage layer of choice for our use of Machinery. The scheduling was performed by an internal project that the team uses for scheduling other types of work:
實施的第一件事是迭代所有站點,并創建用于存檔和記錄清理的任務。 我們選擇了Golang Machinery ,該庫用于異步作業調度和解析。 我們的團隊經常使用Memorystore ,這是我們使用Machine的首選存儲層。 調度是由一個內部項目執行的,團隊使用該內部項目來調度其他類型的工作:
package schedulerimport ("time""github.com/RichardKnop/machinery/v1/tasks""github.com/robfig/cron"// fake packages, abstracts away internal code"github.com/website/internal/logging""github.com/website/internal/repository"
)const (// dailyBackupCleaningSchedule is the daily cron pattern for performing daily backup cleanupsdailyBackupCleaningSchedule string = "@daily"
)// StartBackupCleaningCron creates a cron that scheduled backup cleaning tasks
func StartBackupCleaningCron() {job := cron.New()if err := job.AddFunc(dailyBackupCleaningSchedule, func() {SheduleBackupCleaningTasks()}); err != nil {logging.Errorf("failed to schedule daily backup cleaning, err: %s", err)}job.Run()
}// ScheduleBackupCleaningTasks iterates over all the sites and creates a backup cleaning task
func ScheduleBackupCleaningTasks() {now := time.Now()cursor := repository.CursorBeginningfor cursor != repository.CursorEnd {sites, next, err := repository.List(cursor, repository.DefaultPageSize)if err != nil {// if a listing of sites fails, this will retry tomorrowcontinue}for _, site := range sites {// GetCleanupTask abstracted, see Machinery documentation on how to create a taskrecordCleanupTask := GetRecordingCleanupTask(site.ID(), site.EditionID(), now)// if a record cleanup task has been scheduled already, there's also a record cleanup task, so continuing at this step is sufficient// taskAlreadyQueued abstracted, check whether a task has beed scheduled based on the artificial UUIDif taskAlreadyQueued(recordCleanupTask.UUID) {continue}// GetArchiveCleanupTask abstracted, see Machinery documentation on how to create a taskarchiveCleanupTask := GetArchiveCleanupTask(site.ID, site.EditionID, now)// use a chain because the tasks should occur one after anotherif taskChain, err := tasks.NewChain(recordCleanupTask, archiveCleanupTask); err != nil {logging.Errorf("error creating backup cleanup task chain: %s -> %s, error: %s", recordCleanupTask.UUID, archiveCleanupTask.UUID, err)// machineryQ is not initialized in this script and is abstracted. See how to initialize the queue using Machinery docs} else if _, err := MachineryQueue.SendChain(taskChain); err != nil {logging.Errorf("error scheduling backup cleanup task chain: %s -> %s, error: %s", recordCleanupTask.UUID, archiveCleanupTask.UUID, err)}}cursor = next}return
}The code above fulfills three main objectives:
上面的代碼實現了三個主要目標:
Creates a cron job for a daily task creation;
為日常任務創建創建cron作業;
- Iterates over all the sites; 遍歷所有站點;
- Creates the archive and record cleaning tasks. 創建存檔并記錄清理任務。
The second part of the implementation was to design and create the software that consumes the tasks that were scheduled for cleaning. For this part, the team constructed an SQL query that returns all the records that have to be deleted, and satisfy the constraints imposed by the edition of the products; Express, or Pro.
實施的第二部分是設計和創建使用計劃要進行清理的任務的軟件。 對于這一部分,團隊構建了一個SQL查詢,該查詢返回所有必須刪除的記錄,并滿足產品版本所施加的約束。 Express或Pro。
package backupimport ("fmt"// fake package, you have to instantiate an SQL connection, and then execute queries using it"github.com/driver/sqlconn"// fake packages for abstraction"github.com/website/internal/gcsclient""github.com/website/internal/logging"
)const (// SQLDatetimeFormat is the SQL5.6 datetime formatSQLDatetimeFormat = "2006-01-02 15:04:05"
)// BackupRecordCleanup performs the work associated with cleaning up site backup records from CloudSQL
func BackupRecordCleanup(siteID, editionID, dateScheduled string) error {// GetCutoffBasedOnEdition is abstracted, but it only returns two dates based on the scheduled date of the taskminCutoff, maxCutoff, err := GetCutoffBasedOnEdition(editionID, dateScheduled)if err != nil {return fmt.Errorf("record cleanup failed to construct the date cutoffs for site %s, edition %s, err: %s", siteID, editionID, err)}query := GetRecordsDeleteStatement(siteID, minCutoff.Format(internal.SQLDatetimeFormat), maxCutoff.Format(internal.SQLDatetimeFormat))if res, err := sqlconn.Execute(query); err != nil {return fmt.Errorf("failed to execute delete statement for %s, edition %s, on %s, err: %s", siteID, editionID, dateScheduled, err)} else if numRowsAffected, err := res.RowsAffected(); err != nil {return fmt.Errorf("failed to obtain the number of affected rows after executing a deletion for %s, edition %s, on %s, err: %s", siteID, editionID, dateScheduled, err)} else if numRowsAffected == 0 {// while this expects at least 1 row to be affected, it is ok to not return here as the row might be gone alreadylogging.Infof(m.ctx, "expected deletion statement for %s, edition %s, on %s to affect at least 1 row, 0 affected", siteID, editionID, dateScheduled)}return nil
}// BackupArchiveCleanup performs the work associated with cleaning up site backup archives from GCS
func BackupArchiveCleanup(siteID, editionID, dateScheduled string) error {// SiteBackupCloudBucket abstracted because it's an environment variableobjects, err := gcsclient.Scan(SiteBackupCloudBucket, siteID, gcsclient.UnlimitedScan)if err != nil {return fmt.Errorf("failed to perform GCS scan for %s, err: %s", siteID, err)}minCutoff, maxCutoff, err := GetCutoffBasedOnEdition(editionID, dateScheduled)if err != nil {return fmt.Errorf("archive cleanup failed to construct the date cutoffs for site %s, edition %s, err: %s", siteID, editionID, err)}// sorting is performed to facilitate the deletion of archives first, oldest to most recentsortedBackupObjects, err := SortBackupObjects(m.ctx, objects)if err != nil {return fmt.Errorf("failed to sort backup objects for site %s, edition %s, err: %s", siteID, editionID, err)}if len(sortedBackupObjects) > 0 {// track the month changes in order to filter which backups to keep. The backup at position 0 is always// kept since it is the earliest backup this service has, for whatever month the backup was performed inprevMonth := int(sortedBackupObjects[0].at.Month())// iterations start at 1 since this always keeps the first backup. If a site ends up with two "first month"// backups, the second one will be deleted the next dayfor _, sbo := range sortedBackupObjects[1:] {if sbo.at.After(minCutoff) {// backups are sorted at this point, so this can stop early as any backup after this one will also satisfy the After()break}// no point in keeping backups that are older than maxCutoff, e.g 1 year, so those are deleted without regard// for the month they were created in. However, if a backup was created between min and maxCutoff, this will// keep the month's first backup, and delete everything else conditioned on the edition ID. For example, if sortedBackupObjects[0]// is a January 31st backup and the next one is February 1st, the months will be 1 and 2, respectively,// which will cause the condition to be false, and keep will be set to true, skipping the deletion// of the February 1st backup. The next iteration will set keep to false as the months are the samecurrMonth := int(sbo.at.Month())if sbo.at.Before(maxCutoff) || currMonth == prevMonth {if err := gcsclient.Delete(sbo.gcsObj.Bucket, sbo.gcsObj.Name); err != nil {logging.Infof(m.ctx, "failed to delete GCS archive %s/%s for site %s, edition %s, err: %s", sbo.gcsObj.Bucket, sbo.gcsObj.Name, siteID, editionID, err)}}prevMonth = currMonth}}return nil
}// GetRecordsDeleteStatement returns the SQL statement necessary for deleting a single SQL backup record. The
// statement will delete any backups that have been created before maxDateCutoff but will keep the monthly backups that
// have been created between min and maxDateCutoff. This is a public function so that it is easily testable
func GetRecordsDeleteStatement(siteID, minDateCutoff, maxDateCutoff string) string {internalDatabaseName := fmt.Sprintf("`%s`.`%s`", config.Env.InternalDatabaseName, config.Env.SiteBackupCloudSQLTable)baseStatement := `
-- the main database is website-pro, for both demo and prod
-- delete backup records that are older than 1 year (or whatever maxDateCutoff is set to)
DELETE FROM %[1]s
WHERE (site_id = "%[2]s"AND timestamp < CONVERT("%[4]s", datetime)
) OR (
-- delete the ones older than the date specified according to the edition ID of the site (or whatever minDateCutoff is set to)site_id = "%[2]s"AND timestamp < CONVERT("%[3]s", datetime)AND timestamp NOT IN (SELECT * FROM (SELECT MIN(timestamp)FROM %[1]sWHERE status = "done"AND site_id = "%[2]s"GROUP BY site_id, TIMESTAMPDIFF(month, "1970-01-01", timestamp)) AS to_keep)
);`return fmt.Sprintf(baseStatement,internalDatabaseName, // database name, along with table namesiteID, // the site ID for which old backups will be deletedminDateCutoff, // the min date cutoff for backup datesmaxDateCutoff, // the max date cutoff for backup dates)
}Note that the above code sample is incomplete. To make it a completely workable example, the Machinery task consumer has to be implemented, and BackupArchiveCleanup, along with BackupRecordCleanup, be set as the main functions that process the tasks created by ScheduleBackupCleaningTasks from the previous example. For the code sample above, let’s focus on the SQL query, as it was the part that was the most heavily tested by the team (we do not have backups of backups, and testing is important in general).
請注意,以上代碼示例不完整。 為了使其成為一個完全可行的示例,必須實現“機械”任務使用者,并將BackupArchiveCleanup以及BackupRecordCleanup設置為主要函數,該函數處理上一個示例中的ScheduleBackupCleaningTasks創建的任務。 對于上面的代碼示例,我們將重點放在SQL查詢上,因為它是團隊最嚴格測試的部分(我們沒有備份的備份,并且測試通常很重要)。
The query scans the CloudSQL table that contains the records of the backups (internalDatabaseName) and deletes records with a timestamp older than a maximum date cutoff (the one year requirement). Any records with a timestamp that are not older than one year are deleted conditionally based on whether their timestamp is less than the minimum date cutoff (60 or 10, days, respectively). In addition, the timestamp should not be in the specified sub-query. The sub-query uses an SQL TIMESTAMPDIFF to group timestamps based on the difference in months, which results in the first backup of a month being selected (see documentation).
該查詢將掃描包含備份記錄( internalDatabaseName )的CloudSQL表,并刪除時間戳早于最大截止日期(一年的要求)的記錄。 時間戳不超過一年的任何記錄都將根據其時間戳是否小于最小日期截止時間(分別為60天或10天)而有條件地刪除。 此外,時間戳記不應位于指定的子查詢中。 子查詢使用SQL TIMESTAMPDIFF根據月份差異將時間戳分組,這將導致選擇一個月的第一個備份(請參閱文檔)。

The overall architecture of the cleanup process is represented by the diagram on the left. Generally, there is a service that creates cleanup tasks, one that processes them, both backed by the same underlying storage layer.
清理過程的總體架構由左側的圖表示。 通常,有一種服務可以創建清理任務,并執行清理任務,它們均由同一基礎存儲層支持。
結果 (Results)
The team started the development outlined in this blog with the intent to save storage costs. To measure that, there are two options:
為了節省存儲成本,團隊開始了本博客中概述的開發。 要衡量這一點,有兩種選擇:
Use
gsutil duto measure the total bytes used by specific buckets. However, because of the size of the buckets the team uses, it is recommended to not use this tool for measuring total bytes used;使用
gsutil du來衡量特定存儲桶使用的總字節數。 但是,由于團隊使用的存儲桶的大小, 建議不要使用此工具來測量已使用的總字節數。Use Cloud Monitoring to get the total bytes used by GCS buckets.
使用Cloud Monitoring獲取GCS存儲桶使用的總字節數。
After testing for approximately one week in a demo environment, on a subset of websites (again, no backups of backups), the code was released to production. The result is outlined by the following diagram:
在演示環境中測試了大約一個星期后,在一部分網站上(同樣,沒有備份的備份),該代碼已發布到生產環境中。 下圖概述了結果:
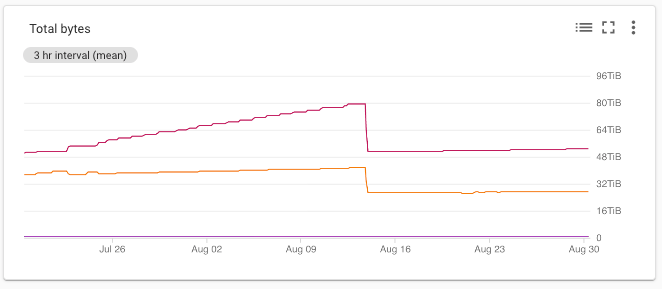
The chart outlines the total amount of bytes, from the past six weeks, that our team is currently using in its main Google Cloud Platform project where backups are stored. The chart contains two lines because of the two types of storage the team uses, NEARLINE and COLDLINE. Throughout July and the beginning of August, the chart outlines a fast rate of increase in storage use — approximately 40TB. After releasing the cleanup process to the production environment, we notice a much more sustainable rate of growth for total bytes used. This has resulted in approximately $800/month in cost savings. While not much for a company the size of Vendasta, it alleviates the team from periodically performing manual backup cleaning, and automates a process that result in significant cost savings long-term. In addition, it is a process that can be used to replicate the cleanup of other types of data. As a note, you may have noticed that the team did not measure the cost savings from deleting CloudSQL records. The CloudSQL deleted table rows resulted only in MB of space savings, which are not significant by comparison to the storage savings from deleting archives.
該圖表概述了我們團隊目前在其用于存儲備份的主要Google Cloud Platform項目中使用的過去六周的字節總數。 由于團隊使用兩種存儲類型,因此圖表包含兩條線: NEARLINE和COLDLINE 。 在整個7月和8月初,該圖表概述了存儲使用量的快速增長-大約40TB。 將清理過程發布到生產環境后,我們注意到所使用的總字節數的增長速度更加可持續。 這樣每月可節省約800美元。 對于一家像Vendasta這樣規模的公司來說,這雖然不算多,但可以減輕團隊定期執行手動備份清理的負擔,并使流程自動化,從而可以長期節省大量成本。 此外,該過程可用于復制其他類型數據的清除。 注意,您可能已經注意到,該團隊沒有衡量刪除CloudSQL記錄所節省的成本。 CloudSQL刪除的表行僅導致MB的空間節省,與刪除檔案所節省的存儲空間相比,這并不重要。
Lastly, it is possible that your company’s data retention policy does not allow you to delete data at all. In that case, I suggest using the Archive storage option, which was released this year and provides the most affordable option for long-term data storage.
最后,您公司的數據保留政策可能根本不允許您刪除數據。 在這種情況下,我建議使用今年發布的“ 存檔存儲”選項,該選項為長期數據存儲提供了最經濟的選擇。
Vendasta helps small and medium-sized businesses around the world manage their online presence. A website is pivotal for managing online presence and performing eCommerce. My team is working on a website-hosting platform that faces numerous interesting scalability (millions of requests per day), performance (loading speed), and storage (read, and write speed) problems. Consider reaching out to me, or applying to work at Vendasta, if you’d like a challenge writing Go and working with Kubernetes, NGINX, Redis, and CloudSQL!
Vendasta幫助全球的中小型企業管理其在線業務。 網站對于管理在線狀態和執行電子商務至關重要。 我的團隊正在開發一個網站托管平臺,該平臺面臨許多有趣的可伸縮性(每天數百萬個請求),性能(加載速度)和存儲(讀和寫速度)問題。 如果您想編寫Go并與Kubernetes , NGINX , Redis和CloudSQL一起工作時遇到挑戰,請考慮與我聯系,或申請在Vendasta工作!
翻譯自: https://medium.com/vendasta/how-to-save-terabytes-of-cloud-storage-be3643c29ce0
tb計算機存儲單位
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/389849.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/389849.shtml 英文地址,請注明出處:http://en.pswp.cn/news/389849.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

nginx簡單代理配置

2059. 轉化數字的最小運算數
)
Django Rest Framework(一)

光落在你臉上,可愛一如往常

數據可視化機器學習工具在線_為什么您不能跳過學習數據可視化

2047. 句子中的有效單詞數


python中nlp的庫_用于nlp的python中的網站數據清理

51Nod 1043 幸運號碼

一張圖看懂云棲大會·上海峰會重磅產品發布


【黑客免殺攻防】讀書筆記14 - 面向對象逆向-虛函數、MFC逆向

怎么看另一個電腦端口是否通_誰一個人睡覺另一個看看夫妻的睡眠習慣


Java基礎之Collection和Map

20155320《網絡對抗》Exp4 惡意代碼分析

tableau 自定義省份_在Tableau中使用自定義圖像映射

2055. 蠟燭之間的盤子

Template、ItemsPanel、ItemContainerStyle、ItemTemplate
