map(平均平均精度
Disclaimer: this was created for my clients because it’s rather challenging to explain such a complex metric in simple words, so don’t expect to see much of math or equations here. And remember that I try to keep it simple.
免責聲明 :這是為我的客戶創建的,因為用一個簡單的詞來解釋這樣一個復雜的指標是相當困難的,因此不要期望在這里看到太多的數學或方程式。 并記住,我嘗試使其保持簡單。
準確性 (Accuracy)
Accuracy is the most vanilla metric out there. Imagine we are doing classification of whether there is a dog in a picture. In order to test our classifier, we prepare a test set with pictures of both containing dogs and not. We then apply our classifier to every picture and get the predicted classes.
準確性是目前最常用的指標。 假設我們正在對圖片中是否有狗進行分類。 為了測試我們的分類器,我們準備了一個包含不包含狗的圖片的測試集。 然后,我們將分類器應用于每張圖片,并獲得預測的分類。
So we can then calculate accuracy using this simple formula.
這樣我們就可以使用此簡單公式來計算準確性。
精度和召回率 (Precision and recall)
There are many more ways to determine how well a model works and two others are precision and recall. They show a bit different things and usually go in a pair.
還有許多方法可以確定模型的運行狀況,還有兩種方法可以提高精度和召回率 。 它們顯示出一些不同的東西,通常成對出現。
Going on with our dog recognizer, precision shows how many of predicted dogs are actually dogs.
繼續我們的狗識別器, 精度顯示出實際上有多少只預測的狗。
And recall is the ratio of correctly predicted dogs to the amount of dogs in our test set.
回憶是正確預測的狗與測試集中狗的數量之比。
例 (Example)
Let’s imagine that our test set contains 12 pictures with dogs and 8 pictures with no dogs. We apply our classifier and get 8 pictures predicted as “dog” and the rest 12 are “no dog”. And out of those 8 marked as “dog” only 5 are actually “dog” and the rest are just wrong.
假設我們的測試集包含12張有狗的圖片和8張無狗的圖片。 我們應用分類器,得到8張預測為“狗”的圖片,其余12張為“無狗”。 在這8個標記為“狗”的動物中,只有5個實際上是“狗”,其余的都是錯誤的。
So our precision is
所以我們的精度是
And our recall is
我們的回憶是
Why to use precision and recall?
為什么要使用精度和召回率?
This two metrics give us a deeper understanding of errors that our model makes, hence allowing us to analyze and create better solutions. And because of this in-depth understanding we stick to them and not to the accuracy metric.
這兩個指標使我們對模型所產生的錯誤有更深入的了解,從而使我們能夠分析和創建更好的解決方案。 并且由于這種深入的了解,我們堅持使用它們而不是準確性指標。
聯合路口 (Intersection over union)
In order to fully understand the mean average precision metric we need to know what intersection over union is.
為了完全理解平均平均精度度量,我們需要知道什么是聯合的交集。
It comes up when we create object detection solutions and is needed for determining how well we find an object in a picture.
當我們創建對象檢測解決方案時,它就會出現,這是確定我們在圖片中找到對象的程度所需要的。
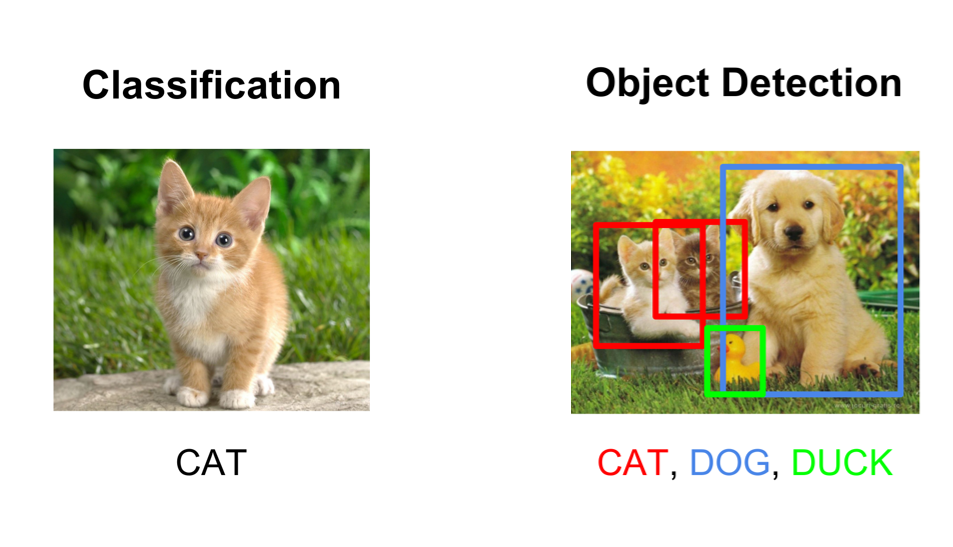
Not only do we need to classify an object but also to locate it. Those little colourful rectangles are called bounding boxes.
我們不僅需要對對象進行分類,還需要對其進行定位。 那些小的彩色矩形稱為邊界框。
So let’s say we have an object detection model but in a what way do we measure how well it detects? That’s when intersection over union (IoU) comes in handy.
因此,假設我們有一個對象檢測模型,但是以什么方式衡量它的檢測效果呢? 那時,聯合交叉口(IoU)派上了用場。
In order to compute this we need a test set with so called ground truth bounding boxes and, of course, they must be labeled at first, so that when it comes to testing we can compare the real data with the predicted data.
為了計算這一點,我們需要一個帶有所謂的地面真實邊界框的測試集,當然,它們必須首先被標記,以便在進行測試時,我們可以將真實數據與預測數據進行比較。
Let’s say that the green boxes are our ground truth bounding boxes (the boxes we labeled beforehand by our human hands and eyes) and the red ones are predicted by our model.
假設綠色框是我們的地面真值邊界框(我們用人的手和眼睛預先標記的框),紅色框是我們的模型預測的。

And the formula is now very simple
現在公式很簡單

To clarify, it’s a ratio of the overlapping (or intersecting) area between a ground truth bounding box and a predicted one and the union area of those two.
為了闡明這一點,它是地面真值邊界框和預測的邊界框之間的重疊(或相交)區域與這兩個區域的并集區域之比。
平均平均精度 (Mean Average Precision)
So what is mean average precision (mAP) then? To calculate it we need to set a threshold value for IoU, for example, 0.5. It means that we say that the object is detected when we located 50% of that object in a bounding box.
那么什么是平均精度 (mAP)呢? 要計算它,我們需要為IoU設置一個閾值,例如0.5。 這意味著當我們在邊界框中找到該對象的50%時,便表示已檢測到該對象。
Then all we have to do is to calculate precision and recall values. There is a way to combine those two into one value but it’s a bit more advanced so we are not going to cover it here.
然后,我們要做的就是計算精度和召回值。 有一種方法可以將這兩個值合并為一個值,但是它要先進一些,因此我們不在這里介紹。
And after that we change the threshold value for IoU with a tiny step. For instance, the next threshold will be 0.55. Then again computing precision and recall values.
之后,我們只需一步就可以更改IoU的閾值。 例如,下一個閾值將是0.55。 然后再次計算精度并調用值。
And again changing the threshold value for IoU. Now it will be 0.6. Again calculating precision and recall values. Usually those threshold values begin with 0.5 and go on up to 0.9 with a step of 0.05.
并再次更改IoU的閾值。 現在將是0.6。 再次計算精度和召回值。 通常,這些閾值以0.5開頭,然后以0.05為步長直到0.9。
And then mean average precision is that combined value of precision and recall averaged over all the thresholds.
然后,平均平均精度是指在所有閾值上平均的精度和召回率的總和。
它顯示什么? (What does it show?)
It shows how well a model classifies objects with different detection threshold values. The higher the value, the better the model. Results are vary highly but usually a well working model has mAP of 0.45–0.5 on a complex task.
它顯示了模型對具有不同檢測閾值的對象進行分類的效果。 值越高,模型越好。 結果差異很大,但正常工作的模型通常在復雜任務上的mAP為0.45-0.5。
You can check out example of models’ mAP on COCO dataset here: https://pjreddie.com/darknet/yolo/.
您可以在以下位置查看COCO數據集上模型的mAP示例: https ://pjreddie.com/darknet/yolo/。
Hope, it helps you.
希望對您有幫助。
Connect with me on Twitter, LinkedIn, Facebook and follow on GitHub!
在 Twitter , LinkedIn , Facebook 上與我聯系 , 然后在 GitHub上關注我 !
翻譯自: https://medium.com/@poddiachyi/mean-average-precision-for-clients-aecb0b039ac9
map(平均平均精度
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/389815.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/389815.shtml 英文地址,請注明出處:http://en.pswp.cn/news/389815.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

Sublime Text 2搭建Go開發環境,代碼提示+補全+調試

629. K個逆序對數組

zookeeper、hbase常見命令

鮮活數據數據可視化指南_數據可視化實用指南

2049. 統計最高分的節點數目

Linux lsof命令詳解

史密斯臥推:杠鈴史密斯下斜臥推、上斜機臥推、平板臥推動作圖解

圖像特征 可視化_使用衛星圖像可視化建筑區域

ELK入門01—Elasticsearch安裝

375. 猜數字大小 II

hdu_2048 錯排問題

海量數據尋找最頻繁的數據_在數據中尋找什么

OSChina 周四亂彈 —— 要成立復仇者聯盟了,來報名

2023. 連接后等于目標字符串的字符串對
)
webapi 找到了與請求匹配的多個操作(ajax報500,4的錯誤)

可視化 nlp_使用nlp可視化尤利西斯

區分'方法'和'函數'

520. 檢測大寫字母

Java 打包 FatJar 方法小結
)