可視化 nlp
My data science experience has, thus far, been focused on natural language processing (NLP), and the following post is neither the first nor last which will include the novel Ulysses, by James Joyce, as its primary target for NLP and literary elucidation. In this post I will explain why it’s such a perfect target, since Ulysses will likely be the focus of my next project. This will probably be a multi-part blog post.
到目前為止,我的數據科學經驗一直集中在自然語言處理(NLP)上,以下文章既不是第一也不是最后一篇,其中包括James Joyce的小說《尤利西斯》(Ulysses),作為其NLP和文學闡釋的主要目標。 在這篇文章中,我將解釋為什么它是一個如此理想的目標,因為尤利西斯很可能成為我下一個項目的重點。 這可能是一個多部分的博客文章。
關于這本書 (About the Book)
First off, why this book?
首先,為什么要這本書?
Ulysses, by James Joyce, has elicited just about every kind of response from readers since its publication in 1922, ranging from claims that it’s the pinnacle of modernist literature to claims that it’s a filthy, decadent depiction of obscenity and pornography (nonetheless glittering with Shakespearean intertextuality on nearly every page) which should be, and was, banned until the famous Supreme Court case, United States v. One Book Called Ulysses in 1933 decidedly readmitted it into the United States. Moreover, this decision highlighted serious, longstanding philosophical questions about the role of art and the right to literary expression.
自1922年出版以來,詹姆斯·喬伊斯(James Joyce)撰寫的《尤利西斯》(Ulysses)引起了讀者的幾乎所有回應,從聲稱這是現代主義文學的巔峰之作,到聲稱這是對淫穢和色情的骯臟,decade廢的描寫(盡管如此,莎士比亞還是閃閃發光的)。幾乎在每頁上都應保留互文性),直到著名的最高法院案件《美國訴一本名叫尤利西斯的書》 (1933年)被堅決重新納入美國為止。 此外,這一決定突出了關于藝術的作用和文學表達權的嚴重的,長期的哲學問題。
I fall firmly into the former category, and I believe it’s an affirmative work of genius. The reasons for this include many of the reasons I use Ulysses for NLP: the intent of Joyce was to recreate the many different modes of human experience through language. Through the scintillating and narrowing confines of different languages, dialects, subdialects, profanities, connotations, grammars, and idioms, all of which cross different religious and cultural traditions from the Catholic Church to Irish nationalists, to the mundane domestic affairs of a house in Ireland in 1904, to the parallels of ordinary life found on one day in Dublin to the Odyssey, as well as Shakespeare’s Hamlet, through fixations on classical philosophy and human suffering expressed via a hallucinatory, drunken escapade in a brothel manifesting as both the climax of the novel and the resurrection of the dead, Joyce believed that dimensionality would emerge through the parallax of flowing between these different modes of language, or life.
我堅決屬于前一類,并且我相信這是天才的肯定作品。 原因包括我將Ulysses用于NLP的許多原因:Joyce的目的是通過語言重現人類體驗的許多不同模式。 通過各種語言,方言,次方言,褻瀆,內涵,語法和成語的閃爍而狹窄的界限,所有這些跨越了不同的宗教和文化傳統,從天主教到愛爾蘭民族主義者,再到愛爾蘭一所房子的平凡的內政在1904年,普通生活的相似之處在都柏林的第一天發現奧德賽 ,以及莎士比亞的哈姆雷特 ,通過對古典哲學,并通過表達人類痛苦的注視幻覺,在妓院醉酒越軌行為表現為兩個高潮喬伊斯(Joece)認為小說和死者的復活是通過這些不同的語言或生活模式之間流動的視差而出現的維度 。
If the ostensible larger project of data science is to provide conceptual clarity via statistical analysis, as well as actionable insight through computing via machine learning, feature engineering, and deep understanding of data structures with the mindset of a scientist, then I can think of no greater interdisciplinary project, at least in the realm of NLP, than Ulysses for the sake of validating Joyce’s larger project. There are deeper parallels between data science and literary criticism than I initially realized when I entered the field, particularly in the importance of understanding the data through exploratory data analysis. And the more experience I’ve gained, the more I’ve realized this is a STEM way of saying ‘cultivate emotional alignment and clarity through conceptually rigorous inspection until dimensionality emerges in the data’.
如果說表面上較大的數據科學項目是通過統計分析來提供概念清晰性,以及通過機器學習,特征工程以及以科學家的思維方式對數據結構的深刻理解來通過計算提供可行的見解,那么我可以認為沒有為了驗證喬伊斯的更大項目,至少在NLP領域,這個更大的跨學科項目要比尤利西斯(Ulysses)好。 數據科學與文學批評之間的相似之處比我進入該領域時最初所意識到的要深得多,尤其是在通過探索性數據分析來理解數據的重要性方面。 而且我獲得的經驗越多,我就越意識到這是一種STEM方式,即“通過概念上嚴格的檢查來培養情緒的一致性和清晰度,直到數據中出現維數為止”。
Hence, the following project will be an attempt to simply visualize Ulysses in a way inspired by a similar project.
因此,以下項目將嘗試以類似項目的啟發方式簡單地可視化Ulysses 。
動機 (The Motivation)
I was initially inspired by this project. The project is presented in the form of an academic article on Thomas Pynchon’s V, another difficult English novel characterized by a fragmented plot and an unclear timeline, by Christos Iraklis Tsatsoulis, completed in 2013, and I remain continuously shocked that I haven’t found more projects like it. I presume this is due to a cultural gap between Data Science and Literary Criticism, for reasons most likely due to the ancient war between STEM and liberal arts.
最初,我受到這個項目的啟發。 該項目以關于托馬斯·平昌V的學術文章的形式呈現,該小說是克里斯托斯·伊拉克利斯·特薩蘇里斯(Christos Iraklis Tsatsoulis)于2013年完成的另一本艱難的英語小說,其特點是劇情零散,時間表不明確,我一直為我沒有發現而感到震驚更多類似的項目。 我認為這是由于數據科學與文學批評之間的文化鴻溝造成的,原因很可能是由于STEM與文科之間的古老戰爭 。
To start, Tsatsoulis presents an overview of the novel from a literary perspective, going over chapter summaries and the two primary ‘storylines’ in the book, the V. storyline and the Profane storyline. For the reader’s sake, I’ll be transparent by saying that I haven’t read V. by Thomas Pynchon, nor do you need to have read Ulysses to understand either project. For this post, I would only like to outline and emphasize the ingenuity behind the overarching project, which is to make a true interdisciplinary effort to use the brilliant tools of contemporary NLP to augment literary analysis through both visualization and deeper understanding of the semantic content.
首先,Tsatsoulis從文學的角度對小說進行了概述,介紹了章節摘要和本書中的兩個主要“故事情節”,即V.故事情節和Profane故事情節。 為了讀者的緣故,我會公開地說我沒有讀過Thomas Pynchon的V. ,也不需要讀過Ulysses就能理解這兩個項目。 對于本篇文章,我只想概述和強調總體項目背后的獨創性, 即通過跨學科的努力,利用可視化和對語義內容的深入理解,利用當代NLP的出色工具來加強文學分析 。
So often have I seen the combative attitude between ‘machine learning’ and ‘art’, always descending into the same pit of claims that ‘a computer can never make real art’ versus claims that ‘real art is simply a set of fundamental patterns which can be learned and replicated’, whether in the context of AI-produced music, literature, or any number of films about AI-related romance and love. Without getting into the tangential complexities of that debate, I only mean to point out how little cooperation there is between these general poles, which seem to correspond, again, to STEM and liberal arts.
我經常看到“機器學習”與“藝術”之間的戰斗態度,總是陷入“計算機永遠不能創造真實藝術”的說法與“真實藝術只是一組基本模式,可以在AI產生的音樂,文學或任何與AI相關的愛情和愛情的電影中學習和復制。 在不討論該辯論的切線復雜性的情況下,我只想指出這些普遍的極點之間幾乎沒有合作 ,而這些極點似乎又與STEM和文科相對應。
What Tsatsoulis accomplished shows just how useful the tools of NLP can be for healing this strange adversarial relationship.
Tsatsoulis取得的成就表明,NLP的工具對于治愈這種奇怪的對抗性關系有多么有用。
After presenting a literary overview of V., he then provides some exploratory data analysis, like any good data scientist, via a wordcloud and some of V.’s characterizing vocabulary. He explains his primary methodology for capturing the structure of semantic content throughout the novel, which involves TF-IDF and hierarchical clustering, as well as the interesting and original utilization of ‘distance thresholds’ between chapters, based on Euclidian, Manhattan, and Canberra distances, as well as an independent section on Normalized Compression Distance, a methodology based on Kolmogorov complexity. He uses these distance thresholds to create the bafflingly interesting visualizations for the novel:
在介紹了V.的文學概觀之后,他隨后通過詞云和一些V.的特征性詞匯,提供了一些探索性的數據分析,就像任何一位好的數據科學家一樣。 他解釋了他捕獲整個小說中語義內容結構的主要方法,該方法涉及TF-IDF和分層聚類,以及基于歐幾里得,曼哈頓和堪培拉距離的章節之間“距離閾值”的有趣和原始用法,以及關于標準化壓縮距離的獨立部分,該方法基于Kolmogorov復雜度。 他使用這些距離閾值為小說創建了令人困惑的有趣可視化效果:
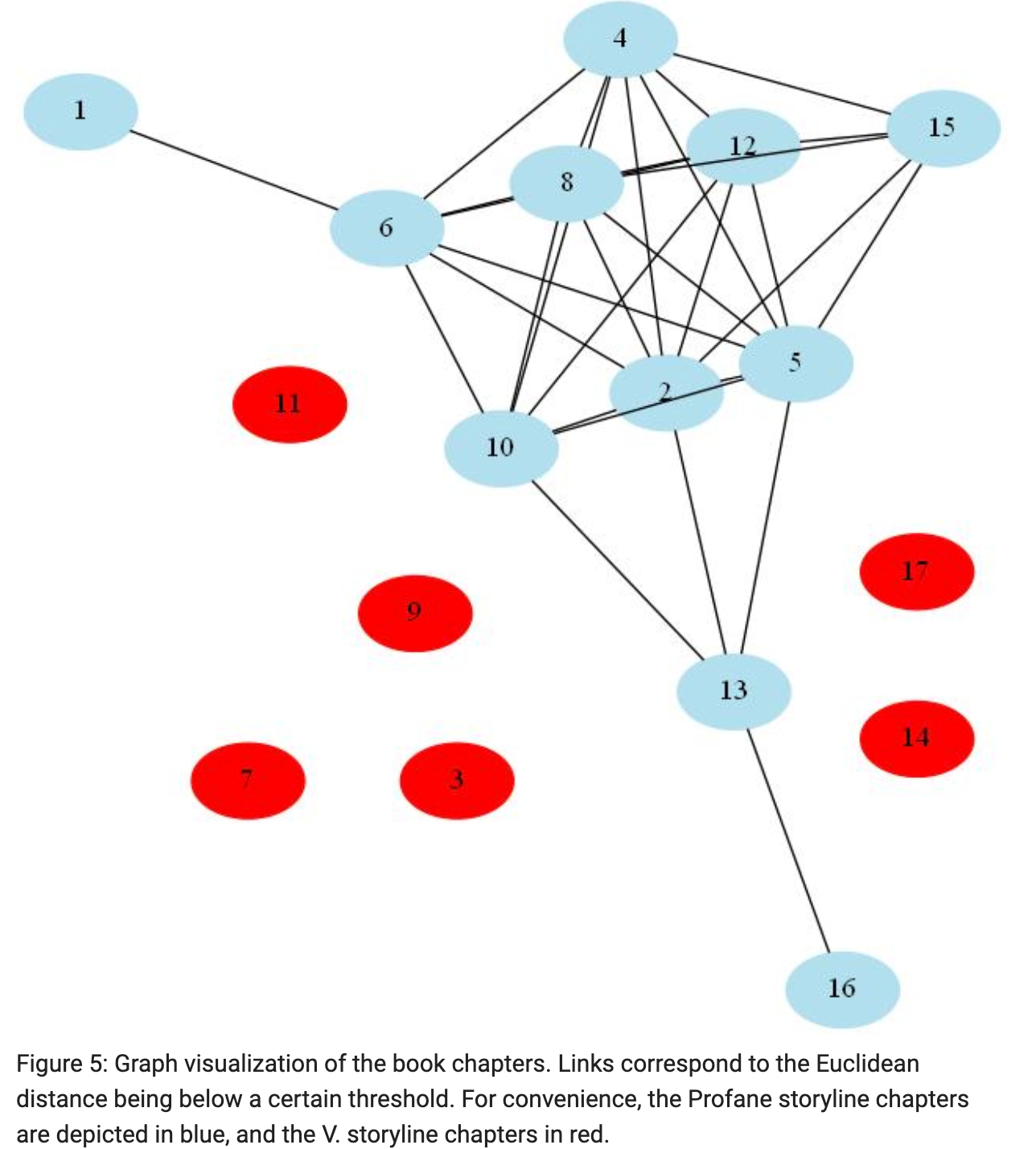
This is an incredible application of NLP to literary analysis. Tsatsoulis even mentions:
這是自然語言處理在文學分析中不可思議的應用。 Tsatsoulis甚至提到:
Somewhat to our surprise, despite this universal agreement regarding the existence of two different storylines in the novel, it seems that there has never been an attempt to exclusively map each chapter to one and only one storyline.
令我們感到驚訝的是,盡管就小說中存在兩個不同的故事情節達成了普遍共識,但似乎從未嘗試過將每一章專門映射到一個故事情節 。
Such a situation screams for the application of the tools of data science, and Tsatsoulis fantastically succeeded in applying them.
這種情況使數據科學工具的應用大為震驚,Tsatsoulis成功地應用了它們。
Why, then, given that this project was completed in 2013, has this methodology not caught on in the field of literary analysis? James Joyce himself is infamous for having said of Ulysses, to his French translator:
那么,既然這個項目于2013年完成,為什么在文學分析領域沒有采用這種方法呢? 詹姆斯·喬伊斯(James Joyce)本人對他的法語翻譯說過《尤利西斯》而臭名昭著:
I’ve put in so many enigmas and puzzles that it will keep the professors busy for centuries arguing over what I meant, and that’s the only way of insuring one’s immortality.
我已經提出了許多謎題和困惑,這將使教授們忙于幾個世紀來一直在爭論我的意思,而這是確保人們永生的唯一方法。
And indeed, professors remain busy arguing over Ulysses. I will not even discuss — for now — the ultimate enigma that is Finnegans Wake for the potential application of NLP, though it may indeed be the telos project of NLP and literature.
確實,教授們仍然忙于爭論尤利西斯。 就目前而言,我什至不會討論Finnegans Wake的終極謎團 對于NLP的潛在應用,雖然它可能確實是終極目的項目NLP和文學。
Hence, my motivation for applying a similar methodology to Ulysses is inspired by the utter success of Tsatsoulis’s project with Thomas Pynchon’s V., not just because of the literary merit provided by such an analysis, but because it demonstrates that productive cooperation between data science, or the field of precision and rigorous statistical dominance, and literary criticism, the refuge of obscurantism and impenetrable vocabulary, is possible.
因此,我之所以將類似的方法學應用于尤利西斯(Ulysses )的動機,是受Tsatsoulis與Thomas Pynchon的V.的項目的巨大成功的啟發,這不僅是因為這種分析提供了文學上的價值,而且還因為它證明了數據科學之間的富有成效的合作,或在精確和嚴格的統計控制領域,以及文學批評領域,躲避晦澀難懂的詞匯是可能的。
Look out for Part Two of this post, where I’ll actually attempt similar visualizations with the plot of Ulysses, which will hopefully align with standard interpretations of the novel.
請注意本文的第二部分,在這里我實際上將嘗試用《 尤利西斯》的情節進行類似的可視化,這有望與小說的標準解釋保持一致。
翻譯自: https://medium.com/swlh/using-nlp-to-visualize-ulysses-8a953c27aca
可視化 nlp
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/389799.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/389799.shtml 英文地址,請注明出處:http://en.pswp.cn/news/389799.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

區分'方法'和'函數'

520. 檢測大寫字母

Java 打包 FatJar 方法小結
)
常見問題及解決方案(前端篇)
)
本地搜索文件太慢怎么辦?用Everything搜索秒出結果(附安裝包)

2024. 考試的最大困擾度

小程序入口傳參:關于帶參數的小程序掃碼進入的方法

python的power bi轉換基礎
)
感想3-對于業務邏輯復用、模板復用的一些思考(未完)


2025. 分割數組的最多方案數

您是六個主要數據角色中的哪一個

命令查看linux主機配置

C#中全局處理異常方式

5911. 模擬行走機器人 II

自定義按鈕動態變化_新聞價值的變化定義
分析(轉載))
Linux記錄-TCP狀態以及(TIME_WAIT/CLOSE_WAIT)分析(轉載)


算法 從 數中選出_算法可以選出勝出的nba幻想選秀嗎
