鮮活數據數據可視化指南
Exploratory data analysis (EDA) is an essential part of the data science or the machine learning pipeline. In order to create a robust and valuable product using the data, you need to explore the data, understand the relations among variables, and the underlying structure of the data. One of the most effective tools in EDA is data visualization.
探索性數據分析(EDA)是數據科學或機器學習管道的重要組成部分。 為了使用數據創建強大而有價值的產品,您需要瀏覽數據,了解變量之間的關系以及數據的基礎結構。 數據可視化是EDA中最有效的工具之一。
Data visualizations tell us much more than plain numbers. They are also more likely to stick to your head. In this post, we will try to explore a customer churn dataset using the power of visualizations.
數據可視化告訴我們的不僅僅是單純的數字。 他們也更有可能堅持你的想法。 在本文中,我們將嘗試使用可視化功能探索客戶流失數據集 。
We will create many different visualizations and, on each one, try to introduce a feature of Matplotlib or Seaborn library.
我們將創建許多不同的可視化,并在每一個上嘗試引入Matplotlib或Seaborn庫的功能。
We start with importing related libraries and reading the dataset into a pandas dataframe.
我們首先導入相關的庫,然后將數據集讀取到pandas數據框中。
import pandas as pd
import numpy as npimport matplotlib.pyplot as plt
import seaborn as sns
sns.set(style='darkgrid')
%matplotlib inlinedf = pd.read_csv("/content/Churn_Modelling.csv")df.head()
The dataset contains 10000 customers (i.e. rows) and 14 features about the customers and their products at a bank. The goal here is to predict whether a customer will churn (i.e. exited = 1) using the provided features.
該數據集包含10000個客戶(即行)和銀行中有關客戶及其產品的14個特征。 這里的目標是使用提供的功能預測客戶是否會流失(即退出= 1)。
Let’s start with a catplot which is a categorical plot of the Seaborn library.
讓我們從貓圖開始,這是Seaborn庫的分類圖。
sns.catplot(x='Gender', y='Age', data=df, hue='Exited', height=8, aspect=1.2)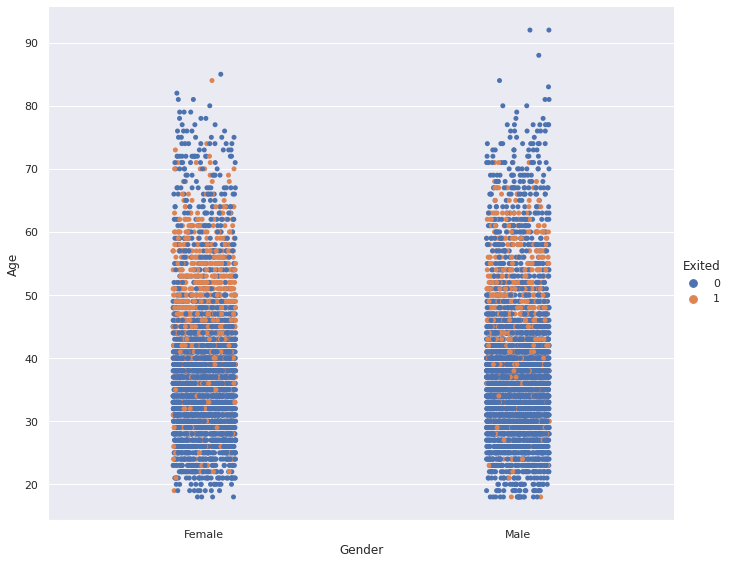
Finding: People between the ages of 45 and 60 are more likely to churn (i.e. leave the company) than other ages. There is not a considerable difference between females and males in terms of churning.
發現 :45至60歲的人比其他年齡段的人更容易流失(即離開公司)。 男性和女性在攪動方面沒有顯著差異。
The hue parameter is used to differentiate the data points based on a categorical variable.
hue參數用于基于分類變量來區分數據點。
The next visualization is the scatter plot which shows the relationship between two numerical variables. Let’s see if the estimated salary and balance of a customer are related.
下一個可視化是散點圖 ,它顯示了兩個數值變量之間的關系。 讓我們看看客戶的估計工資和余額是否相關。
plt.figure(figsize=(12,8))plt.title("Estimated Salary vs Balance", fontsize=16)sns.scatterplot(x='Balance', y='EstimatedSalary', data=df)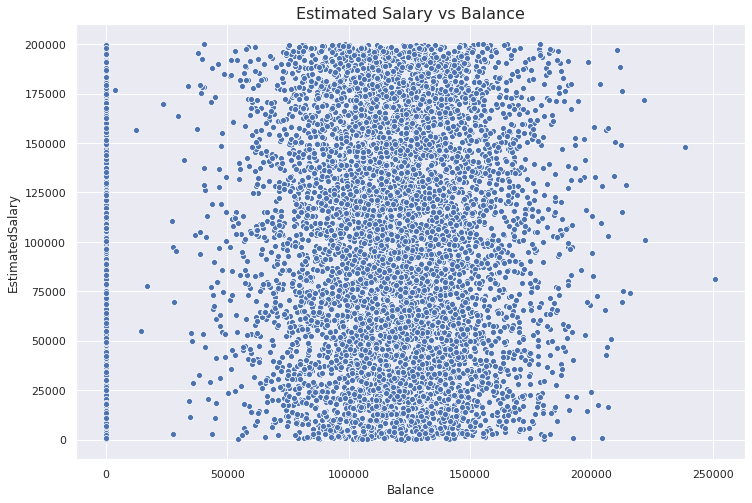
We first used matplotlib.pyplot interface to create a Figure object and set the title. Then, we drew the actual plot on this figure object with Seaborn.
我們首先使用matplotlib.pyplot接口創建一個Figure對象并設置標題。 然后,我們使用Seaborn在此圖形對象上繪制了實際圖。
Finding: There is not a meaningful relationship or correlation between the estimated salary and balance. Balance seems to have a normal distribution (excluding the customers with zero balance).
調查結果 :估計的薪水和余額之間沒有有意義的關系或相關性。 余額似乎具有正態分布(不包括余額為零的客戶)。
The next visualization is the boxplot which shows the distribution of a variable in terms of median and quartiles.
下一個可視化效果是箱線圖 ,它以中位數和四分位數的形式顯示了變量的分布。
plt.figure(figsize=(12,8))ax = sns.boxplot(x='Geography', y='Age', data=df)ax.set_xlabel("Country", fontsize=16)
ax.set_ylabel("Age", fontsize=16)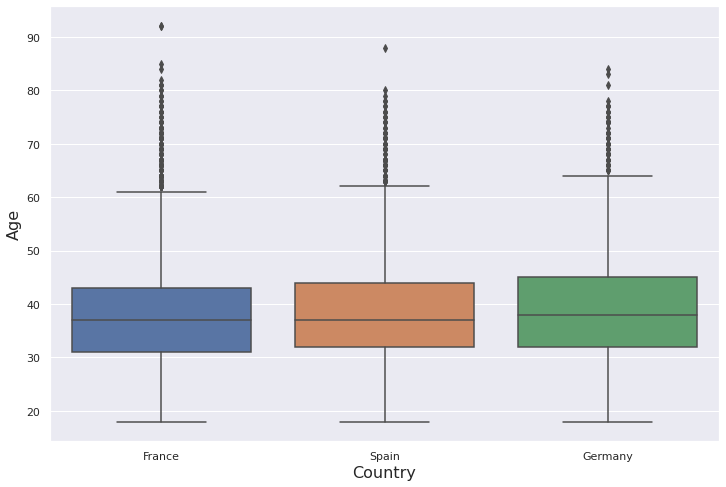
We also adjusted the font sizes of x and y axes using set_xlabel and set_ylabel.
我們還使用set_xlabel和set_ylabel調整了x和y軸的字體大小。
Here is the structure of boxplots:
這是箱線圖的結構:
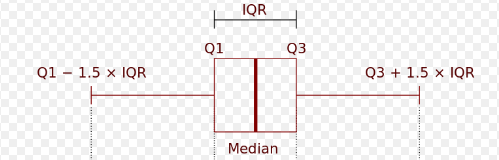
Median is the point in the middle when all points are sorted. Q1 (first or lower quartile) is the median of the lower half of the dataset. Q3 (third or upper quartile) is the median of the upper half of the dataset.
中點是對所有點進行排序時中間的點。 Q1(第一個或下一個四分位數)是數據集下半部分的中位數。 Q3(第三或上四分位數)是數據集上半部分的中位數。
Thus, boxplots give us an idea about the distribution and outliers. In the boxplot we created, there are many outliers (represented with dots) on top.
因此,箱線圖使我們對分布和異常值有了一個了解。 在我們創建的箱線圖中,頂部有許多離群值(以點表示)。
Finding: The distribution of the age variable is right-skewed. The mean is greater than the median due to the outliers on the upper side. There is not a considerable difference between countries.
結果 :年齡變量的分布右偏。 由于上側的異常值,平均值大于中位數。 各國之間沒有顯著差異。
Right-skewness can also be observed in the univariate distribution of a variable. Let’s create a distplot to observe the distribution.
右偏度也可以在變量的單變量分布中觀察到。 讓我們創建一個distplot來觀察分布。
plt.figure(figsize=(12,8))plt.title("Distribution of Age", fontsize=16)sns.distplot(df['Age'], hist=False)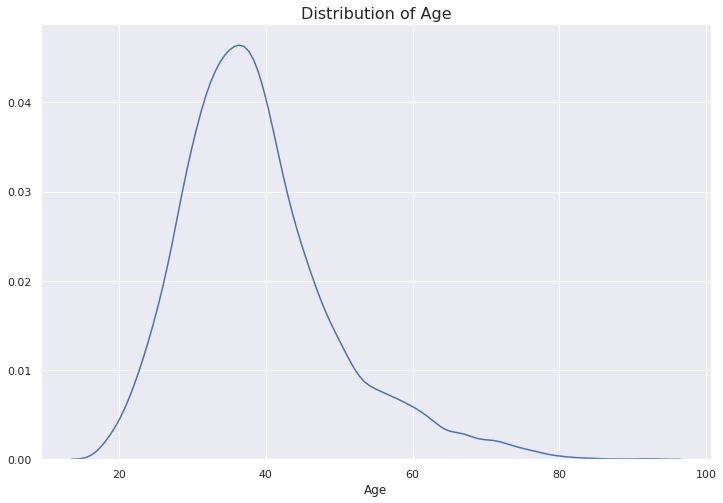
The tail on the right side is heavier than the one on the left. The reason is the outliers as we also observed on the boxplot.
右側的尾巴比左側的尾巴重。 原因是離群值,正如我們在箱線圖上所觀察到的。
The distplot also provides a histogram by default but we changed it using the hist parameter.
默認情況下,distplot還提供直方圖,但我們使用hist參數對其進行了更改。
Seaborn library also provides different types of pair plots which give an overview of pairwise relationships among variables. Let’s first take a random sample from our dataset to make the plots more appealing. The original dataset has 10000 observations and we will take a sample with 100 observations and 4 features.
Seaborn庫還提供了不同類型的成對圖,概述了變量之間的成對關系。 首先,我們從數據集中隨機抽取一個樣本,使圖更具吸引力。 原始數據集具有10000個觀測值,我們將抽取一個具有100個觀測值和4個特征的樣本。
subset=df[['CreditScore','Age','Balance','EstimatedSalary']].sample(n=100)g = sns.pairplot(subset, height=2.5)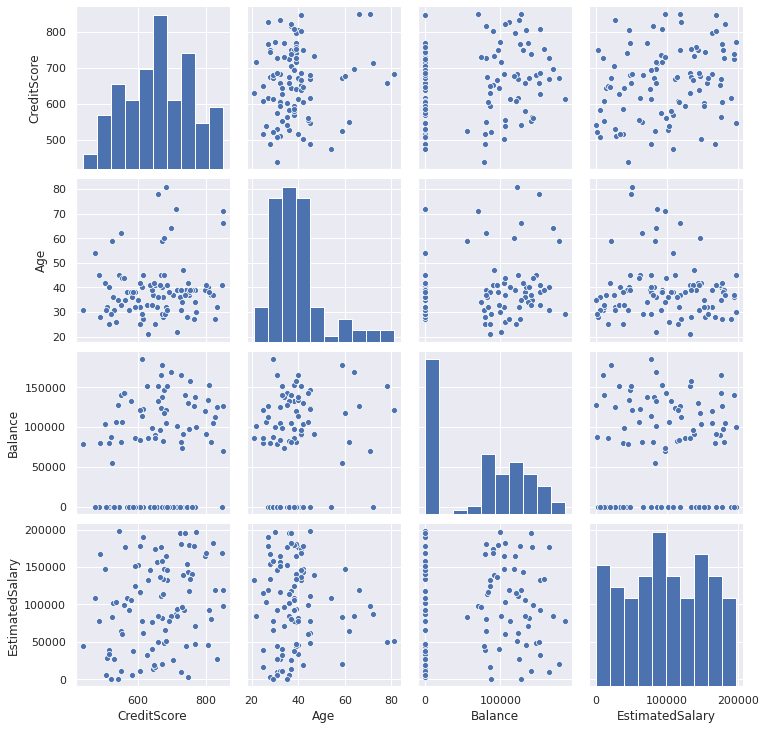
On the diagonal, we can see the histogram of variables. The other part of the grid represents pairwise relationships.
在對角線上,我們可以看到變量的直方圖。 網格的另一部分表示成對關系。
Another tool to observe pairwise relationships is the heatmap which takes a matrix and produces a color encoded plot. Heatmaps are mostly used to check correlations between features and the target variable.
觀察成對關系的另一個工具是熱圖 ,它采用矩陣并生成彩色編碼圖。 熱圖通常用于檢查要素與目標變量之間的相關性。
Let’s first create a correlation matrix of some features using the corr function of pandas.
首先,我們使用熊貓的corr函數創建一些要素的相關矩陣。
corr_matrix = df[['CreditScore','Age','Tenure','Balance',
'EstimatedSalary','Exited']].corr()We can now plot this matrix.
現在我們可以繪制該矩陣。
plt.figure(figsize=(12,8))sns.heatmap(corr_matrix, cmap='Blues_r', annot=True)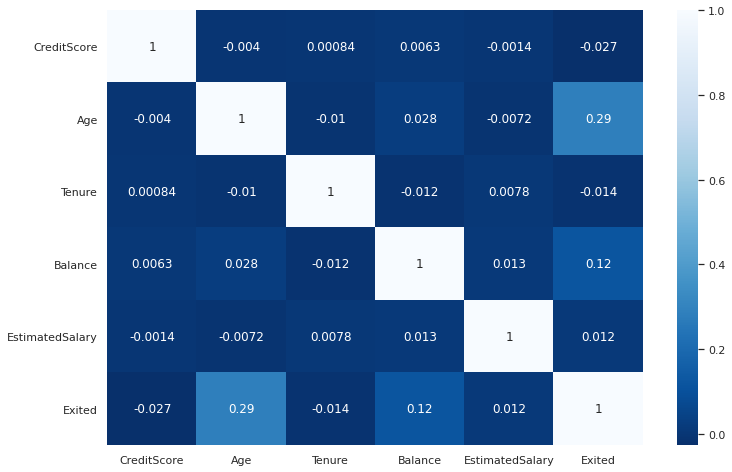
Finding: The “Age” and “Balance” columns are positively correlated with customer churn (“Exited”).
結果 :“年齡”和“平衡”列與客戶流失(“退出”)呈正相關。
As the amount of data increases, it gets trickier to analyze and explore it. There comes the power of visualizations which are great tools in exploratory data analysis when used efficiently and appropriately. Visualizations also help to deliver a message to your audience or inform them about your findings.
隨著數據量的增加,分析和探索數據變得更加棘手。 可視化的強大功能是有效和適當使用探索性數據分析的重要工具。 可視化還有助于向您的聽眾傳達信息或告知他們您的發現。
There is no one-fits-all kind of visualization method so certain tasks require different kinds of visualizations. Depending on the task, different options may be more suitable. What all visualizations have in common is that they are great tools for exploratory data analysis and the storytelling part of data science.
沒有一種萬能的可視化方法,因此某些任務需要不同類型的可視化。 根據任務,不同的選項可能更合適。 所有可視化的共同點在于,它們是探索性數據分析和數據科學講故事部分的出色工具。
Thank you for reading. Please let me know if you have any feedback.
感謝您的閱讀。 如果您有任何反饋意見,請告訴我。
翻譯自: https://towardsdatascience.com/a-practical-guide-for-data-visualization-9f1a87c0a4c2
鮮活數據數據可視化指南
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/389811.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/389811.shtml 英文地址,請注明出處:http://en.pswp.cn/news/389811.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

2049. 統計最高分的節點數目

Linux lsof命令詳解

史密斯臥推:杠鈴史密斯下斜臥推、上斜機臥推、平板臥推動作圖解

圖像特征 可視化_使用衛星圖像可視化建筑區域

ELK入門01—Elasticsearch安裝

375. 猜數字大小 II

hdu_2048 錯排問題

海量數據尋找最頻繁的數據_在數據中尋找什么

OSChina 周四亂彈 —— 要成立復仇者聯盟了,來報名

2023. 連接后等于目標字符串的字符串對
)
webapi 找到了與請求匹配的多個操作(ajax報500,4的錯誤)

可視化 nlp_使用nlp可視化尤利西斯

區分'方法'和'函數'

520. 檢測大寫字母

Java 打包 FatJar 方法小結
)
常見問題及解決方案(前端篇)
)
本地搜索文件太慢怎么辦?用Everything搜索秒出結果(附安裝包)

2024. 考試的最大困擾度

小程序入口傳參:關于帶參數的小程序掃碼進入的方法
