時間序列數據的多元回歸
No matter what kind of data science project one is assigned to, making sense of the dataset and cleaning it always critical for success. The first step is to understand the data using exploratory data analysis (EDA)as it helps us create the logical approach for solving the business problem. It also allows us to identify the issues like outliers existing in our dataset.
無論分配給什么樣的數據科學項目,理解數據集并清理它對于成功都是至關重要的。 第一步是使用探索性數據分析(EDA)來理解數據,因為它有助于我們創建解決業務問題的邏輯方法。 它還使我們能夠識別數據集中存在的異常值之類的問題。
It is necessary to clean up these issues before starting any analysis because if our data is spewing garbage, so will our analysis. Moreover, the insights from such an analysis won’t tie up with the theoretical or business knowledge of our clients and they may lose confidence in our work.Even if the clients end up making a decision based on such an analysis but the end result will turn out to be wrong and we will be in a lot of trouble! Thus, how well we clean and understand the data has a tremendous impact on the quality of the results.
在開始任何分析之前,有必要清理這些問題,因為如果我們的數據冒出垃圾,我們的分析也將如此。 此外,這種分析的見解不會與客戶的理論或業務知識相結合,他們可能會對我們的工作失去信心,即使客戶最終根據這樣的分析做出決定,但最終結果也會原來是錯的,我們會遇到很多麻煩! 因此,我們清理和理解數據的質量對結果的質量有很大的影響。
Things get slightly more complicated when we deal with datasets having hidden properties like time series datasets. Time series datasets is a special type of data which is ordered chronologically and needs special attention for handling it’s intrinsic elements like trend and seasonality.
當我們處理具有隱藏屬性(例如時間序列數據集)的數據集時,事情會變得稍微復雜一些。 時間序列數據集是一種特殊的數據類型,按時間順序排序,在處理其諸如趨勢和季節性之類的內在要素時需要特別注意。
For these reasons, We will be focusing on a step-by-step guideline that walks through the EDA and data cleaning process one can follow while working with multivariate time series data.
由于這些原因,我們將重點關注逐步指南,該指南逐步介紹了在處理多元時間序列數據時可以遵循的EDA和數據清理過程。
指數: (Index:)
- Understanding time series data — The Theory 了解時間序列數據-理論
- EDA (inspection, data profiling, visualizations) EDA(檢查,數據分析,可視化)
- Data Cleaning (missing data, outlier detection and treatment) 數據清理(丟失數據,異常檢測和處理)
- Final words 最后的話
了解時間序列數據-理論 (Understanding time series data — The Theory)
One of the best freely available sources to learn about time series analysis is the book ‘Forecasting Principles and Practices’ by Rob J Hyndman and George Athanasopoulos. Both of them are professors at Monash University, Australia and Rob was Editor-in-Chief of the International Journal of Forecasting and a Director of the International Institute of Forecasters from 2005 to 2018. I am going to summarize some of the basic elements of a time series dataset here and for further details, please refer to the mentioned book.
Rob J Hyndman和George Athanasopoulos所著的“ 預測原理和實踐 ”一書是學習時間序列分析的最佳免費資源之一。 他們都是澳大利亞莫納什大學(Monash University)的教授,羅布(Rob)是2005年至2018年《 國際 預測》雜志的主編和國際預測協會的主任。我將總結一下時間序列數據集,有關更多詳細信息,請參閱上述書籍。
時間序列數據的元素 (Elements of Time Series Data)
A time series data can be considered a list of numbers, along with information about when those numbers were recorded.Most commonly, a time series is a sequence taken at successive equally spaced points in time.Time series data is composed of four elements:
時間序列數據可以看作是一個數字列表以及有關記錄這些數字的時間的信息。最常見的是,時間序列是在連續的等間隔時間點上獲取的序列。時間序列數據由四個元素組成:

Decomposition techniques help us extract trend, seasonality and error/irregular components of a time series dataset. There are multiple decomposition techniques but we will be focusing on the additive method in this blog in the EDA section.
分解技術可幫助我們提取時間序列數據集的趨勢,季節性和誤差/不規則分量。 有多種分解技術,但在本博客的EDA部分中,我們將重點介紹加法。
平穩性 (Stationarity)
In the most intuitive sense, a stationary time series is one whose properties do not depend on the time at which the series is observed. Thus, time series with trends, or with seasonality, are not stationary — the trend and seasonality will affect the value of the time series at different times.
從最直觀的意義上說,固定時間序列是一個其屬性不依賴于觀察該時間的時間的序列。 因此,具有趨勢或季節性的時間序列不是固定的-趨勢和季節性將影響不同時間的時間序列的值。
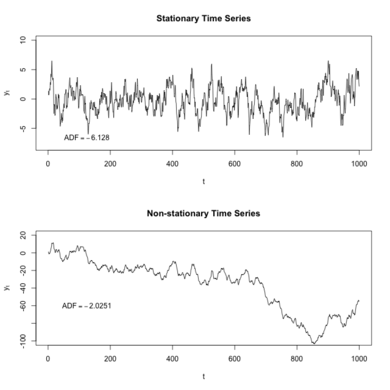
Why is this property important? Stationary processes are easier to model as the way they change is predictable and stable. For most models involving time series, we will find ourselves determining if the data was generated by a stationary process, and if not, then we possibly need to transform it so it has the properties generated by such a process.
為什么這個屬性很重要? 平穩過程更容易模型,因為他們改變的方式是可以預見的,穩定的。 對于大多數涉及時間序列的模型,我們將發現自己確定數據是否是由固定過程生成的,如果不是,則可能需要對其進行轉換,使其具有由該過程生成的屬性。
ACF和PACF (ACF and PACF)
Autocorrelation (ACF) and partial autocorrelation (PACF) plots are heavily used to determine stationarity and time series model parameters.These plots graphically summarize the strength of a relationship with an observation in a time series with observations at prior time steps.
自相關(ACF)和局部自相關(PACF)圖被大量用于確定平穩性和時間序列模型參數,這些圖以圖形方式總結了時間序列中與觀測值的關系強度以及先前時間步長的觀測值。
For ACF plots, we calculate the correlation for time series observations with observations with previous time steps, called lags. The PACF plot is a summary of the relationship between an observation in a time series with observations at prior time steps with the relationships of intervening observations removed. Such time plots for a stationary process will have start having statistically insignificant values within the first few lags.
對于ACF圖,我們計算時間序列觀測值與具有先前時間步長的觀測值(稱為滯后)的相關性。 PACF圖是時間序列中的觀測值與先前時間步長的觀測值之間的關系的摘要,其中刪除了中間觀測值的關系。 固定過程的此類時間圖將在頭幾個滯后內開始具有統計上無關緊要的值。
EDA(檢查,數據分析,可視化) (EDA (inspection, data profiling, visualizations))
To share my understanding of the common concepts and techniques on EDA, we will work on the multivariate time series dataset on Hong Kong flat prices along with various macro economics variables. It is a daily dataset starting from 2nd January 2003 and goes on till 26th November 2019. The dataset is available in Kaggle.
為了分享我對EDA的通用概念和技術的理解,我們將研究香港統一價格的多元時間序列數據集以及各種宏觀經濟變量。 它是一個每日數據集,從2003年1月2日開始,一直持續到2019年11月26日。該數據集可在Kaggle中獲得 。
To begin with, we imported necessary python libraries (for this example pandas, numpy,matplotlib etc) and loaded the data set.
首先,我們導入了必要的python庫(例如pandas,numpy,matplotlib等)并加載了數據集。
查看數據并檢查字段類型 (Looking at the data and checking field types)

- To take a closer look at the data, used “ .head()”function of pandas library which returns first five observations of the data. Similarly “.tail()” returns last five observations of the data set. 為了更仔細地查看數據,使用了熊貓庫的“ .head()”函數,該函數返回數據的前五個觀察值。 同樣,“。tail()”返回數據集的最后五個觀察值。
- We found out the total number of rows and columns in the data set and data type of each column using “.info” function.Dataset comprises of 4233 observations and 14 columns. All the columns have the correct data format (Date is in datetime format and the rest are float). None of the columns have any null values 我們使用“ .info”函數找出數據集中的行和列總數以及每一列的數據類型。數據集包含4233個觀察值和14列。 所有列均具有正確的數據格式(日期為日期時間格式,其余為浮點型)。 所有列均無空值
獲取摘要統計 (Get summary statistics)
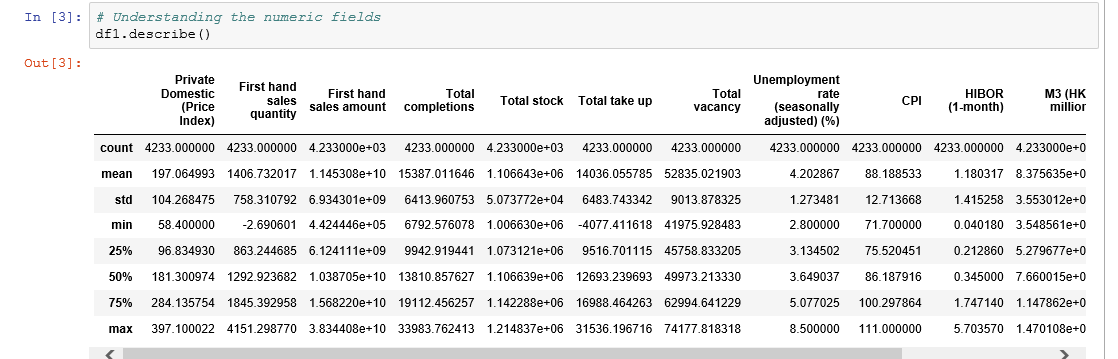
- Here as you can notice mean value is more than median value of most columns which is represented by 50%(50th percentile) in index column. 在這里您可以注意到,平均值大于大多數列的中位數,這由索引列中的50%(第50個百分位數)表示。
- There is notably a big difference between 75th percentile and max values of certain fields like “First hand sales quantity”,”First hand sales amount”,”Total completions” etc. 第75個百分位數與某些字段(例如“第一手銷售數量”,“第一手銷售數量”,“完成總數”等)的最大值之間存在很大差異。
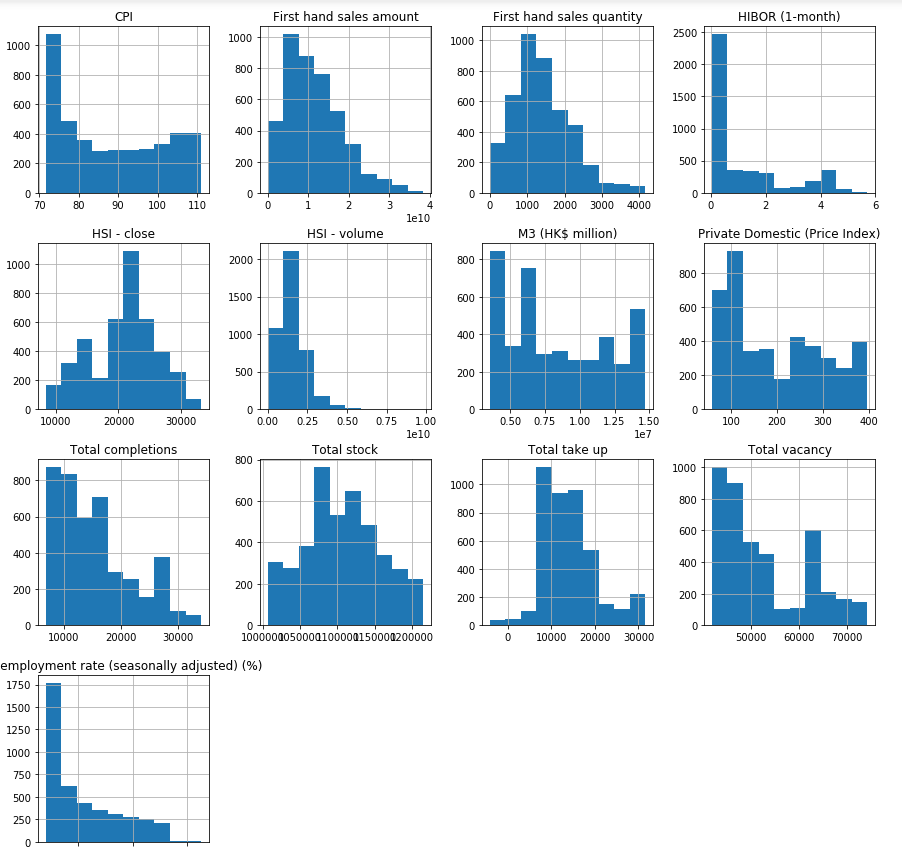
- Thus observations 1 and 2 suggests that there are extreme values-Outliers in our data set. We get the same conclusion once we look at the histograms of all the numeric fields. 因此,觀察值1和2表明在我們的數據集中存在極值-離群值。 查看所有數字字段的直方圖,我們將得出相同的結論。
檢查目標變量的時間序列屬性 (Checking time series properties of target variable)
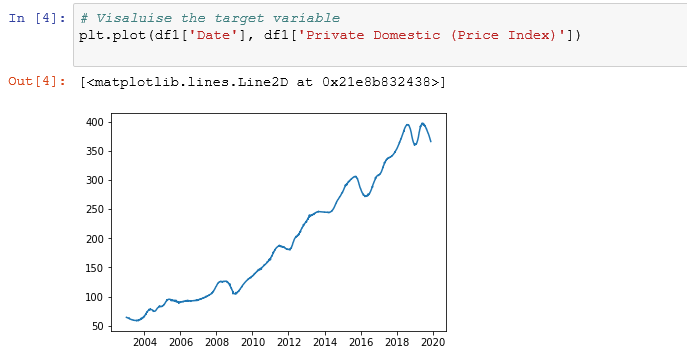
- Target variable/Dependent variable (‘Private Domestic (Price Index)’)has a rising trend 目標變量/因變量(“國內私有(價格指數)”)呈上升趨勢
- There is a seasonal dip in most years. 大多數年份都有季節性下降。
- The variation in 2020 are extreme compared to overall trend 與整體趨勢相比,2020年的變化是極端的
- The target variable is not stationary 目標變量不是固定的
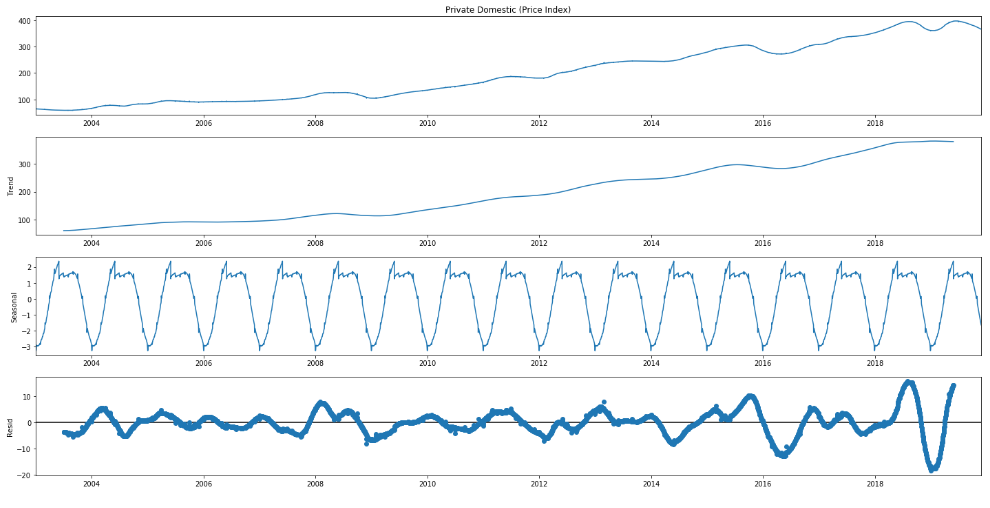
We have used the additive model for decomposition which assumes that the time series data is structured in the following manner:
我們已使用加法模型進行分解,該模型假定時間序列數據的結構如下:
Time Series Data = Trend + Seasonal + Random
時間序列數據=趨勢+季節性+隨機
- We can observe that the seasonal pattern is a regularly repeating pattern and that the trend is upward sloping but it is not a smooth line. 我們可以觀察到,季節性模式是有規律的重復模式,并且趨勢呈向上傾斜,但不是一條平滑線。
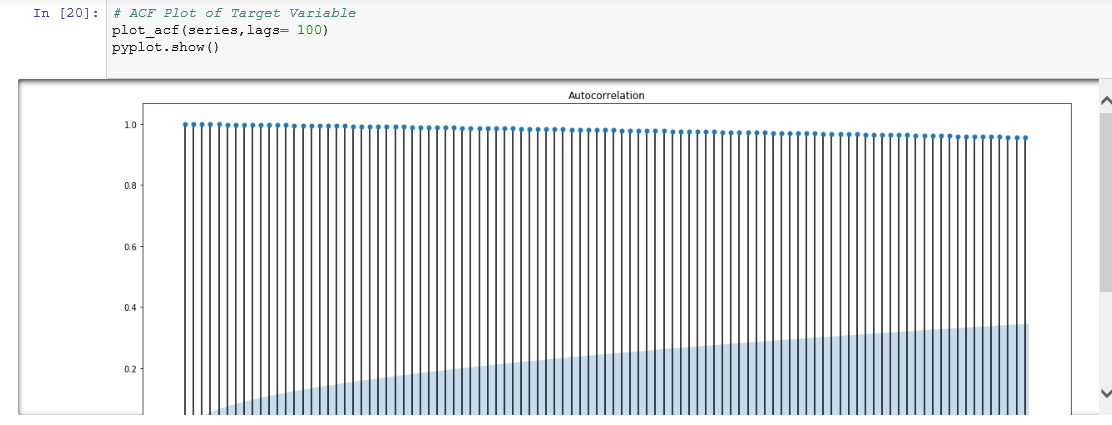
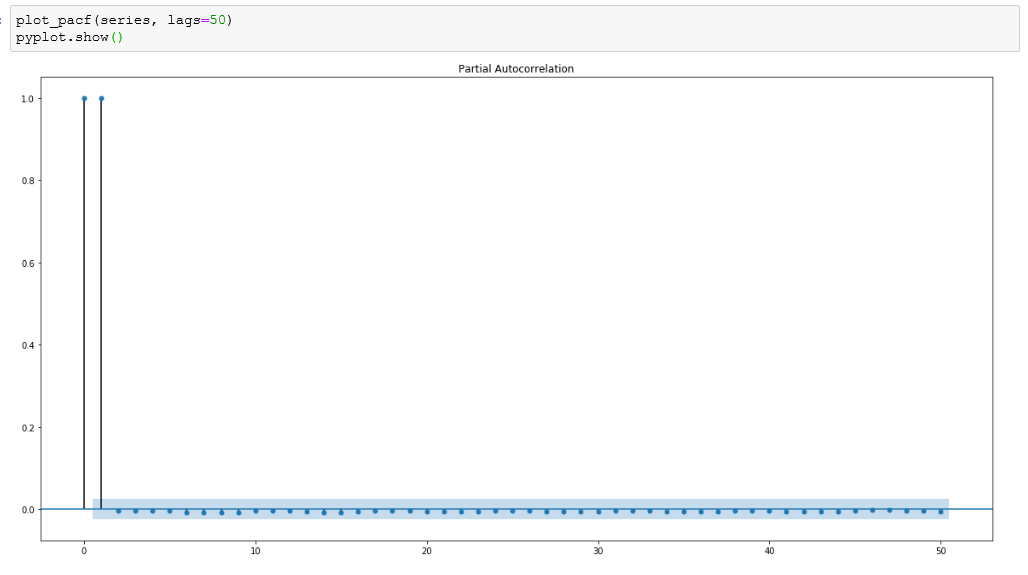
- The dataset is highly non-stationary as can be seen from the ACF and PACF plots. 從ACF和PACF圖可以看出,該數據集非常不穩定。
數據清理(丟失數據,異常值檢測和處理) (Data Cleaning (missing data , outliers detection and treatment))
Data cleaning is the process of identifying and correcting inaccurate records from a dataset along with recognising unreliable or irrelevant parts of the data. We will be focusing on handling missing data and outliers in this blog.
數據清理是從數據集中識別和糾正不正確記錄的過程,同時還要識別數據中不可靠或不相關的部分。 在此博客中,我們將專注于處理丟失的數據和異常值。
缺失數據 (Missing Data)
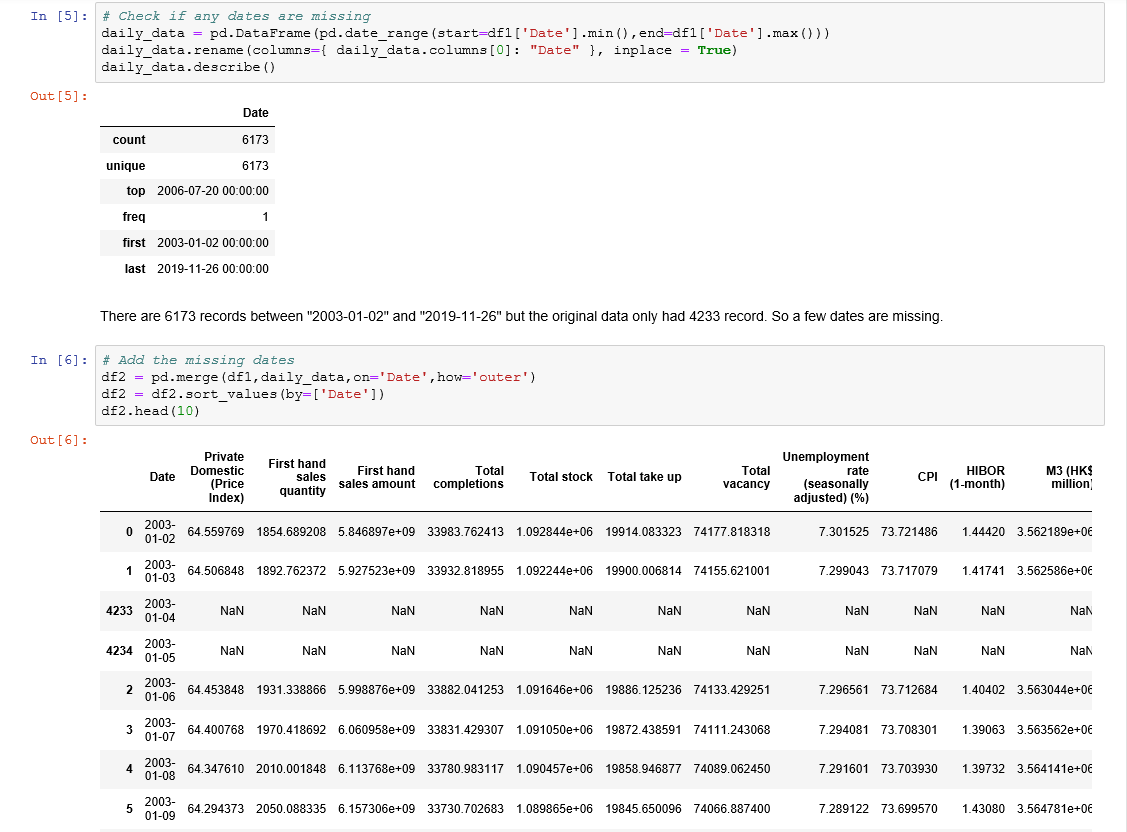
- Our raw data starts from “2003–01–02” and ends at “2019–11–26”. There are 6173 days between “2003–01–02” and “2019–11–26” but the original data only had 4233 record. So a few dates are missing. 我們的原始數據從“ 2003-01-02”開始,到“ 2019-11-26”結束。 從“ 2003-01-02”到“ 2019-11-26”之間有6173天,但是原始數據只有4233條記錄。 因此缺少一些日期。
- We create a new dataset with all the 6173 dates and join the original dataset with this new dataset. This leads to null values for all the record not available in the original dataset. 我們使用所有6173個日期創建一個新數據集,并將原始數據集與此新數據集連接。 這將導致原始數據集中不可用的所有記錄的空值。
- We use linear interpolation to fill in the null values 我們使用線性插值來填充空值
離群值檢測 (Outlier detection)
Wikipedia definition,
維基百科的定義,
In statistics, an outlier is an observation point that is distant from other observations.
在統計中, 離群 點是與其他觀測值相距較遠的觀測點。
To ease the discovery of outliers, we have plenty of methods in statistics, but we will only be discussing few basic techniques (interquartile range, standard deviation) here. In a separate blog, I will be focusing on the advanced methods.
為了簡化離群值的發現,我們在統計數據中提供了很多方法,但是在這里我們將只討論一些基本技術(四分位間距,標準差)。 在另一個博客中,我將重點介紹高級方法。

The Interquartile range (IQR) is calculated as the difference between the 75th and the 25th percentiles of the data.The IQR can be used to identify outliers by defining limits on the sample values that are a factor k of the IQR below the 25th percentile or above the 75th percentile. The common value for the factor k is the value 1.5 (which we have used here). A factor k of 3 or more can be used to identify values that are extreme outliers or “far outs”.
四分位間距(IQR)由數據的第75個百分位數和第25個百分位數之間的差計算得出.IQR可以通過定義樣本值的限制來識別異常值,這些樣本值是IQR的第25個百分位數以下的因數k或高于第75個百分點。 因子k的公共值為1.5(我們在這里使用)。 3或更大的系數k可用于識別極端離群值或“ 遠距 ”值。
- For the initial values, fields like ‘Total Completion’ have a lot of outliers. 對于初始值,“總計完成”之類的字段有很多異常值。
- If we know that the distribution of values in the sample is Gaussian or Gaussian-like, we can use the standard deviation of the sample as a cut-off for identifying outliers.Three standard deviations from the mean is a common cut-off in practice for identifying outliers in a Gaussian or Gaussian-like distribution. For smaller samples of data, perhaps a value of 2 standard deviations (95%) can be used, and for larger samples, perhaps a value of 4 standard deviations (99.9%) can be used. 如果我們知道樣本中值的分布是高斯或類高斯分布,則可以使用樣本的標準偏差作為識別異常值的分界點。與平均值的三個標準差是實踐中的常見分界點用于識別高斯或高斯分布中的離群值。 對于較小的數據樣本,也許可以使用2個標準偏差(95%)的值,對于較大的樣本,也許可以使用4個標準偏差(99.9%)的值。
離群值處理 (Outlier treatment)

- All the identified outliers are replaced by nulls first. 首先將所有標識的異常值替換為零。
- Then the nulls are filled by linear interpolation. In a separate blog, a more robust approach to replace outliers will be discussed. 然后,通過線性插值填充零點。 在單獨的博客中,將討論一種更健壯的方法來替換異常值。
最后的話 (Final Words)
I hope this blog helps the readers make sense of their datasets as well handle some of the issues with messy data. Apart from the that, the readers should now be able to understand the basic elements of a time series dataset as well. But it is important to understand that each dataset comes has its own unique challenges and will need a customized approach to make the data usable.
我希望這個博客可以幫助讀者理解他們的數據集,并解決一些數據混亂的問題。 除此之外,讀者現在還應該能夠理解時間序列數據集的基本元素。 但重要的是要了解,每個數據集都有其獨特的挑戰,并且需要一種定制的方法來使數據可用。
These are some of the questions one should always ask while working with a new dataset:
這些是在使用新數據集時應始終提出的一些問題:
How the data is collected, and under what conditions?
如何收集數據,在什么條件下收集數據?
What does the data represent?
數據代表什么?
What are the issues in the dataset? Are there any outliers?
數據集中有什么問題? 有離群值嗎?
What methods should be used to clean the data and why?
應該使用什么方法清除數據,為什么?
This is a first blog in a series focused on creating a robust forecasting engine based on a multivariate time series data. The next blog will focus on feature engineering and selection. Stay tuned!
這是該系列中的第一個博客,致力于基于多元時間序列數據創建強大的預測引擎。 下一個博客將重點介紹功能設計和選擇。 敬請關注!
翻譯自: https://medium.com/@indraneeldb1993ds/cleaning-and-understanding-multivariate-time-series-data-6554eefbda9c
時間序列數據的多元回歸
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/389760.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/389760.shtml 英文地址,請注明出處:http://en.pswp.cn/news/389760.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

vue-cli搭建項目的目錄結構及說明


bigquery 教程_bigquery挑戰實驗室教程從數據中獲取見解

學習linux系統到底有沒捷徑?

機器學習之路:python k近鄰回歸 預測波士頓房價
)

wxpython實現界面跳轉

java職業技能了解精通_如何通過精通數字分析來提升職業生涯的發展,第8部分...

2028. 找出缺失的觀測數據

51nod 1250 排列與交換——dp
![BZOJ.1024.[SCOI2009]生日快樂(記憶化搜索)](http://pic.xiahunao.cn/BZOJ.1024.[SCOI2009]生日快樂(記憶化搜索))
BZOJ.1024.[SCOI2009]生日快樂(記憶化搜索)

kfc流程管理炸薯條幾秒_炸薯條成為數據科學的最后前沿



2027. 轉換字符串的最少操作次數

bigquery_到Google bigquery的sql查詢模板,它將您的報告提升到另一個層次

分類樹/裝袋法/隨機森林算法的R語言實現

數據科學學習心得_學習數據科學時如何保持動力

用php當作cat使用
