pd種知道每個數據的類型
意見 (Opinion)
目錄 (Table of Contents)
- Introduction 介紹
- Multicollinearity 多重共線性
- One-Hot Encoding 一站式編碼
- Sampling 采樣
- Error Metrics 錯誤指標
- Storytelling 評書
- Summary 摘要
介紹 (Introduction)
I have written about common skills that Data Scientists can expect to use in their professional careers, so now I want to highlight some key concepts of Data Science that can be beneficial to know and later employ. I may be discussing some that you know already, and some that you do not know; my goal is to provide some professional explanation of why these concepts are beneficial regardless of what you do know now. Multicollinearity, one-hot encoding, undersampling and oversampling, error metrics, and lastly, storytelling, are the key concepts I think of first when thinking of a professional Data Scientist in their day-to-day. The last point, perhaps, is a combination of skill and a concept but wanted to highlight, still, its importance on your everyday work life as a Data Scientist. I will expound upon all of these concepts down below.
我已經寫了關于數據科學家可以在其職業生涯中期望使用的常見技能的文章,所以現在我想重點介紹一些數據科學的關鍵概念,這些知識可能有益于知識并在以后使用。 我可能正在討論您已經知道的一些,以及您不知道的一些。 我的目標是提供一些專業的解釋,說明無論您現在知道什么,這些概念為何都是有益的。 多重共線性,單次編碼,欠采樣和過采樣,錯誤度量,以及講故事,是我每天在考慮專業數據科學家時首先想到的關鍵概念。 最后一點也許是技巧和概念的結合,但仍然想強調它對您作為數據科學家的日常工作的重要性。 我將在下面詳細說明所有這些概念。
多重共線性 (Multicollinearity)

Although the word is somewhat long and hard to say, when you break it down, multicollinearity is simple. Multi meaning many, and collinearity meaning linearly related. Multicollinearity can be described as the situation when two or more explanatory variables explain similar information or are highly related in a regression model. There are a few reasons this concept can raise a concern.
盡管這個詞有點長且很難說,但將其分解時,多重共線性很簡單。 多含義很多,共線性含義線性相關。 多重共線性可以描述為當兩個或多個解釋變量解釋相似信息或在回歸模型中高度相關時的情況。 此概念引起關注的原因有幾個。
For some modeling techniques, it can cause overfitting and ultimately a decline in model performance.
對于某些建模技術,它可能導致過度擬合并最終導致模型性能下降。
The data becomes redundant and not each feature or attribute is needed in your model. Therefore, there are some ways to find out which features you should remove that constitute multicollinearity.
數據變得多余,并且模型中不需要每個功能或屬性。 因此,有一些方法可以找出應刪除構成多重共線性的特征。
variance inflation factor (VIF)
方差膨脹因子(VIF)
correlation matrices
相關矩陣
These two techniques are commonly used amongst Data Scientists, especially correlation matrices and plots — usually visualized with a heatmap of some sort, while VIF is lesser-known.
數據科學家通常使用這兩種技術,尤其是相關矩陣和圖-通常以某種形式的熱圖可視化,而VIF則鮮為人知。
The higher the VIF value, the less usable the feature is for your regression model.
VIF值越高,該功能對您的回歸模型的使用就越少。
A great, simple resource for VIF is [3]:
VIF的一個很好的簡單資源是[3]:
一站式編碼 (One-Hot Encoding)
This form of feature transformation in your model is called one-hot encoding. You want to represent your categorical features numerically by encoding them. Whereas the categorical features have text values themselves, one-hot encoding transposes that information so that each value becomes the feature and the observation in the row is either denoted as a 0 or 1. For example, if we have the categorical variable gender, the numerical representation after one-hot encoding would look like (gender before, and male/female after):
模型中這種形式的特征轉換稱為單次編碼。 您想通過編碼來以數字方式表示分類特征。 盡管分類要素本身具有文本值,但是一鍵編碼會轉置該信息,以便每個值都成為要素,并且該行中的觀察值將表示為0或1。例如,如果我們擁有分類變量sex ,則一鍵編碼后的數字表示看起來像( 性別之前和之后的男性/女性 ):
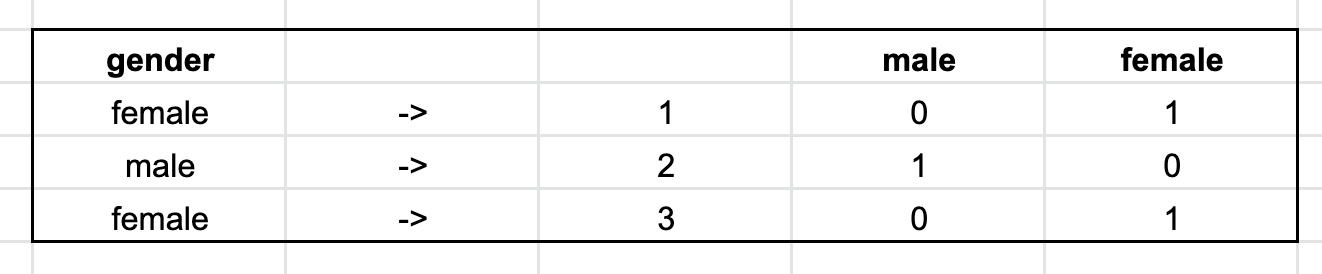
This transformation is useful when you are not just working with numerical features, and need to create that numerical representation with text/categorical features.
當您不僅要使用數字功能并且需要使用文本/分類功能創建該數字表示形式時,此轉換非常有用。
采樣 (Sampling)
When you do not have enough data, oversampling may be suggested as a form of compensation. Say you are working on a classification problem and you have a minority class like the example down below:
當您沒有足夠的數據時,建議使用過采樣作為補償。 假設您正在處理分類問題,并且有一個少數類,如下例所示:
class_1 = 100 rowsclass_2 = 1000 rowsclass_3 = 1100 rowsAs you can see, class_1 has a small amount of data for its class, which means your dataset is imbalanced and will be referred to as the minority class. There are several oversampling techniques. One of them is called SMOTE [5], which stands for Synthetic Minority Over-sampling Technique. One of the ways that SMOTE works is by utilizing a K-neighbor method for finding the nearest neighbor to create synthetic samples. There are similar techniques that use the reverse method for undersampling.
如您所見, class_1的類中包含少量數據,這意味著您的數據集不平衡,將被稱為少數類。 有幾種過采樣技術。 其中之一稱為SMOTE [5],代表合成少數族裔過采樣技術 。 SMOTE工作的方法之一是利用K鄰域方法來找到最接近的鄰域以創建合成樣本。 有類似的技術使用反向方法進行欠采樣 。
These techniques are beneficial when you have outliers in your class or regression data even, and you want to ensure your sampling is the best representation of the data that your model will run on in the future.
當您的類或回歸數據中甚至有異常值時,并且您要確保采樣是模型將在將來運行的數據的最佳表示形式時,這些技術將非常有用。
錯誤指標 (Error Metrics)
There are plenty of error metrics used for both classification and regression models in Data Science. According to sklearn [6], here are some that you can use specifically for regression models:
在數據科學中,分類和回歸模型都有大量錯誤度量標準。 根據sklearn [6],以下是您可以專門用于回歸模型的一些信息:
metrics.explained_variance_score
metrics.explained_variance_score
metrics.max_error
metrics.max_error
metrics.mean_absolute_error
metrics.mean_absolute_error
metrics.mean_squared_error
metrics.mean_squared_error
metrics.mean_squared_log_error
metrics.mean_squared_log_error
metrics.median_absolute_error
metrics.median_absolute_error
metrics.r2_score
metrics.r2_score
metrics.mean_poisson_deviance
metrics.mean_poisson_deviance
metrics.mean_gamma_deviance
metrics.mean_gamma_deviance
The two most popular error metrics for regression from above are MSE and RMSE:
從上方進行回歸分析的兩個最受歡迎的錯誤度量標準是MSE和RMSE:
MSE: the concept is → mean absolute error regression loss (sklearn)
MSE:概念是→平均絕對誤差回歸損失(sklearn)
RMSE: the concept is → mean squared error regression loss (sklearn)
RMSE:概念是→均方誤差回歸損失(sklearn)
For classification, you can expect to evaluate your model’s performance with accuracy and AUC (Area Under the Curve).
對于分類,您可以期望以準確性和AUC(曲線下面積)評估模型的性能。
評書 (Storytelling)

I wanted to add a unique concept of Data Science that is storytelling. I cannot stress enough how important this concept is. It can be seen as a concept or skill, but the label here is not important, what is, is how well you articulate your problem-solving techniques in a business setting. A lot of Data Scientists will focus solely on model accuracy, but will then fail to understand the entire business process. That process includes:
我想添加一個講故事的數據科學獨特概念。 我不能足夠強調這個概念的重要性。 可以將其視為概念或技能,但此處的標簽并不重要,即您在業務環境中表達解決問題技術的能力如何。 許多數據科學家將只專注于模型的準確性,但隨后將無法理解整個業務流程。 該過程包括:
what is the business?
什么事
what is the problem?
問題是什么?
why do we need Data Science?
為什么我們需要數據科學?
what is the goal of Data Science here?
數據科學的目標是什么?
when will we get usable results?
我們什么時候可以獲得可用的結果?
how can we apply our results?
我們如何應用我們的結果?
what is the impact of our results?
我們的結果有什么影響?
how do we share our results and overall process?
我們如何分享我們的結果和整體流程?
As you can see, none of these points are the model itself/improvement in accuracy. The focus here is how you will use data to solve your company's problems. It is beneficial to become acquainted with stakeholders and your non-technical coworkers who you will ultimately be working with. You will also work with Product Managers who will work alongside you in assessing the problem, and Data Engineers to collect the data before even running a base model. At the end of your model process, you will share your results with key individuals who will usually like to see its impact in most likely some type of visual representation (Tableau, Google Slide deck, etc.), so being able to present and communicate is beneficial as well.
如您所見,這些要點都不是模型本身/準確性的提高。 這里的重點是如何使用數據來解決公司的問題。 結識最終將要與之合作的利益相關者和您的非技術合作伙伴是有益的。 您還將與產品經理一起工作,他們將與您一起評估問題,并與數據工程師一起甚至在運行基本模型之前收集數據。 在建模過程的最后,您將與主要人員分享您的結果,這些人員通常希望看到其對某種視覺表示形式( Tableau,Google Slide卡座等 )的影響,從而能夠進行演示和交流也是有益的。
摘要 (Summary)
There are plenty of key concepts Data Scientists, as well as Machine Learning Engineers, should know. Five of them discussed in this article were:
數據科學家以及機器學習工程師應該知道很多關鍵概念。 本文討論的其中五個是:
MulticollinearityOne-hot encodingSamplingErrorStorytellingPlease feel free to comment down below some concepts of Data Science that you focus on daily, or that you think others should know about. Thank you for reading my article, I hope you enjoyed it!
請隨意在以下您每天關注的或您認為其他人應該知道的數據科學概念下進行評論。 感謝您閱讀我的文章,希望您喜歡!
Below are some references and links that can provide more information on the topics discussed in this article.
下面是一些參考和鏈接,它們可以提供有關本文討論的主題的更多信息。
I also want to highlight two other stories I have written which are related to this article, [8] and [9]:
我還想強調我寫的另外兩個與本文有關的故事,[8]和[9]:
These two articles highlight key skills and projects you will need to either know or become familiar with and expect to eventually employ as a professional Data Scientist.
這兩篇文章重點介紹了您需要了解或熟悉的關鍵技能和項目,并期望他們最終成為專業的數據科學家。
翻譯自: https://towardsdatascience.com/5-concepts-every-data-scientist-should-know-16c74d080a83
pd種知道每個數據的類型
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/389731.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/389731.shtml 英文地址,請注明出處:http://en.pswp.cn/news/389731.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章



xgboost keras_用catboost lgbm xgboost和keras預測財務交易

2017. 網格游戲

HUST軟工1506班第2周作業成績公布

幣氪共識指數排行榜0910

走出囚徒困境的方法_囚徒困境的一種計算方法

2016. 增量元素之間的最大差值

Zookeeper系列四:Zookeeper實現分布式鎖、Zookeeper實現配置中心

resize 按鈕不會被偽元素遮蓋

平臺api對數據收集的影響_收集您的數據不是那么怪異的api

709. 轉換成小寫字母

前端技術周刊 2018-09-10:Redux Mobx


1984. 學生分數的最小差值
)
WBLoadingIndicatorView(加載等待動畫)

邏輯回歸 概率回歸_概率規劃的多邏輯回歸
![sys.modules[__name__]的一個實例](http://pic.xiahunao.cn/sys.modules[__name__]的一個實例)
sys.modules[__name__]的一個實例

ajax不利于seo_利于探索移動選項的界面
