sql優化技巧
成為SQL向導! (Become an SQL Wizard!)
It turns out storing data by rows and columns is convenient in a lot of situations, so relational databases have remained a cornerstone of data management in businesses across the globe. Structured Query Language (SQL) is a powerful query language that allows you to retrieve and manipulate data in relational databases. The basics of querying data using SQL are fairly easy to learn, and I highly recommend exploring them if you’re not familiar with it.
事實證明,在很多情況下按行和列存儲數據非常方便,因此關系數據庫一直是全球企業數據管理的基石。 結構化查詢語言( SQL )是一種功能強大的查詢語言,可讓您檢索和處理關系數據庫中的數據。 使用SQL查詢數據的基礎知識非常容易學習,如果您不熟悉SQL,我強烈建議您進行探索 。
In this article, I’m going to give you my process for investigating slow running queries. Even if you’re not in to programming, SQL is a fantastic language to have in your toolbox for situations in which excel doesn’t cut it! If you’re brand new, check out my intro to SQL.
在本文中,我將向您介紹調查運行緩慢的查詢的過程。 即使您不喜歡編程, SQL還是一種出色的語言,可用于工具箱中,即使excel不能勝任! 如果您是新手,請查看我SQL簡介。
跟著! (Follow Along!)
It is free to download and use! I use Microsoft SQL Server and SQL Server Management Studios at work and at home, so that is what I use in the examples.
它是免費下載和使用! 我在工作中和在家中都使用Microsoft SQL Server和SQL Server Management Studio ,所以這就是我在示例中使用的。
為什么查詢速度慢? (Why is my Query Slow?)
There are many reasons a query might be running slow, and it isn’t always obvious. I’ve written plenty of queries I thought would process easily, but ended up taking an absurd amount of time until I did a little tuning. If you’re new to query optimization, read through the SQL Server Query Engine 101 below. If you already know that stuff, skip ahead to the Query Optimization Tips!
有很多原因可能導致查詢運行緩慢,而且這種情況并不總是很明顯。 我已經寫了很多我認為很容易處理的查詢,但是最終花了一些荒謬的時間,直到我做了一些調整。 如果您不熟悉查詢優化,請通讀下面SQL Server查詢引擎101。 如果您已經知道這些知識,請跳至“查詢優化技巧”!
SQL Server查詢引擎101 (SQL Server Query Engine 101)
Although query syntax is fairly simple, there is a lot to understand under the hood of SQL Server. There is no way I can cover it all in an article, but I’ll give you the cliff notes.
盡管查詢語法非常簡單,但是在SQL Server的背景下還有很多要理解的地方。 我不可能在一篇文章中介紹所有內容,但我會給您一些懸崖筆記。
The SQL Server Engine is composed of 2 main parts: Storage Engine and the Query Processor (Relational Engine). The Query Processor is the part of SQL Server that accepts all incoming queries and devises an Execution Plan for them. There is no guarantee the same plan will always be selected for a query. I’ll get deeper into execution plans later…
SQL Server引擎由2個主要部分組成: 存儲引擎和查詢處理器(關系引擎) 。 查詢處理器是SQL Server的一部分,它接受所有傳入的查詢并為它們設計執行計劃 。 不能保證總是為查詢選擇相同的計劃。 稍后我將更深入地執行計劃...
The 4 core steps of the Query Processor:
查詢處理器的4個核心步驟:
Parsing — Checks the query uses valid syntaxBind — Checks that the objects exist and is responsible for name resolutionOptimize — Uses cost-based optimization to generate an optimal execution planExecute — Executes the execution plan
解析-檢查查詢是否使用有效的語法綁定-檢查對象是否存在并負責名稱解析優化-使用基于成本的優化生成最佳執行計劃執行-執行執行計劃
優化器 (The Optimizer)
The query optimizer arrives at the optimal plan by generating and assessing as many execution plans as possible in a given search space. The search space is all possible execution plans for the query. Any plan in the search space must return the query results.
查詢優化器通過在給定的搜索空間中生成并評估盡可能多的執行計劃來得出最佳計劃。 搜索空間是查詢的所有可能的執行計劃。 搜索空間中的任何計劃都必須返回查詢結果。
Of course, it isn’t always possible for the optimizer to assess ALL possible plans. An exhaustive search could take a ridiculously long time and impact overall performance. For example, a complex query might have millions of possible plan combinations. The optimizer finds a balance between plan quality and search time.
當然,優化器并非總是能夠評估所有可能的計劃。 詳盡的搜索可能要花費很長時間,并且會影響整體性能。 例如,一個復雜的查詢可能具有數百萬種可能的計劃組合。 優化器在計劃質量和搜索時間之間找到平衡。
Execution plans consist of physical entities called operators. Operators will make more sense once we look at the plans. To produce an estimated cost for the plan, the optimizer considers:
執行計劃由稱為操作員的物理實體組成。 一旦我們查看了計劃,運營商將變得更加有意義。 為了產生計劃的估計成本,優化器考慮:
- Physical operator costs and things like I/O and memory 物理操作員成本以及I / O和內存之類的東西
- Estimated number of records (Cardinality estimate) 估計記錄數(基數估計)
To help the query optimizer with Cardinality estimates, SQL Server uses stored information on the distribution of values and columns within a table called Statistics. The query optimizer adds up all these costs pretty quickly and determines which plan is good enough to use!
為了幫助查詢優化器進行基數估計 ,SQL Server使用存儲在表中的有關值和列分布的信息,該表稱為“ 統計” 。 查詢優化器可以很快將所有這些成本加起來,并確定哪個計劃足以使用!
執行計劃 (Execution Plans)
You can see the query execution plan by Right-clicking and selecting Show Execution Plan or Show Estimated Execution Plan. Use the Estimated Execution Plan when you want to look for bottlenecks before running a large or complex query.
您可以通過右鍵單擊并選擇“顯示執行計劃”或“顯示估計的執行計劃”來查看查詢執行計劃。 當您想在運行大型或復雜查詢之前查找瓶頸時,請使用“估計執行計劃”。
探索計劃 (Exploring the Plan)
The most common way to view the execution plan is the tree format that uses images to represent the operators. For example:
查看執行計劃的最常見方法是使用圖像表示操作符的樹格式。 例如:
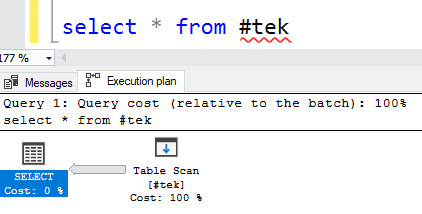
In the example you can see two operators in the execution plan: SELECT and Table Scan. You also see an arrow that represents the flow of data. The thicker the arrow, the more records.
在示例中,您可以在執行計劃中看到兩個運算符: SELECT和Table Scan。 您還會看到一個箭頭 代表數據流。 箭頭越粗,記錄越多。
The first operator is called the Results operator and is mostly there to represent the SELECT. Beyond that, there are a lot of operators! Each performs a single function like scanning, filtering or performing an aggregation. It can represent a logical operation and/or a physical operation. Look them up when you need to instead of trying to memorize them all!
第一個運算符稱為“ 結果”運算符,并且大多數用于表示SELECT 。 除此之外, 這里還有很多運營商! 每個都執行單個功能,例如掃描,過濾或執行聚合。 它可以表示邏輯操作和/或物理操作。 在需要時查找它們,而不要嘗試全部記住它們!
查詢優化技巧 (Query Optimization Tips)
Although it tries, the plan executed by the query processor isn’t always going to be the best plan. For example, a bad cardinality estimate might result in the wrong operator. That’s why you need to learn some query optimization! Here are my top tips and troubleshooting techniques for queries.
盡管可以嘗試,但查詢處理器執行的計劃并不總是最佳的計劃。 例如,基數估計錯誤可能會導致運算符錯誤。 這就是為什么您需要學習一些查詢優化的原因! 這是我查詢的主要技巧和故障排除技術。
設置統計IO開 (SET Statistics IO ON)
Using the command SET Statistics IO ON before the query provides information that can help troubleshoot the query. STATISTICS IO shows you the IO that was incurred for each object. It is useful for understanding what happened behind the scenes and how the data was retrieved.
在查詢之前使用命令SET Statistics IO ON提供可以幫助解決查詢問題的信息。 統計IO向您顯示每個對象產生的IO。 對于了解幕后發生的情況以及如何檢索數據很有用。
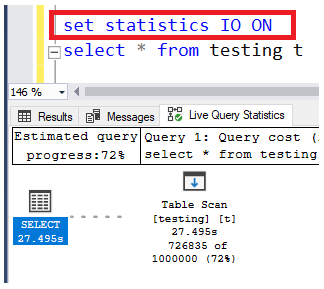
When the query completes, click the Messages tab to see the output.
查詢完成后,單擊“ 消息”選項卡以查看輸出。

Notice the 19397 Logical Reads.
請注意19397 邏輯讀取 。
A lower number is better when it comes to reads (logical and physical). A logical read is when the data is read from the SQL Server Buffer Pool. The SQL Server engine uses the buffer pool when when transferring data, like getting it from disk for example.
讀取(邏輯和物理)值越小越好。 邏輯讀取是指從SQL Server緩沖池讀取數據時。 當傳輸數據時,例如從磁盤獲取數據,SQL Server引擎將使用緩沖池。
To greatly reduce the number of logical reads, try adding an index on the table.
要大大減少邏輯讀取的次數,請嘗試在表上添加索引。

Notice logical reads is 0. Performance was boosted significantly over querying a table without an index. You can see different types of reads occurred instead of the standard Logical or Physical. This is because I’m using a ColumnStore index. ColumnStore indexes are typically used for large data tables or data warehouses.
請注意,邏輯讀取為0。與查詢沒有索引的表相比,性能得到了顯著提高。 您可以看到發生了不同類型的讀取,而不是標準的邏輯或物理讀取。 這是因為我正在使用ColumnStore索引 。 ColumnStore索引通常用于大型數據表或數據倉庫。
使用索引 (Use Indexes)
For good performance, it is imperative the tables have good indexing. Without getting too deep into the woods, basically, there are two types of indexes:
為了獲得良好的性能,表必須具有良好的索引編制。 不必太深入了解,基本上有兩種類型的索引 :
Clustered index — Clustered indexes sort and store the data rows in the table or view based on the key values.
聚集索引 — 聚集索引根據鍵值對數據行進行排序并將其存儲在表或視圖中。
Non-clustered index — A non-clustered index is an index in which the rows are ordered by the columns that make up the index.
非聚集索引 — 非 聚集索引是這樣的索引 ,其中的行按組成索引的列排序。
A table without a clustered index is called a Heap. Most tables should have clustered indexes. If a table is a heap, it is still possible to add non-clustered indexes. Tables can have only 1 clustered index, but many non-clustered indexes.
沒有聚集索引的表稱為堆 。 大多數表應具有聚集索引。 如果表是堆,仍然可以添加非聚集索引。 表只能有1個聚集索引,但可以有許多非聚集索引。
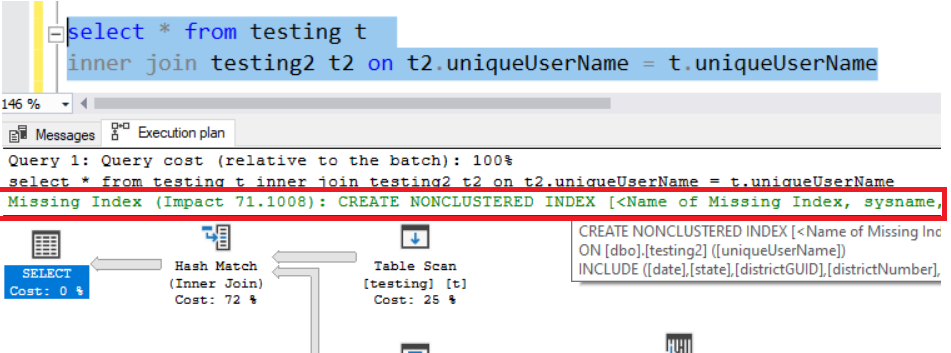
If you’re not sure what to include in the index, generate the Estimated Execution Plan and the Missing Indexes feature provides information about missing indexes that could improve query performance.
如果您不確定要包括在索引中的內容,請生成“估計執行計劃”,“ 缺失索引”功能將提供有關缺失索引的信息,這些信息可以提高查詢性能。
謹慎使用 (Use caution)
Use caution when creating non-clustered indexes since they take up space, and over-indexing is bad. The problem with blindly creating this index in the example is that SQL Server has decided that it is useful for a particular query (or handful of queries), but is ignorant of the rest of the workload. The index might not be a good fit, so be aware of what you’re doing.
創建非聚簇索引時要小心 ,因為它們會占用空間,并且過度索引是不好的。 在示例中盲目創建此索引的問題在于,SQL Server已確定該索引對于特定查詢(或少數查詢)很有用,但是卻忽略了其余工作負載。 該索引可能不適合,因此請注意您在做什么。
避免工會 (Avoid Unions)
When I am querying large tables, I do my best to avoid UNION. When I see queries using it, I hope I packed a sleeping bag because I might be there all night!
查詢大表時,我會盡量避免使用UNION。 當我看到使用它的查詢時,希望我收拾一個睡袋,因為我可能整晚都在那兒!
First, it is important to know the difference between UNION and UNION ALL. The UNION operator is used to combine the result-set of two or more SELECT statements, but it will exclude duplicates. UNION ALL includes duplicates; it essentially concatenates the two datasets. Because they behavior differently, they have very different execution plans:
首先,了解UNION和UNION ALL之間的區別很重要。 UNION運算符用于合并兩個或多個SELECT語句的結果集,但它將排除重復項 。 UNION ALL 包括重復項; 它 本質上是連接兩個數據集。 由于它們的行為不同,因此它們具有非常不同的執行計劃:
Lets take a look at this situation:
讓我們看一下這種情況:
--table testing has 1,000,000 rows
--table testing2 has 5,000,000 rows--I want to return all 6 million rows. Which should I use? Is there a faster way?
select * from testing
union
select * from testing2select * from testing
union all
select * from testing2Of the two options, UNION ALL will guarantee all rows are included. However, when comparing the execution plans, UNION ALL is slower!
在這兩個選項中,UNION ALL將保證包括所有行。 但是,在比較執行計劃時,UNION ALL會更慢!
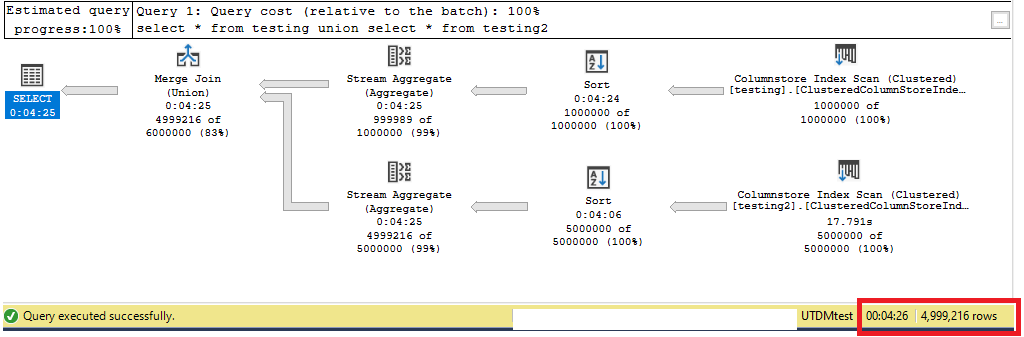
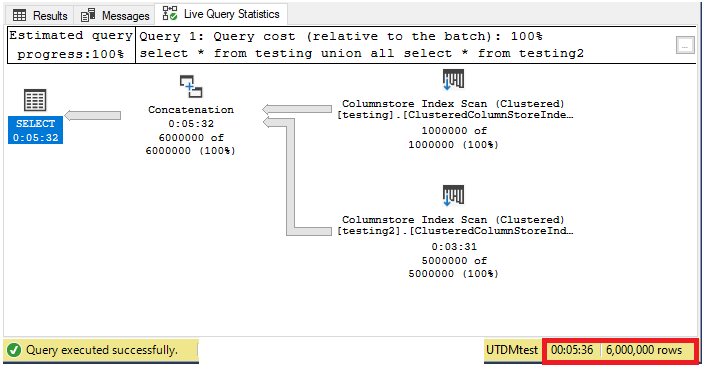
Notice UNION ALL takes over 5 minutes in the example!
注意,在示例中,UNION ALL花費了5分鐘以上!
Instead of using UNION ALL, I like using a temporary table. I dump the data into a temporary table and then select all from the table.
我喜歡使用臨時表, 而不是使用UNION ALL 。 我將數據轉儲到臨時表中,然后從表中全選。
select * into #tek from testing2
insert into #tek select * from testingselect * from #tek
--drop table #tek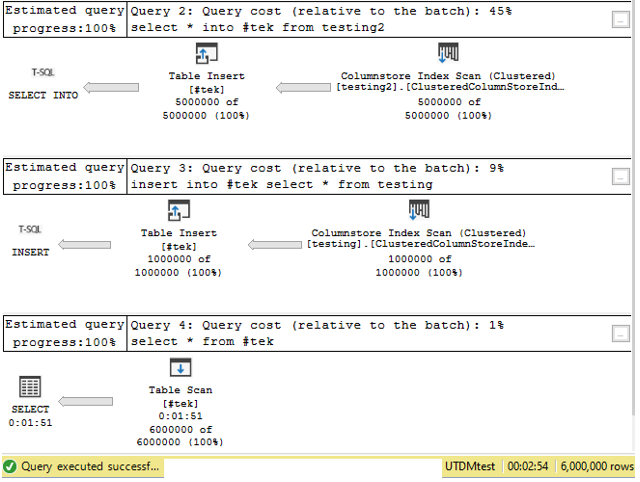
Notice this method took under 3 minutes to return 6 million rows compared to UNION ALL which took over 5! Since the data exists in the temp table, it is in a semi-permanent place allowing you to do more with it if needed too.
請注意,此方法花了不到3分鐘的時間才能返回600萬行,而UNION ALL則需要5 分鐘 ! 由于數據存在于臨時表中,因此它位于半永久位置,允許您在需要時進行更多處理。
避免排序 (Avoid Sort)
Do what you can to avoid seeing the Sort operator in the Execution Plan. Sorts are slow and can take up a lot of resources resulting in spills that eat up tempDB! If you see a warning sign in your execution plan, hover over it to see what it says.
盡力避免在執行計劃中看到“排序”運算符。 排序速度很慢,并且會占用大量資源,從而導致溢出而耗盡tempDB! 如果在執行計劃中看到警告標志,請將鼠標懸停在該計劃上以查看其內容。
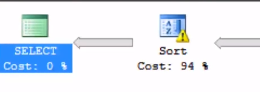
Don’t use an ORDER BY clause in your query if you don’t have to. Ideally, if you need to sort by a specific column often, you can add a non-clustered index for that column to help avoid Sort operators in the plan.
如果不需要,請不要在查詢中使用ORDER BY子句。 理想情況下,如果您需要經常按特定的列排序,則可以為該列添加非聚集索引,以幫助避免計劃中的“排序”運算符。
現貨懶桌子線軸 (Spot Lazy Table Spools)
I’ve seen Table Spools cause queries to takes hours when they should be taking minutes, or even seconds. The Table Spool Operator is essentially used to create a temporary table in memory or on-disk that stores results of sub-queries that might be used multiple times in the execution plan. The table spool builds a temporary table that is lazy, meaning it only accesses rows when it is needed. There are 5 or so different types of Spool operators, but all have similar purpose.
我已經看到表假脫機會導致查詢花費數小時甚至數秒的時間。 的 表假脫機操作符本質上用于在內存或磁盤上創建一個臨時表,該臨時表存儲可能在執行計劃中多次使用的子查詢的結果。 表假脫機構建了一個懶惰的臨時表,這意味著它僅在需要時才訪問行。 大約有5種不同類型的Spool運算符,但是它們都有相似的用途。
Table Spools are tricky because they can sometimes show a low Cost %, but be a huge bottleneck in the execution plan. Hover over the operator to see how the estimated rows compare to the actual rows and collect additional info about the properties!
表假脫機非常棘手,因為它們有時可以顯示較低的“成本百分比”,但會成為執行計劃中的巨大瓶頸。 將鼠標懸停在運算符上可以查看估算的行與實際行的比較情況,并收集有關屬性的其他信息!
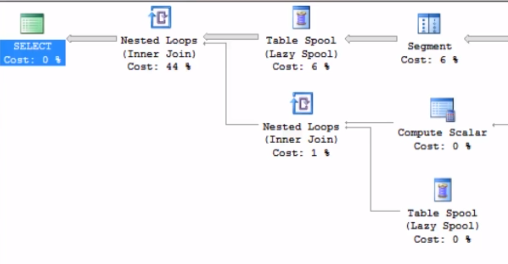
To avoid Table Spools, try using an index that includes all fields in the query. If that is not possible, you can try Query Hints or force the order of the query or specify the join operation. For example, try using INNER HASH JOIN instead of INNER JOIN. Forcing Hash joins can boost speed significantly, but they can cause a lot of spill over into TempDB, so be very careful using query hints!
為避免表假脫機,請嘗試使用包含查詢中所有字段的索引。 如果不可能,則可以嘗試查詢提示或強制查詢順序或指定聯接操作。 例如,嘗試使用INNER HASH JOIN代替INNER JOIN。 強制使用哈希聯接可以顯著提高速度,但是它們可能導致大量溢出到TempDB中,因此請謹慎使用查詢提示!
最后的想法 (Final Thoughts)
Understanding execution plans and optimizing SQL queries can be tedious and take a while to learn. I’ve been using SQL for years and still learn new techniques all the time! As long as you remember the following, you’re on your way to becoming a SQL Query tuning wizard:
了解執行計劃和優化SQL查詢可能是乏味的,需要一段時間才能學習。 我已經使用SQL多年了,仍然一直在學習新技術! 只要您記住以下幾點,就可以成為SQL查詢調優向導:
- Use table indexes 使用表索引
- Set Statistics IO on 將統計數據IO設置為打開
- Check the Execution Plan 檢查執行計劃
Check out my other articles on SQL, Programming and Data Science if you enjoyed this article!
如果您喜歡這篇文章,請查看我有關SQL,編程和數據科學的其他文章!
翻譯自: https://medium.com/swlh/become-a-sql-wizard-using-these-query-optimization-tips-a932d18c762f
sql優化技巧
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/389052.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/389052.shtml 英文地址,請注明出處:http://en.pswp.cn/news/389052.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

Day 4:集合——迭代器與List接口

oem是代工還是貼牌_代加工和貼牌加工的區別是什么

KNN 算法--圖像分類算法

java核心技術-NIO

物種分布模型_減少物種分布建模中的空間自相關
![BZOJ1014: [JSOI2008]火星人prefix](http://pic.xiahunao.cn/BZOJ1014: [JSOI2008]火星人prefix)
BZOJ1014: [JSOI2008]火星人prefix

redis將散裂中某個值自增_這些Redis命令你都掌握了沒?

asp.net的MessageBox


如何一鍵部署項目、代碼自動更新

Kettle7.1在window啟動報錯

opa847方波放大電路_電子管放大電路當中陰極電阻的作用和選擇


matplotlib基礎函數函數 plot, figure

清潔數據ploy n_清潔屋數據

redis安裝redis集群

聯想拯救者y7000p加內存條_內存、硬盤不夠用?手把手教你升級聯想拯救者Y7000P...

機器學習實踐一 logistic regression regularize

ajax+webservice
