邏輯回歸 python
Classification techniques are an essential part of machine learning and data science applications. Approximately 70% of problems in machine learning are classification problems. There are lots of classification problems that are available, but the logistics regression is the most common way and is a useful regression method for solving the binary classification(0–1) problem,Another category of classification is multi-class classification, which takes care of the issues where several classes are present in the outcome variable. For example, IRIS dataset a very famous example of multi-class classification. Other examples are classifying articles ( require NLP skills ).
分類技術是機器學習和數據科學應用程序的重要組成部分。 機器學習中大約70%的問題是分類問題。 可用的分類問題很多,但是物流回歸是最常用的方法,是解決二元分類(0-1)問題的一種有用的回歸方法。另一類分類是多分類,需要注意結果變量中存在幾個類別的問題。 例如,IRIS數據集是非常著名的多類分類示例。 其他示例是對文章進行分類(需要NLP技能)。
Logistic Regression can be used for multiple classification problems such as credit cards approvalls ,Diabetes prediction and given a customer will purchase a particular product or will they churn another competitor, whether the user will click on a given advertisement link or not, and so much more.
Logistic回歸可用于多種分類問題,例如信用卡審批,糖尿病預測以及給定客戶將購買特定產品還是會吸引其他競爭對手(無論用戶是否會點擊給定的廣告鏈接)等等。 。
Logistic Regression is one of the most famous or simple way and commonly used Machine Learning algorithms for binary (0–1) classification. It is easy to code and can be used as the baseline for any binary classification problem. Its basic fundamental concepts are also constructive in deep learning. Logistic regression describes and estimates the relationship between one dependent binary variable and independent variables.
Logistic回歸是最著名或最簡單的方法之一,也是用于二進制(0-1)分類的機器學習算法。 它易于編碼,可以用作任何二進制分類問題的基準。 它的基本基本概念在深度學習中也具有建設性。 Logistic回歸描述和估計一個因變量和自變量之間的關系。
To break down to you,here is what we gonna be learning in this tutorial.
總結一下,這是我們將在本教程中學習的內容。
Introduction To Logistic Regression.
Logistic回歸概論。
Linear Regression Vs Logistic Regression.
線性回歸與邏輯回歸。
- Maximum Likelihood Estimation Vs. Ordinary Least Square Method 最大似然估計與 普通最小二乘法
- Logistic Regression under the hood? 引擎蓋下的邏輯回歸?
Logistic Regression in Scikit-learn.
Scikit學習中的邏輯回歸 。
- Confusion Matrix for Model Evaluation. 用于模型評估的混淆矩陣。
- Advantages over Disadvantages. 優勢勝過劣勢。
邏輯回歸: (Logistic Regression:)
Logistic regression is a statistical learning method for predicting two-class(0–1). the target variable is dichotomous in nature. Dichotomous means there are only two possible classes. For example, it can be used for cancer detection problems. the logistic regression output probabilities and based on that output we can predict the corresponding classes.
Logistic回歸是一種用于預測兩級(0-1)的統計學習方法。 目標變量本質上是二分法的。 二分法意味著只有兩種可能的類別。 例如,它可以用于癌癥檢測問題。 邏輯回歸輸出的概率,并基于該輸出,我們可以預測相應的類。
It is a special case of linear regression where the target variable is categorical in nature. It uses a log of odds as the dependent variable. Logistic Regression predicts the probability of occurrence of a binary event utilizing a logit function.
這是線性回歸的一種特殊情況,其中目標變量本質上是分類的。 它使用幾率對數作為因變量。 Logistic回歸利用logit函數預測二進制事件的發生概率。
Linear Regression Equation:
線性回歸方程:
In statistics, econometrics and machine learning, a linear regression model is a regression model that seeks to establish a linear relationship between a variable, called explained, and one or more variables, called explanatory,It is also referred to as a linear model or a linear regression model.
在統計,計量經濟學和機器學習中,線性回歸模型是一種回歸模型,旨在建立一個變量(稱為解釋變量)和一個或多個變量(稱為解釋變量)之間的線性關系,也稱為線性模型或線性模型。線性回歸模型。
We consider the model for individual i. For each individual, the explained variable is written as a linear function of the explanatory variables.
我們考慮個人i的模型。 對于每個人,將解釋變量寫為解釋變量的線性函數。
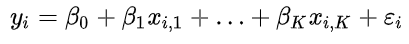
where yi and the xi,j are fixed and εi represents the error.
其中yi和xi , j是固定的,而εi表示誤差。
Sigmoid Function:
乙狀結腸功能:
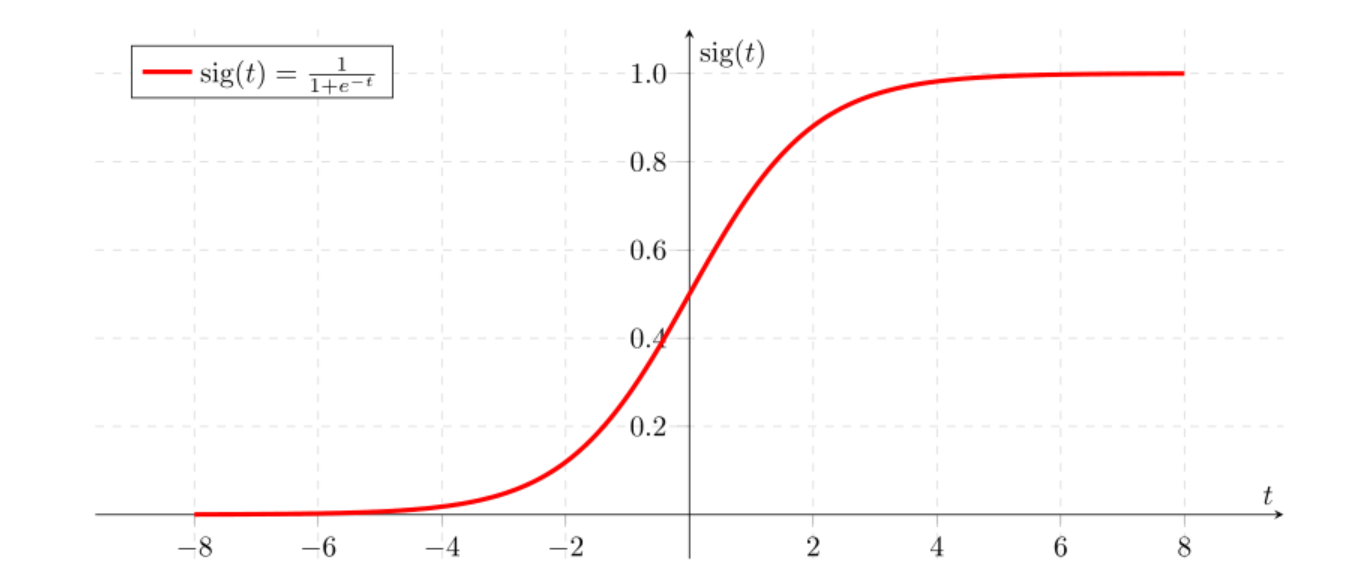
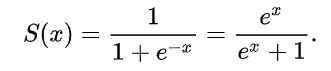
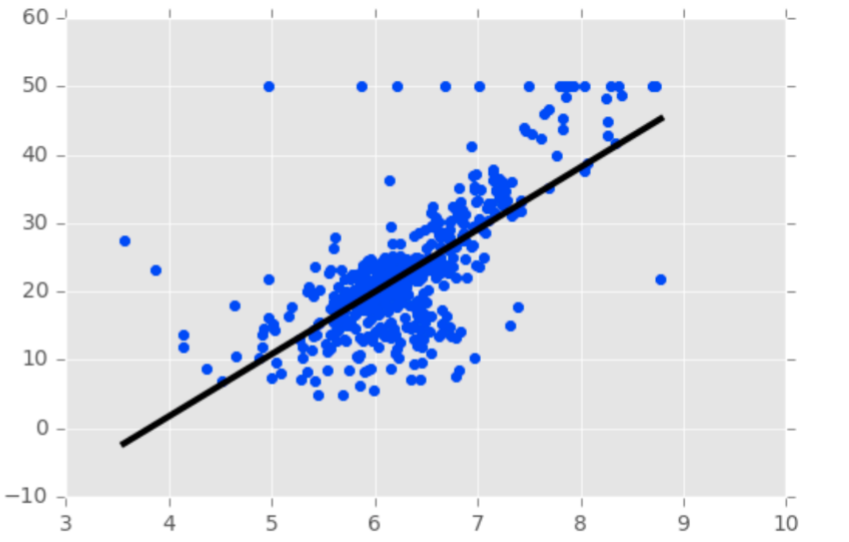
The sigmoid function, also called logistic function gives an ‘S’ shaped curve that can take any real-valued number and map it into a value between 0 and 1( probability). If the curve goes to positive infinity, y predicted will become 1, and if the curve goes to negative infinity, y predicted will become 0. If the output of the sigmoid function is more than 0.5, we can classify the outcome as 1 or YES( by default in logistic regression), and if it is less than 0.5, we can classify it as 0 or NO. The output cannot For example: If the output is 0.75, we can say in terms of probability as: There is a 75 percent chance that patient will suffer from cancer.
S形函數 (也稱為邏輯函數)給出了一個“ S”形曲線,該曲線可以采用任何實數值,并將其映射為0到1(概率)之間的值。 如果曲線變為正無窮大,則y預測將變為1,如果曲線變為負無窮大,則y預測將變為0。如果S型函數的輸出大于0.5,我們可以將結果分類為1或YES。 (在邏輯回歸中默認情況下),如果小于0.5,我們可以將其分類為0或NO。 輸出不能為例如:如果輸出為0.75,就概率而言,我們可以這樣說:患者有75%的機會患上癌癥。
Properties of Logistic Regression:
Logistic回歸的屬性:
The dependent variable in logistic regression follows Bernoulli Distribution.
邏輯回歸中的因變量遵循伯努利分布。
- Estimation is done through maximum likelihood. 估計是通過最大似然來完成的。
- No R Square, Model fitness is calculated through Concordance, KS-Statistics. 沒有R平方,模型適用性通過Concordance,KS-Statistics計算。
線性回歸與邏輯回歸: (Linear Regression Vs Logistic Regression:)
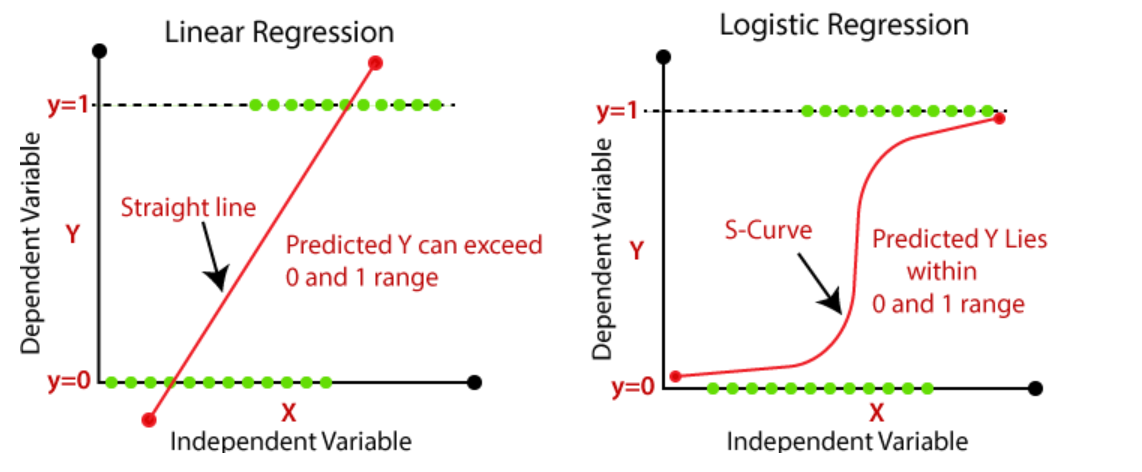
Linear regression gives you a continuous output, but logistic regression provides a constant output. An example of the continuous output is house price and stock price. Example’s of the discrete output is predicting whether a patient has cancer or not, predicting whether the customer will churn. Linear regression is estimated using Ordinary Least Squares (OLS) while logistic regression is estimated using Maximum Likelihood Estimation (MLE) approach.
線性回歸可提供連續的輸出,而邏輯回歸可提供恒定的輸出。 連續輸出的一個例子是房屋價格和股票價格。 離散輸出的示例正在預測患者是否患有癌癥,并預測客戶是否會流失。 使用普通最小二乘(OLS)估計線性回歸,而使用最大似然估計(MLE)方法估計邏輯回歸。
最大似然估計與 最小二乘法: (Maximum Likelihood Estimation Vs. Least Square Method:)
In statistics, maximum likelihood estimate (MLE) is a method of estimating the parameters of a probability distribution by maximizing a likelihood function, so that under the assumed statistical model the observed data is most probable. The point in the parameter space that maximizes the likelihood function is called the maximum likelihood estimate. The logic of maximum likelihood is both intuitive and flexible, and as such the method has become a dominant means of statistical inference.
在統計中,最大似然估計(MLE)是通過最大化似然函數來估計概率分布參數的方法,因此在假定的統計模型下,觀察到的數據最有可能。 參數空間中使似然函數最大化的點稱為最大似然估計。 最大似然邏輯既直觀又靈活,因此該方法已成為統計推斷的主要手段。
Ordinary Least squares estimates are computed by fitting a regression line on given data points that has the minimum sum of the squared deviations (least square error). Both are used to estimate the parameters of a linear regression model. MLE assumes a joint probability mass function, while OLS doesn’t require any stochastic assumptions for minimizing distance.
普通最小二乘估計值是通過在給定的數據點上擬合回歸線來計算的,該數據點具有平方差的最小和(最小二乘誤差)。 兩者都用于估計線性回歸模型的參數。 MLE假設一個聯合概率質量函數,而OLS不需要任何隨機假設來最小化距離。
Logistic回歸的類型: (Types of Logistic Regression:)
Multinomial Logistic Regression: The target variable has three or more nominal categories such as predicting the type of Wine.
多項邏輯回歸 :目標變量具有三個或更多名義類別,例如預測酒的類型。
Binary Logistic Regression: The target variable has only two possible outcomes such as Spam or Not Spam.
二進制Logistic回歸 :目標變量只有兩個可能的結果,例如垃圾郵件或非垃圾郵件。
multi-label Logistic Regression: the target variable has three or more ordinal categories such as restaurant or product rating from 1 to 5.
多標簽Logistic回歸 :目標變量具有三個或多個序數類別,例如餐廳或產品等級從1到5。
Scikit學習中的模型構建: (Model building in Scikit-learn:)
Scikit-learn is a free Python library for machine learning. It has been developed by many contributors, particularly in the academic world, by French higher education and research institutes such as Inria. It includes functions for estimating random forests, logistic regressions, classification algorithms, and support vector machines. It is designed to harmonize with other free Python libraries, including NumPy and SciPy.
Scikit-learn是用于機器學習的免費Python庫。 它是由許多貢獻者開發的,特別是在學術界,是由法國高等教育和研究所(例如Inria)開發的。 它包括用于估計隨機森林的功能,邏輯回歸,分類算法和支持向量機。 它旨在與其他免費的Python庫(包括NumPy和SciPy)保持一致 。
datasets: https://www.kaggle.com/uciml/pima-indians-diabetes-database
數據集: https : //www.kaggle.com/uciml/pima-indians-diabetes-database
now Let’s build the diabetes prediction model,Here, you are going to predict diabetes using Logistic Regression Classifier,first load the required Pima Indian Diabetes.
現在,我們建立糖尿病預測模型,在這里,您將使用Logistic回歸分類器預測糖尿病,首先加載所需的Pima印度糖尿病。

選擇功能: (Selecting Feature:)
Here, you need to divide the given columns into two types of variables dependent(or target variable) and independent variable(or feature variables or predictors variables).
在這里,您需要將給定的列分為因變量(或目標變量)和自變量(或特征變量或預測變量)兩種類型。

分割資料: (Splitting Data:)
To understand model performance, dividing the dataset into a training set and a test set is a good strategy.
為了了解模型的性能,將數據集分為訓練集和測試集是一個很好的策略。
Let’s split dataset by using function train_test_split(). You need to pass 3 parameters features, target, and test_set size. Additionally, you can use random_state to select records randomly.
讓我們使用函數train_test_split()拆分數據集。 您需要傳遞3個參數功能,目標和test_set大小。 此外,您可以使用random_state隨機選擇記錄。

Here, the Dataset is broken into two parts in a ratio of 75:25. It means 75% data will be used for model training and 25% for model testing.
在這里,數據集按75:25的比例分為兩部分。 這意味著75%的數據將用于模型訓練,而25%的數據將用于模型測試。
模型開發和預測: (Model Development and Prediction:)
First, import the Logistic Regression module and create a Logistic Regression classifier object using LogisticRegression() function.
首先,導入Logistic回歸模塊,并使用LogisticRegression()函數創建一個Logistic回歸分類器對象。
Then, fit your model on the train set using fit() and perform prediction on the test set using predict().
然后,使用fit()將模型擬合到訓練集上,并使用predict()對測試集執行預測。

使用混淆矩陣的模型評估: (Model Evaluation using Confusion Matrix:)
A confusion matrix is a table that is used to evaluate the performance of a classification model. You can also visualize the performance of an algorithm. The fundamental of a confusion matrix is the number of correct and incorrect predictions are summed up class-wise.
混淆矩陣是用于評估分類模型的性能的表。 您還可以可視化算法的性能。 混淆矩陣的基本原理是按類別匯總正確和錯誤預測的數量。
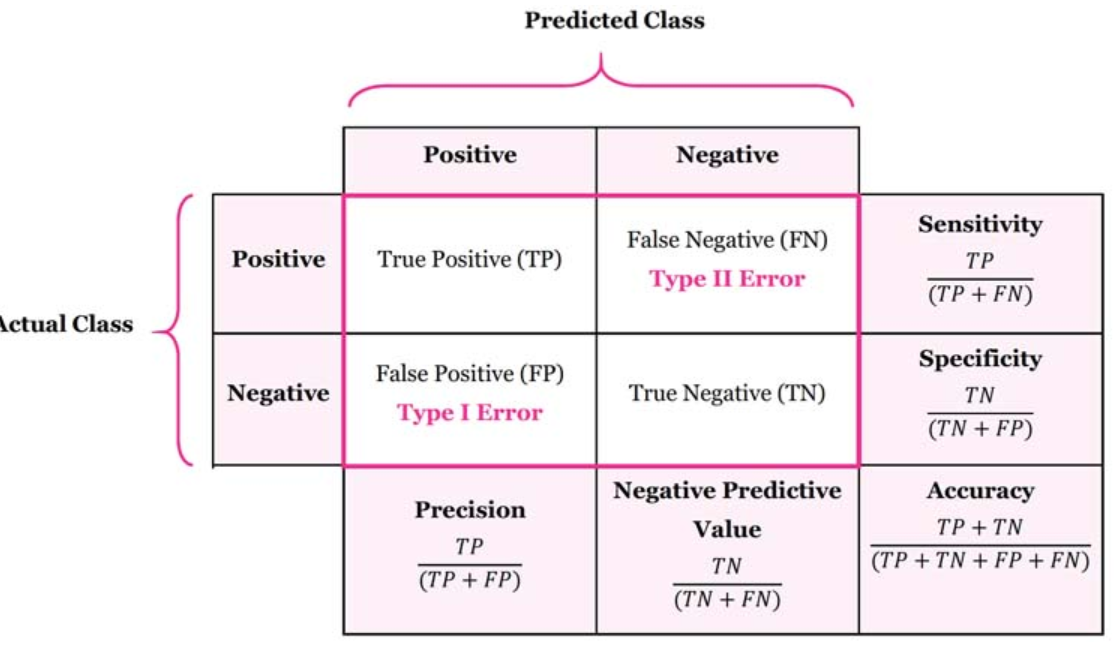


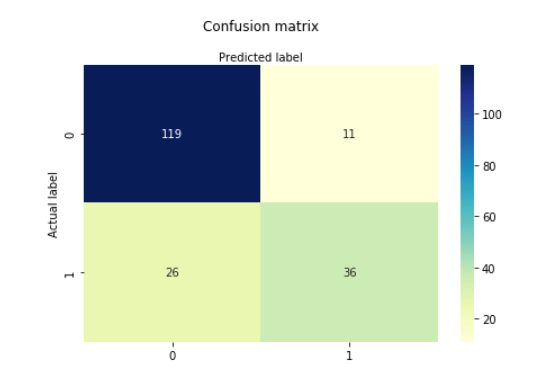
Here, you can see the confusion matrix in the form of the array object. The dimension of this matrix is 2*2 because this model is binary classification. You have two classes 0 and 1. Diagonal values represent accurate predictions, while non-diagonal elements are inaccurate predictions. In the output, 119 and 36 are actual predictions, and 26 and 11 are incorrect predictions.
在這里,您可以看到數組對象形式的混淆矩陣。 該矩陣的維數為2 * 2,因為該模型是二進制分類。 您有兩個類別0和1。對角線值表示準確的預測,而非對角線元素則表示不正確的預測。 在輸出中,119和36是實際預測,而26和11是不正確的預測。
使用熱圖可視化混淆矩陣: (Visualizing Confusion Matrix using Heatmap:)
A heatmap is a data visualization technique that shows magnitude of a phenomenon as color in two dimensions. The variation in color may be by hue or intensity, giving obvious visual cues to the reader about how the phenomenon is clustered or varies over space.
熱圖是一種數據可視化技術,可將現象的大小顯示為二維顏色。 顏色的變化可能是色相或強度 ,從而為讀者提供了有關現象如何聚集或隨空間變化的明顯視覺提示。
Here, you will visualize the confusion matrix using Heatmap.
在這里,您將使用Heatmap可視化混淆矩陣。


混淆矩陣評估指標: (Confusion Matrix Evaluation Metrics:)
Let’s evaluate the model using model evaluation metrics such as accuracy, precision, and recall.
讓我們使用模型評估指標(例如準確性,準確性和召回率)評估模型。


Well, you got a classification rate of 80%, considered as good accuracy.
好吧,您的分類率為80%,被認為是不錯的準確性。
Precision: Precision is about being precise, i.e., how accurate your model is. In other words, you can say, when a model makes a prediction, how often it is correct. In your prediction case, when your Logistic Regression model predicted patients are going to suffer from diabetes, that patients have 76% of the time.
精度 :精度是指精度,即模型的精度。 換句話說,您可以說,當模型做出預測時,預測正確的頻率是多少。 在您的預測案例中,當您的Logistic回歸模型預測患者將患有糖尿病時,該患者有76%的時間。
Recall: If there are patients who have diabetes in the test set and your Logistic Regression model can identify it 58% of the time.
回想一下 :如果測試集中有糖尿病患者,并且您的Logistic回歸模型可以在58%的時間內識別出糖尿病。
優點: (Advantages:)
Because of its efficient and straightforward nature, doesn’t require high computation power, easy to implement, easily interpretable, used widely by data analyst and scientist. Also, it doesn’t require scaling of features. Logistic regression provides a probability score for observations.
由于其高效而直接的特性,它不需要高計算能力,易于實現,易于解釋的方法,并被數據分析師和科學家廣泛使用。 而且,它不需要縮放功能。 Logistic回歸為觀察提供了概率分數。
缺點: (Disadvantages:)
Logistic regression is not able to handle a large number of categorical features/variables. It is vulnerable to overfitting. Also, can’t solve the non-linear problem with the logistic regression that is why it requires a transformation of non-linear features. Logistic regression will not perform well with independent variables that are not correlated to the target variable and are very similar or correlated to each other.
Logistic回歸無法處理大量分類特征/變量。 它很容易過擬合。 此外,無法通過邏輯回歸來解決非線性問題,這就是為什么它需要轉換非線性特征的原因。 如果邏輯變量與目標變量不相關,非常相似或彼此相關,則邏輯回歸將無法很好地執行。
結論: (Conclusion:)
this tutorial, you covered a lot of details about Logistic Regression. You have learned what the logistic regression is, how to build respective models, how to visualize results and some of the theoretical background information. Also, you covered some basic concepts such as the sigmoid function, maximum likelihood, confusion matrix, with that said see you guys in the next article and don’t forget to keep learning.
在本教程中,您涵蓋了有關Logistic回歸的許多詳細信息。 您已經了解了邏輯回歸是什么,如何建立各自的模型,如何可視化結果以及一些理論背景信息。 另外,您還介紹了一些基本概念,例如S形函數,最大似然,混淆矩陣,并說在下一篇文章中與大家見面, 不要忘記繼續學習。

翻譯自: https://medium.com/analytics-vidhya/dive-into-logistic-regression-with-python-48911f37f8ee
邏輯回歸 python
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/388783.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/388783.shtml 英文地址,請注明出處:http://en.pswp.cn/news/388783.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章
)
spring定時任務(@Scheduled注解)

net user 用戶名 密碼 /add 建立用戶

JavaScript是如何工作的:與WebAssembly比較及其使用場景

友元 java_C++ 友元關系詳解

Matplotlib中的“ plt”和“ ax”到底是什么?

【數據庫的備份與還原】 .


java 控制jsp_JSP學習之Java Web中的安全控制實例詳解

PHP 基礎 自動類型轉換之比較運算符

java的多線程訪問共享變量_java多線程通信之共享變量

2018年阿里云NoSQL數據庫大事盤點

cayenne:用于隨機模擬的Python包

java 如何將word 轉換為ftl_使用 freemarker導出word文檔

DotNetBar office2007效果

Spring boot 中pom.xml 各個節點詳解

spotify 數據分析_沒有數據? 沒問題! 如何從Wikipedia和Spotify收集重金屬數據

stack 的一些用法

IS環境下配置PHP5+MySql+PHPMyAdmin

