用戶體驗可視化指南pdf
Learning to build complete visualizations in R is like any other data science skill, it’s a journey. RStudio’s ggplot2 is a useful package for telling data’s story, so if you are newer to ggplot2 and would love to develop your visualizing skills, you’re in luck. I developed a pretty quick — and practical — guide to help beginners advance their understanding of ggplot2 and design a couple polished, business-insightful graphs. Because early success with visualizations can be very motivating!
學習在R中構建完整的可視化效果就像其他任何數據科學技能一樣,是一段旅程。 RStudio的ggplot2是一個有用的軟件包,用于講述數據的故事,因此,如果您是ggplot2的新手,并且希望發展自己的可視化技能,那么您會很幸運。 我開發了一個非常快速且實用的指南,以幫助初學者提高對ggplot2的理解,并設計一些精美的,具有業務洞察力的圖表。 因為可視化的早期成功會非常有激勵作用!
This tutorial assumes you have completed at least one introduction to ggplot2, like this one. If you haven’t, I encourage you to first to get some basics down.
本教程假定您至少已完成ggplot2的介紹, 例如本教程。 如果您還沒有,我鼓勵您首先了解一些基礎知識。
By the end of this tutorial you will:
在本教程結束時,您將:
- Deepen your understanding for enhancing visualizations in ggplot2 加深對ggplot2中可視化效果的理解
- Become familiar with navigating the ggplot2 cheat sheet (useful tool) 熟悉導航ggplot2備忘單(有用的工具)
- Build two original, polished visuals shown below through a simple, step-by-step format 通過簡單的分步格式構建兩個原始的,經過拋光的視覺效果,如下所示
Before we begin, here are a couple tools that can support your learning. The first is the ‘R Studio Data Visualization with ggplot2 cheat sheet’ (referred to as ‘cheat sheet’ from now on). We will reference it throughout to help you navigate it for future use.
在我們開始之前,這里有一些工具可以支持您的學習。 第一個是“帶有ggplot2備忘單的R Studio數據可視化”(從現在開始稱為“備忘單”)。 我們將始終引用它,以幫助您導航以備將來使用。
The second is a ‘ggplot2 Quick Guide’ I made to help me build ggplots on my own faster. It’s not comprehensive, but it may help you more quickly understand the big picture of ggplot2.
第二個是“ ggplot2快速指南 ” ,它旨在幫助我更快地自行構建ggplots。 它并不全面,但是可以幫助您更快地了解ggplot2的概況。
我們走吧! (Let’s go!)
For this tutorial, we will use the IBM HR Employee Attrition dataset, available here. This data offers (fictitious) business insight and requires no preprocessing. Sweet!
在本教程中,我們將使用IBM HR Employee Attrition數據集 , 可從此處獲得 。 該數據提供(虛擬的)業務洞察力,不需要進行預處理。 甜!
Let’s install libraries and import the data.
讓我們安裝庫并導入數據。
# install libraries
library(ggplot2)
library(scales)
install.packages("ggthemes")
library(ggthemes)# import data
data <- read.csv(file.path('C:YourFilePath’, 'data.csv'), stringsAsFactors = TRUE)Then check the data and structure.
然后檢查數據和結構。
# view first 5 rows
head(attrition)# check structure
str(attrition)Upon doing so, you will see that there are 1470 observations with 35 employee variables. Let’s start visual #1.
這樣做之后,您將看到有1470個觀察值和35個員工變量。 讓我們開始視覺#1。
視覺#1 (Visual #1)
HR wants to know how monthly income is related to employee attrition by job role.
人力資源部想知道按職位 劃分的月收入與員工流失之間的關系。
步驟1.數據,美學,幾何 (Step 1. Data, Aesthetics, Geoms)
For this problem, ‘JobRole’ is our X variable (discrete) and ‘MonthlyIncome’ is our Y variable (continuous). ‘Attrition’ (yes/no) is our z variable.
對于此問題,“ JobRole”是我們的X變量(離散),“ MonthlyIncome”是我們的Y變量(連續)。 “損耗”(是/否)是我們的z變量。
Check side 1 of your cheat sheet under ‘Two Variables: Discrete X, Continuous Y,’ and note the various graphs. We will use geom_bar(). On the cheat sheet, it’s listed as geom_bar(stat = ‘identity’). This would give us total monthly income of all employees. We instead want average, so we insert (stat = ‘summary’, fun = mean).
在“兩個變量:離散X,連續Y”下檢查備忘單的第一面,并記下各種圖形。 我們將使用geom_bar()。 在備忘單上,它被列為geom_bar(stat ='identity')。 這將給我們所有雇員的總月收入。 相反,我們想要平均值,所以我們插入(stat ='summary',fun = mean)。
# essential layers
ggplot(data, aes(x = JobRole, y = MonthlyIncome, fill=Attrition)) +
geom_bar(stat = 'summary', fun = mean) #Gives mean monthly income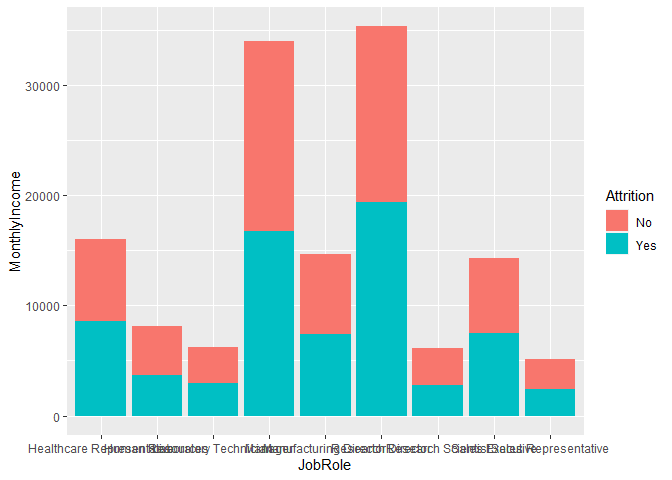
We obviously can’t read the names, which leads us to step 2…
我們顯然無法讀取名稱,這導致我們進入步驟2…
步驟2.座標和位置調整 (Step 2. Coordinates and Position Adjustments)
When names are too long, it often helps to flip the x and y axis. To do so, we will add coord_flip() as a layer, as shown below. We will also unstack the bars to better compare Attrition, by adding position = ‘dodge’ within geom_bar() in the code. Refer to the ggplot2 cheat sheet side 2, ‘Coordinate Systems’ and ‘Position Adjustments’ to see where both are located.
名稱太長時,通常有助于翻轉x和y軸。 為此,我們將添加coord_flip()作為圖層,如下所示。 通過在代碼的geom_bar()中添加position ='dodge',我們還將對這些條進行堆疊以更好地比較損耗。 請參考ggplot2備忘單第2面,“坐標系”和“位置調整”,以了解兩者的位置。
# unstack bars and flipping axis
ggplot(data, aes(x = JobRole, y = MonthlyIncome, fill=Attrition)) +
geom_bar(stat = ‘summary’, fun = mean, position = ‘dodge’) +
coord_flip()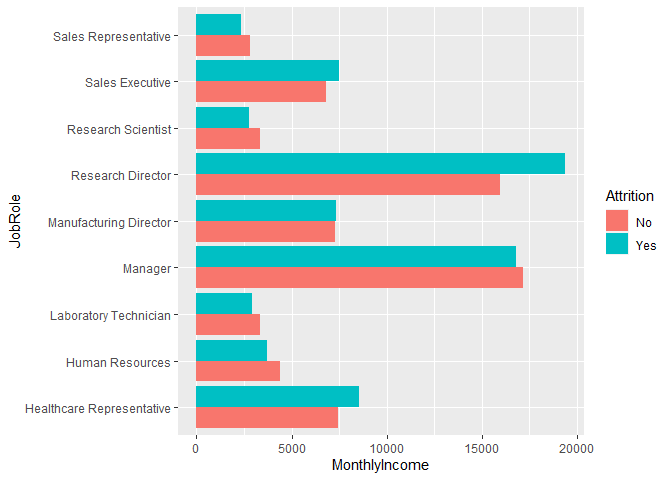
步驟3.從最高到最低重新排列條形 (Step 3. Reorder bars from highest to lowest)
Now, let’s reorder the bars from highest to lowest Monthly Income to help us better analyze by Job Role. Add the reorder code below within the aesthetics line.
現在,讓我們從月收入的最高到最低重新排序,以幫助我們更好地按工作角色進行分析。 在美學行中的下方添加重新訂購代碼。
# reordering job role
ggplot(data, aes(x = reorder(JobRole, MonthlyIncome), y = MonthlyIncome, fill = Attrition)) +
geom_bar(stat = 'summary', fun = mean, position = 'dodge') +
coord_flip()步驟4.更改條形顏色和寬度 (Step 4. Change bar colors and width)
Let’s change the bar colors to “match the company brand.” This must be done manually, so find scale_fill_manual() on side 2 of the cheat sheet, under “Scales.” It lists colors in base R. You can try some, but they aren’t “company colors.” I obtained the color #s below from color-hex.com.
讓我們更改條形顏色以“匹配公司品牌”。 這必須手動完成,因此請在備忘單第二側的“比例”下找到scale_fill_manual()。 它在基準R中列出了顏色。您可以嘗試一些,但它們不是“公司顏色”。 我從color-hex.com獲得以下顏色#。
Also, we will narrow the bar widths by adding ‘width=.8’ within geom_bar() to add visually-appealing space.
另外,我們將通過在geom_bar()中添加'width = .8'來縮小條形寬度,以增加視覺上吸引人的空間。
ggplot(data, aes(x = reorder(JobRole, MonthlyIncome), y = MonthlyIncome, fill = Attrition)) +
geom_bar(stat='summary', fun=mean, width=.8, position='dodge') +
coord_flip() +
scale_fill_manual(values = c('#96adbd', '#425e72'))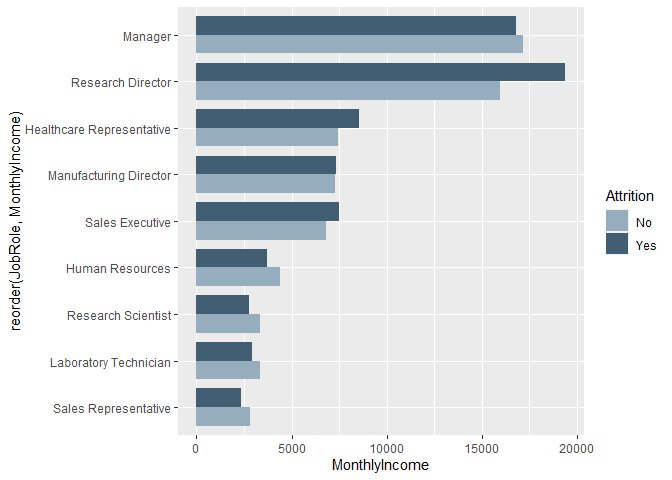
步驟5.標題和軸標簽 (Step 5. Title and Axis Labels)
Now let’s add Title and Labels. We don’t need an x label since the job titles explain themselves. See the code for how we handled. Also, check out “Labels” on side 2 of the cheat sheet.
現在讓我們添加標題和標簽。 我們不需要x標簽,因為職位說明了自己。 請參閱代碼以了解我們的處理方式。 另外,請檢查備忘單第二面的“標簽”。
ggplot(data, aes(x = reorder(JobRole, MonthlyIncome), y = MonthlyIncome, fill = Attrition)) +
geom_bar(stat='summary', fun=mean, width=.8, position='dodge') +
coord_flip() +
scale_fill_manual(values = c('#96adbd', '#425e72')) +
xlab(' ') + #Removing x label
ylab('Monthly Income in USD') +
ggtitle('Employee Attrition by Job Role & Income')步驟6.添加主題 (Step 6. Add Theme)
A theme will kick it up a notch. We will add a theme layer at the end of our code, as shown below. When you start typing ‘theme’ in R, it shows options. For this graph, I chose theme_clean()
一個主題將使它提升一個等級。 我們將在代碼末尾添加一個主題層,如下所示。 當您開始在R中鍵入“主題”時,它會顯示選項。 對于此圖,我選擇了theme_clean()
#Adding theme after title
ggtitle('Employee Attrition by Job Role & Income') +
theme_clean()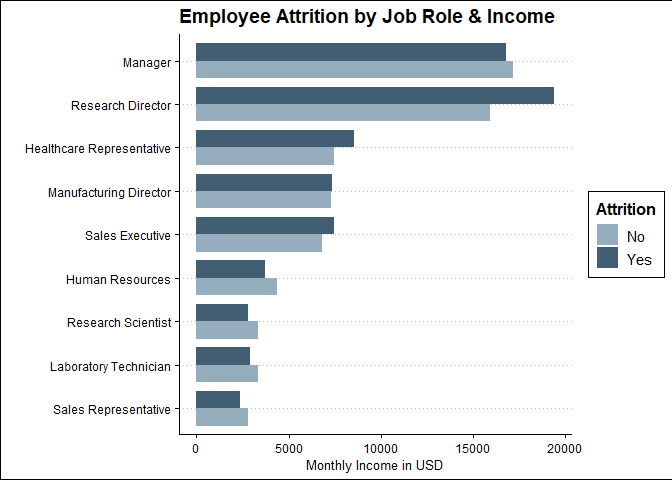
步驟7.降低圖形高度并使輪廓不可見 (Step 7. Reduce graph height and make outlines invisible)
Just two easy tweaks. First, we will remove the graph and legend outlines. Second, the graph seems tall, so let’s reduce the height via aspect.ratio within theme(). Here is the full code for the final graph.
只需兩個簡單的調整。 首先,我們將刪除圖形和圖例輪廓。 其次,圖形看起來很高,因此讓我們通過theme()中的Aspect.ratio降低高度。 這是最終圖形的完整代碼。
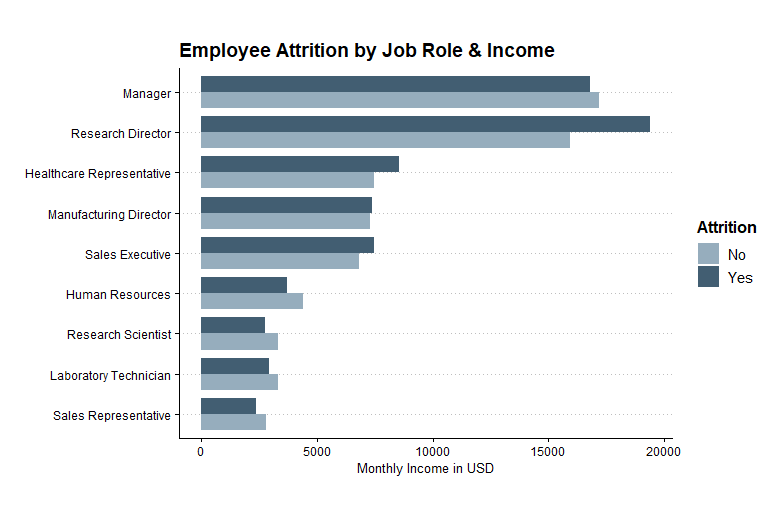
ggplot(data, aes(x = reorder(JobRole, MonthlyIncome), y = MonthlyIncome, fill = Attrition)) +
geom_bar(stat='summary', fun=mean, width=.8, position='dodge') +
coord_flip() +
scale_fill_manual(values = c('#96adbd', '#425e72')) +
xlab(' ') +
ylab('Monthly Income in USD') +
ggtitle('Employee Attrition by Job Role & Income') +
theme_clean() +
theme(aspect.ratio = .65,
plot.background = element_rect(color = 'white'),
legend.background = element_rect(color = 'white'))Nice. We see that Research Directors who make more in monthly income are more likely to leave the company. The opposite is the case for other job roles.
真好 我們發現,月收入更高的研究主管更有可能離開公司。 其他工作角色則相反。
You’ve accomplished a lot. Ready for another go? Visual 2 walk-through will be a piece of cake.
您已經取得了很多成就。 準備再去嗎? Visual 2演練將是小菜一碟。
視覺#2 (Visual #2)
For the second visual, we want to know if employee attrition has any relationship to monthly income, years since last promotion, and work-life balance. Another multivariate analysis.
對于第二個視覺圖像,我們想知道員工的流失是否與月收入 , 自上次升職以來 的年限以及工作與生活的平衡有關。 另一個多元分析。
步驟1.數據,美學,幾何 (Step 1. Data, Aesthetics, Geoms)
For this problem, ‘MonthlyIncome’ is our X and ‘YearsSinceLastPromotion’ is our Y variable. Both are continuous, so check side 1 of your cheat sheet under ‘Two Variables: Continuous X, Continuous Y.’ For visualization context, we will use geom_smooth(), a regression line often added to scatter plots to reveal patterns. ‘Attrition’ will again be differentiated by color.
對于此問題,“ MonthlyIncome”是我們的X,“ YearsSinceLastPromotion”是我們的Y變量。 兩者都是連續的,因此請檢查備忘單第1面的“兩個變量:連續X,連續Y”。 對于可視化上下文,我們將使用geom_smooth(),這是一條通常添加到散點圖中以揭示模式的回歸線。 “損耗”將再次通過顏色區分。
ggplot(data, aes(x=MonthlyIncome, y=YearsSinceLastPromotion, color=Attrition)) +
geom_smooth(se = FALSE) #se = False removes confidence shading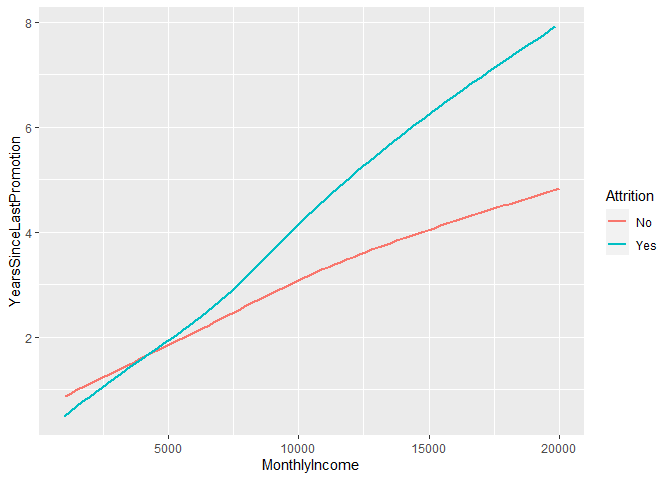
We can see that employees who leave are promoted less often. Let’s delve deeper and compare by work-life balance. For this 4th variable, we need to use ‘Faceting’ to view subplots by work-life balance level.
我們可以看到,離職的員工升職的頻率降低了。 讓我們深入研究并通過工作與生活之間的平衡進行比較。 對于第四個變量,我們需要使用“ Faceting”以按工作與生活的平衡水平查看子圖。
步驟2.刻面將子圖添加到畫布 (Step 2. Faceting to add subplots to the canvas)
Check out ‘Faceting’ on side 2 of the cheat sheet. We will use facet_wrap() for a rectangular layout.
檢查備忘單第二面的“ Faceting”。 我們將facet_wrap()用于矩形布局。
ggplot(data, aes(x = MonthlyIncome, y = YearsSinceLastPromotion, color=Attrition)) +
geom_smooth(se = FALSE) +
facet_wrap(WorkLifeBalance~.)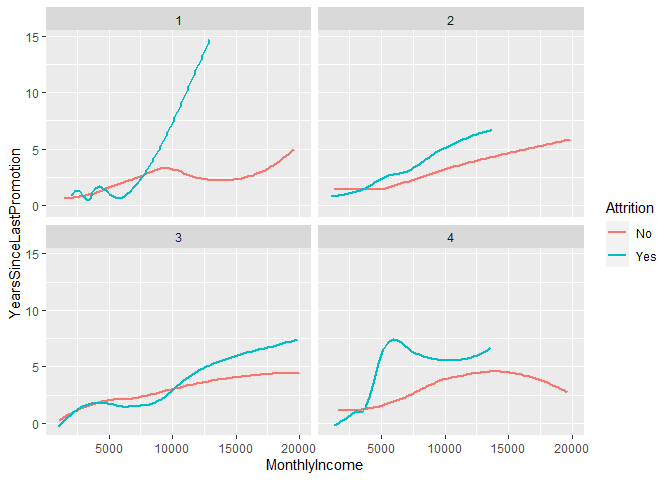
The facet grids look good, but what do the numbers mean? The data description explains the codes for ‘WorkLifeBalance’: 1 = ‘Bad’, 2 = ‘Good’, 3 = ‘Better’, 4 = ‘Best’. Add them in step 3.
刻面網格看起來不錯,但是數字意味著什么? 數據說明解釋了“ WorkLifeBalance”的代碼:1 =“差”,2 =“好”,3 =“更好”,4 =“最好”。 在步驟3中添加它們。
步驟3.將標簽添加到構面子圖 (Step 3. Add Labels to Facet Subplots)
To add subplot labels, we need to first define the names with a character vector, then use the ‘labeller’ function within facet_wrap.
要添加子圖標簽,我們需要首先使用字符向量定義名稱,然后在facet_wrap中使用'labeller'函數。
# define WorkLifeBalance values
wlb.labs <- c('1' = 'Bad Balance', '2' = 'Good Balance', '3' = 'Better Balance', '4' = 'Best Balance')#Add values to facet_wrap()
ggplot(data, aes(x = MonthlyIncome, y = YearsSinceLastPromotion, color=Attrition)) +
geom_smooth(se = FALSE) +
facet_wrap(WorkLifeBalance~.,
labeller = labeller(WorkLifeBalance = wlb.labs))步驟4.標簽和標題 (Step 4. Labels and Title)
Add your labels and title at the end of your code.
在代碼末尾添加標簽和標題。
facet_wrap(WorkLifeBalance~.,
labeller = labeller(WorkLifeBalance = wlb.labs)) +
xlab('Monthly Income') +
ylab('Years Since Last Promotion') +
ggtitle('Employee Attrition by Workplace Factors')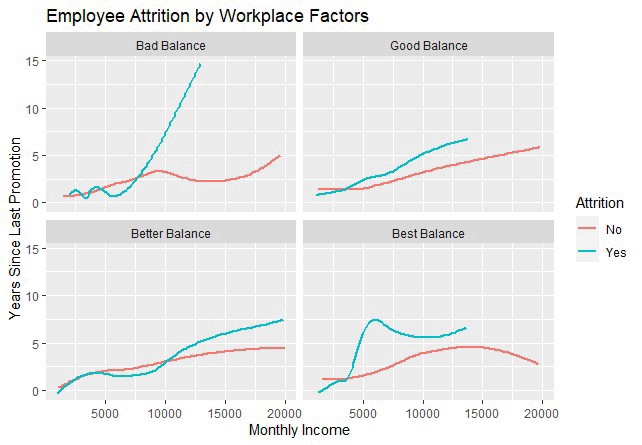
步驟5.在標簽和刻度標記之間添加空格 (Step 5. Add Space Between Labels and Tick Markers)
When I look at the graph, the x and y labels seem too close to the tick markers. A simple trick is to insert newline (\n) code within label names.
當我查看圖表時,x和y標簽似乎太靠近刻度線標記。 一個簡單的技巧是在標簽名稱中插入換行(\ n)代碼。
xlab('\nMonthly Income') + #Adds space above label
ylab('Years Since Last Promotion\n') #Adds space below label步驟6.主題 (Step 6. Theme)
When you installed library(‘ggthemes’), it gave you more options. For a modern look, I went with theme_fivethirtyeight(). Simply add at the end.
當您安裝庫('ggthemes')時,它為您提供了更多選擇。 對于現代外觀,我選擇了theme_fivethirtyeight()。 只需在末尾添加即可。
ggtitle('Employee Attrition by Workplace Factors') +
theme_fivethirtyeight()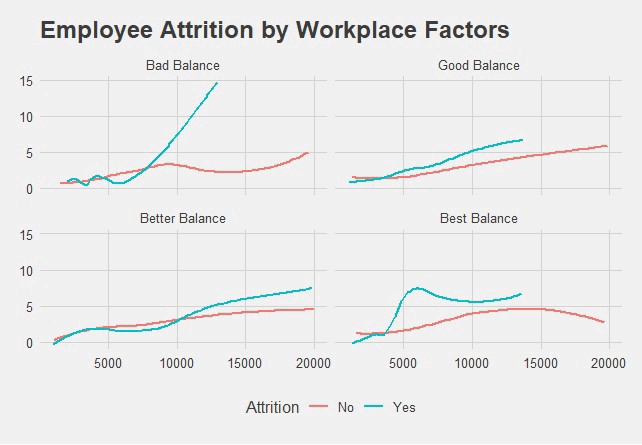
步驟7.覆蓋主題默認值 (Step 7. Override a Theme Default)
What happened to our x and y labels? Well, the default for theme_fivethirtyeight() doesn’t have labels. But we can easily override that with a second theme() layer at the end of your code as shown below.
我們的x和y標簽發生了什么? 好吧,theme_fivethirtyeight()的默認值沒有標簽。 但是我們可以在代碼末尾的第二個theme()層輕松覆蓋它,如下所示。
theme_fivethirtyeight() +
theme(axis.title = element_text())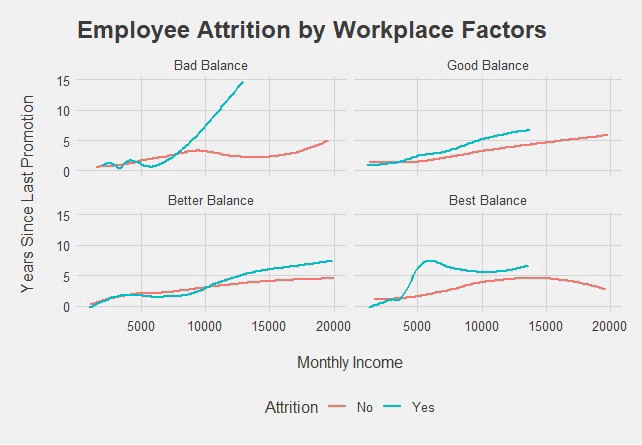
Not bad. But…people may not be able to tell if ‘Better Balance’ and ‘Best Balance’ are for the top or bottom grids right away. Let’s also change our legend location in step 8.
不錯。 但是……人們可能無法立即判斷出“最佳平衡”和“最佳平衡”是用于頂部還是底部網格。 我們還要在步驟8中更改圖例位置。
步驟8.在網格之間添加空間并更改圖例位置 (Step 8. Add Space Between Grids and Change Legend Location)
Adding space between top and bottom grids and changing the legend location both occur within the second theme() line. See side 2 of cheat sheet under ‘Legends.’
在頂部和底部網格之間添加空間并更改圖例位置都在第二個theme()行內。 請參閱“傳奇”下備忘單的第二面。
theme_fivethirtyeight() +
theme(axis.title = element_text(),
legend.position = 'top',
legend.justification = 'left',
panel.spacing = unit(1.5, 'lines'))步驟9。更改線條顏色 (Step 9. Change Line Color)
It would be awesome to change line colors to pack a visual punch. Standard R colors don’t quite meet our needs. We will change manually just like we did with Visual #1. I obtained the colors #s from color-hex.com, which has become a useful tool for us.
更改線條顏色以增加視覺沖擊力真是太棒了。 標準R顏色不能完全滿足我們的需求。 我們將像使用Visual#1一樣手動進行更改。 我從color-hex.com獲得了顏色#,它已成為我們的有用工具。
Here is the full code for the second visual.
這是第二個視覺效果的完整代碼。
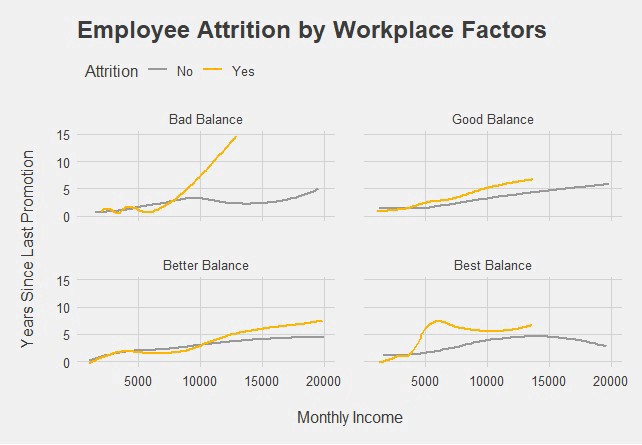
ggplot(data, aes(x = MonthlyIncome, y = YearsSinceLastPromotion, color=Attrition)) +
geom_smooth(se = FALSE) +
facet_wrap(WorkLifeBalance~.,
labeller = labeller(WorkLifeBalance = wlb.labs)) +
xlab('\nMonthly Income') +
ylab('Years Since Last Promotion\n') +
theme_ggtitle('Employee Attrition by Workplace Factors') +
theme_fivethirtyeight() +
theme(axis.title = element_text(),
legend.position = 'top',
legend.justification = 'left',
panel.spacing = unit(1.5, 'lines')) +
scale_color_manual(values = c('#999999','#ffb500'))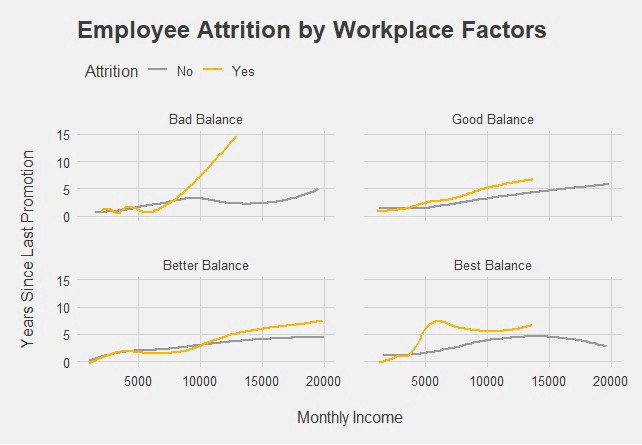
Another job well done. We see that employees in roles lacking work-life balance seem to stay if promotions are more frequent. The difference in attrition is less noticeable in good or higher work-life balance levels.
另一項工作做得很好。 我們看到,如果升職更加頻繁,則缺乏工作與生活平衡的角色的員工似乎會留下來。 在良好或較高的工作與生活平衡水平下,損耗的差異不太明顯。
In this tutorial, we gained skills needed for ggplot2 visual enhancement, became more familiar with the R Studio ggplot2 cheat sheet, and built two nice visuals. I hope that the step-by-step explanations and cheat sheet referencing were helpful and enhanced your confidence using ggplot2.
在本教程中,我們獲得了ggplot2視覺增強所需的技能,對R Studio ggplot2備忘單更加熟悉,并構建了兩個不錯的視覺效果。 我希望逐步說明和備忘單參考對您有所幫助,并使用ggplot2增強您的信心。
Many are helping me as I advance my data science and machine learning skills, so my goal is to help and support others in the same way.
隨著我提高數據科學和機器學習技能,許多人正在幫助我,所以我的目標是以同樣的方式幫助和支持他人。
翻譯自: https://towardsdatascience.com/beginners-guide-to-enhancing-visualizations-in-r-9fa5a00927c9
用戶體驗可視化指南pdf
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/388435.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/388435.shtml 英文地址,請注明出處:http://en.pswp.cn/news/388435.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

nodeJS 開發微信公眾號

單招計算機應用基礎知識考試,四川郵電職業技術學院單招計算機應用基礎考試大綱...

linux掛載磁盤陣列

dedecms ---m站功能基礎詳解

一個小菜鳥給未來的菜鳥們的一丟丟建議
)
sql橫著連接起來sql_SQL聯接的簡要介紹(到目前為止)

霸縣計算機學校,廊坊中專排名2021

《Python》進程收尾線程初識

北京修復宕機故障之旅

計算機學院李世杰,有關辦理2016級轉專業學生相關手續通知

一般線性模型和混合線性模型_從零開始的線性混合模型

《企業私有云建設指南》-導讀

vs2005的webbrowser控件如何接收鼠標事件
![[TimLinux] Python 迭代器(iterator)和生成器(generator)](http://pic.xiahunao.cn/[TimLinux] Python 迭代器(iterator)和生成器(generator))
[TimLinux] Python 迭代器(iterator)和生成器(generator)

太原冶金技師學院計算機系,山西冶金技師學院專業都有什么

海南首例供港造血干細胞志愿者啟程赴廣東捐獻

如何擊敗Python的問題

KindEditor解決上傳視頻不能在手機端顯示的問題

湖北經濟學院的計算機是否強,graphics-ch11-真實感圖形繪制_湖北經濟學院:計算機圖形學_ppt_大學課件預覽_高等教育資訊網...
