醫療大數據處理流程
Note: the fictitious examples and diagrams are for illustrative purposes ONLY. They are mainly simplifications of real phenomena. Please consult with your physician if you have any questions.
注意:虛擬示例和圖表僅用于說明目的。 它們主要是真實現象的簡化。 如有任何疑問,請咨詢您的醫生。
Scale is one of the main challenges in public health services. Specialized treatments are hard to track when applied to thousands of patients. Fortunately, we can now identify bottlenecks and errors in the flow of these processes at scale. Through the combination of Process Modelling and Probabilistic Modelling, precision medicine and stratified healthcare has achieved state-of-the-art results like parallel process consolidation, task connections, and task pruning.
規模是公共衛生服務的主要挑戰之一。 當應用于數以千計的患者時,難以追蹤專業治療。 幸運的是,我們現在可以大規模地識別這些流程中的瓶頸和錯誤。 通過將過程建模和概率建模相結合,精密醫學和分層醫療保健已取得了最新成果,例如并行過程合并,任務連接和任務修剪。
Process modeling helps structure a series of steps to perform a task.
流程建模有助于構造一系列步驟以執行任務。
In the real world, tasks can run in parallel or series. Processes can have loops, divergent and convergent paths, and unnecessary steps.
在現實世界中,任務可以并行或串行運行。 流程可以具有循環,分歧和收斂的路徑以及不必要的步驟。
Process modeling discovers such complexities and improves upon them. Improving our process models is important since the main objective of stratified healthcare and precision medicine is to achieve an individual, precise and complete treatment for each patient. Stratified healthcare refers to the practice of offering a robust infrastructure to treat patients, while precision medicine seeks to improve the health of individual patients through personalized treatments.
流程建模發現了這種復雜性并對其進行了改進。 改進我們的過程模型非常重要,因為分層醫療保健和精密醫學的主要目標是為每位患者提供個性化,精確和完整的治療。 分層醫療保健是指提供強大的基礎設施來治療患者的實踐,而精密醫學則致力于通過個性化治療來改善單個患者的健康。
Personalized treatments are a reality, thanks to the Human Genome Project. The Human Genome Project demonstrates that no human is made the same. Therefore, prescriptions and treatments cause different reactions in each individual. Modeling processes allow us to reflect this reality in paper. However, this method is not perfect.
得益于人類基因組計劃,個性化治療成為現實。 人類基因組計劃表明,沒有任何一個人類是一樣的。 因此,處方和治療在每個人中引起不同的React。 建模過程使我們能夠在紙上反映這一現實。 但是,這種方法并不完美。
While processes in health go through rigorous statistical tests, they are by no means rid of bias. This bias can impact the flow of steps or parallelism that could be applied to optimize positive outcomes or the speed of the treatments. Additionally, the tools and tests in operations and treatments evolve with time, which shortens steps or reduces the time overhead in these tasks. Updating each process model every time a breakthrough is validated by experts consumes a lot of time.
盡管健康過程經過嚴格的統計檢驗,但絕不能消除偏見。 這種偏見會影響可用于優化陽性結果或治療速度的步驟或并行性流程。 此外,手術和治療中的工具和測試會隨著時間而發展,從而縮短了步驟或減少了這些任務的時間開銷。 每當專家驗證突破性進展時,更新每個流程模型都會花費大量時間。
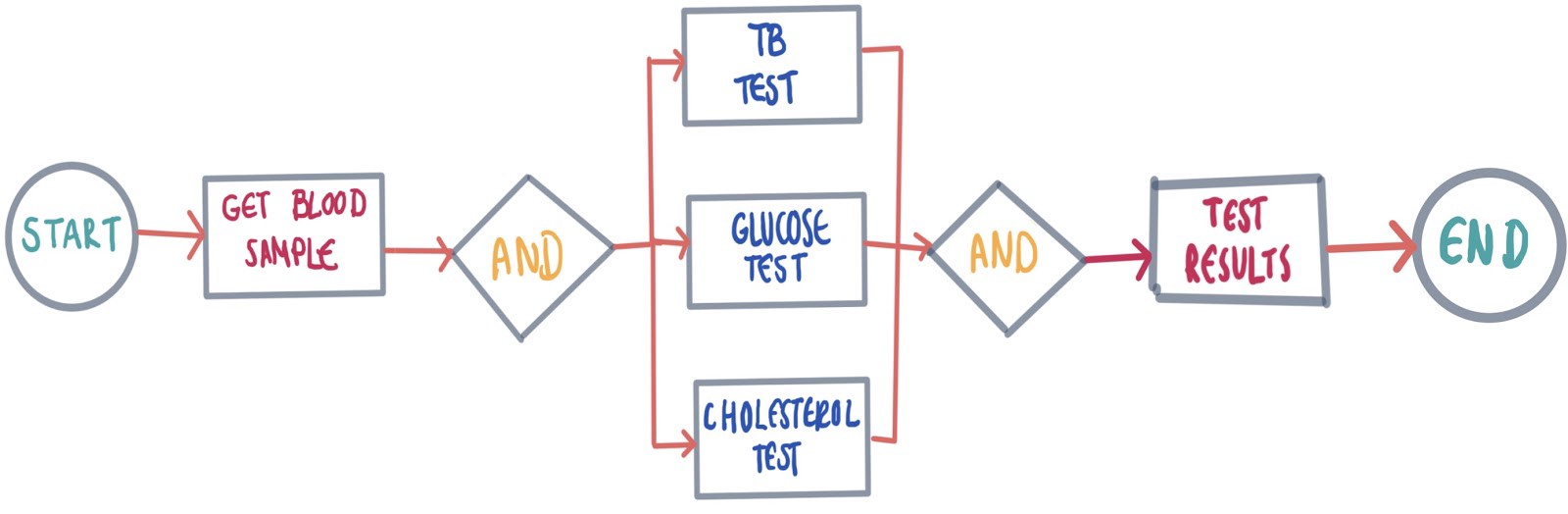
For example, imagine we currently have these personalized brain imaging processes for 5 patients with a brain tumor:
例如,假設我們目前有針對5位腦腫瘤患者的以下個性化大腦成像過程:
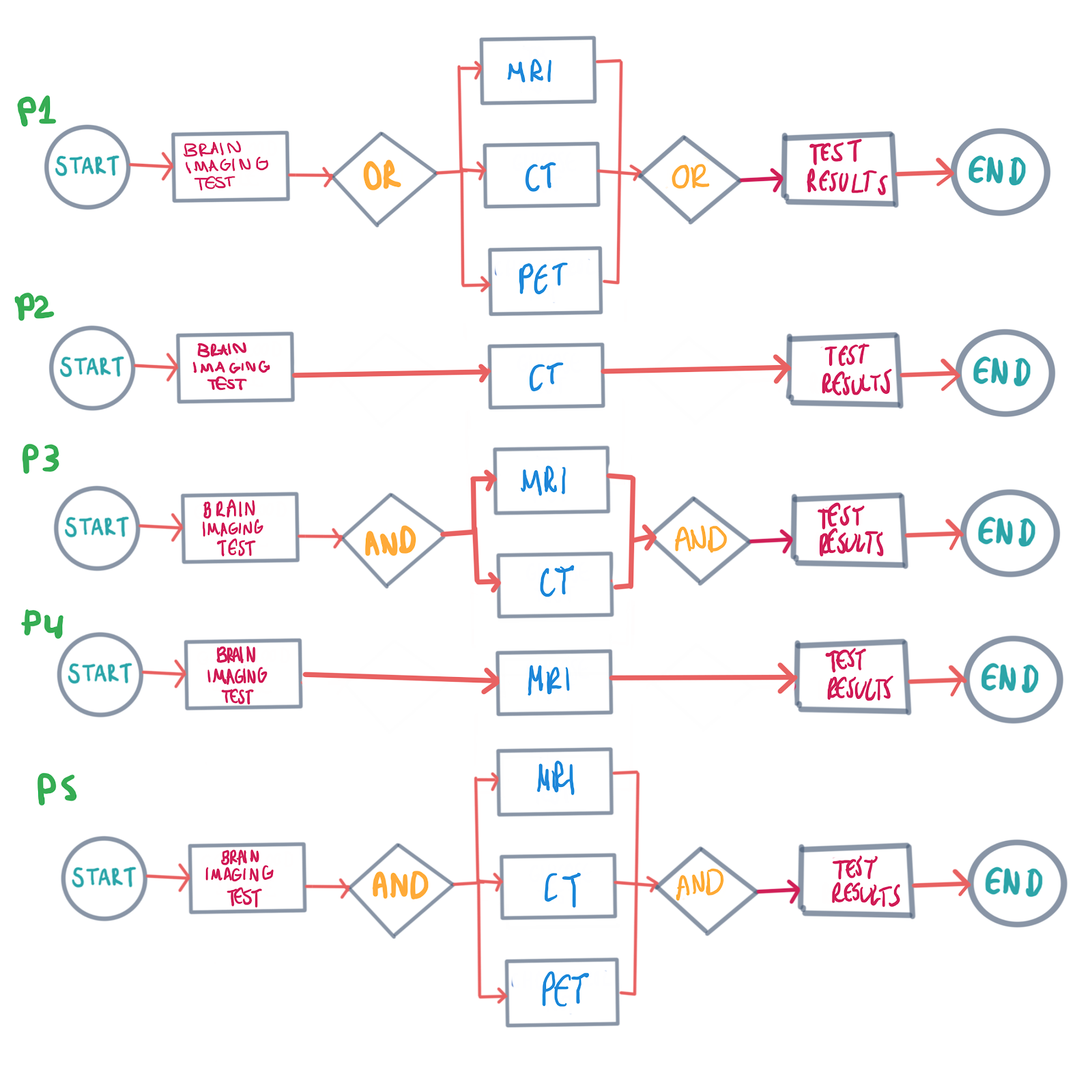
Let’s say we have a new technology called BrainImagingx2, which scans a patient’s tumor size two times faster than the current brain imaging technology, but it’s only precise for patients that can handle both MRI and CT scans periodically:
假設我們擁有一項名為BrainImagingx2的新技術,該技術可掃描患者的腫瘤大小,其速度是當前腦部成像技術的兩倍,但這僅適用于可同時處理MRI和CT掃描的患者:
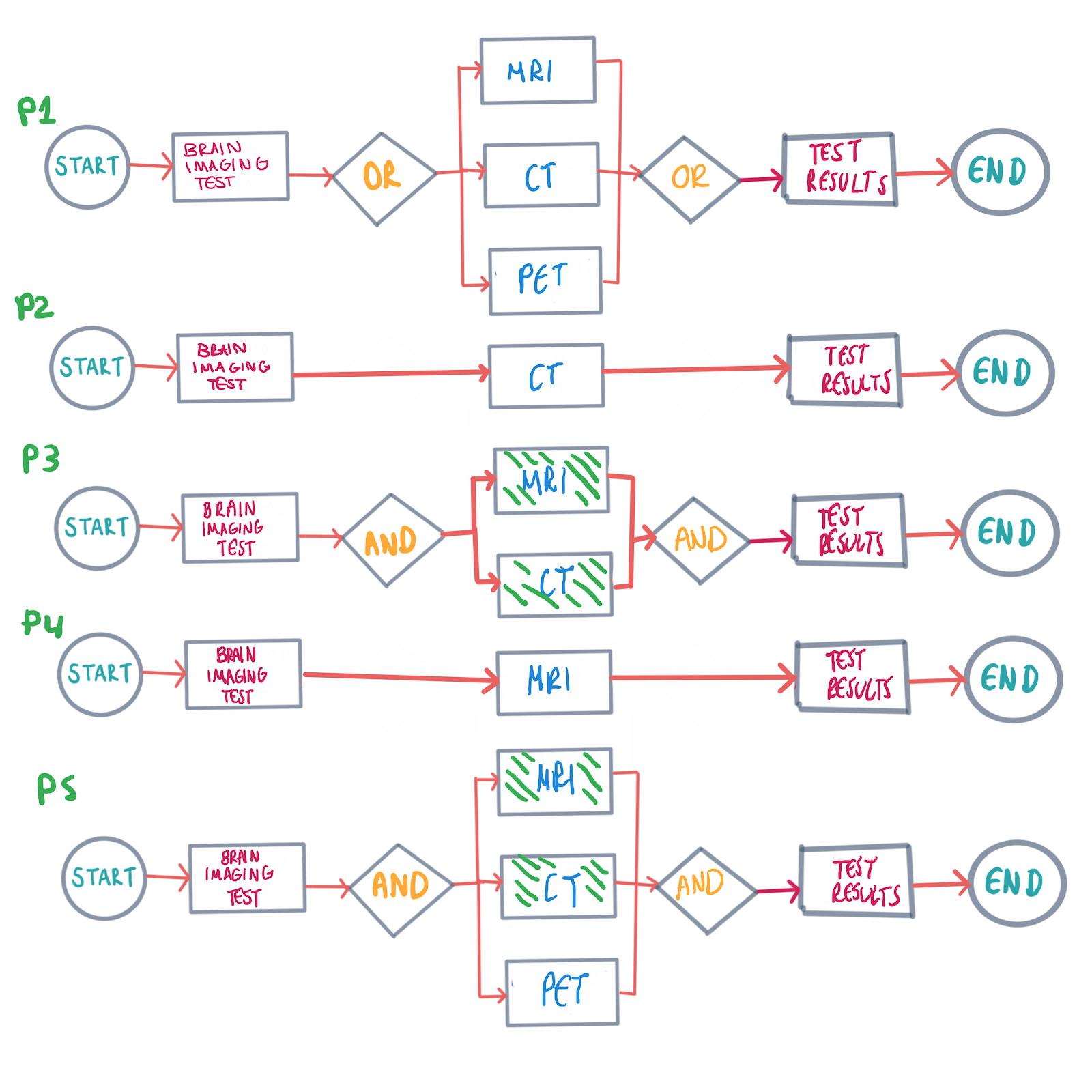
Naturally, we want to update our 5 model processes. This might be easy to do since we’re dealing with only 5 patients at this time. We can review each case manually to evaluate the risk of updating the process model and weigh it against the benefit:
自然,我們要更新5個模型流程。 這可能很容易實現,因為我們目前僅處理5名患者。 我們可以手動檢查每個案例,以評估更新流程模型的風險,并將其與收益進行權衡:
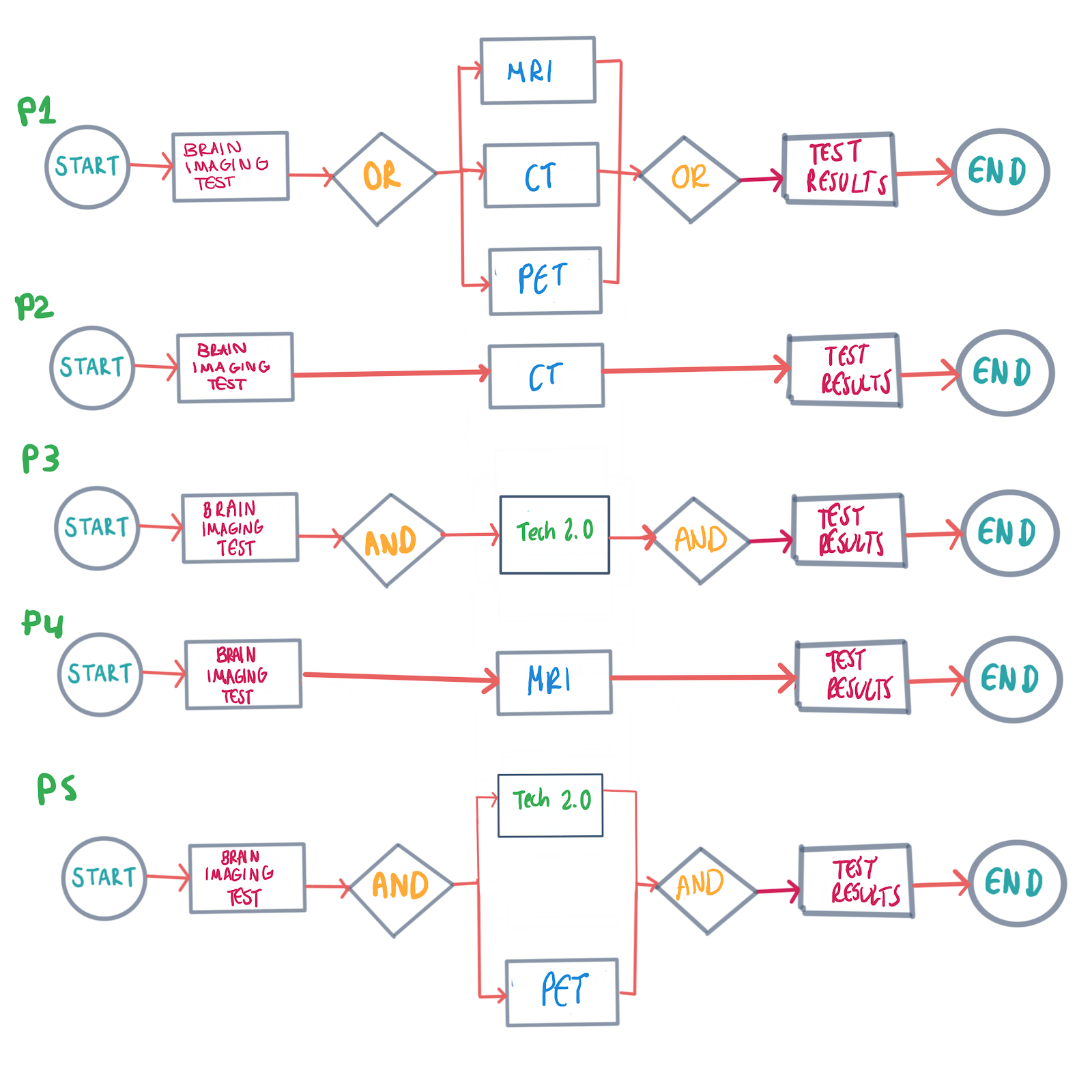
But what happens if suddenly our 5 patients turn into 1,000 different and unique patients, each with their medical history and background? The cost of evaluating each process model manually skyrockets. Even worse, maybe one of our 1,000 patients has a great risk of damage if exposed to the new technology in BrainImagingx2, like electromagnetic fields. Under these conditions, we can’t generalize or skip updating models for time and effort optimization. In summary, process modeling’s key issue is time and effort from analyzing existing models thoroughly and updating models with time. This gets worse when the number of patient profiles, and therefore the processes modeled increase with scale.
但是,如果我們的5名患者突然變成1000名不同且獨特的患者,每個患者都有其病史和背景,會發生什么? 手動評估每個流程模型的成本激增。 更糟糕的是,如果暴露于BrainImagingx2的新技術(例如電磁場)中,我們的1000名患者中可能會有一個遭受損壞的風險很高。 在這種情況下,我們無法概括或跳過更新模型以節省時間和精力。 總而言之,流程建模的關鍵問題是從徹底分析現有模型并隨時間更新模型中所花費的時間和精力。 當患者檔案的數量增加時,情況變得更糟,因此建模的過程隨規模的增加而增加。
Process mining achieves an automated “understanding” of the processes through the analysis of event logs and expert reviews to approximate processes. Rather than attempting to update existing models, it builds models from the data it is fed. The process of generating updated process models is thus faster. However, it’s not a perfect approach. Process mining outputs a greater number of personalized healthcare models. However, generalization or aggregation can still happen since most process mining techniques rely on process analysis, which automatically filters, sorts and compresses the logs fed to the process. We need to avoid generalizing the aggregation of our information to not obscure the edge case illnesses and response our patients could have as a result of their unique genetic composition like we discussed as a fact through the breakthrough of the Human Genome Project.
流程挖掘通過事件日志分析和專家評審來近似流程,從而實現流程的自動化“理解”。 與其嘗試更新現有模型,不如從饋送的數據構建模型。 因此,生成更新的過程模型的過程更快。 但是,這不是一個完美的方法。 流程挖掘輸出了大量個性化的醫療保健模型。 但是,由于大多數流程挖掘技術都依賴于流程分析,因此一般化或聚合仍然可能發生,流程分析會自動過濾,分類和壓縮饋送到流程的日志。 我們需要避免概括我們的信息匯總,以免掩蓋邊緣病例的疾病和患者由于其獨特的遺傳組成而可能產生的React,就像我們通過人類基因組計劃的突破所討論的那樣。
Another limitation to take into account is that this is an automated method that relies on data, and the quality of the process models exported is directly related to the quality of the information it is fed. The combined data of patients around the world have variance and noise. The different scales (the what), and sometimes even standards of the measurements (the how) impact what we see. Additionally, Electronic Health Records are not always available across the world, so inconsistencies between global records are highly likely. Missing data greatly degrades the quality of these models. Language disparity obscures the understanding learned through these data mining-based approaches.
要考慮的另一個限制是,這是一種依賴數據的自動化方法,并且導出的流程模型的質量直接與其所饋送信息的質量有關。 世界各地患者的綜合數據存在差異和噪音。 不同的比例(什么),有時甚至是度量標準(如何)也會影響我們所看到的。 此外,電子病歷在世界范圍內并不總是可用的,因此全球病歷之間很可能存在不一致之處。 數據丟失會大大降低這些模型的質量。 語言差異掩蓋了通過這些基于數據挖掘的方法學到的理解。

Source: https://www.apadivisions.org/division-31/publications/records/intake
資料來源: https : //www.apadivisions.org/division-31/publications/records/intake
We can combine Process Modelling, namely Process Mining, with Probabilistic Modelling to better mitigate these issues. Probabilistic modeling takes uncertainty into account, treating it as noise. A probabilistic model gives a distribution of possible outcomes. By modeling outcomes as likelihoods, the uncertainty is quantified to be further addressed and corrected by statistical methods.
我們可以將過程建模(即過程挖掘)與概率建模相結合,以更好地緩解這些問題。 概率建模將不確定性考慮在內,將其視為噪聲。 概率模型給出了可能結果的分布。 通過將結果建模為可能性,可以量化不確定性,以便通過統計方法進一步解決和糾正。
Probabilistic Modelling assumes a relationship between the outcome and the independent variable, however, this is something that needs to be proven. Correlation coefficients and regression analysis are used to perform hypothesis tests. While correlation measures the degree of association between two variables, other methods like regression measures the predictive power of the independent variable should the relationship be represented by a mathematical model. Probabilistic methods assume a model to account for noise and to make inferences based on these models.
概率建模假設結果與自變量之間存在關系,但是,這需要加以證明。 相關系數和回歸分析用于執行假設檢驗。 雖然相關性度量兩個變量之間的關聯度,但其他方法(如回歸)可以度量自變量的預測能力(如果該關系由數學模型表示)。 概率方法假設一個模型來考慮噪聲并基于這些模型進行推斷。
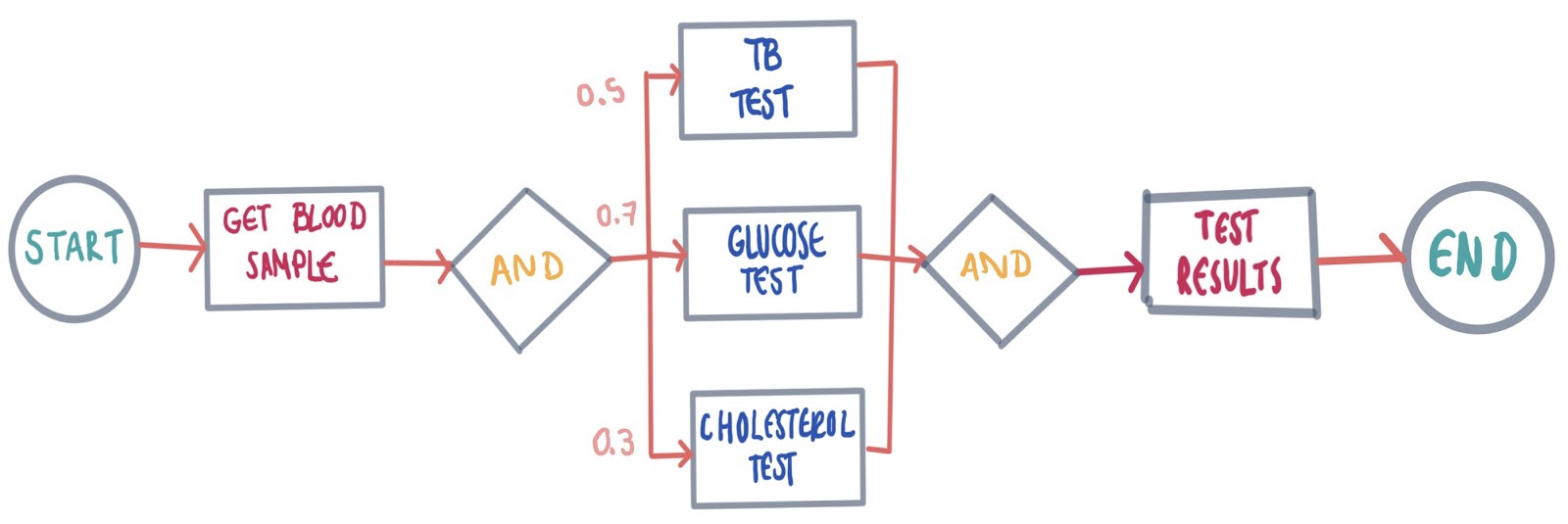
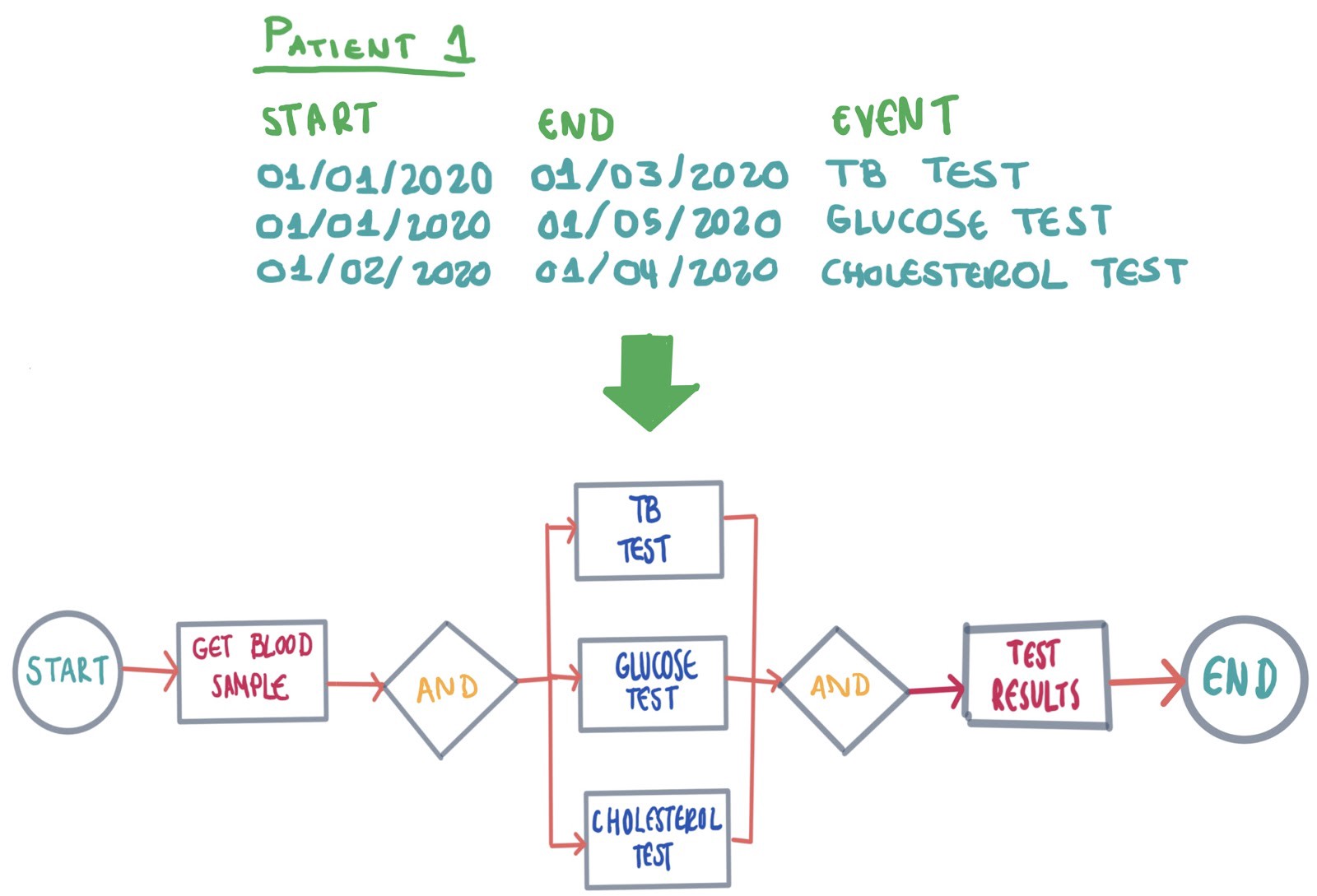
To combine both Process Modelling and Probabilistic Modelling, we can represent similar healthcare processes through a single diagram, which is the result of grouping similar patient task histories. In this diagram, each state transitions to multiple states. Each transition has a probability based on the data that was grouped. This way, even if the models are inconsistent with reality, they can be reviewed easily.
結合過程建模和概率建模,我們可以通過單個圖表表示相似的醫療過程,這是對相似的患者任務歷史進行分組的結果。 在此圖中,每個狀態都轉換為多個狀態。 每個轉換都有一個基于分組數據的概率。 這樣,即使模型與現實不一致,也可以輕松地對其進行檢查。
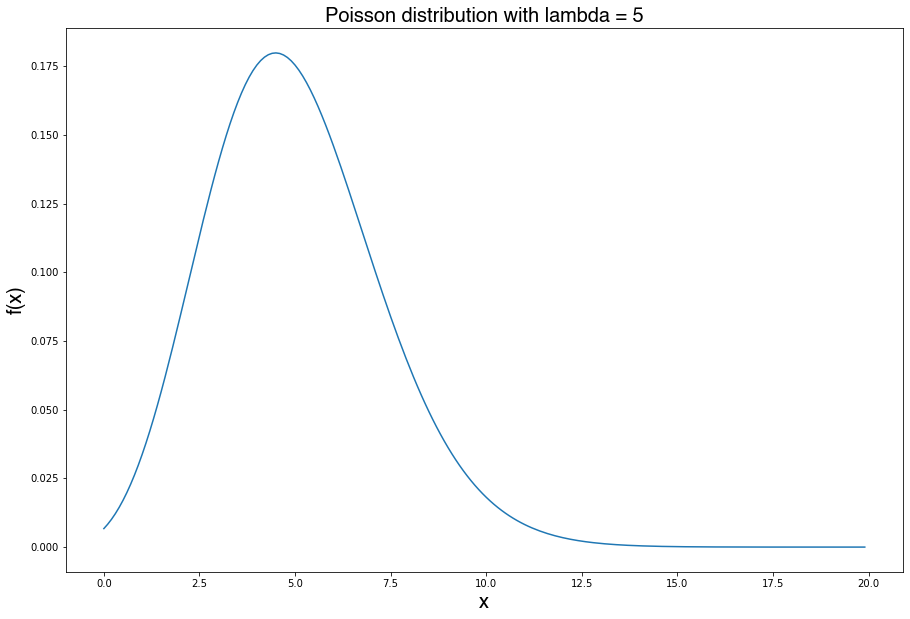
Additionally, statistical methods probability distribution fitting can be used to find the distribution that best fits the process modeled. Some examples of these distributions include the Poisson distribution for discrete variables like the task of vaccinating a patient and the Exponential and Gamma distributions for continuous variables like the process of assessing the levels of cholesterol in the body of a patient. Systems with queues, like those of a coffee shop, a computer server, and more specifically a health clinic can be modeled as probabilities through the theory of Queuing Systems, which incorporate the aforementioned probability distributions. By fitting a distribution, you can determine to which degree the outcomes in your processes are due to chance or not, which helps trim down or update the tasks in processes that matter in healthcare.
此外,可以使用統計方法概率分布擬合來找到最適合建模過程的分布。 這些分布的一些示例包括離散變量的Poisson分布(如為患者接種疫苗的任務)和連續變量的指數和Gamma分布(如評估患者體內膽固醇水平的過程)。 可以通過排隊系統的理論將帶有隊列的系統(例如咖啡店,計算機服務器的系統,更具體地說是健康診所的系統)建模為概率,該系統結合了上述概率分布。 通過擬合分布,您可以確定過程中的結果是否由于偶然而導致,這有助于縮減或更新對醫療保健至關重要的過程中的任務。
Some of the latest applications of Probability Modelling in Process Modelling include dealing with invisible prime tasks through rules and equations utilizing the probability of state transition of Coupled Hidden Markov and double time-stamped in event logs. Invisible prime tasks are usually run in parallel, and it’s hard to map this parallelism from raw logs back to XOR or AND gates in the diagrams without manual reviews. Through Coupled Hidden Markov Models, “wherein all of states from each Hidden Markov Model are dependent on the states of all Hidden Markov Model in previous time slice”, mapping logs back to process diagrams can now include such parallel tasks. (Sarno & Sungkono, 2016)
流程建模中概率建模的一些最新應用包括通過規則和方程式處理不可見的主要任務,這些規則和方程式利用耦合隱馬爾可夫狀態轉換的概率和事件日志中的雙重時間戳記。 看不見的主要任務通常并行運行,并且在沒有人工檢查的情況下,很難將這種并行性從原始日志映射回圖中的XOR或AND門。 通過耦合隱馬爾可夫模型,“其中每個隱馬爾可夫模型的所有狀態都取決于先前時間片中所有隱馬爾可夫模型的狀態”,映射回流程圖的流程現在可以包括此類并行任務。 (Sarno和Sungkono,2016)
New learning methods for process mining based on probability modeling include using a logistic regression model for the discovery of direct connections between events in event logs with noise. (Maruster et al., 2002) Logistic regression addresses noise by treating the occurrence of events as a binary outcome calculated with the independent variable mapped to the sigmoid function, that for extreme positive values still gives a 1 and for extreme negative values still gives a 0. Even so, this function exports a probability as a continuous variable which allows us to show experts the probability of connecting events A and B, allowing further assessment if needed.
基于概率模型的過程挖掘的新學習方法包括使用邏輯回歸模型來發現帶有噪聲的事件日志中事件之間的直接聯系。 (Maruster et al。,2002)Logistic回歸通過將事件的發生視為二進制結果來處理噪聲,該結果使用映射到S型函數的自變量進行計算,對于極高的正值仍然給出1,對于極度的負值仍然給出1。 0。即使這樣,此函數也將概率導出為連續變量,這使我們可以向專家顯示將事件A和B聯系起來的概率,并在需要時進行進一步評估。
There’s a classic machine learning example that illustrates the limitations of using probabilistic methods in process mining: you can’t say a cancer test classifier is good enough if it predicts that someone doesn’t have cancer 90% of the time. This applies to models learned through Probabilistic Modelling in Process Mining. If you have event logs that indicate that 90% of the time after a test you should give a negative result for cancer, what does this probability mean? Let’s assume for a second that we didn’t know what cancer was and decided that under an arbitrary threshold, and that we were looking to prune out steps in our process to invest more money in those with higher probability. What would happen if we decided to invest more money in the pathway of the process for negative cancer cases, instead of positive cancer cases? Interpreting the probabilities and steps requires a good understanding of their evaluation and implementation. To perform this automatically is a challenge that still needs to be addressed for clinical processes.
有一個經典的機器學習示例,說明了在過程挖掘中使用概率方法的局限性:如果癌癥測試分類器可以預測某人90%的時間未患癌癥,則不能說它足夠好。 這適用于通過過程挖掘中的概率建模學習的模型。 如果您有事件日志表明在測試后90%的時間您應該給出癌癥陰性結果,那么這種可能性意味著什么? 讓我們假設一秒鐘,我們不知道癌癥是什么,并決定在一個任意閾值下進行,并且我們正在尋找簡化過程的步驟,以便將更多的資金投資于那些可能性更高的患者。 如果我們決定在陰性癌癥病例而不是陽性癌癥病例的治療過程中投入更多的資金,將會發生什么? 解釋概率和步驟需要對它們的評估和實施有很好的理解。 要自動執行此操作是一項挑戰,臨床過程仍需要解決。
Does correlation imply prediction? The relationships found between the components of a process diagram may not be true, they may as well be false negatives. For example, if you find two consecutive event logs for a patient where one is the patient taking medication and the next one is the sickness getting worse, just looking at these isolated logs could draw the naive conclusion that the medication is to blame. However, this may not be the case. If more event logs, both in the past and the future were taken into account, effects of. That’s why correlation and regression alone are not enough to solve these cases. A potential solution for this is the use of probability chains such as Markov Chains and their extensions, that allow the probability of an event to be traced back to an earlier event than its immediate predecessor.
相關性暗示預測嗎? 在流程圖的各個組件之間發現的關系可能不是真實的,也可能是假陰性。 例如,如果您發現一個患者的兩個連續事件日志,其中一個是正在服藥的患者,下一個是病情加重,那么僅查看這些孤立的日志可能會得出天真的結論,那就是應歸咎于藥物。 但是,事實并非如此。 如果考慮更多的事件日志(過去和將來)的影響。 這就是僅相關性和回歸不足以解決這些情況的原因。 一種可能的解決方案是使用概率鏈,例如馬爾可夫鏈及其擴展,這種概率鏈可將事件的概率追溯到比其前身更早的事件。
Health information is highly sensible. It is a snapshot of the user’s medical, pathological, nutritional, and psychological history. In a world surrounded by taboos for mental illness and HIV, this information needs to be handled with utmost care. Patients are served so that their information is solely used for their recovery and rarely to be sold to third parties in a game of profit.
健康信息非常明智。 它是用戶的醫療,病理,營養和心理史的快照。 在一個充滿精神疾病和艾滋病毒禁忌的世界中,需要非常謹慎地處理這些信息。 為患者提供服務,以便他們的信息僅用于恢復,很少在贏利游戲中出售給第三方。

Process Modelling and Probabilistic Modelling methods aggregate from individual cases to generalize and personalize during treatments when needed. No matter how promising the results look, we need to understand the potential edge cases and caveats of the methods used. For example, the classic photo classification example classified pictures of people of color as monkeys because of the underrepresentation of their skin color in the data gathered for its training. In health, this can lead to a misunderstanding from our models for things like HIV, where most data collected have been documented for the queer community, especially gay men.
過程建模和概率建模方法從各個案例中匯總,以便在需要時在治療期間進行概括和個性化。 無論結果看起來多么有希望,我們都需要了解所使用方法的潛在優勢和注意事項。 例如,經典的照片分類示例將有色人種的圖片歸類為猴子,這是因為在為其訓練收集的數據中皮膚顏色的表示不足。 在健康方面,這可能會導致我們對諸如艾滋病毒之類的模型產生誤解,在該模型中,大多數收集到的數據已記錄在酷兒社區,尤其是男同性戀者。
https://www.researchgate.net/profile/Bouchra_Marzak/publication/306046482_Clustering_in_Vehicular_Ad-Hoc_Network_Using_Artificial_Neural_Network/links/5a0c19f0a6fdccc69edaa37c/Clustering-in-Vehicular-Ad-Hoc-Network-Using-Artificial-Neural-Network.pdf#page=75
https://www.researchgate.net/profile/Bouchra_Marzak/publication/306046482_Clustering_in_Vehicular_Ad-Hoc_Network_Using_Artificial_Neural_Network/links/5a0c19f0a6fdccc69edaa37c/Clustering-in-Vehicular-Ad-Ne-Hoc-Network-Network。
https://link.springer.com/chapter/10.1007/3-540-36182-0_37
https://link.springer.com/chapter/10.1007/3-540-36182-0_37
https://neuroneurotic.net/2015/11/30/does-correlation-imply-prediction/
https://neuroneurotic.net/2015/11/30/does-correlation-imply-prediction/
翻譯自: https://medium.com/swlh/we-need-data-to-improve-healthcare-processes-at-scale-d3592a44c8d4
醫療大數據處理流程
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/388020.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/388020.shtml 英文地址,請注明出處:http://en.pswp.cn/news/388020.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章
 and detectChanges())
What's the difference between markForCheck() and detectChanges()

ASP.NET Core中使用GraphQL - 第七章 Mutation

POM.xml紅叉解決方法

JS前臺頁面驗證文本框非空

python對象引用計數器_在Python中借助計數器對象對項目進行計數
阻塞模式)
套接字設置為(非)阻塞模式

經典問題之「分支預測」


數字圖像處理 python_5使用Python處理數字的高級操作

05精益敏捷項目管理——超越Scrum

帶標題的圖片輪詢展示

linux java 查找進程中的線程

定位匹配 模板匹配 地圖_什么是地圖匹配?


MySQL學習【第十二篇事務中的鎖與隔離級別】

Android WebKit

jQuery的事件綁定和解綁

軟件測試框架課程考試_那考試準備課程值得嗎?

