軟件測試框架課程考試
By Levi Petty
李維·佩蒂(Levi Petty)
This project uses a public, synthesized exam scores dataset from Kaggle to analyze average scores in Math, Reading, and Writing subject areas, relative to the student’s parents’ level of education and whether the student took a preparation course before the exam. I used Deephaven’s R integration, which gave me access to cool plotting libraries. Additionally, users can see the code and plots step-by-step, yielding more detailed information.
?他的項目采用的是公開的,合成的考試成績,從數據集Kaggle分析數學,閱讀和寫作學科領域的平均成績,相對于學生的父母的受教育程度,以及是否該學生拿了準備課程在考試前。 我使用了Deephaven的R集成,這使我可以訪問很酷的繪圖庫。 此外,用戶可以查看代碼并逐步進行繪制,從而獲得更詳細的信息。
我的過程 (My Process)
配置變量 (Configuration Variables)
We begin by defining some configuration variables:
我們首先定義一些配置變量:
home: Your home directory
home :您的主目錄
system: Deephaven system to connect to (configured in the launcher)
系統 :要連接的Deephaven系統(在啟動器中配置)
keyfile: Key file used to authenticate when connecting to the Deephaven system
keyfile :連接到Deephaven系統時用于認證的密鑰文件
workerHeapGB: Gigabytes of heap for the Deephaven query worker
workerHeapGB :Deephaven查詢工作者的千兆字節堆
jvmHeapGB: Gigabytes of heap for the local Java Virtual Machine (JVM)
jvmHeapGB :本地Java虛擬機(JVM)的千兆字節堆
workerHost: host to run the Deephaven query worker on
workerHost :在其上運行Deephaven查詢worker的主機
連接到Deephaven查詢工作者 (Connecting to the Deephaven Query Worker)
After setting up the configuration variables, the first step is to connect R to a Deephaven query worker. To determine the proper value for JAVA_HOME, run R CMD javareconf from the command line.
設置配置變量后,第一步是將R連接到Deephaven查詢工作程序。 要確定JAVA_HOME的正確值,請從命令行運行R CMD javareconf 。
在表中加載 (Loading in the Table)
Prior to writing my code, I downloaded the StudentsPerformance.csv file from Kaggle and created a new user table so that I could access the table without needing to reload the file into a variable every time I executed my code.
在編寫代碼之前,我從Kaggle下載了StudentsPerformance.csv文件并創建了一個新的用戶表,這樣我就可以訪問該表,而無需每次執行代碼時都將文件重新加載到變量中。
創建初始表 (Creating The Initial Table)
After all this setup, my next step is to use Deephaven’s filtering tools to get the relevant data from this new user table and create an initial data table with each student’s parental level of education, whether they took a test prep course, and their scores in each of three subjects: Math, Reading, and Writing.
完成所有這些設置后,我的下一步就是使用Deephaven的過濾工具從此新用戶表中獲取相關數據,并使用每個學生的父母的受教育程度,他們是否參加了考試預備課程以及他們的分數來創建初始數據表。三個科目中的每一個:數學,閱讀和寫作。
增加教育水平的排名 (Adding Rankings for Education Levels)
Next, I use a map to add rankings for each education level to the data table so that I can order the plots by education level instead of alphabetically. Each education level is given its own corresponding ranking from 0–5, with higher education levels having higher numbers for their ranking.
接下來,我使用地圖將每個受教育程度的排名添加到數據表,以便我可以按受教育程度而不是按字母順序對圖進行排序。 每個教育級別都有自己從0-5的相應排名,而高等教育級別的排名則更高。
初始圖 (Initial Plots)
Next, I use R’s ggplot2 and gridExtra libraries to plot the students’ scores with regard to their parents’ levels of education, and the students’ scores with regard to whether they took a test prep course. You’ll need to run install.packages(“ggplot2”, “gridExtra”) in RStudio to install these packages first.
接下來,我使用R的ggplot2和gridExtra庫來繪制學生對他們父母的教育水平的評分,以及學生對他們是否參加考試預備課程的評分。 您需要在RStudio中運行install.packages(“ ggplot2”,“ gridExtra”)才能首先安裝這些軟件包。
獲取標準偏差和總體平均值 (Get Standard Deviations and Overall Averages)
Next, I use Deephaven’s filtering and aggregation tools to calculate the overall standard deviations and average scores for each subject, and store the results in constants. I do this because the standard deviations above average are actually more important information than just raw values, because knowing the standard deviation gives you a better idea of the magnitude of the impact of each variable.
接下來,我使用Deephaven的過濾和匯總工具來計算每個主題的總體標準偏差和平均分數,并將結果存儲在常量中。 我這樣做是因為高于平均值的標準偏差實際上比原始值更重要,因為知道標準偏差可以使您更好地了解每個變量的影響幅度。
將高于總體平均值的標準偏差添加到數據表中 (Add Standard Deviations Above Overall Average to the Data Table)
Lastly, I use Deephaven’s table updating functions to add the number of standard deviations each student’s score was above the overall average for each subject to the data table.
最后,我使用Deephaven的表格更新功能將每個學生的分數的標準差加到數據表中每個學科的總體平均水平之上。
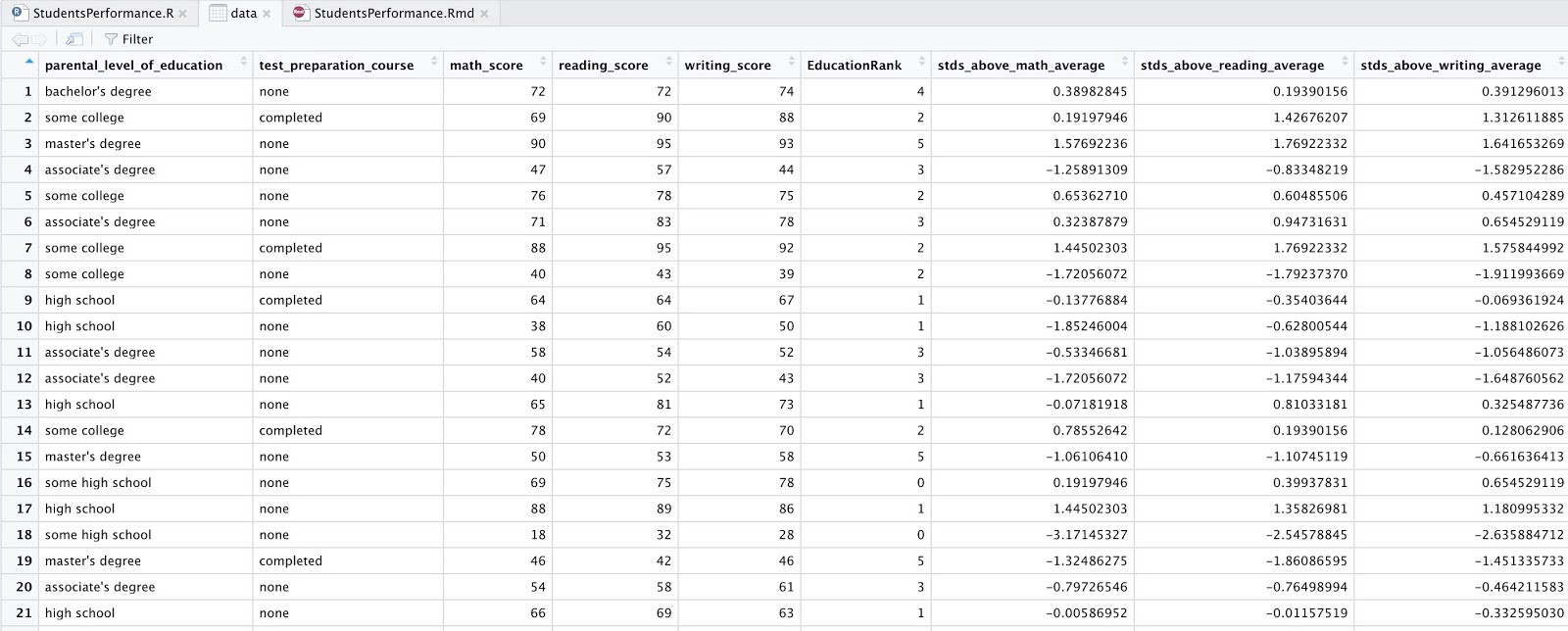
最終情節 (Final Plots)
Finally, I add the standard deviations above average to both plots.
最后,我將高于平均值的標準偏差添加到兩個圖中。
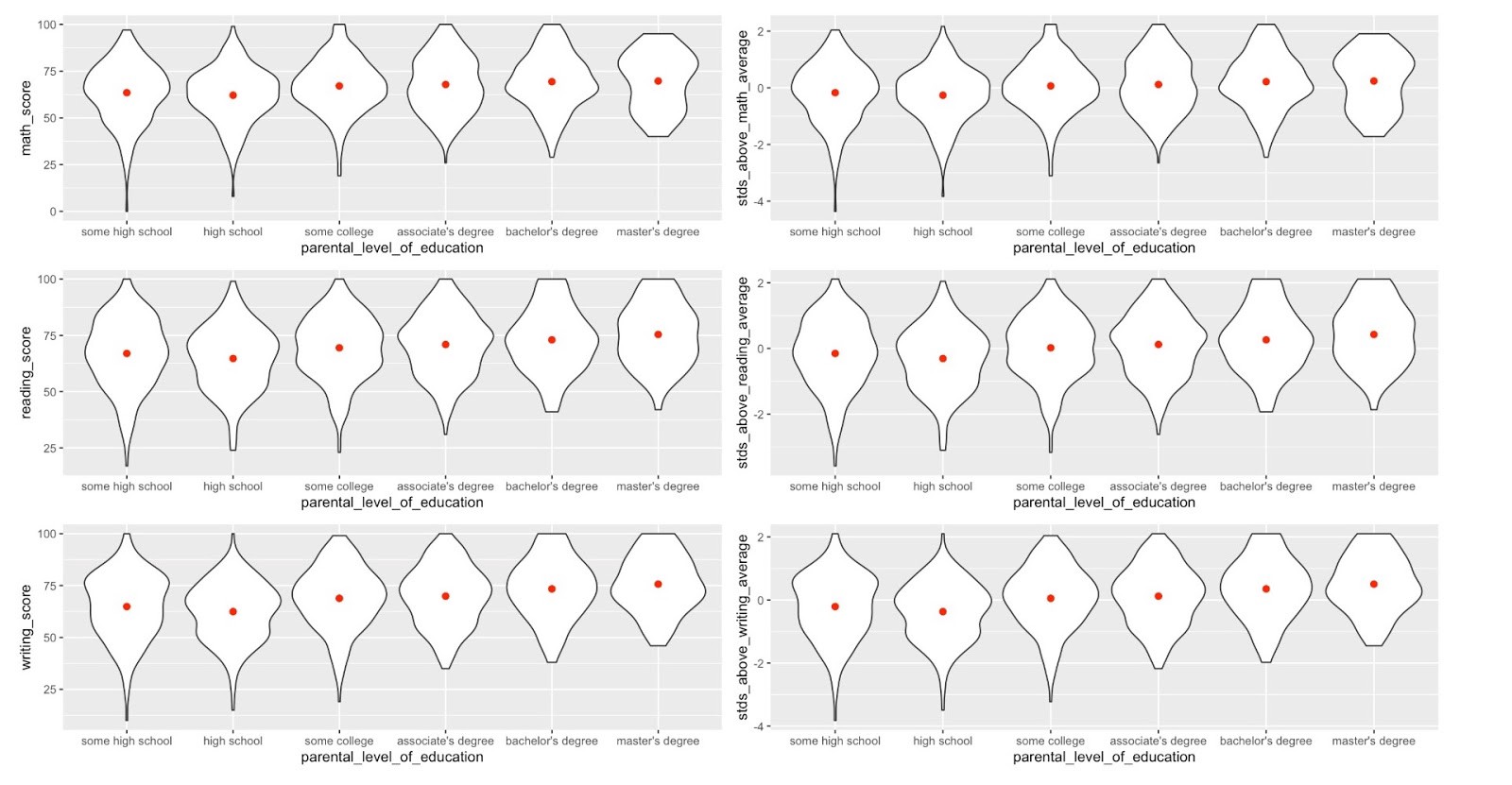
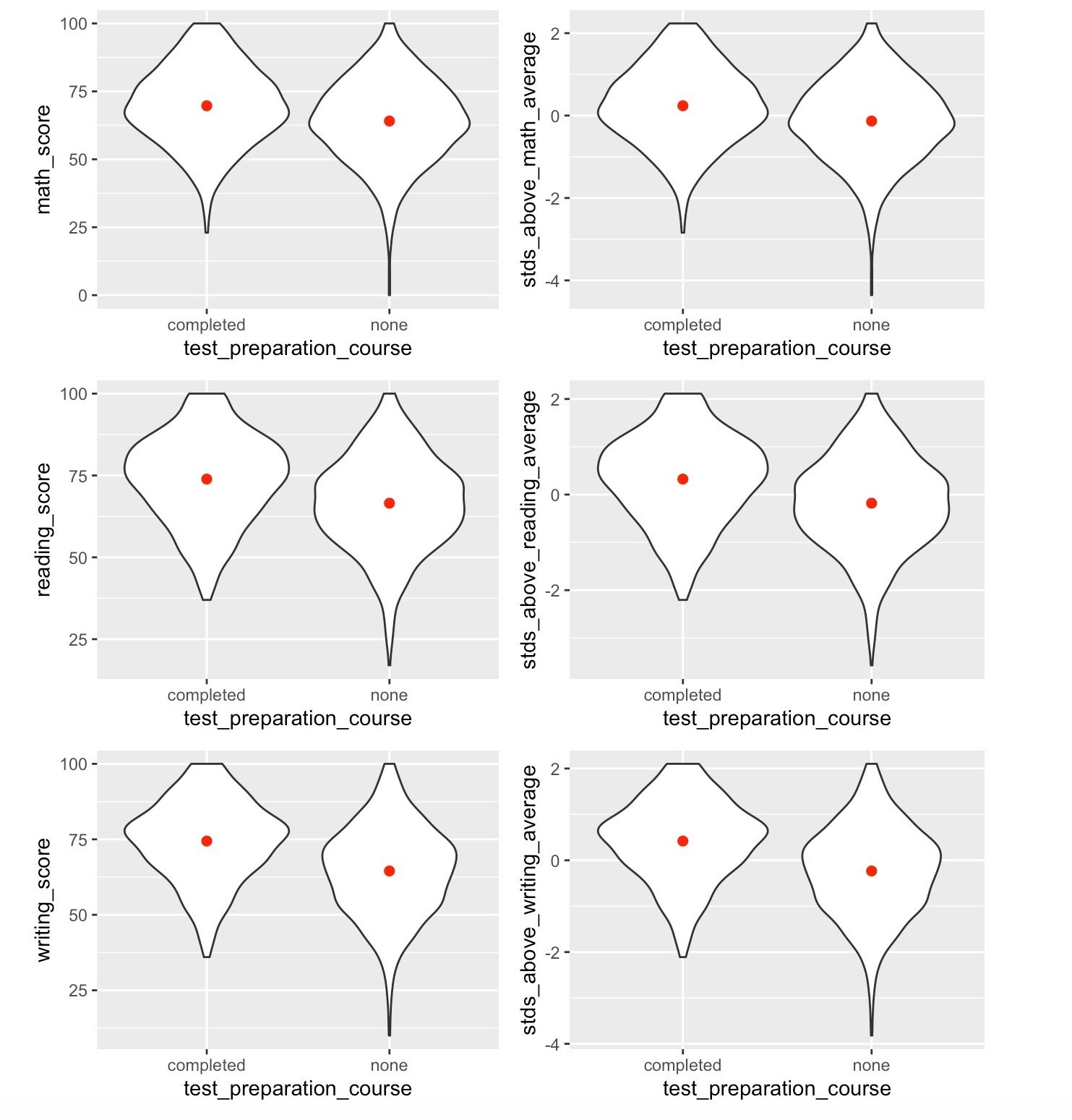
結論 (Conclusion)
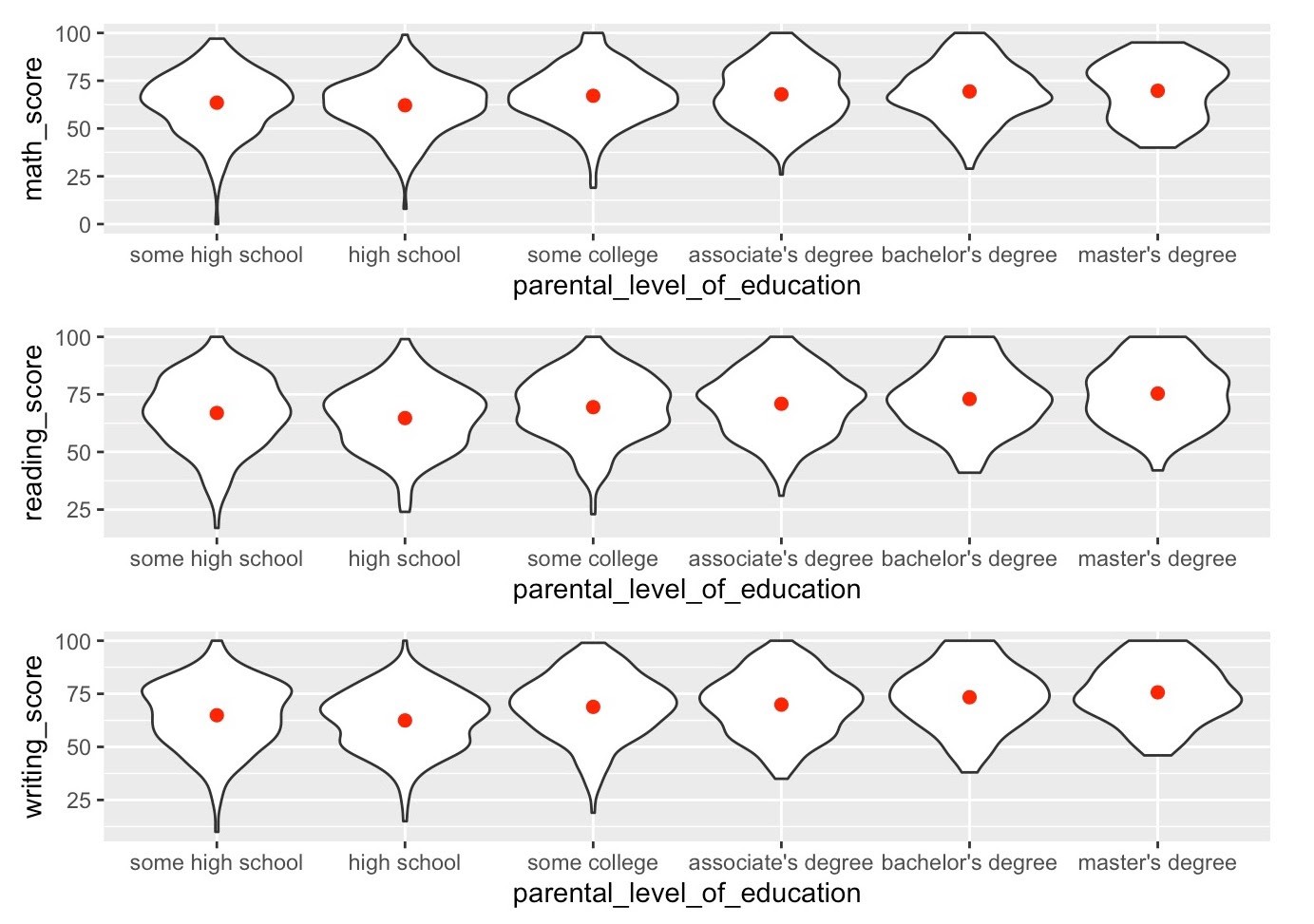
As expected, a higher parental level of education correlated with higher scores in every subject, and generally resulted in less varying distributions. Students with a master’s degree parental education level in particular had top-heavy score distributions in math and writing.
不出所料,父母的受教育程度越高,每門科目的得分越高,通常分配的差異就越小。 尤其是具有父母教育程度的碩士學位的學生在數學和寫作方面的成績分配最高。
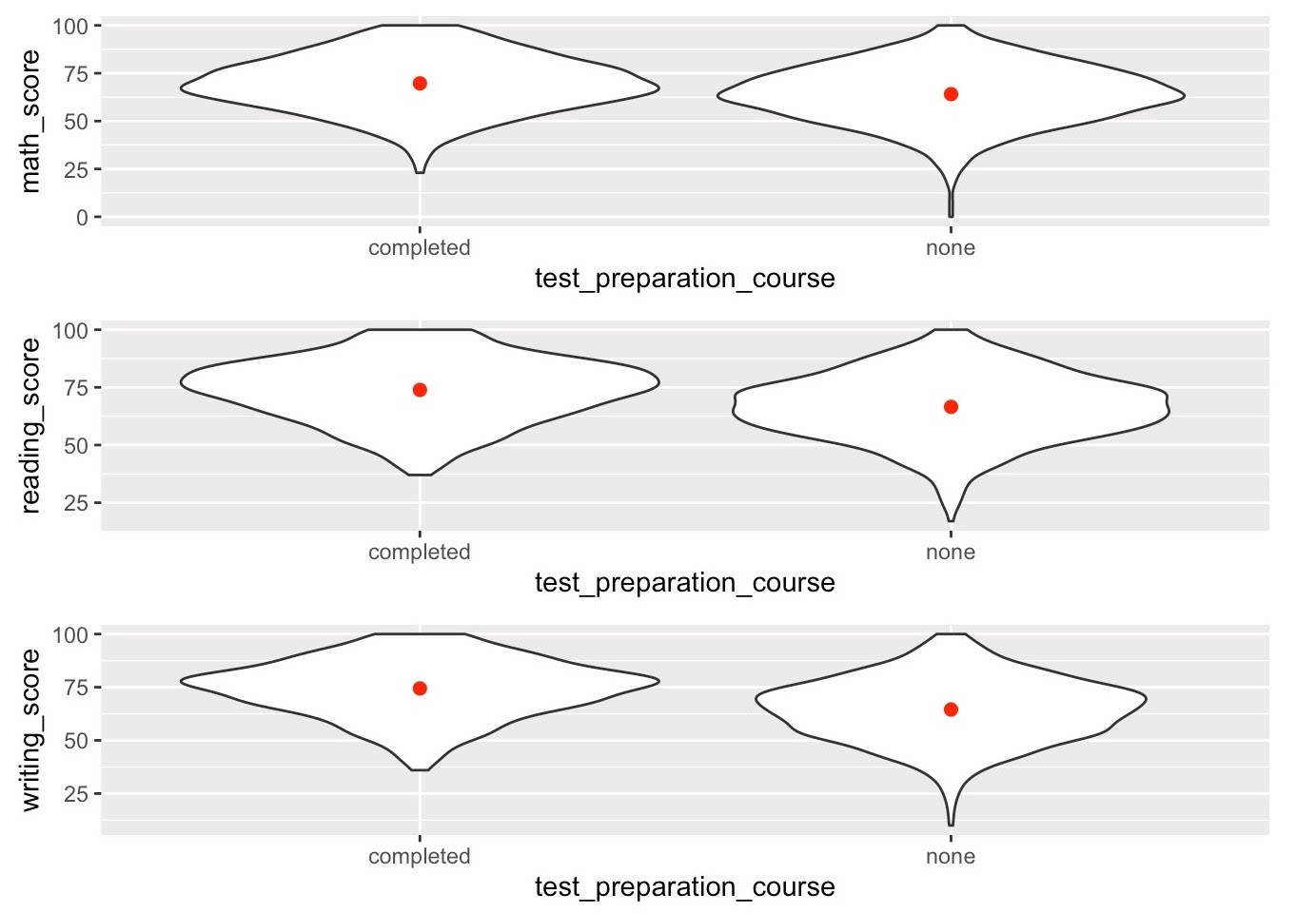
Also unsurprisingly, whether the student took a test prep course had a larger impact on the scores in each subject. The students who took a test prep course had more top-heavy scores in every subject than those who didn’t, especially writing. Surprisingly, the math scores were the least impacted by test prep courses. Neither variable had a large influence on the scores, though, as the scores were only impacted by <1 standard deviation. However, because this data is simulated, we must take the results with a grain of salt.
同樣也就不足為奇的是,學生是否參加了考試預備課程對每個科目的成績都有較大的影響。 參加考試預備課程的學生與沒有考試的學生相比,在各個學科上的成績最高,尤其是寫作。 令人驚訝的是,數學分數受考試準備課程的影響最小。 但是,這兩個變量都不會對分數產生很大影響,因為分數僅受<1個標準偏差的影響。 但是,由于此數據是模擬的,因此必須對結果進行細微的估計。
If you’re interested, you can read my full code below. If you want to see the html file, you can run the code in RStudio.
如果您有興趣,可以在下面閱讀我的完整代碼。 如果要查看html文件,可以在RStudio中運行代碼。
翻譯自: https://medium.com/swlh/is-that-test-prep-course-worth-it-a18011524394
軟件測試框架課程考試
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/388002.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/388002.shtml 英文地址,請注明出處:http://en.pswp.cn/news/388002.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章


GitLab 11.9 正式發布,自動化工具 ChatOps 已開源

DOCKER windows安裝

為什么在Python代碼中需要裝飾器
![Elasticsearch Reference [6.7] ? Modules ? Network Settings](http://pic.xiahunao.cn/Elasticsearch Reference [6.7] ? Modules ? Network Settings)
Elasticsearch Reference [6.7] ? Modules ? Network Settings
——HTTPS協議和原理)
【百度】大型網站的HTTPS實踐(一)——HTTPS協議和原理

數據清理最終實現了自動化

mui 與jquery 同時使用,$沖突解決辦法。

LVS原理介紹及安裝過程

Python氣流介紹

java~springcloud微服務目錄索引

DNS Bind9在windows7下

- 全局組件)
Vue.js(5)- 全局組件

DNS的幾個基本概念:

廢水處理計算書 excel_廢水監測數據是匿名的嗎?

文件在線預覽 圖片 PDF Excel Word

數據科學還是計算機科學_您應該擁有數據科學博客的3個原因

激活Xposed框架的教程)