定位匹配 模板匹配 地圖
By Marie Douriez, James Murphy, Kerrick Staley
瑪麗·杜里茲(Marie Douriez),詹姆斯·墨菲(James Murphy),凱里克·史塔利(Kerrick Staley)
When you request a ride, Lyft tries to match you with the driver most suited for your route. To make a dispatch decision, we first need to ask: where are the drivers? Lyft uses GPS data from the drivers’ phones to answer this question. However, the GPS data that we get is often noisy and does not match the road.
當您請求乘車時,Lyft會嘗試將您與最適合您的路線的駕駛員進行匹配。 要做出調度決定,我們首先需要問: 駕駛員在哪里? Lyft使用駕駛員電話中的GPS數據來回答此問題。 但是,我們獲取的GPS數據通常比較嘈雜,與道路不匹配。
To get a clearer picture from this raw data, we run it through an algorithm that takes raw locations and returns more accurate locations that are on the road network. This process is called map-matching. We recently developed and launched a completely new map-matching algorithm and found that it improved driver location accuracy and made Lyft’s marketplace more efficient. In this post, we’ll discuss the details of this new model.
為了從原始數據中獲得更清晰的圖像,我們通過一種算法來運行它,該算法將獲取原始位置并返回道路網絡上的更精確位置。 這個過程稱為map-matching 。 我們最近開發并推出了一種全新的地圖匹配算法,發現它提高了駕駛員的定位準確性,并使Lyft的市場更加高效。 在這篇文章中,我們將討論這個新模型的細節。
什么是地圖匹配? (What is map-matching?)
Map-matching is a process that maps raw GPS locations to road segments on a road network in order to create an estimate of the route taken by a vehicle.
地圖匹配是一種將原始GPS位置映射到路網上的路段的過程,以創建對車輛所走路線的估算。
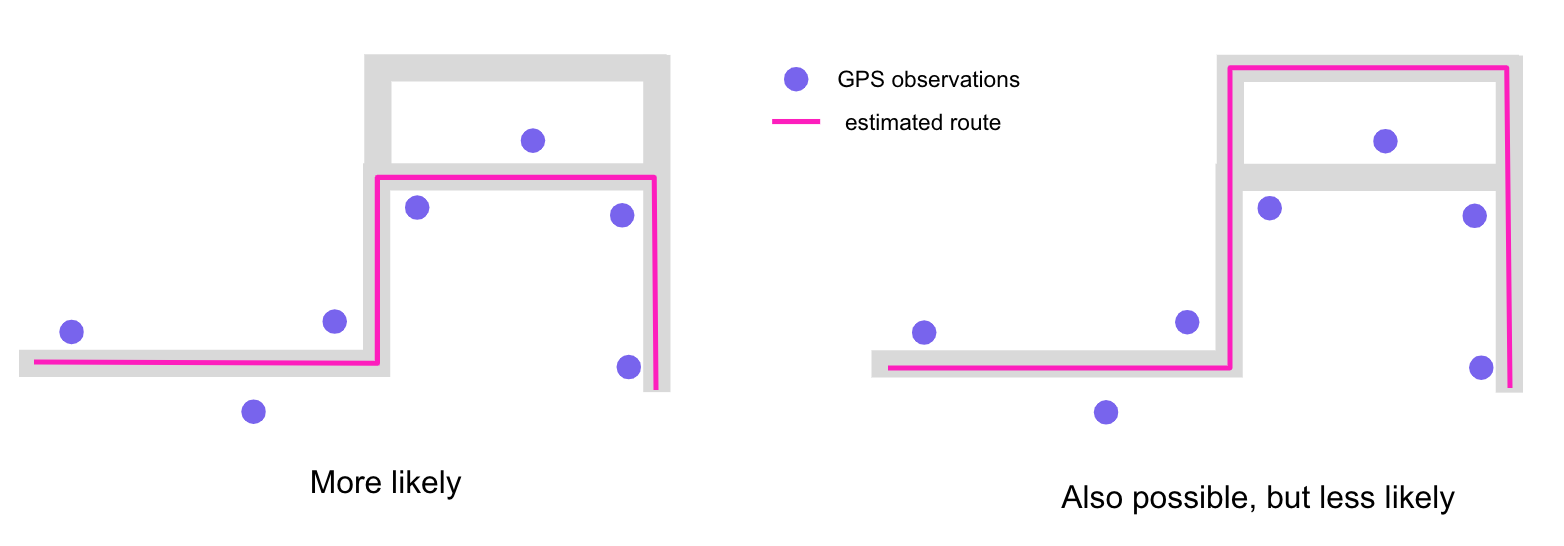
為什么需要地圖匹配? (Why do we need map-matching?)
At Lyft, we have two main use cases for map-matching:
在Lyft,我們有兩個主要的地圖匹配用例:
- At the end of a ride, to compute the distance travelled by a driver to calculate the fare. 乘車結束時,計算駕駛員行進的距離,以計算票價。
In real-time, to provide accurate locations to the ETA team and make dispatch decisions as well as to display the drivers’ cars on the rider app.
實時 ,為ETA團隊提供準確的位置并做出調度決策,并在rider應用程序上顯示駕駛員的汽車。
These two use cases differ by their constraints: in real-time, we need to be able to perform map-matching quickly (low latency) and with the locations available up to the current time only. At the end of a ride however, the latency requirements are less stringent and the whole history of the ride is available to us (allowing us to work “backwards” from future locations). As a result, End-Of-Ride Map-Matching (EORMM) and Real-Time Map-Matching (RTMM) are solved using slightly different approaches. In this post, we will focus on algorithms used for Real-Time Map-Matching.
這兩個用例的約束條件不同:實時,我們需要能夠快速執行地圖匹配(低延遲),并且僅在當前時間可用位置。 但是,在乘車結束時,對等待時間的要求不那么嚴格,并且可以使用乘車的全部歷史記錄(允許我們從將來的位置“向后”工作)。 結果,使用略有不同的方法解決了行進路線圖匹配(EORMM)和實時地圖匹配(RTMM)。 在本文中,我們將重點介紹用于實時地圖匹配的算法。
為什么地圖匹配具有挑戰性? (Why is map-matching challenging?)
A bad map-matched location leads to inaccurate ETAs, then to bad dispatch decisions and upset drivers and riders. Map-matching thus directly impacts Lyft’s marketplace and has important consequences on our users’ experience. There are several main challenges to map-matching.
與地圖匹配的位置不正確會導致ETA信息不準確,進而導致調度決策不正確,并使駕駛員和乘客感到不適。 因此,地圖匹配會直接影響Lyft的市場 ,并對我們的用戶體驗產生重要影響。 地圖匹配存在幾個主要挑戰。
First, as Yunjie noted in his blog post, the location data collected from the phones can get very noisy in urban canyons (where streets are surrounded by tall buildings), around stacked roads, or under tunnels. Those areas are particularly challenging for map-matching algorithms and are all the more important to do correctly since many Lyft rides happen there.
首先,正如Yunjie在他的博客文章中指出的那樣,從手機中收集的位置數據在城市峽谷(街道被高樓大廈包圍),堆積道路周圍或隧道下會變得非常嘈雜 。 對于地圖匹配算法而言,這些區域特別具有挑戰性,而正確進行操作則更加重要,因為在那里發生了許多Lyft騎行。
Beyond noise and road geometry, another challenge is the lack of ground truth: we don’t actually know the true locations of the drivers when they are driving and we have to find proxies to evaluate the accuracy of our models.
除了噪音和道路幾何形狀外,另一個挑戰是缺乏地面真實性 :我們實際上不知道駕駛員在開車時的真實位置,我們必須找到代理來評估模型的準確性。
Finally, the performance of the map-matching algorithms relies on the quality of the road network data. This problem is being solved by another team within Mapping at Lyft; see Albert’s blog post to learn how we make our internal map more accurate.
最后,地圖匹配算法的性能取決于道路網絡數據的質量 。 Lyft的Mapping內部的另一個小組正在解決此問題; 請參閱Albert的博客文章,以了解我們如何使內部地圖更加準確。
那么我們如何解決地圖匹配問題呢? (So how do we solve map-matching?)
We won’t go into all of the techniques for solving map-matching, but for a review of common approaches, please refer to this study by Quddus et al. [1].
我們不會介紹解決地圖匹配的所有技術,但是要回顧常見方法,請參考Quddus等人的這項研究。 [1]。
A nice way to frame the problem is to use state space models. State space models are time series models where the system has “hidden” states that cannot be directly observed but give rise to visible observations. Here, our hidden states are the actual positions of the car on the road network that we are trying to estimate. We only observe a modified version of the hidden states: the observations (raw location data). We assume that the state of the system evolves in a way that only depends on the current state (Markov assumption) and further define a hidden-state-to-hidden-state transition density and a hidden-state-to-observation density.
解決問題的一種好的方法是使用狀態空間模型 。 狀態空間模型是時間序列模型,其中系統具有“隱藏”狀態,這些狀態無法直接觀察到,但會引起可見的觀察。 在這里,我們的隱藏狀態是我們要估算的汽車在道路網絡上的實際位置。 我們僅觀察到隱藏狀態的修改版本:觀察值(原始位置數據)。 我們假設系統的狀態以僅取決于當前狀態的方式演化(馬爾可夫假設),并進一步定義了從隱藏狀態到隱藏狀態的轉移密度和從隱藏狀態到觀察的密度。
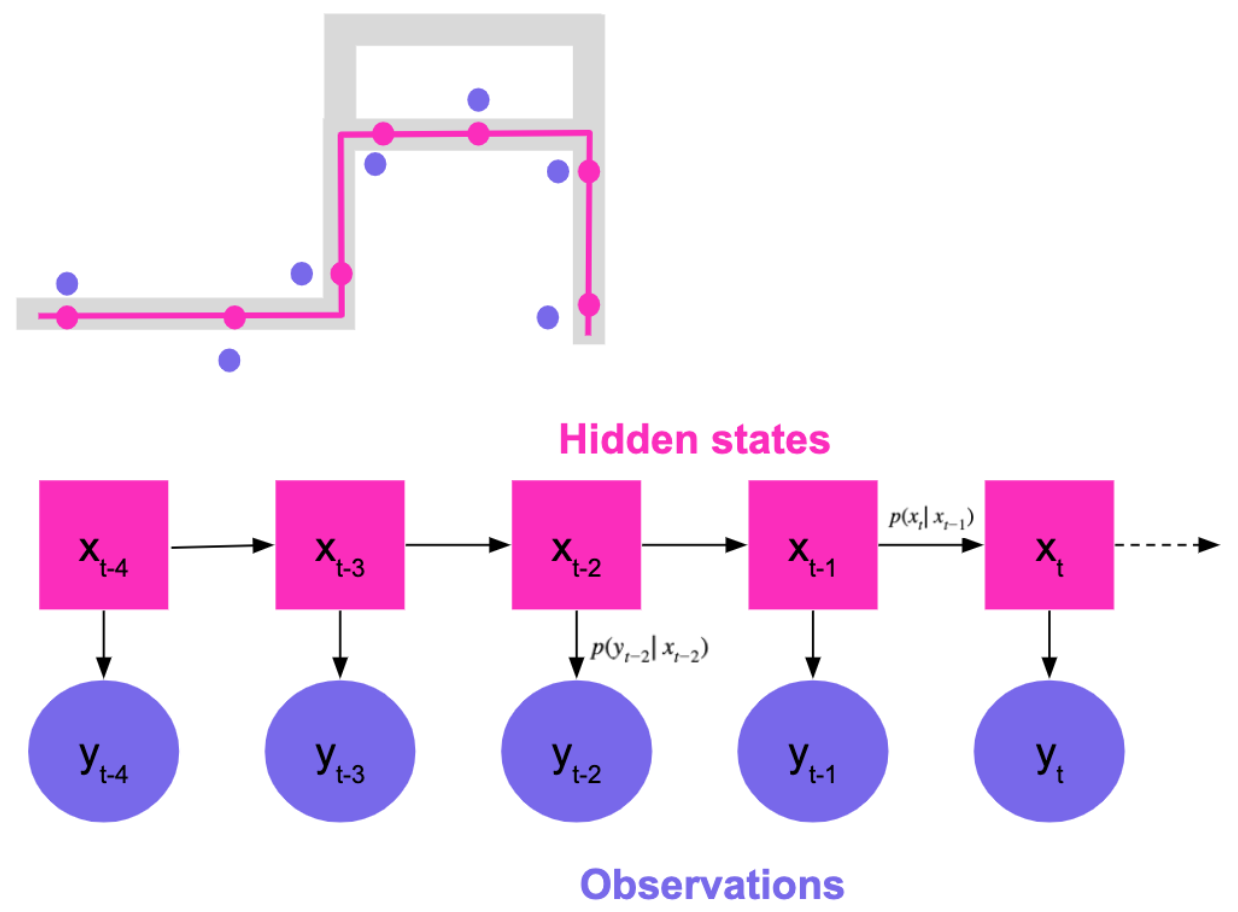
A commonly used state space model for map-matching is the discrete-state Hidden Markov Model (Newson & Krumm [2], DiDi’s IJCAI-19 Tutorial [3], Map Matching @ Uber [4]). In this system, we generate candidates by looking at the closest points on the road segment and use the Viterbi algorithm to find the most likely sequence of hidden states.
常用的地圖匹配狀態空間模型是離散狀態隱馬爾可夫模型 (Newson&Krumm [2],DiDi的IJCAI-19教程[3],Uber的Map Matching [4])。 在該系統中,我們通過查看路段上的最近點來生成候選對象,并使用維特比算法查找最可能的隱藏狀態序列。
However, the Hidden Markov Model (HMM) has several limitations:
但是,隱馬爾可夫模型(HMM)有幾個限制:
- It is relatively inflexible to different modeling choices and input data 對于不同的建模選擇和輸入數據而言,它相對不靈活
- It scales badly (O(N2), where N is the number of possible candidates at each state) 它縮放嚴重(O(N2),其中N是每個狀態下可能的候選數)
- It can’t cope well with high(ish) frequency observations (see Newson & Krumm [2]) 它不能很好地應對高頻觀測(請參閱Newson&Krumm [2])。
For these reasons, we developed a new real-time map-matching algorithm that is more accurate and more flexible to incorporate additional sensor data.
由于這些原因,我們開發了一種新的實時地圖匹配算法,該算法更準確,更靈活,可以合并其他傳感器數據。
基于(無味)卡爾曼濾波器的新模型 (A new model based on the (unscented) Kalman filter)
卡爾曼濾波器基礎 (Kalman filter basics)
Let’s first review the basics of the Kalman filter. (Read how Marguerite and her team used Kalman filters to estimate the seasonality of a market in this blog post.)
讓我們首先回顧一下卡爾曼濾波器的基礎。 (在此博客文章中,了解Marguerite和她的團隊如何使用Kalman濾波器來估計市場的季節性。)
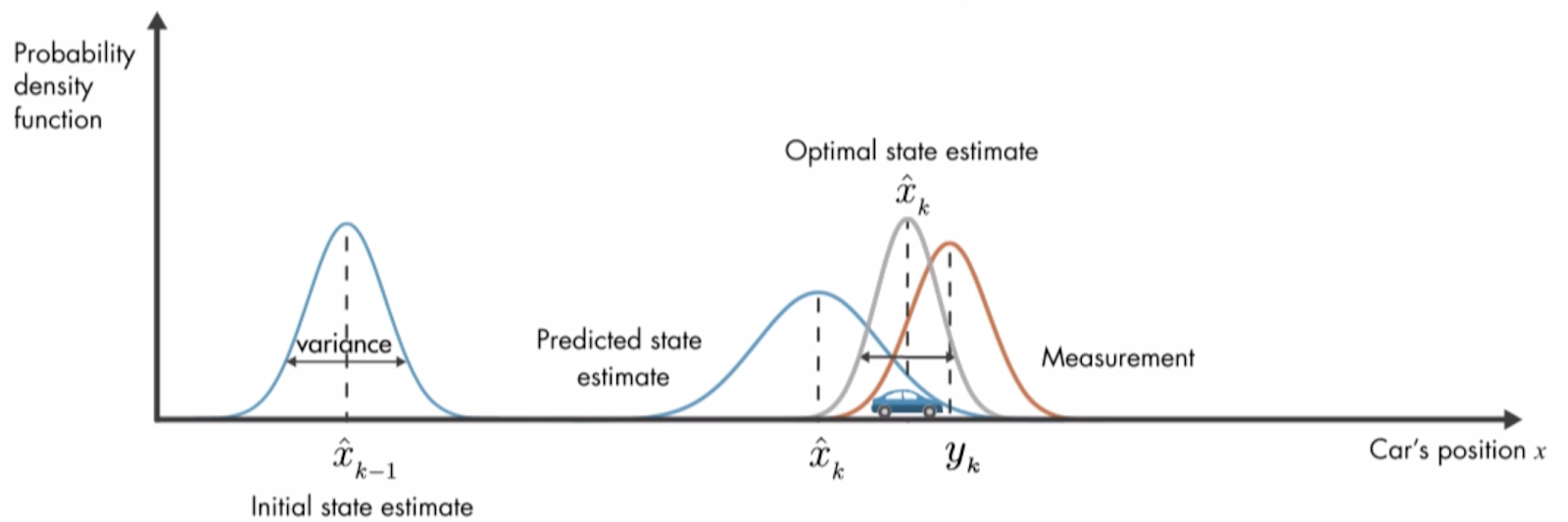
Unlike the discrete-state HMM, the Kalman filter allows for the hidden state to be a continuous distribution. At its core, the Kalman filter is simply a linear Gaussian model and models the system using the following equations:
與離散狀態HMM不同,卡爾曼濾波器允許隱藏狀態為連續分布。 卡爾曼濾波器的核心是線性高斯模型 , 使用以下公式對系統進行建模:

Using these equations, the Kalman filter iteratively updates its representation of the system’s state using a closed form predict-correct step to go from step t-1 posterior to step t posterior.
使用這些方程式,卡爾曼濾波器使用封閉形式的預測正確步驟從后繼的步驟t-1到后繼的步驟t,迭代地更新其對系統狀態的表示。
One limitation of the Kalman filter, however, is that it can only handle linear problems. To deal with non-linearities, generalizations of the Kalman filter have been developed such as the Extended Kalman Filter (EKF) and the Unscented Kalman Filter (UKF) [5]. As we’ll see in the next section, our new RTMM algorithm uses the UKF technique. For the rest of the post, the technical differences between the Kalman filter and the UKF don’t really matter: we can simply assume that the UKF works like a standard linear Kalman filter.
但是,卡爾曼濾波器的局限性在于它只能處理線性問題。 為了處理非線性,已經開發了卡爾曼濾波器的通用性,例如擴展卡爾曼濾波器(EKF)和無味卡爾曼濾波器(UKF)[5]。 正如我們將在下一節中看到的那樣,我們新的RTMM算法使用UKF技術。 在剩下的文章中,卡爾曼濾波器和UKF之間的技術差異并不重要:我們可以簡單地假設UKF的工作方式類似于標準線性卡爾曼濾波器。
邊緣化粒子過濾器 (The Marginalized Particle Filter)
Let’s now describe how our new RTMM algorithm works. We will refer to it as a Marginalized Particle Filter (MPF).
現在讓我們描述新的RTMM算法如何工作。 我們將其稱為邊際化粒子過濾器 (MPF)。
At a high level, our MPF algorithm keeps track of multiple “particles”, each representing a position on a trajectory on the road network, and runs an unscented Kalman filter conditioned on each of these trajectories. To be more precise, let us define the following objects:
在較高的層次上,我們的MPF算法會跟蹤多個“粒子”,每個“粒子”代表道路網絡上某個軌跡上的位置,并運行一個以這些軌跡為條件的無味卡爾曼濾波器。 更準確地說,讓我們定義以下對象:
An MPF state is a list of particles.
MPF狀態是粒子列表。
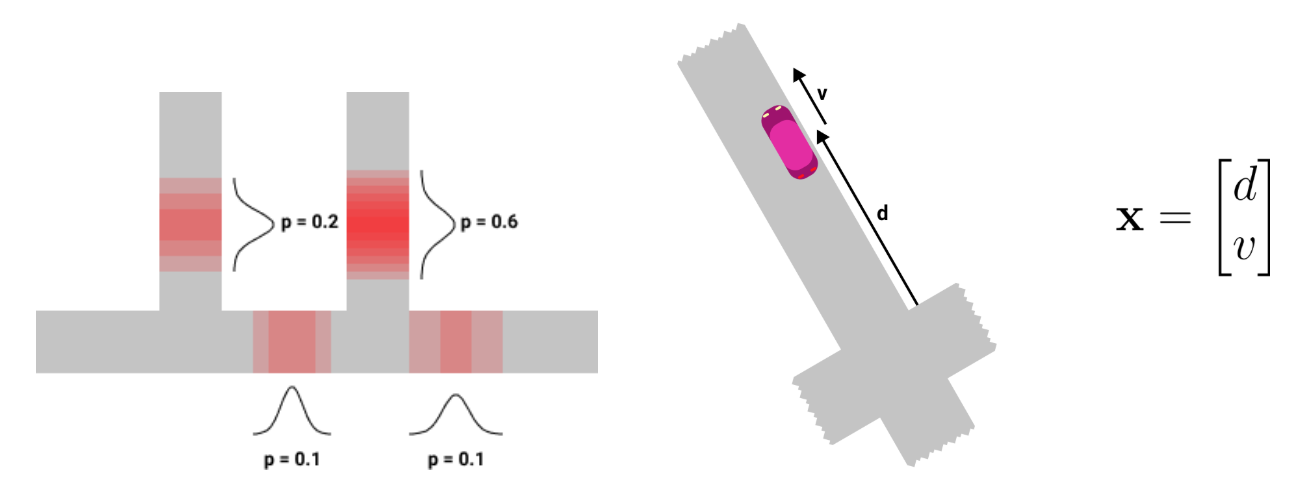
A particle represents one possible road position of the car on the map, associated with some probability. Each particle has 4 attributes:
粒子表示汽車在地圖上的一種可能的道路位置,并具有一定的概率。 每個粒子具有4個屬性:
- A probability p ∈ [0,1] 概率p∈[0,1]
- A trajectory (i.e. a list of intersections from the map) 軌跡(即地圖上的交點列表)
A mean vector x = [d v]’ where d is the position of the car on the trajectory (in meters) and v is the car’s velocity (in meters/second)
平均矢量x = [dv]',其中d是汽車在軌跡上的位置(以米為單位),v是汽車的速度(以米/秒為單位)
A 2x2 covariance matrix P representing the uncertainty around the car’s position and velocity
2x2協方差矩陣P,表示汽車位置和速度周圍的不確定性
We update the MPF state each time we receive a new observation from the driver’s phone in the following way:
每次從駕駛員的手機收到新的觀察結果時,我們都會以以下方式更新MPF狀態 :

If the previous MPF state has no particle (for example, if the driver just logged in to the app), we need to initialize a new one. The initialization step simply “snaps” the GPS observation onto the map and returns the closest road positions. Each particle’s probability is computed as a function of its distance to the observation.
如果以前的MPF狀態沒有粒子(例如,如果驅動程序剛剛登錄到應用程序),則需要初始化一個新的粒子。 初始化步驟只是將GPS觀測值“捕捉”到地圖上,然后返回最接近的道路位置。 每個粒子的概率根據其到觀測值的距離來計算。
At the next update (new observation), we iterate through our state’s (non-empty) list of particles and perform two steps for each particle. First, the trajectory extension step finds all the possible trajectories from the particle’s current position on the road network. Second, we loop through these new trajectories and on each of these, we run our UKF and update the newly created particle’s probability. After these two nested loops, we end up with a new list of particles. To avoid keeping track of too many of them in our MPF state, we simply discard the most unlikely ones (pruning).
在下一次更新(新觀察)時,我們遍歷狀態的(非空)粒子列表,并對每個粒子執行兩個步驟。 首先, 軌跡擴展步驟從道路網絡上粒子的當前位置找到所有可能的軌跡。 其次,我們遍歷這些新軌跡,并在每條軌跡上運行UKF并更新新創建的粒子的概率。 在這兩個嵌套循環之后,我們最終得到一個新的粒子列表。 為了避免在MPF狀態下跟蹤過多的事件,我們只丟棄最不可能的事件( 修剪 )。
The downstream teams can then decide to use the most probable particle from the MPF state as the map-matched location or can directly exploit our probabilistic output (e.g. to create a distribution of possible ETAs).
然后,下游團隊可以決定使用MPF狀態中最可能的粒子作為地圖匹配的位置,或者可以直接利用我們的概率輸出(例如,創建可能的ETA的分布)。
To recap, the Marginalized Particle Filter maintains a set of particles representing possible positions of the car on trajectories and each particle is updated using the Kalman filter algorithm. The new algorithm provides not only location but also speed estimates and uncertainty. In practice, we have observed that it yields more accurate map-matched locations than the HMM, in particular in downtown areas and around intersections where errors would lead to very inaccurate ETAs.
概括地說,邊緣化粒子過濾器會維護一組代表汽車在軌跡上可能位置的粒子,并且使用卡爾曼過濾器算法更新每個粒子。 新算法不僅提供位置,還提供速度估計和不確定性。 在實踐中,我們已經觀察到,與HMM相比,它產生的地圖匹配位置更加準確,尤其是在市區和交叉路口附近,在這些交叉路口,錯誤會導致非常不準確的ETA。
結論 (Conclusion)
After experimenting with this new real-time map-matching algorithm, we found positive effects on Lyft’s marketplace. The new model reduced ETA errors, meaning that we could more accurately match passengers to the most suited driver. It also reduced passenger cancels, showing that it increased passengers’ confidence that their drivers would arrive on-time for pickup.
在嘗試了這種新的實時地圖匹配算法之后,我們發現了對Lyft市場的積極影響 。 新模型減少了ETA錯誤,這意味著我們可以更準確地將乘客與最適合的駕駛員匹配。 它還減少了乘客的取消,這表明它增強了乘客對他們的駕駛員將準時到達接機的信心。
We’re not done yet, though: there are many ways that we plan to improve this model in the coming months. We’re going to incorporate data from other phone sensors, such as the gyroscope, which will allow us to detect when drivers turn. We also plan to take into account the driver’s destination (if they have one, e.g. when en route to a pickup) as a prior. Indeed, another strength of the Marginalized Particle Filter is that it allows us to easily add these new types of information to the model in a principled way, and it is a good foundation on which we can continue to make the Lyft experience a little more seamless for our passengers and drivers.
不過,我們尚未完成:我們計劃在未來幾個月中改進此模型的方法有很多。 我們將合并來自其他電話傳感器(例如陀螺儀)的數據,這將使我們能夠檢測到駕駛員何時轉向。 我們還計劃事先考慮駕駛員的目的地(如果他們有目的地,例如在去接送人的途中)。 確實,邊緣化粒子過濾器的另一個優勢在于,它使我們能夠以有原則的方式輕松地將這些新類型的信息添加到模型中,并且這是我們可以繼續使Lyft體驗更加無縫的良好基礎。為我們的乘客和司機。
Special thanks to the entire Locations team for helping us put this model into production!
特別感謝整個Locations團隊幫助我們將此模型投入生產!
As always, Lyft is hiring! If you’re passionate about developing state-of-the-art quantitative models or building the infrastructure that powers them, read more about our Science and Engineering roles and reach out to us.
與往常一樣,Lyft正在招聘! 如果您熱衷于開發最新的定量模型或構建支持它們的基礎架構,請詳細了解我們的科學和工程角色并 與我們聯系 。
翻譯自: https://eng.lyft.com/a-new-real-time-map-matching-algorithm-at-lyft-da593ab7b006
定位匹配 模板匹配 地圖
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/388007.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/388007.shtml 英文地址,請注明出處:http://en.pswp.cn/news/388007.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章


MySQL學習【第十二篇事務中的鎖與隔離級別】

Android WebKit

jQuery的事件綁定和解綁

軟件測試框架課程考試_那考試準備課程值得嗎?


GitLab 11.9 正式發布,自動化工具 ChatOps 已開源

DOCKER windows安裝

為什么在Python代碼中需要裝飾器
![Elasticsearch Reference [6.7] ? Modules ? Network Settings](http://pic.xiahunao.cn/Elasticsearch Reference [6.7] ? Modules ? Network Settings)
Elasticsearch Reference [6.7] ? Modules ? Network Settings
——HTTPS協議和原理)
【百度】大型網站的HTTPS實踐(一)——HTTPS協議和原理

數據清理最終實現了自動化

mui 與jquery 同時使用,$沖突解決辦法。

LVS原理介紹及安裝過程

Python氣流介紹

java~springcloud微服務目錄索引

DNS Bind9在windows7下

- 全局組件)
Vue.js(5)- 全局組件
