2019獨角獸企業重金招聘Python工程師標準>>> 
在2019年3月的北京云棲峰會上,阿里云正式推出全球首個云原生HDFS存儲服務—文件存儲HDFS,為數據分析業務在云上提供可線性擴展的吞吐能力和免運維的快速彈性伸縮能力,降低用戶TCO。阿里云文件存儲HDFS的發布真正解決了HDFS文件系統不適應云上場景的缺陷問題,用戶無須花費精力維護和優化底層存儲。
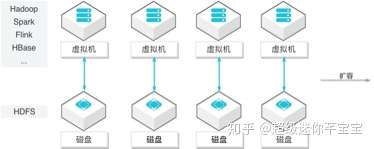
云時代,通過借助虛擬化技術,大數據分析的計算框架在云上逐漸實現了快速部署和彈性伸縮。但是作為數據底座的HDFS文件系統,它在設計之初并沒有考慮到上云場景。其數據的擴縮容、故障硬件排除都依賴大量手工運維,因此其服務質量難以保證。在隨著其他計算引擎一起彈性部署時,HDFS會成為整個計算框架的短板,限制了業務的整體彈性伸縮能力,增加了規劃和運維難度。
?
為響應用戶在云上使用HDFS的訴求,文件存儲HDFS應運而生。產品設計方面,得益于文件存儲HDFS兼容標準Hadoop文件接口,基于HDFS進行開發的分析服務無須進行改造即可直接連接文件存儲HDFS進行數據分析,可作為serverless計算架構的后端數據引擎。用戶無須花費精力維護和優化底層存儲,聚焦在計算和業務本身。
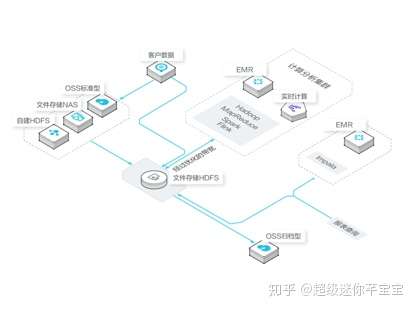
用戶場景方面,文件存儲HDFS的多租戶和權限控制能力可以有效支撐企業內部多業務數據管理的場景。用戶可以將生產集群的數據直接寫入文件存儲HDFS,也可以將存儲在自建HDFS、阿里云OSS、文件存儲NAS中的數據導入到文件存儲HDFS,再利用Spark/Mapreduce/Flink/Hive/Tensoflow等不同的分析框架對文件存儲HDFS上的數據進行處理,處理結果可以按需輸出到不同的系統中。廣泛用于實時統計與分析、離線用戶畫像、實時分析、機器學習等業務場景中。
?
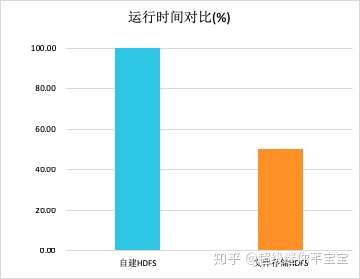
技術能力方面,作為聚焦大數據分析場景的云存儲產品,文件存儲HDFS針對計算中最關注的吞吐性能進行了軟硬一體的優化,提供遠超自建HDFS的吞吐能力。在模擬離線分析場景的Terasort測試中,在使用同等數量的CPU和內存的情況下,用文件存儲HDFS替代HDFS可以使整體的分析性能提升一倍。
?
原文鏈接
本文為云棲社區原創內容,未經允許不得轉載。
)


















