客戶流失
Big Data Analytics within a real-life example of digital music service
數字音樂服務真實示例中的大數據分析
Customer churn is a key predictor of the long term success or failure of a business. It is the rate at which customers are leaving your business and taking their subscription dollars elsewhere. For every single business, why the users churn and how to change, keep, attract the users is the forever questions they ask themselves.
客戶流失是企業長期成功或失敗的關鍵預測指標。 這是客戶離開您的業務并將其訂閱費轉移到其他地方的費率。 對于每一項業務,為什么用戶流失以及如何改變,保持,吸引用戶是他們永遠問自己的問題。

Digital Music Service, as an example for us here to look into. Let’s think of the most familiar platform, like Spotify, Pandora. Every time when you, as the user interact with the service, every small step, such as playing music, logging out the page, like the song, etc, generate the data. Here comes the Big Data! All these data contain the key insight for predicting the churn of the users and keeping the business thrive. Because of the size of the data, it is a challenging and common problem that we regularly encounter in any customer-facing business.
數字音樂服務 ,以我們為例進行研究。 讓我們考慮一下最熟悉的平臺,例如Spotify,Pandora。 每當您作為用戶與服務交互時,每一個小步驟(例如播放音樂,注銷頁面,喜歡歌曲等)都會生成數據。 大數據來了! 所有這些數據都包含了預測用戶流失并保持業務蓬勃發展的關鍵見解。 由于數據量大,這是我們在任何面向客戶的業務中經常遇到的具有挑戰性的普遍問題。
Here we are going to analyze the real-life large datasets for a music streaming service with Spark. We attempt to build machine learning models to predict the churning possibilities of the users and understand the features that contribute to the churning behaviors.
在這里,我們將分析Spark的音樂流服務的真實大型數據集。 我們試圖建立機器學習模型 來預測用戶的攪動可能性,并了解有助于攪動行為的功能。
Let’s start with a mini-subset (~128MB) of the large data (12 GB) first for understanding and exploring the datasets. We will load in our dataset (JSON format) through the following commands:
讓我們首先從大數據(12 GB)的微型子集 (?128MB)開始,以了解和探索數據集。 我們將通過以下命令加載數據集(JSON格式):
# Create a Spark session
spark = (SparkSession.builder
.master(“local”)
.appName(“sparkify”)
.getOrCreate())# Read the dataset
events_df = spark.read.json(‘mini_sparkify_event_data.json’)We can also take a look at the shortcut of all the features and their datatype
我們還可以看一下所有功能及其數據類型的快捷方式
root
|-- artist: string (nullable = true)
|-- auth: string (nullable = true)
|-- firstName: string (nullable = true)
|-- gender: string (nullable = true)
|-- itemInSession: long (nullable = true)
|-- lastName: string (nullable = true)
|-- length: double (nullable = true)
|-- level: string (nullable = true)
|-- location: string (nullable = true)
|-- method: string (nullable = true)
|-- page: string (nullable = true)
|-- registration: long (nullable = true)
|-- sessionId: long (nullable = true)
|-- song: string (nullable = true)
|-- status: long (nullable = true)
|-- ts: long (nullable = true)
|-- userAgent: string (nullable = true)
|-- userId: string (nullable = true)The feature page seems to be the most important one as it records all the user interactions. The page column recorded values, such as Logout, Save Settings, Roll Advert, Settings, Submit Upgrade, Cancellation Confirmation, Add Friends, etc. Also, the Cancellation Confirmation events of page define the churn that we are interested in. (0 as un-churn, and 1 as churn)
功能頁面似乎是最重要的頁面 ,因為它記錄了所有用戶交互。 頁面列記錄的值,例如注銷,保存設置,滾動廣告,設置,提交升級,取消確認,添加朋友等。此外,頁面的取消確認事件定義了我們感興趣的用戶流失。(0為un -攪動,而1為攪動)
Exploratory Data Analysis (EDA)
探索性數據分析(EDA)
We want to perform some exploratory data analysis to observe the behavior for users who stayed vs users who churned.
我們希望執行一些探索性數據分析,以觀察留下的用戶與攪動的用戶的行為。
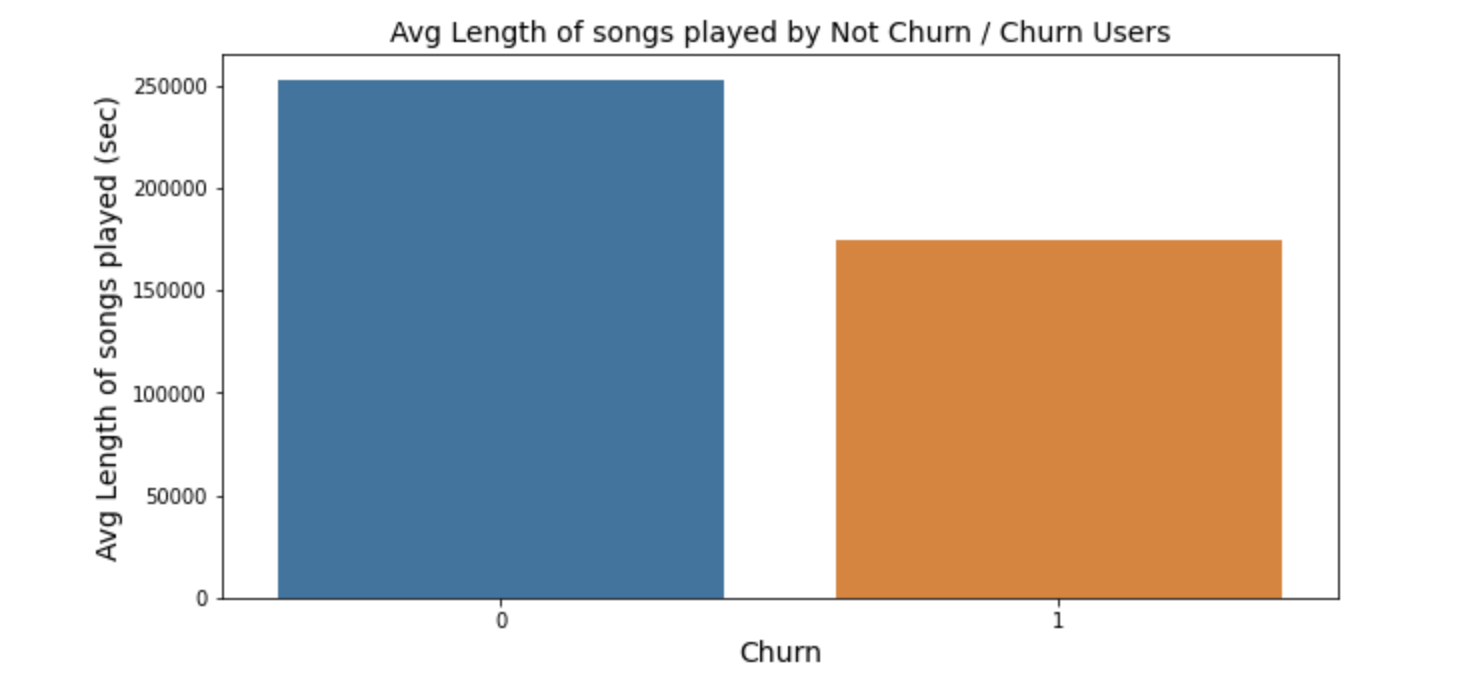
From the bar plot on the left, the average length of songs played for churn and un-churn users is generated. For un-churned users, they have longer mean length for listening to the songs compare to the other group.
從左側的條形圖中, 可以得出為流失和不流失用戶播放的歌曲的平均長度 。 對于未訂閱的用戶,與其他組相比,他們的平均聽歌時間更長。
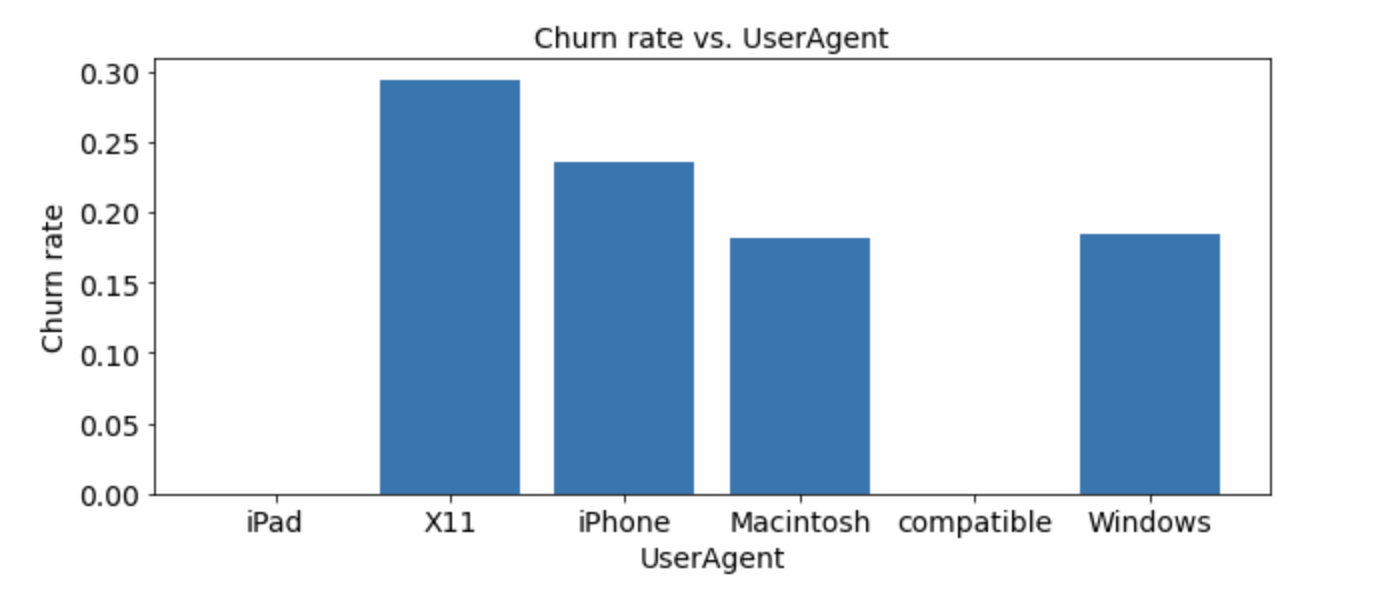
The second bar chart shows the relationship of the churn rate and User-Agent of the users. From the data, we can conclude that X11 and iPhone users tend to churn more and this can give us some insights for further investigation of the systems.
第二個條形圖顯示了用戶的客戶流失率與User-Agent的關系 。 根據數據,我們可以得出結論,X11和iPhone用戶的流失率更高,這可以為我們進一步研究系統提供一些見識。
By checking the correlation matrix of the page and our domain knowledge, we pick several features (Thumbs Up, Thumbs Down, Add Friend, Add to Playlist, Error, Help) to observe the difference between churn and un-churn customers. The box plot below shows some detailed information.
通過檢查頁面的相關矩陣和我們的領域知識 ,我們選擇了幾種功能(“豎起大拇指”,“大拇指朝下”,“添加朋友”,“添加到播放列表”,“錯誤”,“幫助”),以觀察流失客戶與未流失客戶之間的差異。 下面的方框圖顯示了一些詳細信息。
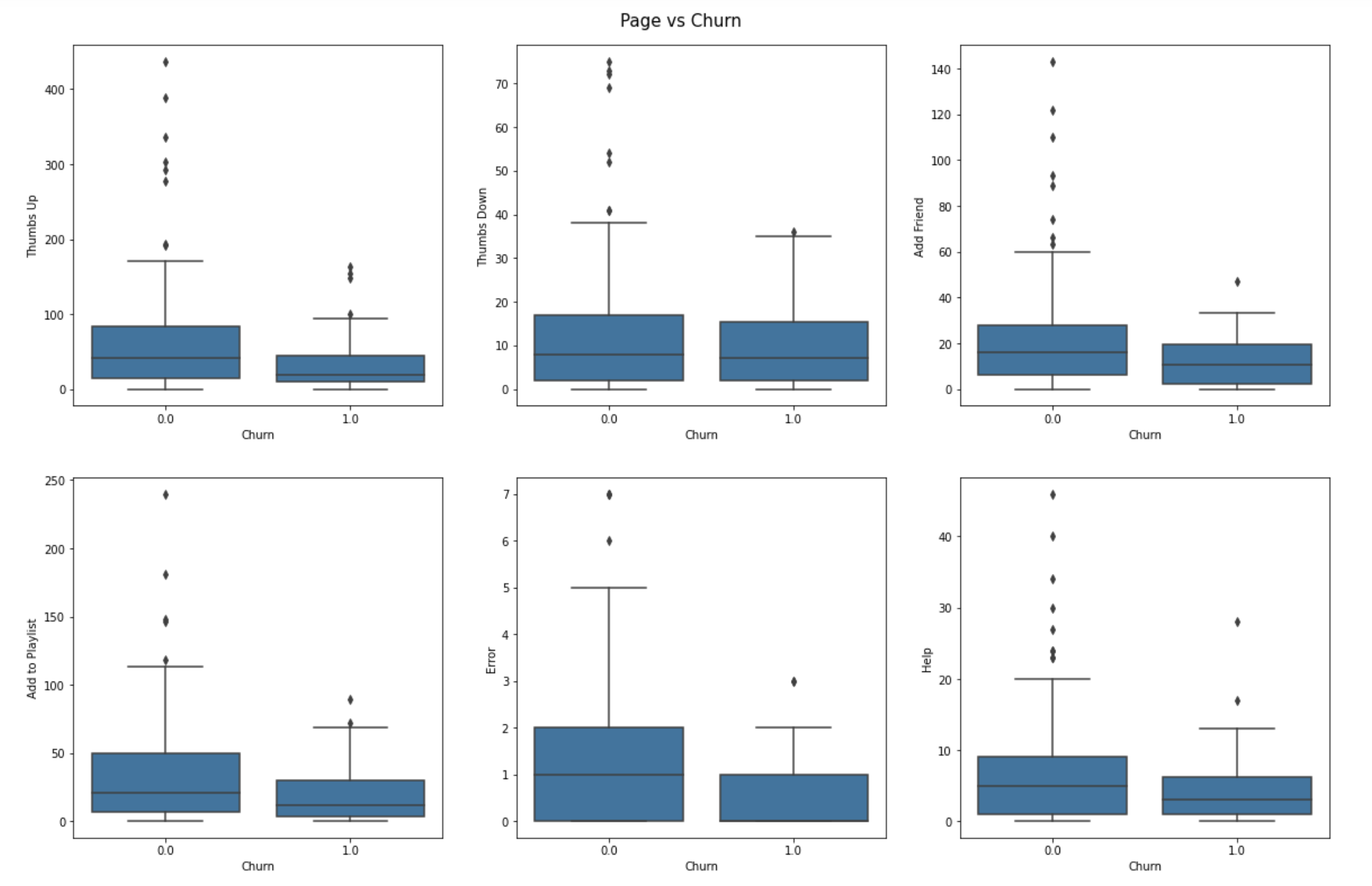
What can you gain from the plots? From my perspective, churn users:
您可以從地塊中獲得什么? 在我看來,用戶流失 :
- less likely to click thumbs up 不太可能點擊豎起大拇指
- less likely to add friends 不太可能添加朋友
- less likely to add songs to the playlist 將歌曲添加到播放列表的可能性較小
However, it doesn’t necessarily mean that they have more errors encountered and need more help from the service.
但是,這不一定意味著他們遇到了更多的錯誤,并且需要該服務提供更多幫助。
Once we familiarized ourselves with the data, let’s build out the features find promising to train the model on.
一旦我們熟悉了數據,就可以建立一些很有希望在模型上進行訓練的功能。
Feature Engineering
特征工程
Here are some features that I found interesting:
以下是一些我發現很有趣的功能:
Features of Page but remove un-related ones
Page的功能,但刪除不相關的功能
df_features = df.groupby([‘userId’])
.pivot(‘page’)
.count()
.fillna(0)df_features.withColumnRenamed(‘Cancellation Confirmation’,’Churn’)df_features = df_features.drop(‘About’, ‘Cancel’, ‘Login’,’Logout’, ‘Roll Advert’, ‘Submit Registration’, ‘Register’, ‘Save Settings’)2. Total song-length of the user listened
2.聽過的用戶的總歌曲長度
total_length = df.filter(df.page == ‘NextSong’)
.groupby(df.userId)
.agg(sum(df.length)
.alias(‘total_songlength’))df_features = df_features.join(total_length, on=[‘userId’], how=’inner’)3. Gender: Dummy variables created
3.性別:虛擬變量已創建
gender_df = df.select(‘userId’,’gender’).dropDuplicates()categories = gender_df.select(‘gender’)
.distinct()
.rdd.flatMap(lambda x: x)
.collect()exprs = [F.when(F.col(‘gender’) == category, 1)
.otherwise(0)
.alias(category) for category in categories]gender_df = gender_df.select(‘userId’, *exprs)df_features = df_features.join(gender_df, on=[‘userId’], how=’inner’)4. Number of days user active
4.用戶活躍天數
days = df.groupby(‘userId’).agg(max(df.ts),(min(df.ts)))days = days.withColumn(‘days_active’, (col(‘max(ts)’) -col(‘min(ts)’)) / (60*60*24) )df_features = df_features.join(days, on=[‘userId’], how=’inner’).drop(‘max(ts)’,’min(ts)’)5. Number of days register the account
5.注冊帳戶的天數
days_reg = df.groupby(‘userId’)
.agg(max(df.registration),(max(df.ts)))days_reg = days_reg.withColumn(‘days_register’, (col(‘max(ts)’) -col(‘max(registration)’)) / (60*60*24) )df_features = df_features.join(days_reg, on=[‘userId’], how=’inner’).drop(‘max(ts)’,’max(registration)’)6. The final level of the user (paid/free)
6.用戶的最終級別(付費/免費)
final_level = df.groupby(‘userId’, ‘level’)
.agg(max(df.ts)
.alias(‘finalTime’))
.sort(“userId”)categories = final_level.select(‘level’)
.distinct()
.rdd.flatMap(lambda x: x)
.collect()exprs = [F.when(F.col(‘level’) == category, 1)
.otherwise(0)
.alias(category) for category in categories]final_level = final_level.select(‘userId’, *exprs)Modeling
造型
After we engineered the features, we will build three models: logistic regression, random forest, gradient boosting trees. Let’s start by generating the table, splitting, and scale the data.
設計完這些功能之后,我們將構建三個模型:邏輯回歸,隨機森林,梯度增強樹。 讓我們從生成表,拆分和縮放數據開始 。
# Rename Cancellation Confirmation as label in df_features_label
df_features_label = df_features.withColumnRenamed(‘Cancellation Confirmation’, ‘label’)# Generate features table
df_features = df_features.drop(‘Cancellation Confirmation’, ‘userId’)# Splitting the data
train, test = df_features_label.randomSplit([0.8, 0.2])# Instantiating vectorassembler for creating pipeline
vector_assembler = VectorAssembler(inputCols = df_features.columns, outputCol = ‘Features’)# Scale each column for creating pipeline
scale_df = StandardScaler(inputCol = ‘Features’, outputCol=’ScaledFeatures’)Here we give an example of building the Logistic Regression Model. All the other models are similar methods to build.
這里我們舉一個建立Logistic回歸模型的例子。 所有其他模型都是相似的構建方法。
lr = LogisticRegression(featuresCol=”ScaledFeatures”, labelCol=”label”, maxIter=10, regParam=0.01)# Creating pipeline
pipeline_lr = Pipeline(stages=[vector_assembler, scale_df, lr])# fitting the model
model_lr = pipeline_lr.fit(train)In order to evaluate the accuracy of the model, we write a function to report results on the validation set. Since the churned users are a fairly small subset, and F1 score as the metric to optimize.
為了評估模型的準確性,我們編寫了一個函數來報告驗證集上的結果。 由于攪動的用戶是一個相當小的子集,因此F1得分是要優化的指標。
def peformance(model, data, evaluation_metric):
# Generate predictions
evaluator = MulticlassClassificationEvaluator(metricName = evaluation_metric)
predictions = model.transform(data)
# Get scores
score = evaluator.evaluate(predictions)
confusion_matrix = (predictions.groupby(‘label’)
.pivot(‘prediction’)
.count()
.toPandas())
return score, confusion_matrixWe check the performance of the model as follows:
我們按以下方式檢查模型的性能:
# Performance
score_lr, confusion_matrix_lr = peformance(model_lr, test, ‘f1’)print(‘The f1 score for Logistic Regression model:{}’.format(score_lr))print(confusion_matrix_lr)Here is the resulting output for the Logistic Regression Model:
這是邏輯回歸模型的結果輸出:

From the analysis, the Gradient Boosting Tree Model did the best job with an F-1 score of up to 0.88. We need to notice that, since we only have a small group of people churn in the business usually, we care more about we can identify the churned users correctly, instead of pursuing high overall performance. In this case, we didn’t perform the grid searching and tune the parameters.
根據分析,梯度提升樹模型的F-1分數最高為0.88,表現最佳。 我們需要注意的是,由于通常業務中只有一小部分人在流失 ,因此我們更關心可以正確識別被攪動的用戶,而不是追求較高的整體績效。 在這種情況下,我們沒有執行網格搜索和調整參數。
Feature Importance
功能重要性
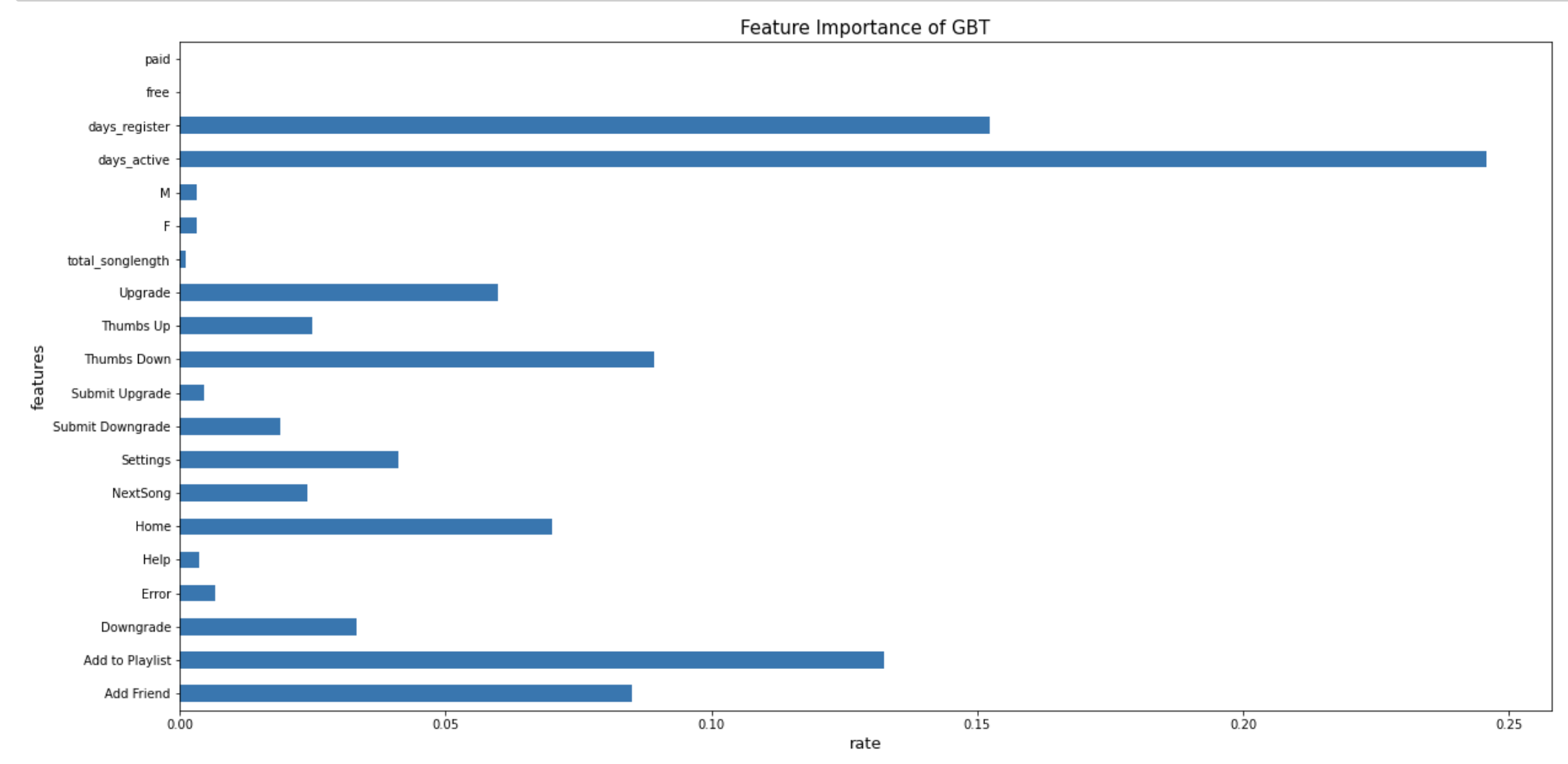
Using our best GBT model and feature importance function, we visualize the relative importance rank of each feature we obtained in the feature engineering process. As the figure below, we find that the days of the active, register of the users, and the number of times users add the song to the playlist are the most important features to the GBT model we built.
使用我們最好的GBT模型和特征重要性函數 ,我們可以可視化在特征工程過程中獲得的每個特征的相對重要性等級。 如下圖所示,我們發現活動的日子,用戶的注冊日期以及用戶將歌曲添加到播放列表的次數是我們構建的GBT模型最重要的功能。
What actions we can take to decrease the churn rate then?
那么我們可以采取什么措施來降低流失率呢?
By finishing analyzing the data is never the end, always how to apply to the business is the most important part and the part makes our model crucial. With the feature importance we gained, we can come up with some business strategies to counter customer churns in real-life business. Here are some brief ideas related to our analysis:
通過完成對數據的分析永無止境,始終如何應用到業務是最重要的部分,而這一部分使我們的模型至關重要。 利用我們獲得的功能重要性,我們可以提出一些業務策略來應對現實業務中的客戶流失。 以下是與我們的分析有關的一些簡要建議:
The number of active days is one of the important factors for churning, then rewarding and discounting can be considered to attract the activity of the users. This can also apply to the adding friends’ system, for example, if the user recommend and add 5 friends in the community, they can unblock unique badge
活動天數是攪動的重要因素之一,因此可以考慮獎勵和折扣來吸引用戶的活動。 這也可以應用于添加朋友的系統 ,例如,如果用戶在社區中推薦并添加5個朋友,則他們可以取消阻止唯一徽章
Wow! We are finally here! Do you still remember what did we do to use Big Data methods in order to find out the churn behaviors of the customers?
哇! 我們終于來了! 您是否還記得我們做了什么工作才能使用大數據方法來發現客戶的流失行為?
Let’s do a recap:
讓我們來回顧一下:
- data loading 資料載入
- Exploratory data analysis 探索性數據分析
- Feature engineering 特征工程
- Model building and evaluation 模型建立與評估
- Identifying important features 識別重要特征
- Business Strategy (Actions) 商業策略(行動)
If you are interested in more details of these procedures, you could check out my entire code for this Sparkify analysis at my GitHub repository.
如果您對這些過程的更多細節感興趣,可以在我的GitHub存儲庫中查看我的整個代碼,以進行Sparkify分析。
Hope you enjoy reading this long blog and learn the strategies booming your business in Data Science Way!
希望您喜歡閱讀這個漫長的博客,并學習以Data Science Way推動業務蓬勃發展的策略!
翻譯自: https://medium.com/@jessie.sssy/understanding-customer-churning-abd6525d61c5
客戶流失
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/387946.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/387946.shtml 英文地址,請注明出處:http://en.pswp.cn/news/387946.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

Java 動態加載class 并反射調用方法

Nginx:Nginx limit_req limit_conn限速

快速數據庫框架_快速學習新的數據科學概念的框架

Linux實戰教學筆記12:linux三劍客之sed命令精講

activiti 為什么需要采用樂觀鎖?
)
Python實現三級菜單(字典和列表的使用)

停止使用p = 0.05

centos7系統根目錄擴容

instrumentation模擬很多activity的操作

成像數據更好的展示_為什么更多的數據并不總是更好



Android Studio 導入新工程項目

馬蜂窩張矗:績效考核是為了激發工作潛力,而不是逃避問題

vue domo網站_DOMO與Tableau-逐輪

fiddler抓包1-抓小程序https包


Linux下的 FTP
)
python入門23 pymssql模塊(python連接sql server增刪改數據 )
