視頻鏈接:
https://www.youtube.com/watch?v=ugWDIIOHtPA&list=PLJV_el3uVTsOK_ZK5L0Iv_EQoL1JefRL4&index=60
文章目錄
- Self-Attention layer
- Multi-head self-attention
- Positional encoding
- Seq2Seq with Attention
- Transformer
- Universal Transformer
Seq2Seq
RNN不容易被平行化
提出用CNN來代替RNN,CNN 可以平行化,但是需要的層數比較深,才能看完所有的輸入內容。
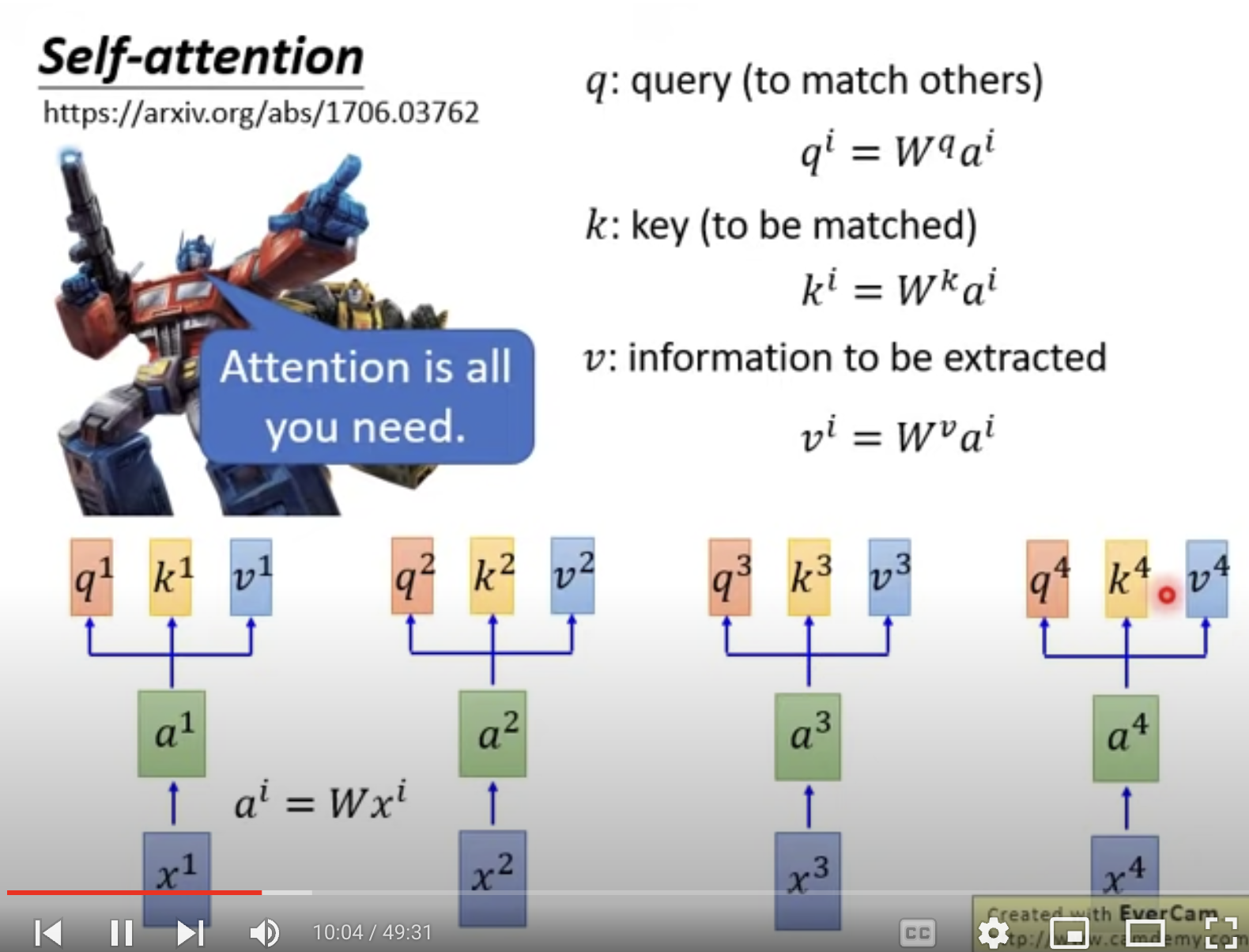
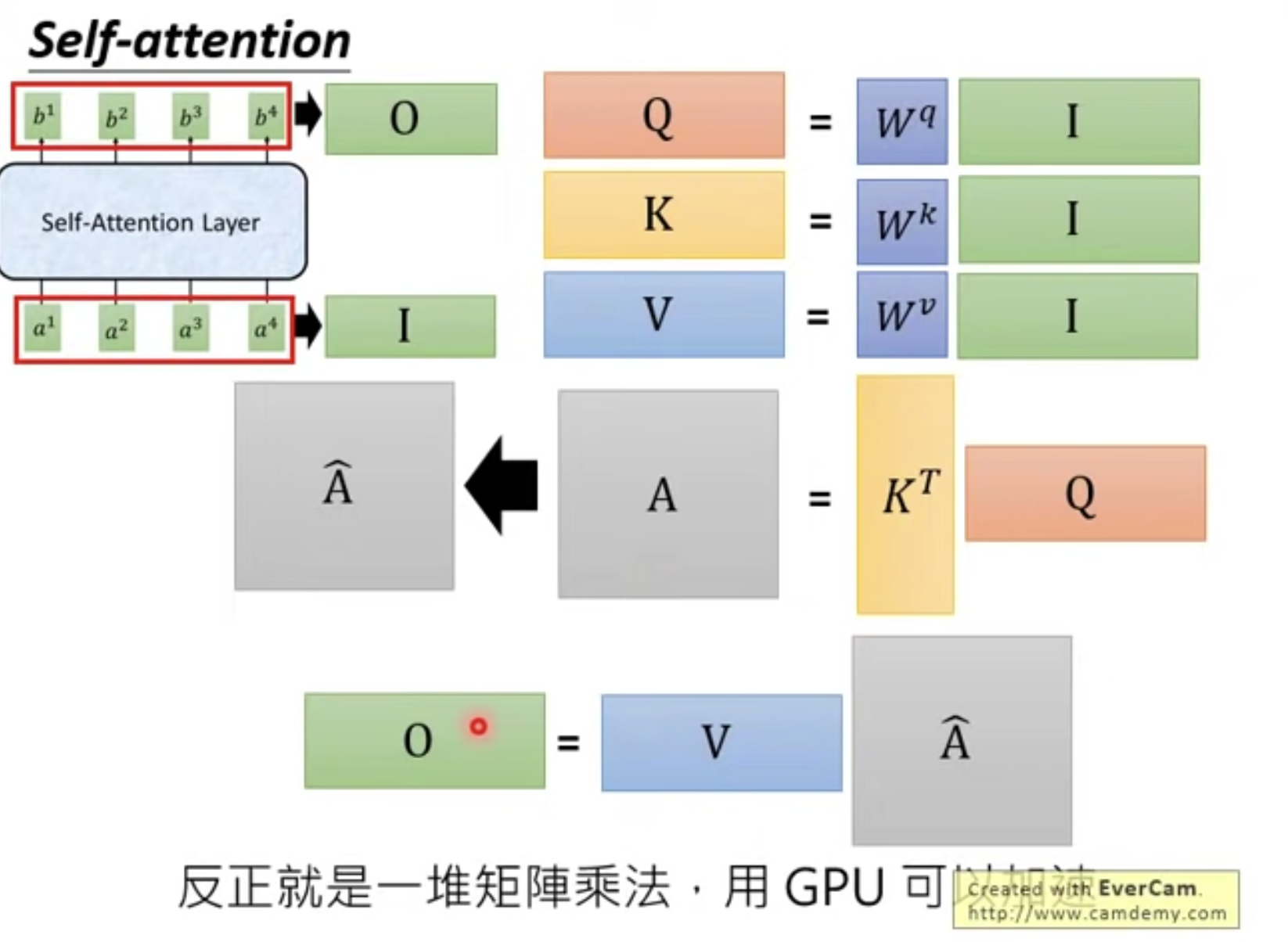
Self-Attention layer

b1 到b4 是可以同時被算出。
可以用來取代RNN。
來源: Attention is all you need
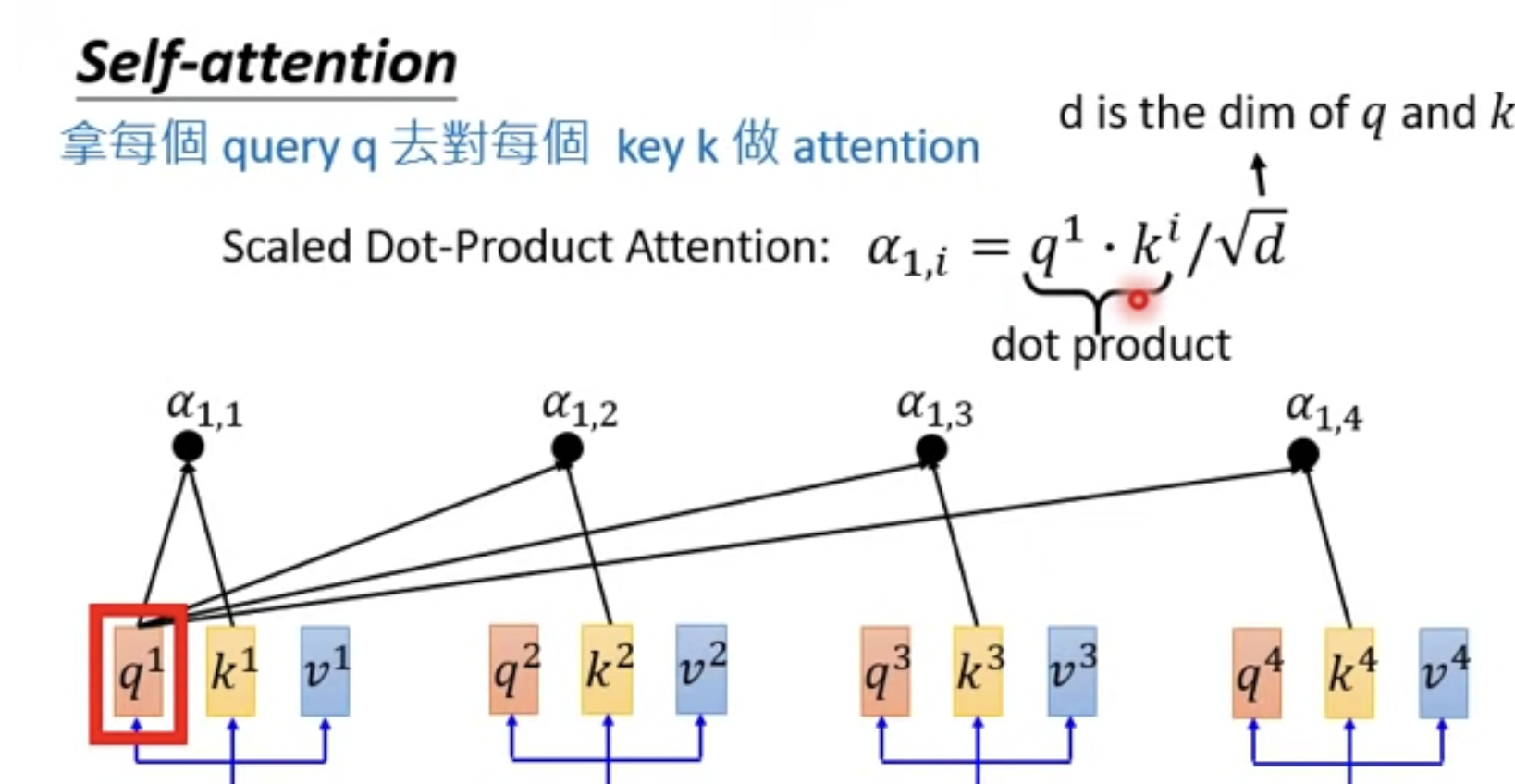
然后用每一個a 去對每個k 做attention
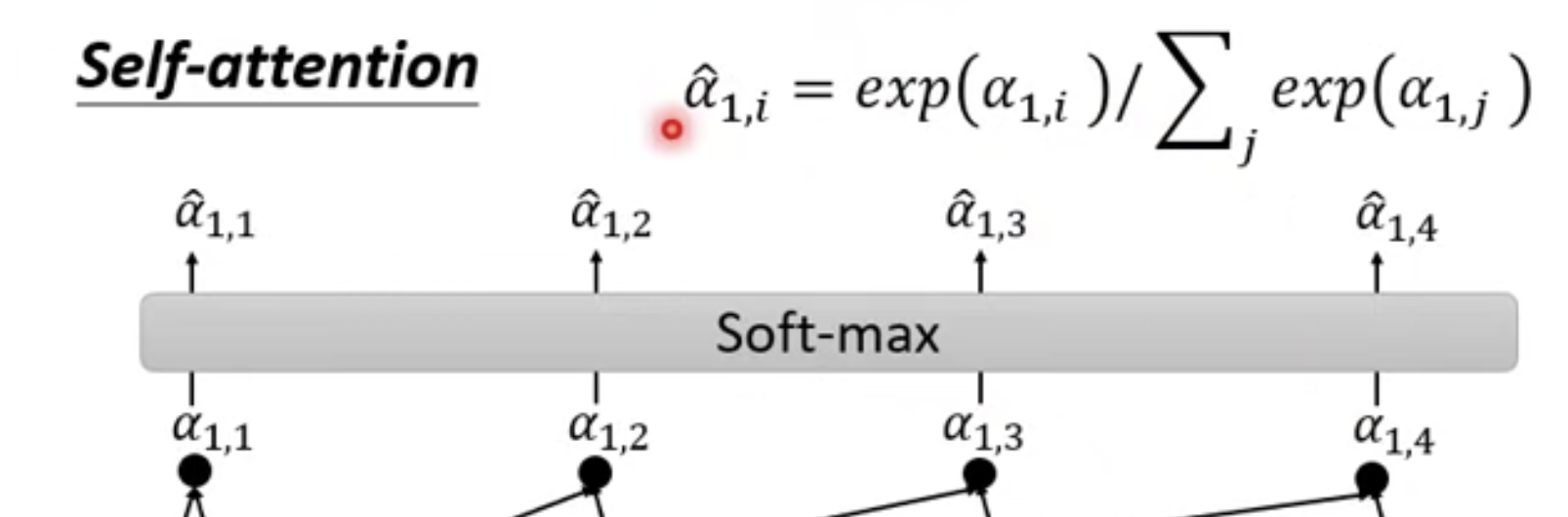
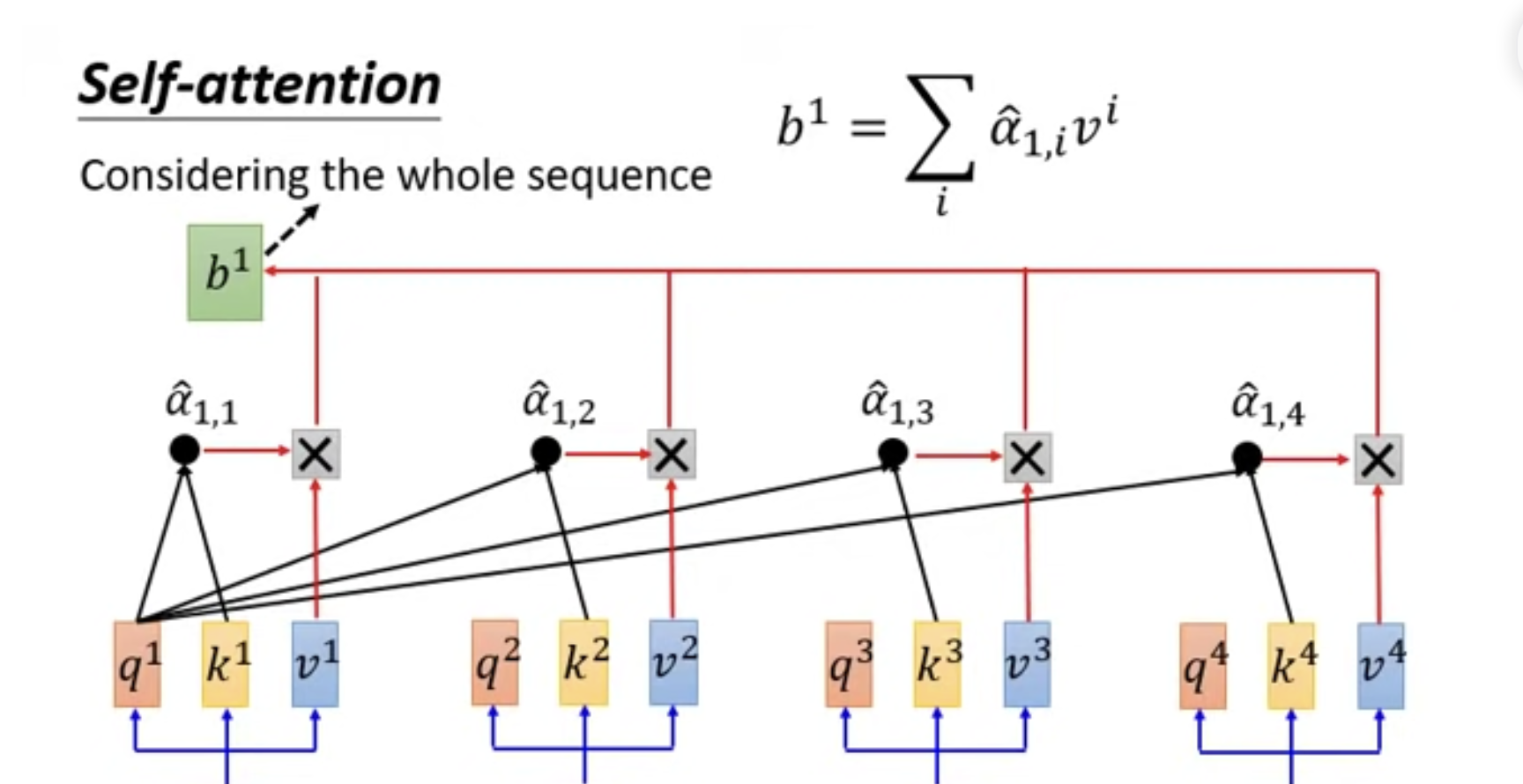
加速的矩陣乘法過程
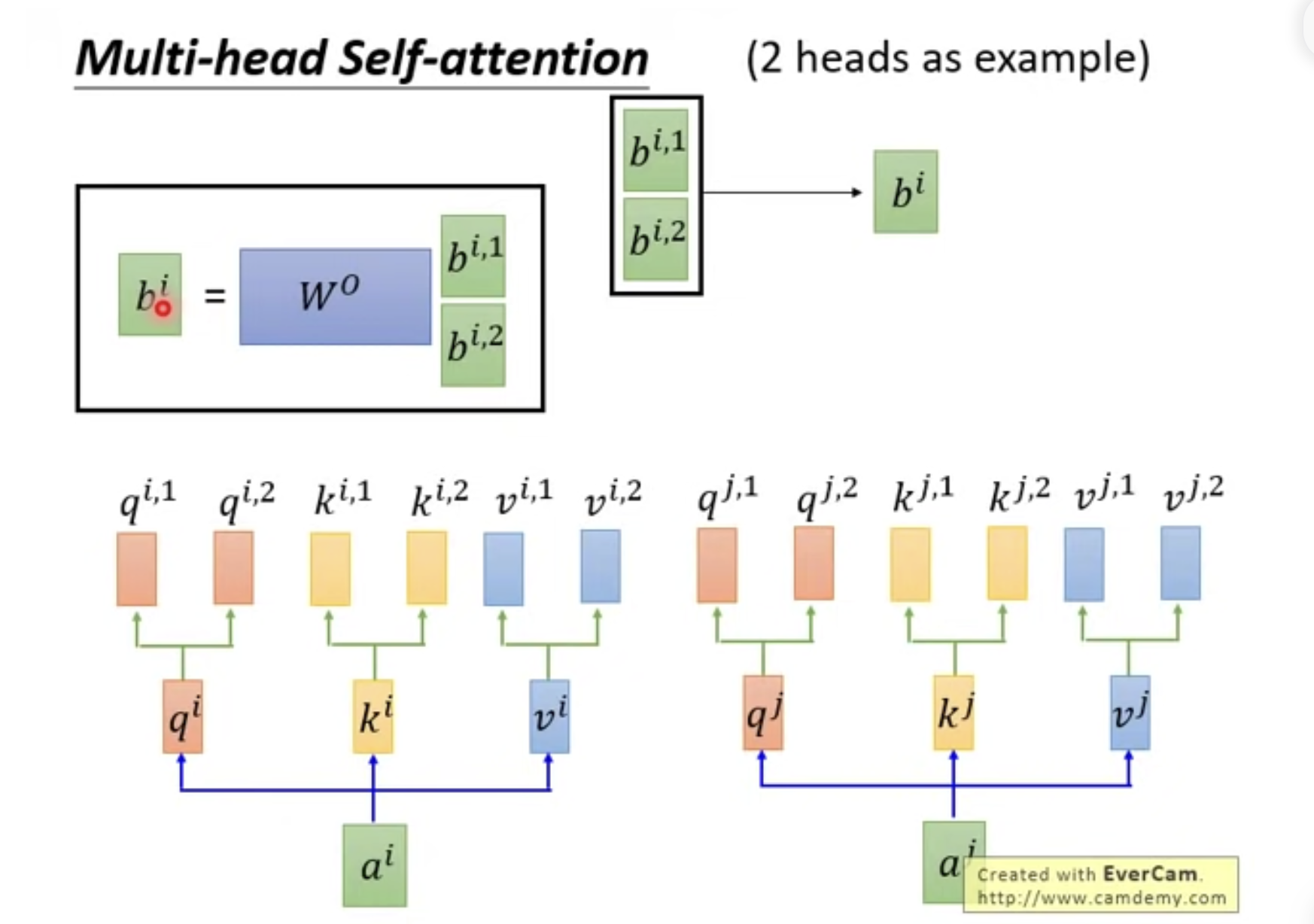
Multi-head self-attention
不同的head 可以關注不同的內容,達到一個更好的注意力效果。
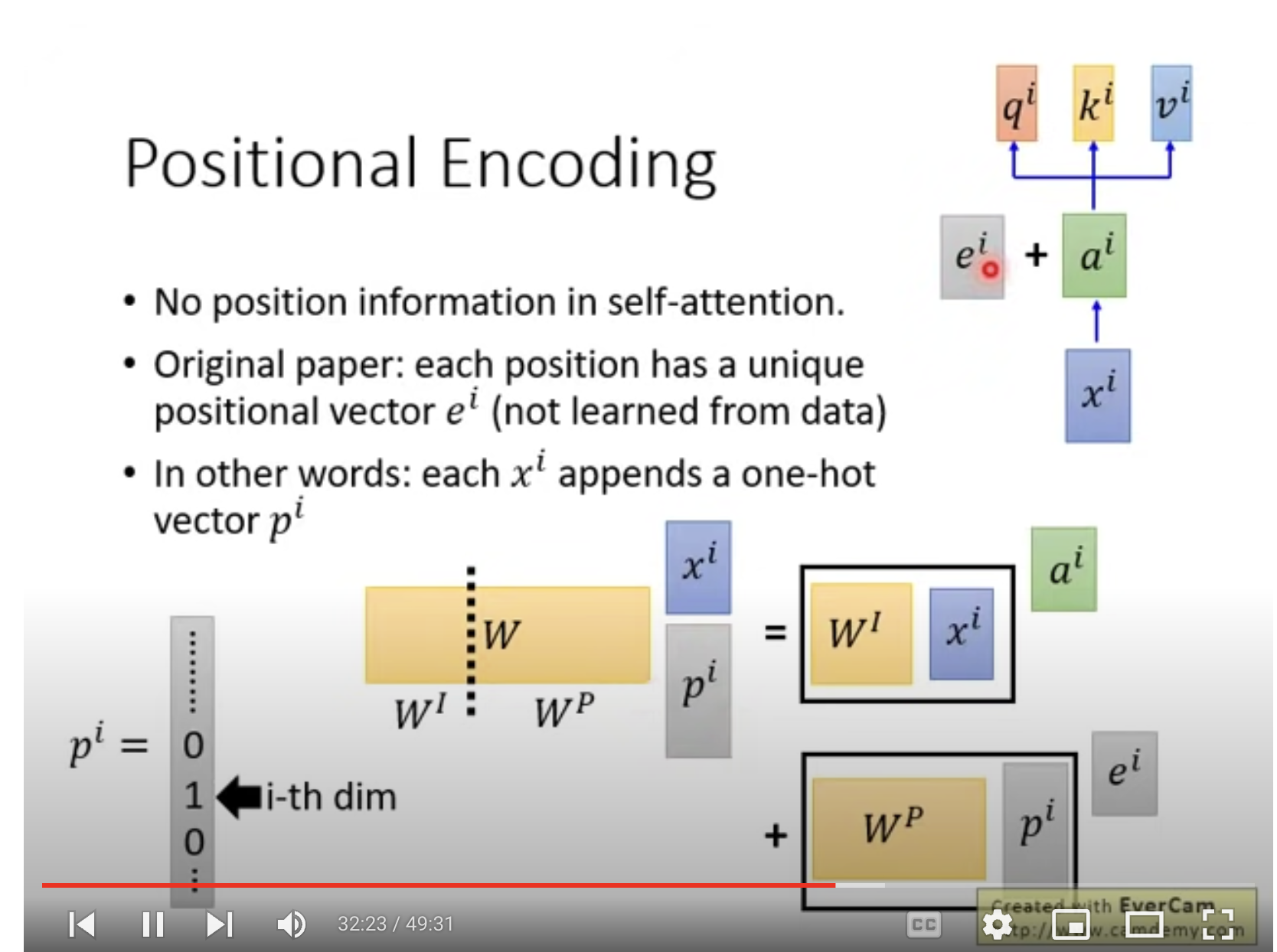
Positional encoding
self-attention 沒有考慮位置信息。
因此需要再ai的同時加ei,表示位置信息,有人工控制。
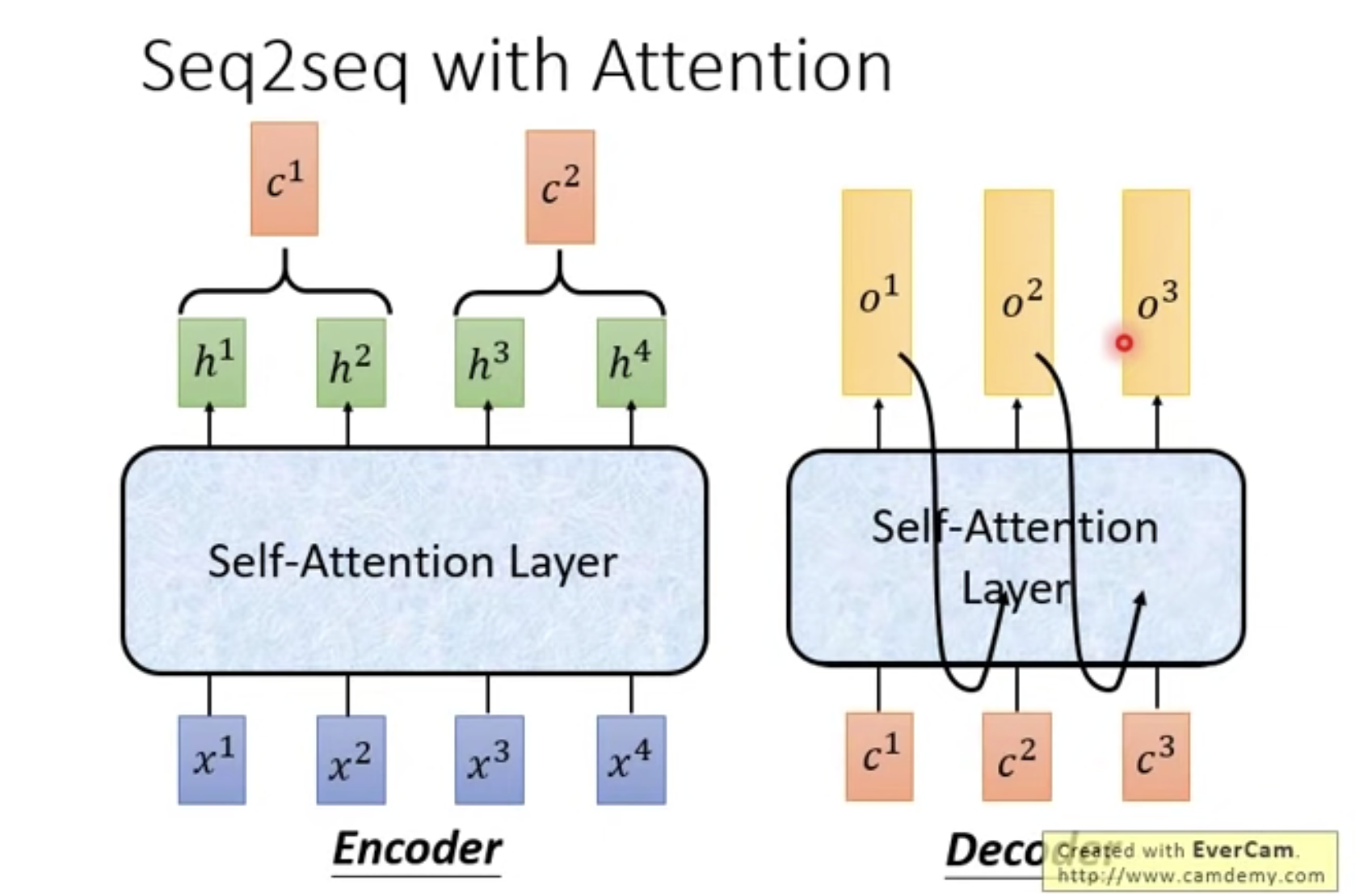
Seq2Seq with Attention
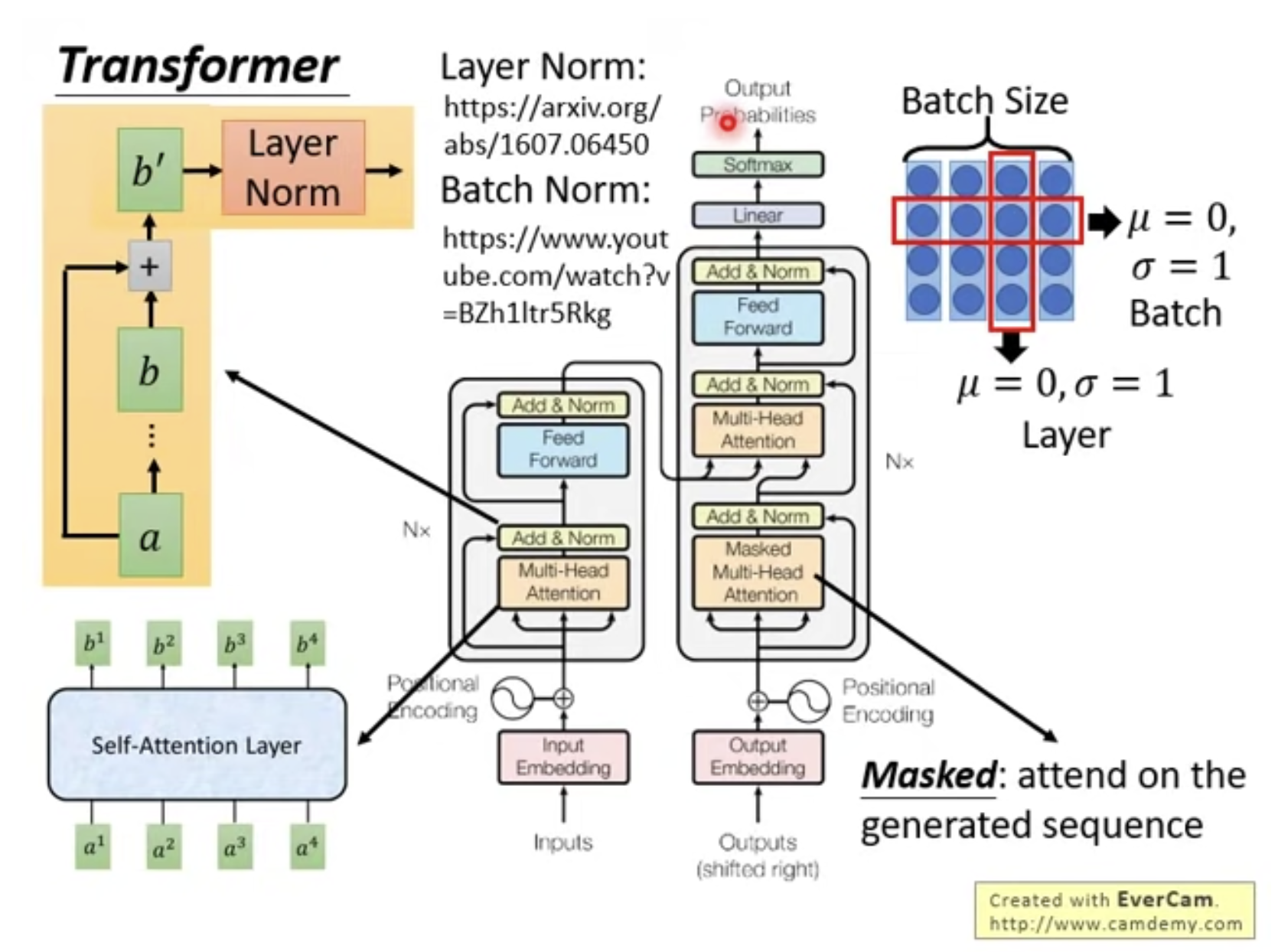
Transformer

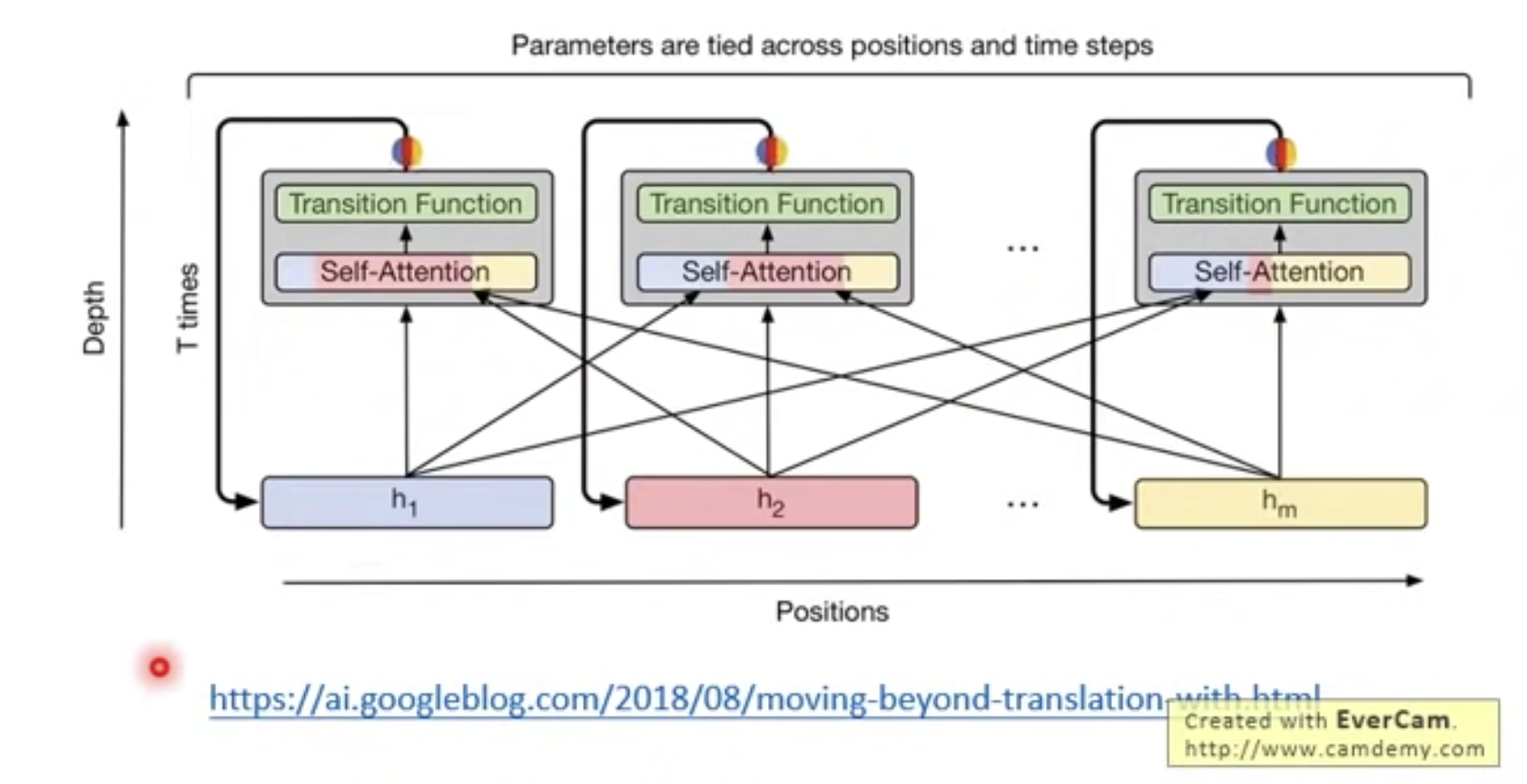
Universal Transformer

)











![[cv] stable diffusion——2、公式](http://pic.xiahunao.cn/[cv] stable diffusion——2、公式)

)

)

