對于ToC端來說,廣大群眾的口味已經被ChatGPT給養叼了,市場基本上被ChatGPT吃的干干凈凈。雖然國內大廠在緊追不舍,但目前絕大多數都還在實行內測機制,大概率是不會廣泛開放的(畢竟,各大廠還是主盯ToB、ToG市場的,從華為在WAIC的匯報就可以看出)。而對于ToB和ToG端來說,本地化部署、領域or行業內效果絕群、國產化無疑就成為了重要的考核指標。
個人覺得垂直領域大模型或者說大模型領域化、行業化才是大模型落地的核心要素。恰好前幾天ChatLaw(一款法律領域大模型產品)也是大火,當時也是拿到了一手內測資格測試了一陣,也跟該模型的作者聊了很久。正好利用周末的時間,好好思考、梳理、匯總了一些垂直領域大模型內容。
文章內容將從ChatLaw展開、到垂直領域大模型的一些討論、最后匯總一下現有的開源領域大模型。
聊聊對ChatLaw的看法
ChatLaw的出現,讓我更加肯定未來大模型落地需要具有領域特性。相較于目前領域大模型,ChatLaw不僅僅是一個模型,而是一個經過設計的大模型領域產品,已經在法律領域具有很好的產品形態。
Paper:?https://arxiv.org/pdf/2306.16092.pdf
Github:?https://github.com/PKU-YuanGroup/ChatLaw官網:?https://www.chatlaw.cloud/
可能會有一些質疑,比如:不就是一個langchain嗎?法律領域它能保證事實性問題嗎?等等等。但,我覺得在否定一件事物的前提,是先去更深地了解它。
ChatLaw共存在兩種模式:普通模型和專業模型。普通模式就是僅基于大模型進行問答。
而專業模式是借助檢索的手段,對用戶查詢進行匹配從知識庫中篩選出合適的證據,再根據大模型匯總能力,得到最終答案。
由于專業模式,借助了知識庫的內容,也會使得用戶得到的效果更加精準。而在專業版中,ChatLaw制定了一整套流程,如上圖所示,存在反問提示進行信息補全,用戶信息確認、相似案例檢索、建議匯總等。
作者@JessyTsui(知乎) 也說過,其實ChatLaw=ChatLaw LLM + keyword LLM + laws LLM。而keyword LLM真的讓我眼前一亮的,之前對關鍵詞抽取的理解,一直是從文本中找到正確的詞語,在傳統檢索中使用同義詞等方法來提高檢索效果。而keyword LLM利用大模型生成關鍵詞,不僅可以找到文本中的重點內容,還可以總結并釋義出一些詞。使得整個產品在檢索證據內容時,效果更加出色。
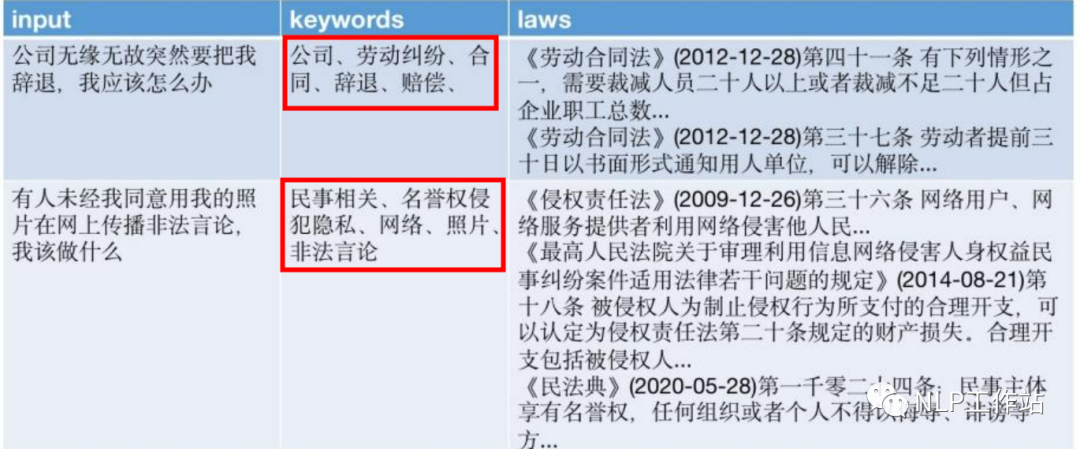
同時,由于不同模型對不同類型問題解決效果并不相同,所以在真正使用階段,采用HuggingGPT作為調度器的方式,在每次用戶請求的時候去選擇調用更加適配的模型。也就是讓適合的模型做更適合的事情。
聊聊對垂直領域大模型的看法
現在大模型的使用主要就是兩種模型,第一種是僅利用大模型本身解決用戶問題;第二種就是借助外部知識來解決用戶問題。而我個人覺得是“借助外部知識進行問答”才是未來,雖然會對模型推理增加額外成本,但是外部知識是緩解模型幻覺的有效方法。
但隨著通用大模型底層能力越來越強,以及可接受文本越來越長,在解決垂直領域問題時,完全可以采用ICL技術,來提升通用大模型在垂直領域上的效果,那么訓練一個垂直領域大模型是否是一個偽命題,我們還有必要做嗎?
個人認為是需要的,從幾個方面來討論:
-
1、個人覺得真正垂直領域大模型的做法,應該從Pre-Train做起。SFT只是激發原有大模型的能力,預訓練才是真正知識灌輸階段,讓模型真正學習領域數據知識,做到適配領域。但目前很多垂直領域大模型還停留在SFT階段。
-
2、對于很多企業來說,領域大模型在某幾個能力上絕群就可以了。難道我能源行業,還需要care模型詩寫的如何嗎?所以領域大模型在行業領域上效果是優于通用大模型即可,不需要“即要又要還要”。
-
3、不應某些垂直領域大模型效果不如ChatGPT,就否定垂直領域大模型。有沒有想過一件可怕的事情,ChatGPT見的垂直領域數據,比你的領域大模型見的還多。但某些領域數據,ChatGPT還是見不到的。
-
4、考慮到部署成本得問題,我覺得在7B、13B兩種規模的參數下,通用模型真地干不過領域模型。及時175B的領域大模型沒有打過175B的通用模型又能怎么樣呢?模型參數越大,需要數據量越大,領域可能真的沒有那么多數據。
PS:很多非NLP算法人員對大模型產品落地往往會有一些疑問:?
Q:我有很多的技術標準和領域文本數據,直接給你就能訓練領域大模型了吧??
A:是也不是,純文本只能用于模型的預訓練,真正可以進行后續問答,需要的是指令數據。當然可以采用一些人工智能方法生成一些指數據,但為了保證事實性,還是需要進行人工校對的。高質量SFT數據,才是模型微調的關鍵。?
Q:你用領域數據微調過的大模型,為什么不直接問答,還要用你的知識庫??
A:外部知識主要是為了解決模型幻覺、提高模型回復準確。?
Q:為什么兩次回復結果不一樣??
A:大模型一般為了保證多樣性,解碼常采用Top-P、Top-K解碼,這種解碼會導致生成結果不可控。如果直接采用貪婪解碼,模型生成結果會是局部最優。?
Q:我是不是用開源6B、7B模型自己訓練一個模型就夠了??
A:兄弟,沒有訓練過33B模型的人,永遠只覺得13B就夠了。
以上是個人的一些想法,以及一些常見問題的回復,不喜勿噴,歡迎討論,畢竟每個人對每件事的看法都不同。
開源垂直領域大模型匯總
目前有很多的垂直領域大模型已經開源,主要在醫療、金融、法律、教育等領域,本小節主要進行「中文開源」模型的匯總及介紹。
「PS:一些領域大模型,如未開源不在該匯總范圍內;并且歡迎大家留言,查缺補漏。」
醫療領域
非中文項目:BioMedLM、PMC-LLaMA、ChatDoctor、BioMedGPT等,在此不做介紹。
MedicalGPT-zh
Github:?https://github.com/MediaBrain-SJTU/MedicalGPT-zh
-
簡介:基于ChatGLM-6B指令微調的中文醫療通用模型。
-
數據:通過對16組診療情景和28個科室醫用指南借助ChatGPT構造182k條數據。數據也已開源。
-
訓練方法:基于ChatGLM-6B,采用Lora&16bit方法進行模型訓練。
DoctorGLM
Github:?https://github.com/xionghonglin/DoctorGLM
-
簡介:一個基于ChatGLM-6B的中文問診模型。
-
數據:主要采用CMD(Chinese Medical Dialogue Data)數據。
-
訓練方法:基于ChatGLM-6B模型,采用Lora和P-tuning-v2兩種方法進行模型訓練。
PS:數據來自Chinese-medical-dialogue-data項目。
Huatuo-Llama-Med-Chinese
Github:?https://github.com/SCIR-HI/Huatuo-Llama-Med-Chinese
-
簡介:本草(原名:華駝-HuaTuo): 基于中文醫學知識的LLaMA微調模型。
-
數據:通過醫學知識圖譜和GPT3.5 API構建了中文醫學指令數據集,數據共開源9k條。
-
訓練方法:基于Llama-7B模型,采用Lora方法進行模型訓練。
Med-ChatGLM
Github:?https://github.com/SCIR-HI/Med-ChatGLM
-
簡介:基于中文醫學知識的ChatGLM模型微調,與本草為兄弟項目。
-
數據:與Huatuo-Llama-Med-Chinese相同。
-
訓練方法:基于ChatGLM-6B模型,采用Lora方法進行模型訓練。
ChatMed
Github:?https://github.com/michael-wzhu/ChatMed
-
簡介:中文醫療大模型,善于在線回答患者/用戶的日常醫療相關問題.
-
數據:50w+在線問診+ChatGPT回復作為訓練集。
-
訓練方法:基于Llama-7B模型,采用Lora方法進行模型訓練。
ShenNong-TCM-LLM
Github:?https://github.com/michael-wzhu/ShenNong-TCM-LLM
-
簡介:“神農”大模型,首個中醫藥中文大模型,與ChatMed為兄弟項目。
-
數據:以中醫藥知識圖譜為基礎,采用以實體為中心的自指令方法,調用ChatGPT得到11w+的圍繞中醫藥的指令數據。
-
訓練方法:基于Llama-7B模型,采用Lora方法進行模型訓練。
BianQue
Github:?https://github.com/scutcyr/BianQue
-
簡介:扁鵲,中文醫療對話模型。
-
數據:結合當前開源的中文醫療問答數據集(MedDialog-CN、IMCS-V2、CHIP-MDCFNPC、MedDG、cMedQA2、Chinese-medical-dialogue-data),分析其中的單輪/多輪特性以及醫生問詢特性,結合實驗室長期自建的生活空間健康對話大數據,構建了千萬級別規模的扁鵲健康大數據BianQueCorpus。
-
訓練方法:扁鵲-1.0以ChatYuan-large-v2作為底座模型全量參數訓練得來,扁鵲-2.0以ChatGLM-6B作為底座模型全量參數訓練得來。
SoulChat
Github:?https://github.com/scutcyr/SoulChat
-
簡介:中文領域心理健康對話大模型,與BianQue為兄弟項目。
-
數據:構建了超過15萬規模的單輪長文本心理咨詢指令數據,并利用ChatGPT與GPT4,生成總共約100萬輪次的多輪回答數據。
-
訓練方法:基于ChatGLM-6B模型,采用全量參數微調方法進行模型訓練。
法律領域
LaWGPT
Github:?https://github.com/pengxiao-song/LaWGPT
-
簡介:基于中文法律知識的大語言模型。
-
數據:基于中文裁判文書網公開法律文書數據、司法考試數據等數據集展開,利用Stanford_alpaca、self-instruct方式生成對話問答數據,利用知識引導的數據生成,引入ChatGPT清洗數據,輔助構造高質量數據集。
-
訓練方法:(1)Legal-Base-7B模型:法律基座模型,使用50w中文裁判文書數據二次預訓練。(2)LaWGPT-7B-beta1.0模型:法律對話模型,構造30w高質量法律問答數據集基于Legal-Base-7B指令精調。(3)LaWGPT-7B-alpha模型:在Chinese-LLaMA-7B的基礎上直接構造30w法律問答數據集指令精調。(4)LaWGPT-7B-beta1.1模型:法律對話模型,構造35w高質量法律問答數據集基于Chinese-alpaca-plus-7B指令精調。
ChatLaw
Github:?https://github.com/PKU-YuanGroup/ChatLaw
-
簡介:中文法律大模型
-
數據:主要由論壇、新聞、法條、司法解釋、法律咨詢、法考題、判決文書組成,隨后經過清洗、數據增強等來構造對話數據。
-
訓練方法:(1)ChatLaw-13B:基于姜子牙Ziya-LLaMA-13B-v1模型采用Lora方式訓練而來。(2)ChatLaw-33B:基于Anima-33B采用Lora方式訓練而來。
LexiLaw
Github:?https://github.com/CSHaitao/LexiLaw
-
簡介:中文法律大模型
-
數據:BELLE-1.5M通用數據、LawGPT項目中52k單輪問答數據和92k帶有法律依據的情景問答數據、Lawyer LLaMA項目中法考數據和法律指令微調數據、華律網20k高質量問答數據、百度知道收集的36k條法律問答數據、法律法規、法律參考書籍、法律文書。
-
訓練方法:基于ChatGLM-6B模型,采用Freeze、Lora、P-Tuning-V2三種方法進行模型訓練。
LAW-GPT
Github:?https://github.com/LiuHC0428/LAW-GPT
-
簡介:中文法律大模型(獬豸)
-
數據:現有的法律問答數據集和基于法條和真實案例指導的self-Instruct構建的高質量法律文本問答數據。
-
訓練方法:基于ChatGLM-6B,采用Lora&16bit方法進行模型訓練。
lawyer-llama
Github:?https://github.com/AndrewZhe/lawyer-llama
-
簡介:中文法律LLaMA
-
數據:法考數據7k、法律咨詢數據14k
-
訓練方法:以Chinese-LLaMA-13B為底座,未經過法律語料continual training,使用通用instruction和法律instruction進行SFT。
金融領域
非中文較好的項目:BloombergGPT、PIXIU等,在此不做介紹。
FinGPT
Github:?https://github.com/AI4Finance-Foundation/FinGPT
-
簡介:金融大模型
-
數據:來自東方財富
-
訓練方法:基于ChatGLM-6B,采用Lora方法訓練模型。
FinTuo
Github:?https://github.com/qiyuan-chen/FinTuo-Chinese-Finance-LLM
-
簡介:一個中文金融大模型項目,旨在提供開箱即用且易于拓展的金融領域大模型工具鏈。
-
數據:暫未完成。
-
訓練方法:暫未完成。
教育領域
EduChat
Github:?https://github.com/icalk-nlp/EduChat
-
簡介:以預訓練大模型為基底的教育對話大模型相關技術,提供教育場景下自動出題、作業批改、情感支持、課程輔導、高考咨詢等豐富功能,服務于廣大老師、學生和家長群體,助力實現因材施教、公平公正、富有溫度的智能教育。
-
數據:混合多個開源中英指令、對話數據,并去重后得到,約400w。
-
訓練方法:基于LLaMA模型訓練而來。





)
)











——生成敵方炮彈(rand()和srand()函數應用))
