文章目錄
- MySQL結構
- 1.2存儲引擎介紹
- 1.3存儲引擎特點
- InnoDB
- 邏輯存儲結構
- MyISAM
- Memory
- 區別及特點
- 存儲引擎選擇
- 索引
- 索引概述
- 索引結構
- B+Tree
- Hash
- 索引分類
- 聚集索引&二級索引
- 索引語法
- SQL性能分析
- 索引優化
- 最左前綴法則
- 范圍查詢
- 字符串不加引號
- 模糊查詢
- or連接條件
- 數據分布影響
- 覆蓋索引
- 前綴索引
- 索引設計原則
MySQL結構
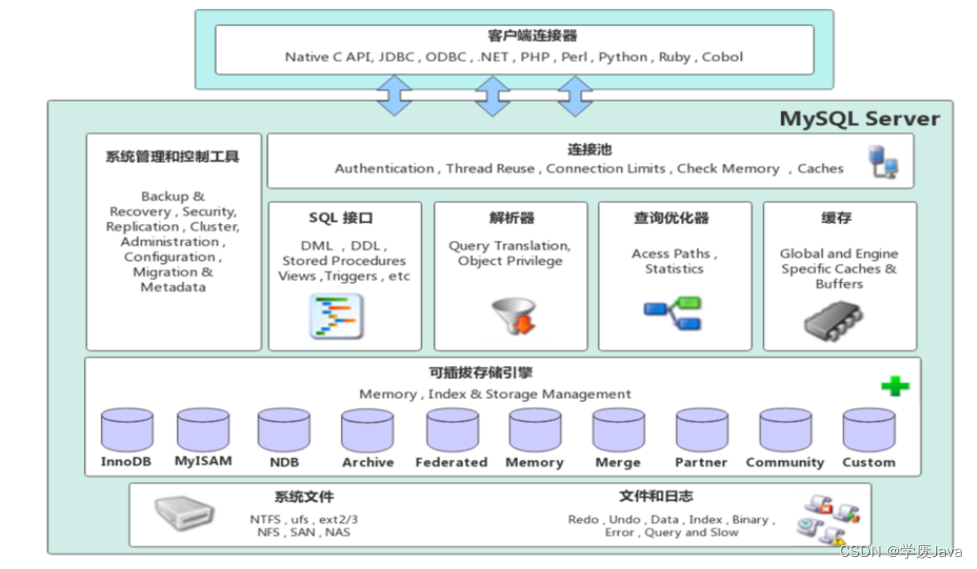 1). 連接層
1). 連接層
最上層是一些客戶端和鏈接服務,包含本地sock 通信和大多數基于客戶端/服務端工具實現的類似于
TCP/IP的通信。主要完成一些類似于連接處理、授權認證、及相關的安全方案。在該層上引入了線程
池的概念,為通過認證安全接入的客戶端提供線程。同樣在該層上可以實現基于SSL的安全鏈接。服務
器也會為安全接入的每個客戶端驗證它所具有的操作權限。
2). 服務層
第二層架構主要完成大多數的核心服務功能,如SQL接口,并完成緩存的查詢,SQL的分析和優化,部
分內置函數的執行。所有跨存儲引擎的功能也在這一層實現,如 過程、函數等。在該層,服務器會解
析查詢并創建相應的內部解析樹,并對其完成相應的優化如確定表的查詢的順序,是否利用索引等,
最后生成相應的執行操作。如果是select語句,服務器還會查詢內部的緩存,如果緩存空間足夠大,
這樣在解決大量讀操作的環境中能夠很好的提升系統的性能。
3). 引擎層
存儲引擎層, 存儲引擎真正的負責了MySQL中數據的存儲和提取,服務器通過API和存儲引擎進行通
信。不同的存儲引擎具有不同的功能,這樣我們可以根據自己的需要,來選取合適的存儲引擎。數據庫
中的索引是在存儲引擎層實現的。
4). 存儲層
數據存儲層, 主要是將數據(如: redolog、undolog、數據、索引、二進制日志、錯誤日志、查詢
日志、慢查詢日志等)存儲在文件系統之上,并完成與存儲引擎的交互。
和其他數據庫相比,MySQL有點與眾不同,它的架構可以在多種不同場景中應用并發揮良好作用。主要
體現在存儲引擎上,插件式的存儲引擎架構,將查詢處理和其他的系統任務以及數據的存儲提取分離。
這種架構可以根據業務的需求和實際需要選擇合適的存儲引擎。
1.2存儲引擎介紹

大家可能沒有聽說過存儲引擎,但是一定聽過引擎這個詞,引擎就是發動機,是一個機器的核心組件。
比如,對于艦載機、直升機、火箭來說,他們都有各自的引擎,是他們最為核心的組件。而我們在選擇
引擎的時候,需要在合適的場景,選擇合適的存儲引擎,就像在直升機上,我們不能選擇艦載機的引擎
一樣。
而對于存儲引擎,也是一樣,他是mysql數據庫的核心,我們也需要在合適的場景選擇合適的存儲引
擎。接下來就來介紹一下存儲引擎。
存儲引擎就是存儲數據、建立索引、更新/查詢數據等技術的實現方式 。存儲引擎是基于表的,而不是
基于庫的,所以存儲引擎也可被稱為表類型。我們可以在創建表的時候,來指定選擇的存儲引擎,如果
沒有指定將自動選擇默認的存儲引擎。
- 建表時指定引擎存儲
CREATE TABLE 表名(
字段1 字段1類型 [ COMMENT 字段1注釋 ] ,
......
字段n 字段n類型 [COMMENT 字段n注釋 ]
) ENGINE = INNODB [ COMMENT 表注釋 ] ;
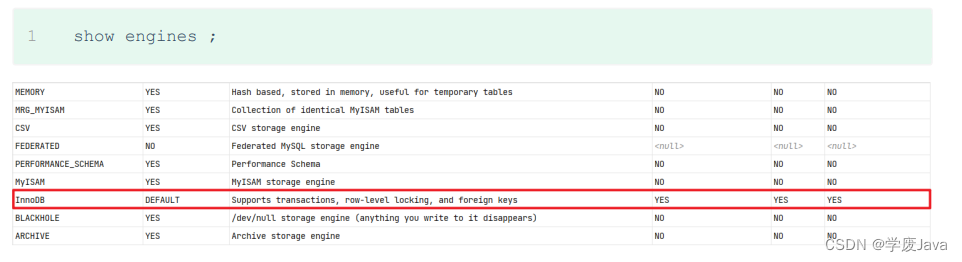
- 查詢當前數據庫支持的存儲引擎
show engunes;
1.3存儲引擎特點
上面我們介紹了什么是存儲引擎,以及如何在建表時如何指定存儲引擎,接下來我們就來介紹下來上面
重點提到的三種存儲引擎 InnoDB、MyISAM、Memory的特點。
InnoDB
1). 介紹
InnoDB是一種兼顧高可靠性和高性能的通用存儲引擎,在 MySQL 5.5 之后,InnoDB是默認的
MySQL 存儲引擎。
2). 特點
DML操作遵循ACID模型,支持事務;
行級鎖,提高并發訪問性能;
支持外鍵FOREIGN KEY約束,保證數據的完整性和正確性;
3). 文件
xxx.ibd:xxx代表的是表名,innoDB引擎的每張表都會對應這樣一個表空間文件,存儲該表的表結
構(frm-早期的 、sdi-新版的)、數據和索引。
- 如果該參數開啟,代表對于InnoDB引擎的表,每一張表都對應一個ibd文件。 我們直接打開MySQL的
數據存放目錄: C:\ProgramData\MySQL\MySQL Server 8.0\Data , 這個目錄下有很多文件
夾,不同的文件夾代表不同的數據庫,我們直接打開itcast文件夾。

可以看到里面有很多的ibd文件,每一個ibd文件就對應一張表,比如:我們有一張表 account,就
有這樣的一個account.ibd文件,而在這個ibd文件中不僅存放表結構、數據,還會存放該表對應的
索引信息。 而該文件是基于二進制存儲的,不能直接基于記事本打開,我們可以使用mysql提供的一
個指令 ibd2sdi ,通過該指令就可以從ibd文件中提取sdi信息,而sdi數據字典信息中就包含該表的表結構
邏輯存儲結構
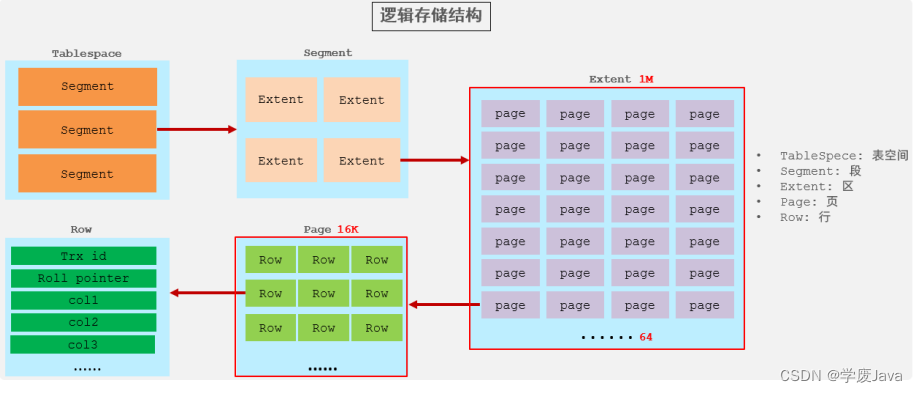
- 表空間 : InnoDB存儲引擎邏輯結構的最高層,ibd文件其實就是表空間文件,在表空間中可以
包含多個Segment段。 - 段 : 表空間是由各個段組成的, 常見的段有數據段、索引段、回滾段等。InnoDB中對于段的管
理,都是引擎自身完成,不需要人為對其控制,一個段中包含多個區。 - 區 : 區是表空間的單元結構,每個區的大小為1M。 默認情況下, InnoDB存儲引擎頁大小為
16K, 即一個區中一共有64個連續的頁。 - 頁 : 頁是組成區的最小單元,頁也是InnoDB 存儲引擎磁盤管理的最小單元,每個頁的大小默
認為 16KB。為了保證頁的連續性,InnoDB 存儲引擎每次從磁盤申請 4-5 個區。 - 行 : InnoDB 存儲引擎是面向行的,也就是說數據是按行進行存放的,在每一行中除了定義表時
所指定的字段以外,還包含兩個隱藏字段(后面會詳細介紹)。
MyISAM
1). 介紹
MyISAM是MySQL早期的默認存儲引擎。
2). 特點
不支持事務,不支持外鍵
支持表鎖,不支持行鎖
訪問速度快
3). 文件
xxx.sdi:存儲表結構信息
xxx.MYD: 存儲數據
xxx.MYI: 存儲索引

Memory
1). 介紹
Memory引擎的表數據時存儲在內存中的,由于受到硬件問題、或斷電問題的影響,只能將這些表作為
臨時表或緩存使用。
2). 特點
內存存放
hash索引(默認)
3).文件
xxx.sdi:存儲表結構信息
區別及特點
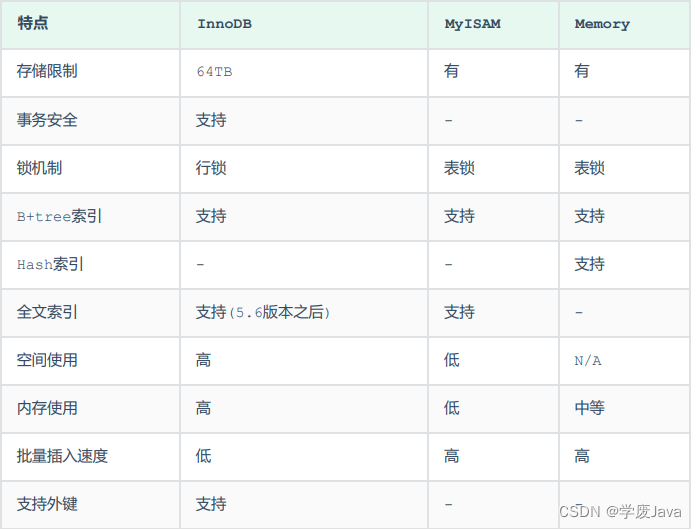
- 面試題:
InnoDB引擎與MyISAM引擎的區別 ?
①. InnoDB引擎, 支持事務, 而MyISAM不支持。
②. InnoDB引擎, 支持行鎖和表鎖, 而MyISAM僅支持表鎖, 不支持行鎖。
③. InnoDB引擎, 支持外鍵, 而MyISAM是不支持的。
存儲引擎選擇
在選擇存儲引擎時,應該根據應用系統的特點選擇合適的存儲引擎。對于復雜的應用系統,還可以根據
實際情況選擇多種存儲引擎進行組合。
- InnoDB: 是Mysql的默認存儲引擎,支持事務、外鍵。如果應用對事務的完整性有比較高的要
求,在并發條件下要求數據的一致性,數據操作除了插入和查詢之外,還包含很多的更新、刪除操
作,那么InnoDB存儲引擎是比較合適的選擇。 - MyISAM : 如果應用是以讀操作和插入操作為主,只有很少的更新和刪除操作,并且對事務的完
整性、并發性要求不是很高,那么選擇這個存儲引擎是非常合適的。 - MEMORY:將所有數據保存在內存中,訪問速度快,通常用于臨時表及緩存。MEMORY的缺陷就是
對表的大小有限制,太大的表無法緩存在內存中,而且無法保障數據的安全性。
索引
索引概述
索引(index)是幫助MySQL高效獲取數據的數據結構(有序)。在數據之外,數據庫系統還維護著滿足
特定查找算法的數據結構,這些數據結構以某種方式引用(指向)數據, 這樣就可以在這些數據結構
上實現高級查找算法,這種數據結構就是索引。

- 在無索引情況下,就需要從第一行開始掃描,一直掃描到最后一行,我們稱之為 全表掃描,性能很
低。 - 如果我們針對于這張表建立了索引,假設索引結構就是二叉樹,那么也就意味著,會對age這個字段建
立一個二叉樹的索引結構
索引結構
MySQL的索引是在存儲引擎層實現的,不同的存儲引擎有不同的索引結構,主要包含以下幾種:
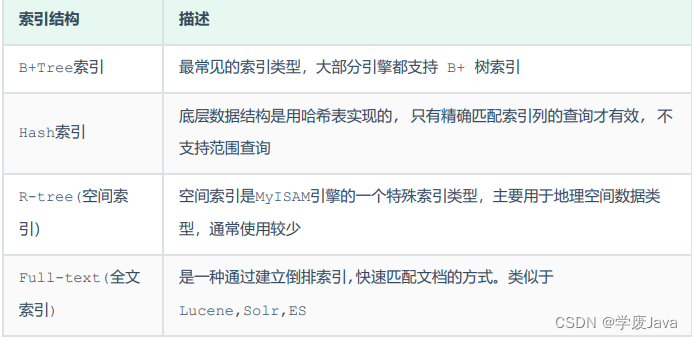
上述是MySQL中所支持的所有的索引結構,接下來,我們再來看看不同的存儲引擎對于索引結構的支持
情況。
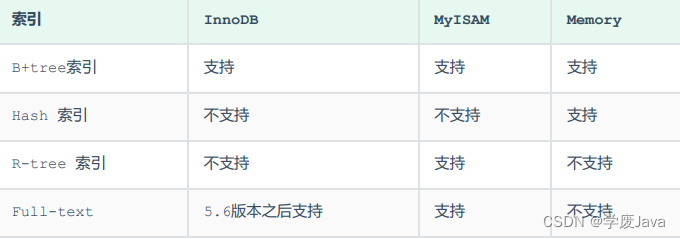
注意: 我們平常所說的索引,如果沒有特別指明,都是指B+樹結構組織的索引。
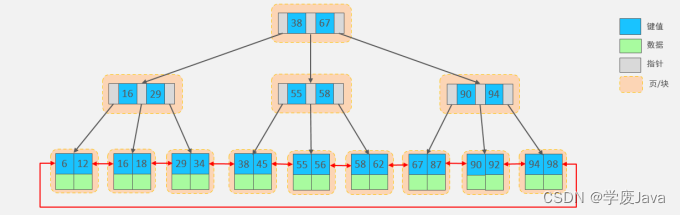
B+Tree
MySQL索引數據結構對經典的B+Tree進行了優化。在原B+Tree的基礎上,增加一個指向相鄰葉子節點
的鏈表指針,就形成了帶有順序指針的B+Tree,提高區間訪問的性能,利于排序。
Hash
MySQL中除了支持B+Tree索引,還支持一種索引類型—Hash索引。
- 結構
哈希索引就是采用一定的hash算法,將鍵值換算成新的hash值,映射到對應的槽位上,然后存儲在
hash表中 - 特點
A. Hash索引只能用于對等比較(=,in),不支持范圍查詢(between,>,< ,…)
B. 無法利用索引完成排序操作
C. 查詢效率高,通常(不存在hash沖突的情況)只需要一次檢索就可以了,效率通常要高于B+tree索
引 - 存儲引擎支持
在MySQL中,支持hash索引的是Memory存儲引擎。 而InnoDB中具有自適應hash功能,hash索引是
InnoDB存儲引擎根據B+Tree索引在指定條件下自動構建的。
面試題** 為什么InnoDB存儲引擎選擇使用B+tree索引結構?**
A. 相對于二叉樹,層級更少,搜索效率高;
B. 對于B-tree,無論是葉子節點還是非葉子節點,都會保存數據,這樣導致一頁中存儲
的鍵值減少,指針跟著減少,要同樣保存大量數據,只能增加樹的高度,導致性能降低;
C. 相對Hash索引,B+tree支持范圍匹配及排序操作;
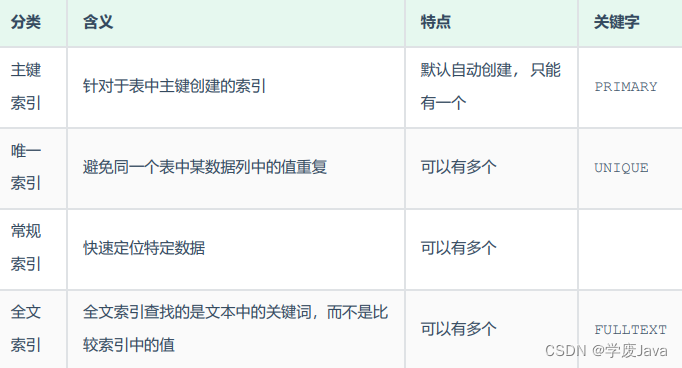
索引分類
在MySQL數據庫,將索引的具體類型主要分為以下幾類:主鍵索引、唯一索引、常規索引、全文索引。
聚集索引&二級索引
在在InnoDB存儲引擎中,根據索引的存儲形式,又可以分為以下兩種:
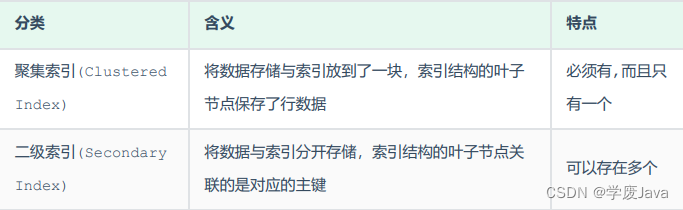
聚集索引選取規則:
- 如果存在主鍵,主鍵索引就是聚集索引。
- 如果不存在主鍵,將使用第一個唯一(UNIQUE)索引作為聚集索引。
- 如果表沒有主鍵,或沒有合適的唯一索引,則InnoDB會自動生成一個rowid作為隱藏的聚集索
引。
聚集索引和二級索引的具體結構如下:
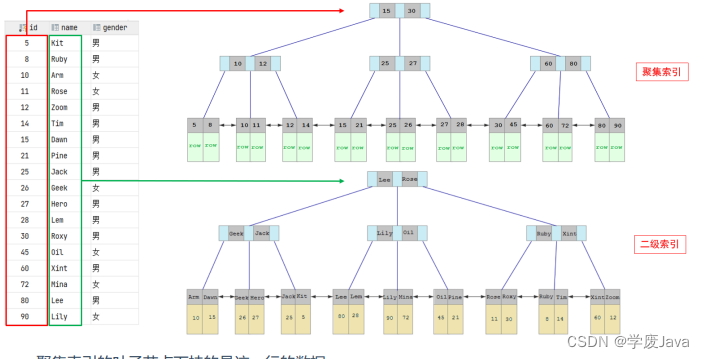
- 聚集索引的葉子節點下掛的是這一行的數據 。
- 二級索引的葉子節點下掛的是該字段值對應的主鍵值
接下來,我們來分析一下,當我們執行如下的SQL語句時,具體的查找過程是什么樣子的。
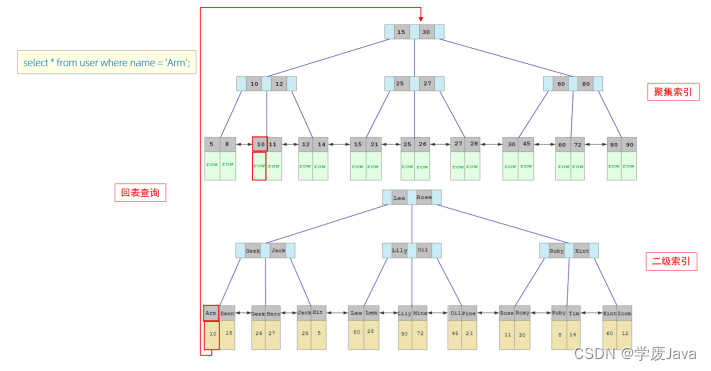
具體過程如下:
①. 由于是根據name字段進行查詢,所以先根據name='Arm’到name字段的二級索引中進行匹配查
找。但是在二級索引中只能查找到 Arm 對應的主鍵值 10。
②. 由于查詢返回的數據是*,所以此時,還需要根據主鍵值10,到聚集索引中查找10對應的記錄,最
終找到10對應的行row。
③. 最終拿到這一行的數據,直接返回即可。
回表查詢: 這種先到二級索引中查找數據,找到主鍵值,然后再到聚集索引中根據主鍵值,獲取
數據的方式,就稱之為回表查詢。
索引語法
- 創建索引
CREATE [ UNIQUE | FULLTEXT ] INDEX 索引名字 ON 表名 ( 表字段,... ) ; - 查看索引
SHOW INDEX FROM table_name ; - 刪除索引
DROP INDEX 索引名字 ON table_name ;
SQL性能分析
- SQL執行頻率
- MySQL 客戶端連接成功后,通過 show [session|global] status 命令可以提供服務器狀態信
息。通過如下指令,可以查看當前數據庫的INSERT、UPDATE、DELETE、SELECT的訪問頻次:
- MySQL 客戶端連接成功后,通過 show [session|global] status 命令可以提供服務器狀態信
-- session 是查看當前會話 ;
-- global 是查詢全局數據 ;
SHOW GLOBAL STATUS LIKE 'Com_______';
過上述指令,我們可以查看到當前數據庫到底是以查詢為主,還是以增刪改為主,從而為數據
庫優化提供參考依據。 如果是以增刪改為主,我們可以考慮不對其進行索引的優化。 如果是以
查詢為主,那么就要考慮對數據庫的索引進行優化了。
-
慢查詢日志
-
慢查詢日志記錄了所有執行時間超過指定參數(long_query_time,單位:秒,默認10秒)的所有
SQL語句的日志。 -
MySQL的慢查詢日志默認沒有開啟,我們可以查看一下系統變量 slow_query_log。
-
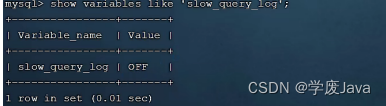
-
如果要開啟慢查詢日志,需要在MySQL的配置文件(/etc/my.cnf)中配置如下信息:
# 開啟MySQL慢日志查詢開關
slow_query_log=1
# 設置慢日志的時間為2秒,SQL語句執行時間超過2秒,就會視為慢查詢,記錄慢查詢日志
long_query_time=2
配置完畢之后,通過以下指令重新啟動MySQL服務器進行測試,查看慢日志文件中記錄的信息
systemctl restart mysqld
- profile詳情
show profiles 能夠在做SQL優化時幫助我們了解時間都耗費到哪里去了。通過have_profiling
參數,能夠看到當前MySQL是否支持profile操作:
SELECT @@have_profiling ;
可以看到,當前MySQL是支持 profile操作的,但是開關是關閉的。可以通過set語句在
session/global級別開啟profiling:
SET profiling = 1;
- explain
EXPLAIN 或者 DESC命令獲取 MySQL 如何執行 SELECT 語句的信息,包括在 SELECT 語句執行
過程中表如何連接和連接的順序。
-- 直接在select語句之前加上關鍵字 explain / desc
EXPLAIN SELECT 字段列表 FROM 表名 WHERE 條件 ;
Explain 執行計劃中各個字段的含義:

索引優化
最左前綴法則
如果索引了多列(聯合索引),要遵守最左前綴法則。最左前綴法則指的是查詢從索引的最左列開始,
并且不跳過索引中的列。如果跳躍某一列,索引將會部分失效(后面的字段索引失效)。
范圍查詢
- 聯合索引中,出現范圍查詢(>,<),范圍查詢右側的列索引失效。
- 當范圍查詢使用>= 或 <= 時,走聯合索引了,但是索引的長度為54,就說明所有的字段都是走索引
的。
字符串不加引號
字符串類型字段使用時,不加引號,索引將失效。
模糊查詢
如果僅僅是尾部模糊匹配,索引不會失效。如果是頭部模糊匹配,索引失效。
or連接條件
用or分割開的條件, 如果or前的條件中的列有索引,而后面的列中沒有索引,那么涉及的索引都不會
被用到。
數據分布影響
如果MySQL評估使用索引比全表更慢,則不使用索引。
覆蓋索引
盡量使用覆蓋索引,減少select *。 那么什么是覆蓋索引呢? 覆蓋索引是指 查詢使用了索引,并
且需要返回的列,在該索引中已經全部能夠找到 。
前綴索引
當字段類型為字符串(varchar,text,longtext等)時,有時候需要索引很長的字符串,這會讓
索引變得很大,查詢時,浪費大量的磁盤IO, 影響查詢效率。此時可以只將字符串的一部分前綴,建
立索引,這樣可以大大節約索引空間,從而提高索引效率。
create index idx_xxxx on 表名(字段(前綴長度)) ;
索引設計原則
- 針對于數據量較大,且查詢比較頻繁的表建立索引。
- 針對于常作為查詢條件(where)、排序(order by)、分組(group by)操作的字段建立索
引。 - 盡量選擇區分度高的列作為索引,盡量建立唯一索引,區分度越高,使用索引的效率越高。
- 如果是字符串類型的字段,字段的長度較長,可以針對于字段的特點,建立前綴索引。
- 盡量使用聯合索引,減少單列索引,查詢時,聯合索引很多時候可以覆蓋索引,節省存儲空間,
避免回表,提高查詢效率。 - 要控制索引的數量,索引并不是多多益善,索引越多,維護索引結構的代價也就越大,會影響增
刪改的效率。 - 如果索引列不能存儲NULL值,請在創建表時使用NOT NULL約束它。當優化器知道每列是否包含
NULL值時,它可以更好地確定哪個索引最有效地用于查詢。






——生成敵方炮彈(rand()和srand()函數應用))




——Centos7安裝DockerDocker Compose)

_Set集合,函數,深入拷貝,淺入拷貝,文件處理)





)