在開始配置前,我們先了解Hadoop的三種運行模式。
Hadoop的三種運行模式
- 獨立(或本地)模式:無需運行任何守護進程,所有程序都在同一個JVM上執行。在獨立模式下測試和調試MapReduce程序很方便,因此該模式在開發階段比較適合。
- **偽分布式模式:**Hadoop守護進程運行在本地機器上,模擬一個小規模的集群。
- **全分布式模式:**Hadoop守護進程運行在一個集群上。
下面我們進入正題,即如何在Windows 7上搭建Hadoop偽分布式環境。
- 安裝JDK,設置環境變量。
首先,在控制面板上查看自己的操作系統是32位還是64位。
然后,檢查自己的電腦上是否已經具備Java環境。步驟如下:
1)Ctrl+R
2)cmd
3)輸入java -version,若正常顯示java版本,證明本機已安裝java環境,跳到步驟2.若顯示“不是內部或外部命令”,則需要安裝JDK,繼續步驟4)
4) 安裝JDK,樓主用的是jdk-8u131-windows-x64.exe,因為不允許重復上傳CSDN資源,所以樓主無法提供給大家,可以自行下載。說明:只需安裝JDK,不需要安裝JRE。
5)配置Java環境變量,配置路徑:計算機(右鍵)–屬性–高級系統設置—高級–環境變量。
在系統變量處新建,變量名:JAVA_HOME;變量值:你安裝JDK的位置,樓主的是D:\Tools\jdk
修改path:在原有的那串變量值后增加%JAVA_HOME%\bin;…
6)測試Java環境
在cmd窗口:
測試Java環境:
echo %JAVA_HOME%
echo %path%
path
java -version
javac -version - 下載Hadoop 2.7.7,這個樓主傳了資源,誠信賺分,哈哈(https://download.csdn.net/download/u013159040/10620584)
下載,解壓到某個文件夾,如D:\Tools\Hadoop - 下載window util for hadoop。為了配合hadoop 2.7.7,樓主也上傳了資源(https://download.csdn.net/download/u013159040/10620589),下載后解壓到hadoop2.7.7的bin目錄下,直接覆蓋該目錄下的所有內容。請注意此util與具體的hadoop版本是有關的,如果選用不同的hadoop版本,需要找到正確的util。
- 添加Hadoop環境變量,參考Java的,新建HADOOP_HOME 變量名同樣是自己存放hadoop的位置,如D:\Tools\Hadoop\hadoop-2.7.7, 并添加path路徑:%HADOOP_HOME%\bin
創建nodename和datanode目錄,用來保存數據,如:
d:\tools\hadoop\data\namenode
d:\tools\hadoop\data\datanode在D:\Tools\Hadoop\hadoop-2.7.7\etc\hadoop里修改4個配置文件:core-site.xml, hdfs-site.xml, mapred-site.xml, yarn-site.xml
<configuration><property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value></property>
</configuration>hdfs-site.xml(不要直接復制樓主的,要看看自己的namenode和datanode存放的位置是否和樓主一致,不一致的要修改):
<configuration><property><name>dfs.replication</name><value>1</value></property><property><name>dfs.namenode.name.dir</name><value>/D:/Tools/data/namenode</value></property><property><name>dfs.datanode.data.dir</name><value>/D:/Tools/data/datanode</value></property>
</configuration>mapred-site.xml:
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property>
</configuration>yarn-site.xml:
<configuration><!-- Site specific YARN configuration properties --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name><value>org.apache.hadoop.mapred.ShuffleHandler</value></property><property><name>yarn.scheduler.minimum-allocation-mb</name><value>1024</value></property><property><name>yarn.nodemanager.resource.memory-mb</name><value>4096</value></property><property><name>yarn.nodemanager.resource.cpu-vcores</name><value>2</value></property>
</configuration>7.上面步驟完成設置后,就可以試著運行Hadoop了。
Hadoop 啟動命令start -all.cmd
Hadoop 結束命令stop -all.cmd
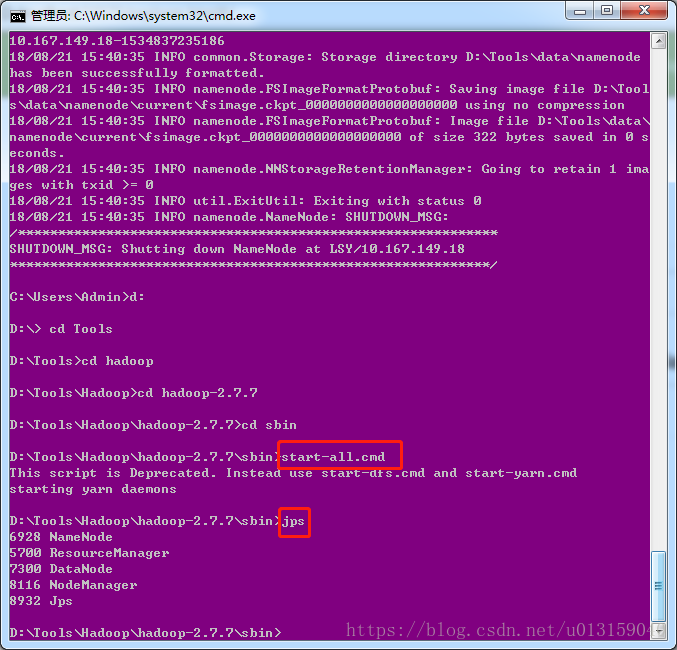
進入到自己的hadoop sbin目錄(一直cd就行了),啟動start-all.cmd,再jps查看java進程,如下圖
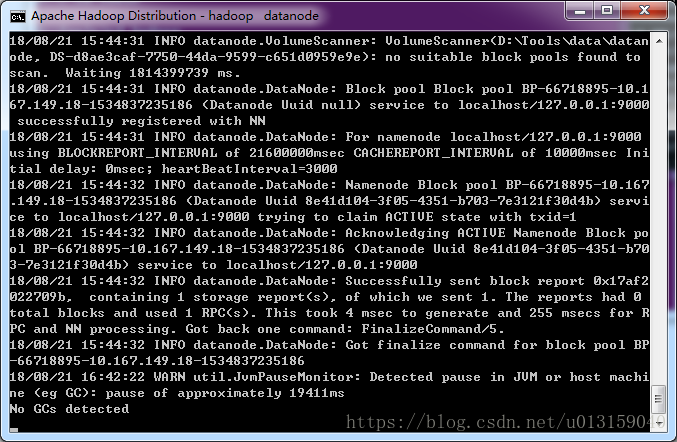
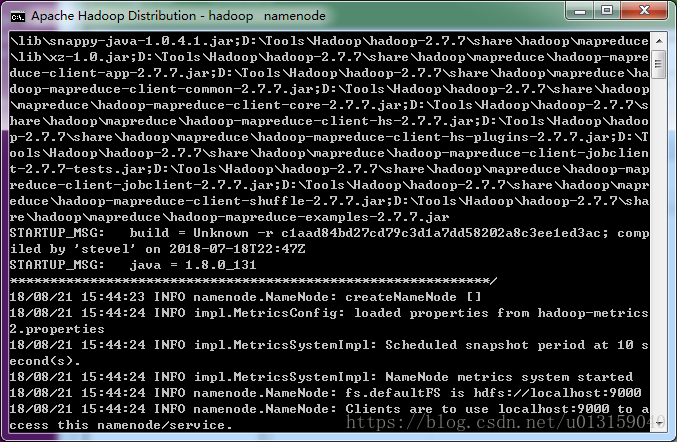
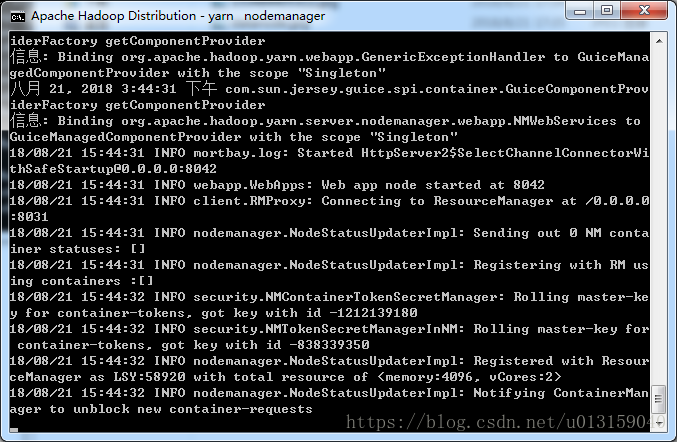
同時,會跳出4個窗口
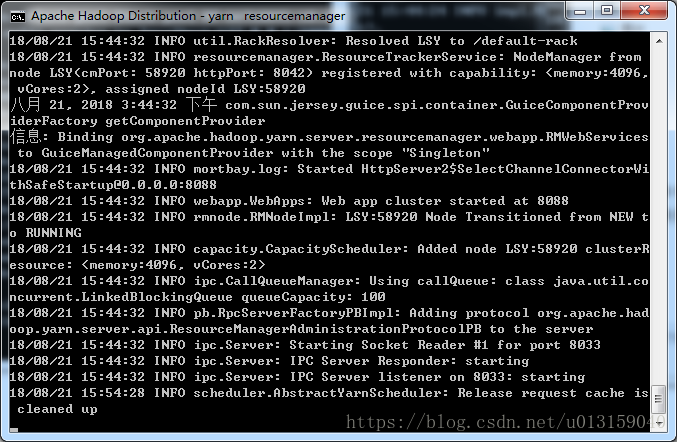
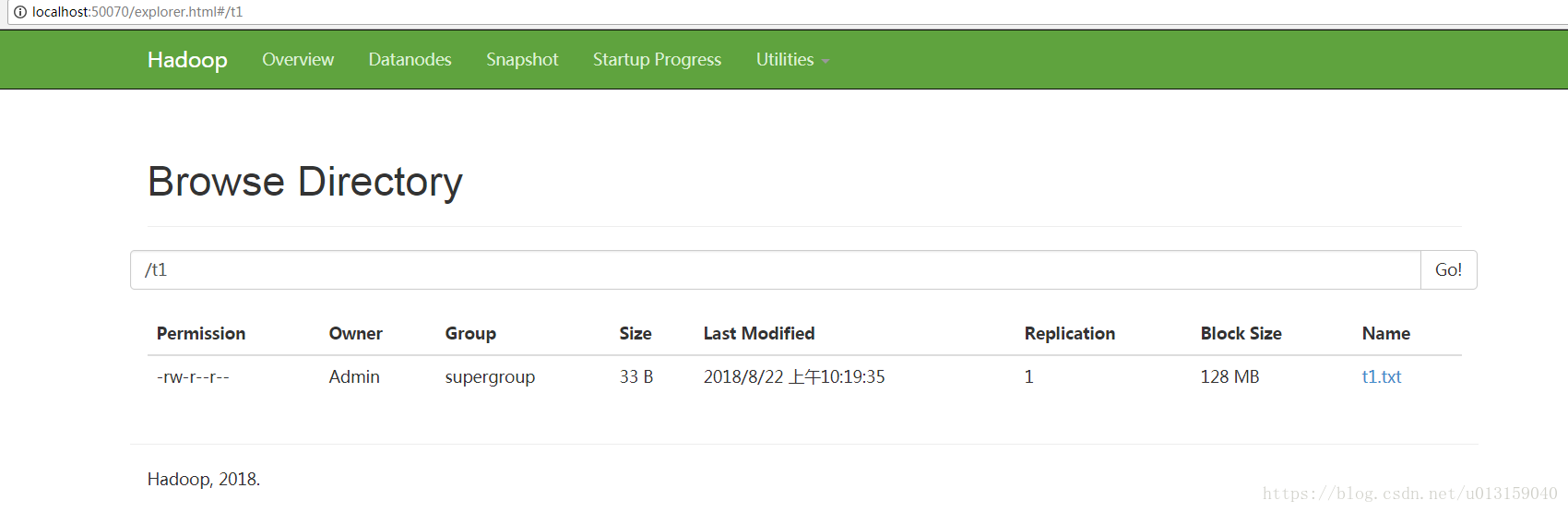
web方式查看文件系統:http://localhost:50070/
查看mapreduce job:http://localhost:8088
由NameNode(守護進程)服務提供
下面可以測試Hadoop自帶的Wordcount
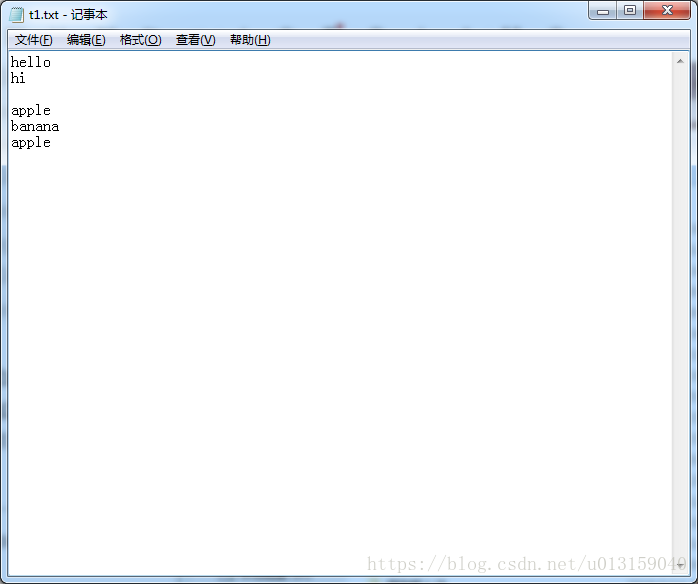
- 在d盤新建一個txt文件t1.txt
- 把t1上傳到HDFS: hadoop fs -put d:\t1.txt /t1/t1.txt
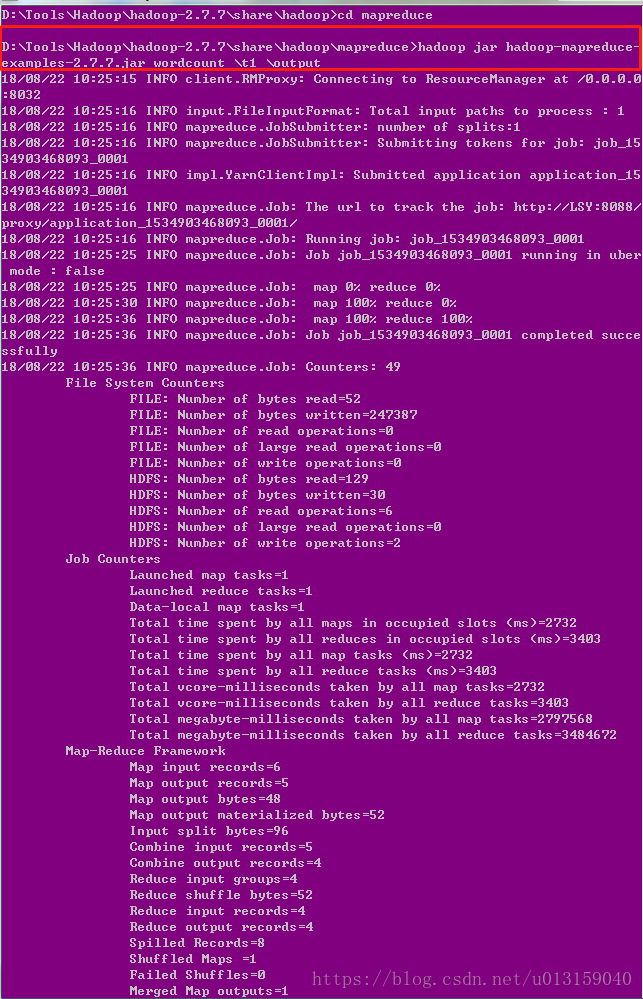
- cd進到mapreduce,然后可以開始運行wordcount了:
hadoop jar /D:\Application\hadoop-2.7.7\share\hadoop\mapreduce\hadoop-mapreduce-examples-2.7.7.jar wordcount \t1 \output
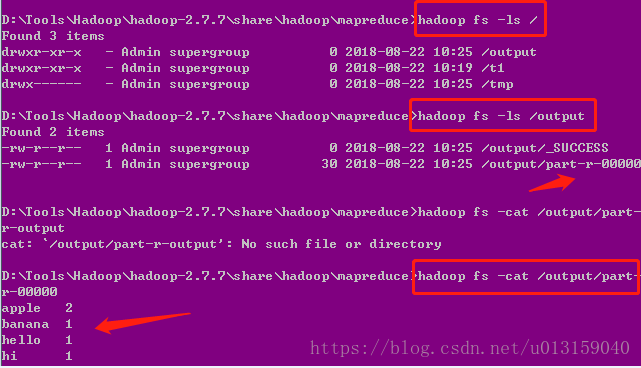
- 然后我們可以看到詞頻統計結果:
網頁上查看的如下:
可以下載分布式文件系統上的這個t1.txt文件。
——————————————–歡迎一起學習探討————————————————














-第11篇)




