一、對Kafka的認識
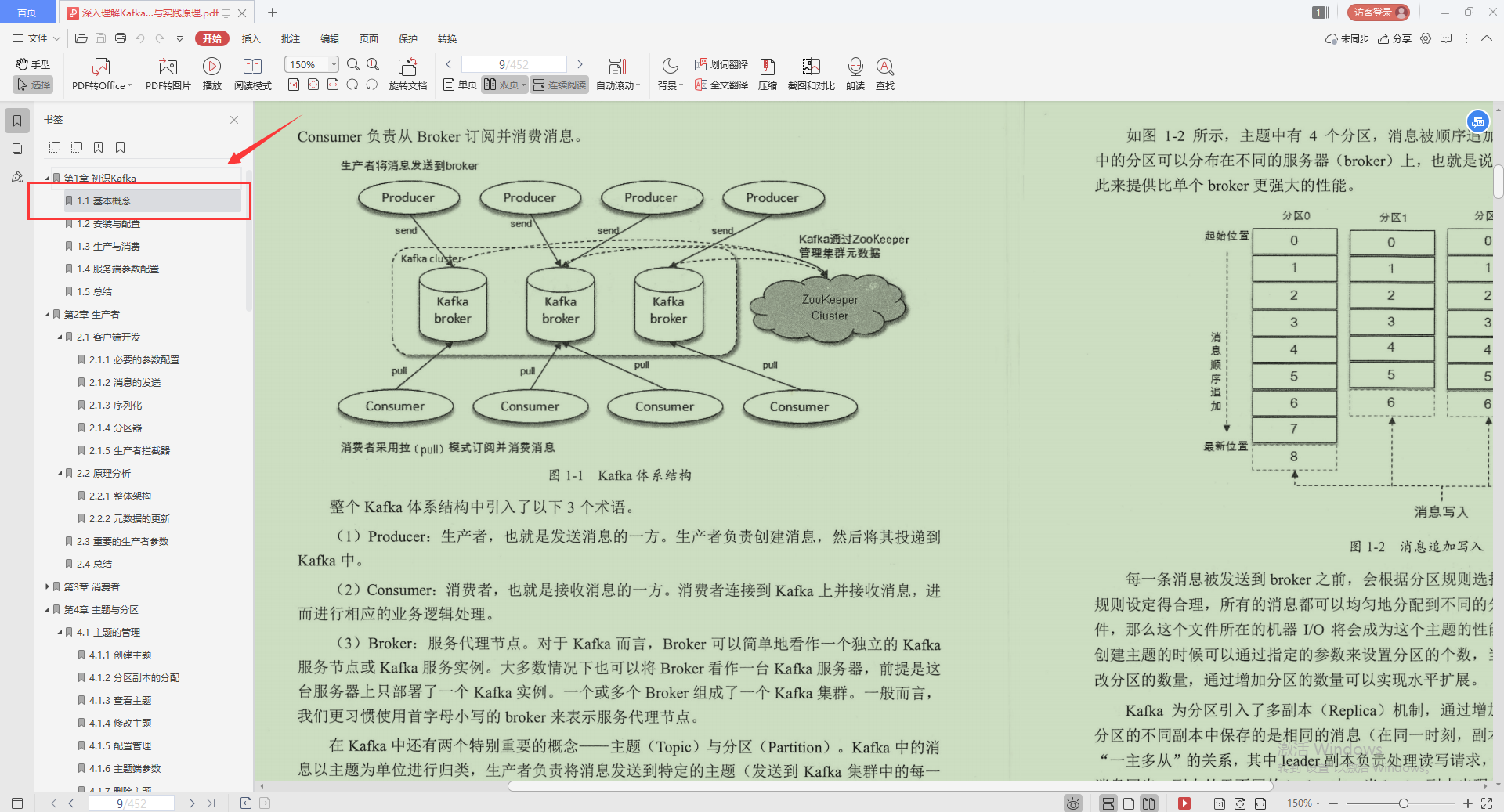
1.Kafka的基本概念
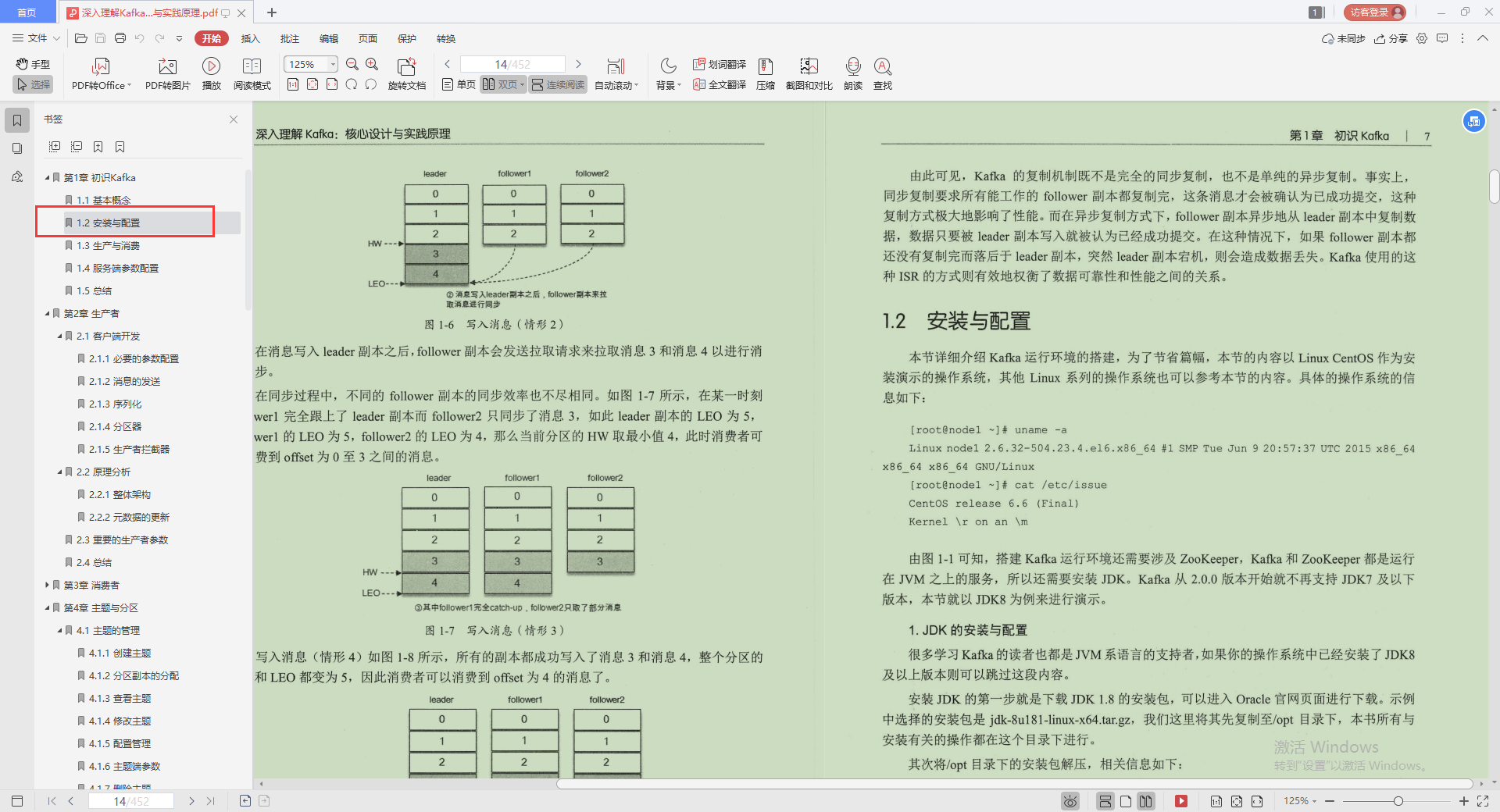
2.安裝與配置
3.生產與消費
4.服務端參數配置
二、生產者
1.客戶端開發
- 必要的參數配置
- 消息的發送
- 序列化
- 分區器
- 生產者攔截器
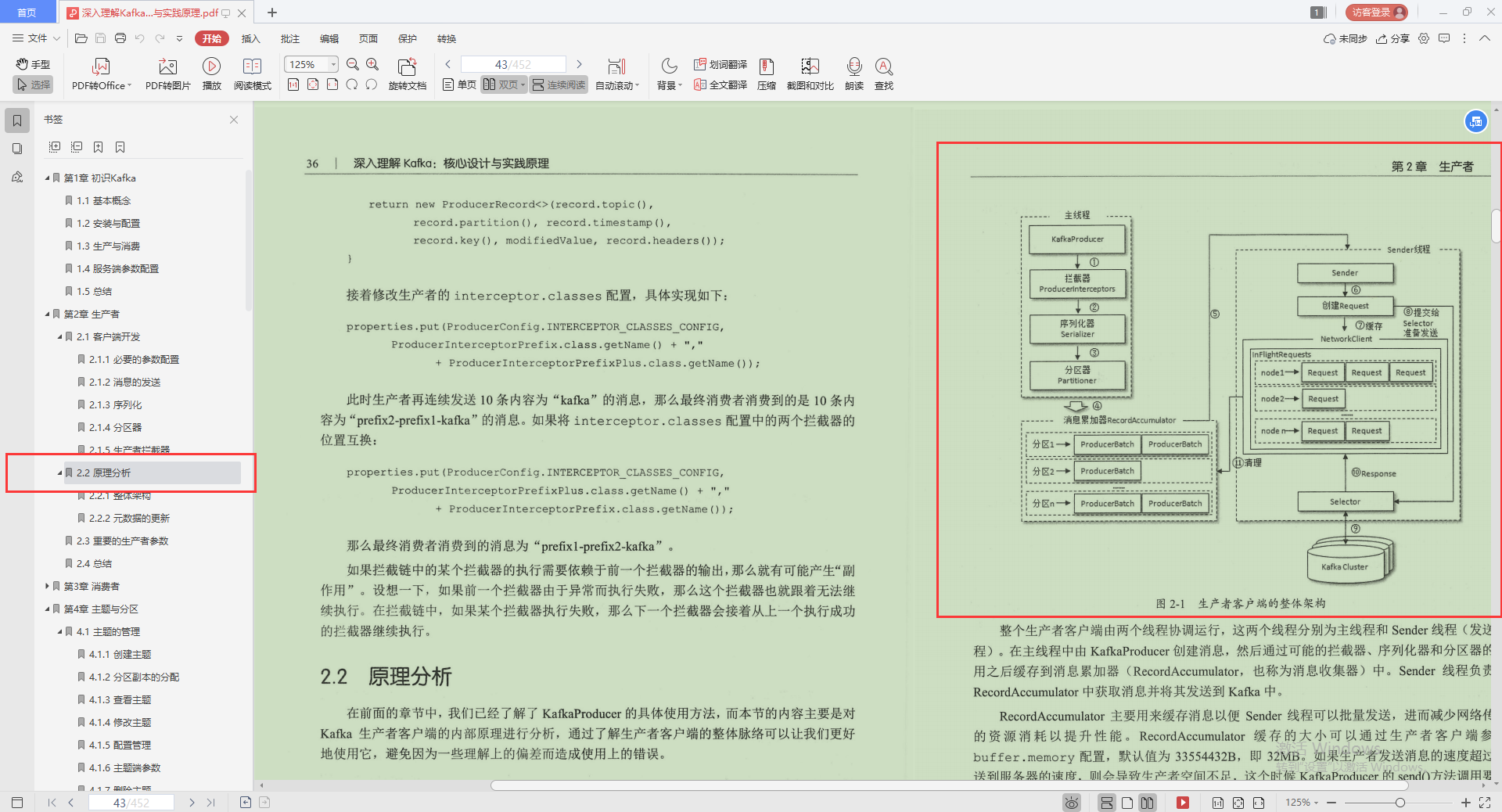
2.原理分析
- 整體架構
- 元數據的更新
3.重要的生產者參數
三、消費者
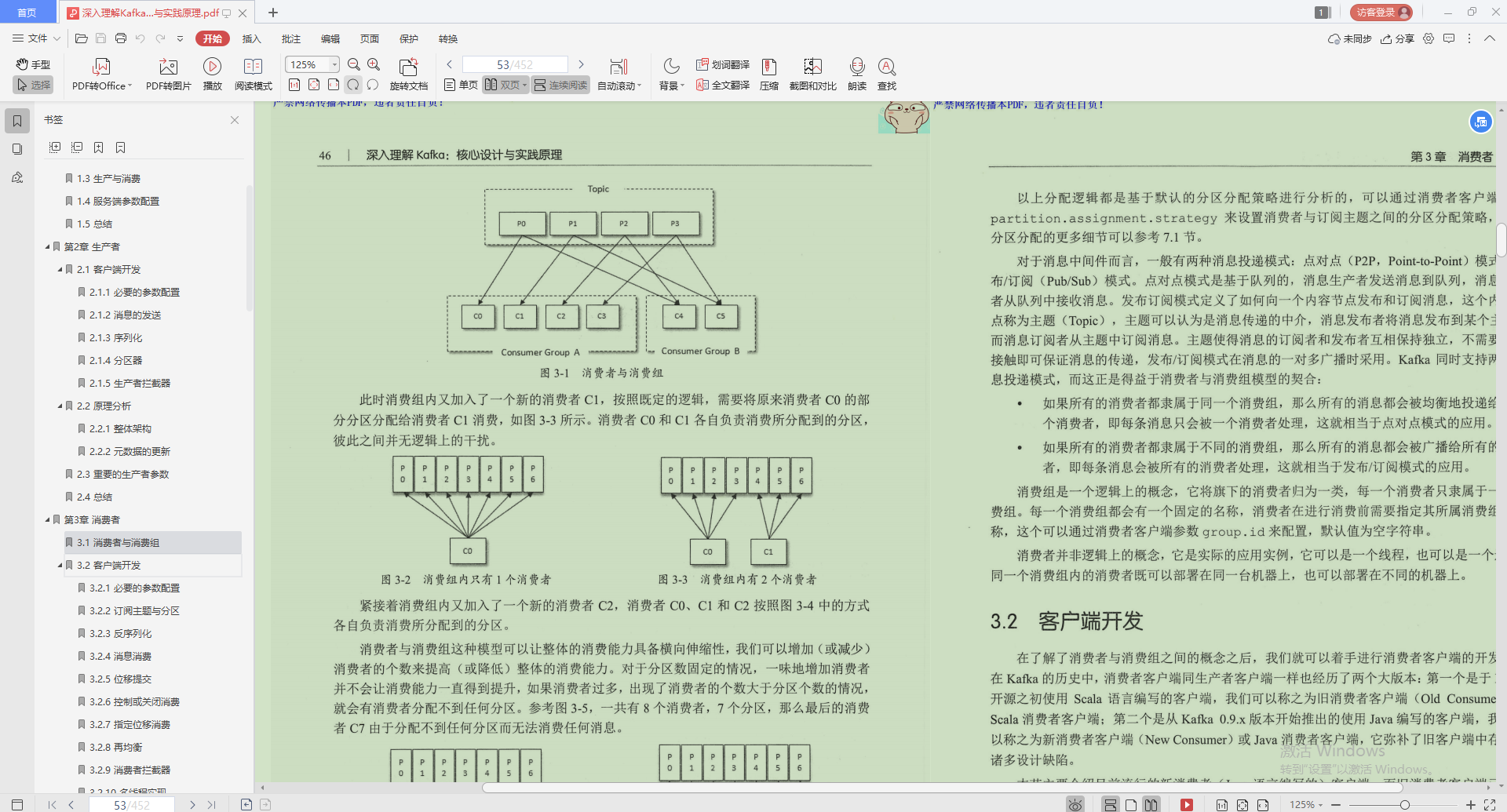
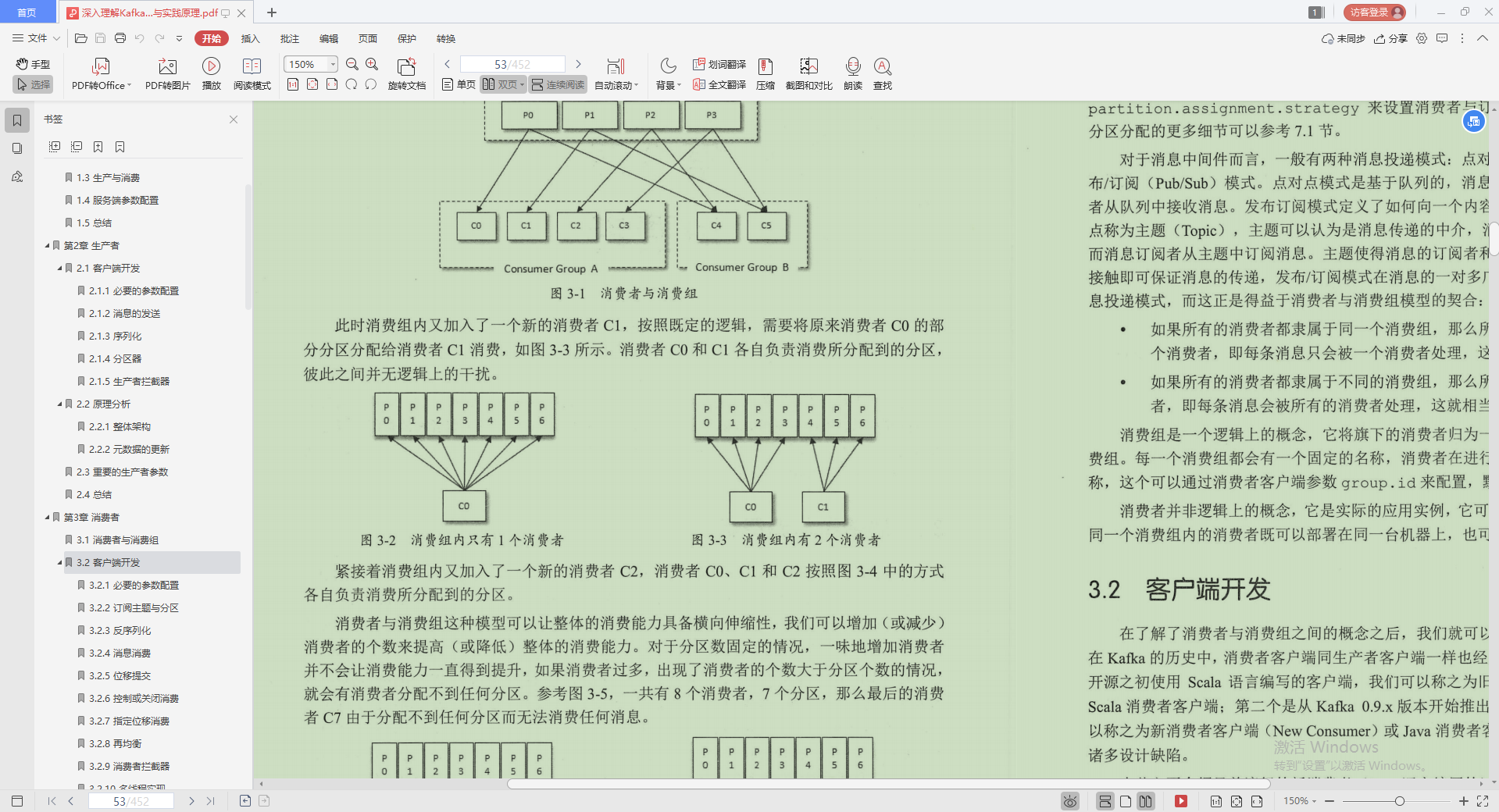
1.消費者與消費組
2.客戶端開發
- 必要的參數配置
- 訂閱主題與分區
- 反序列化
- 消息消費
- 位移提交
- 控制或關閉消費
- 指定位移消費
- 再均衡
- 消費者攔截器
- 多線程實現
- 重要的消費者參數
四、主題與分區
1.主題的管理
- 創建主題
- 分區副本的分配
- 查看主題
- 修改主題
- 配置管理
- 主題端參數
- 刪除主題
2.初識KafkaAdminCilent
- 基本使用
- 主題合法性驗證
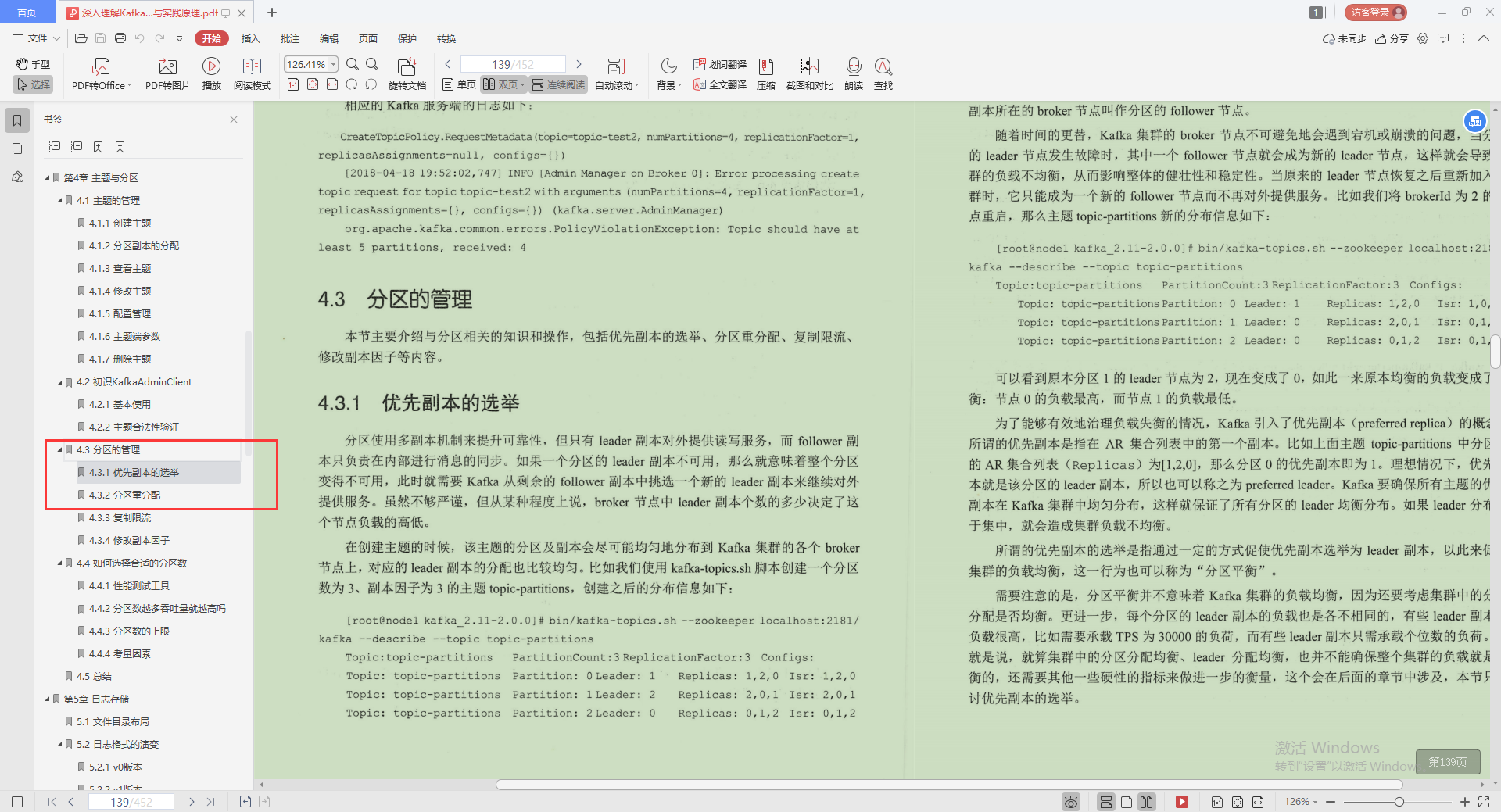
3.分區的管理
- 優先副本的選舉
- 分區重分配
- 復制限流
- 修改副本因子
4.如何選擇合適的分區數
- 性能測試工具
- 分區數越多吞吐量就越高嗎
- 分區數的上限
- 考量因素
五、日志存儲
1.文件目錄布局

2.日志格式的演變
- v0版本
- v1版本
- 消息壓縮
- 變長字段
- v2版本
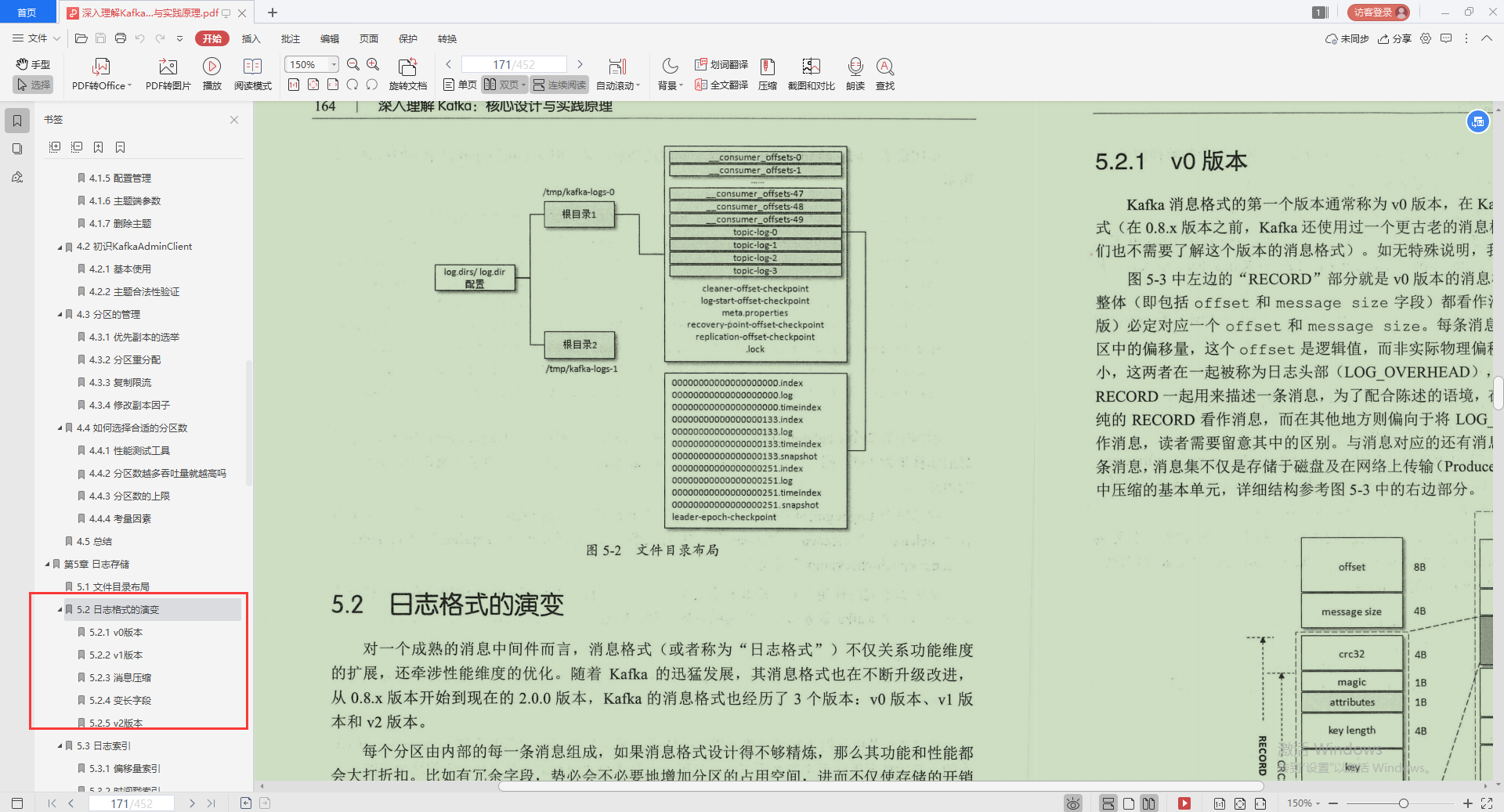
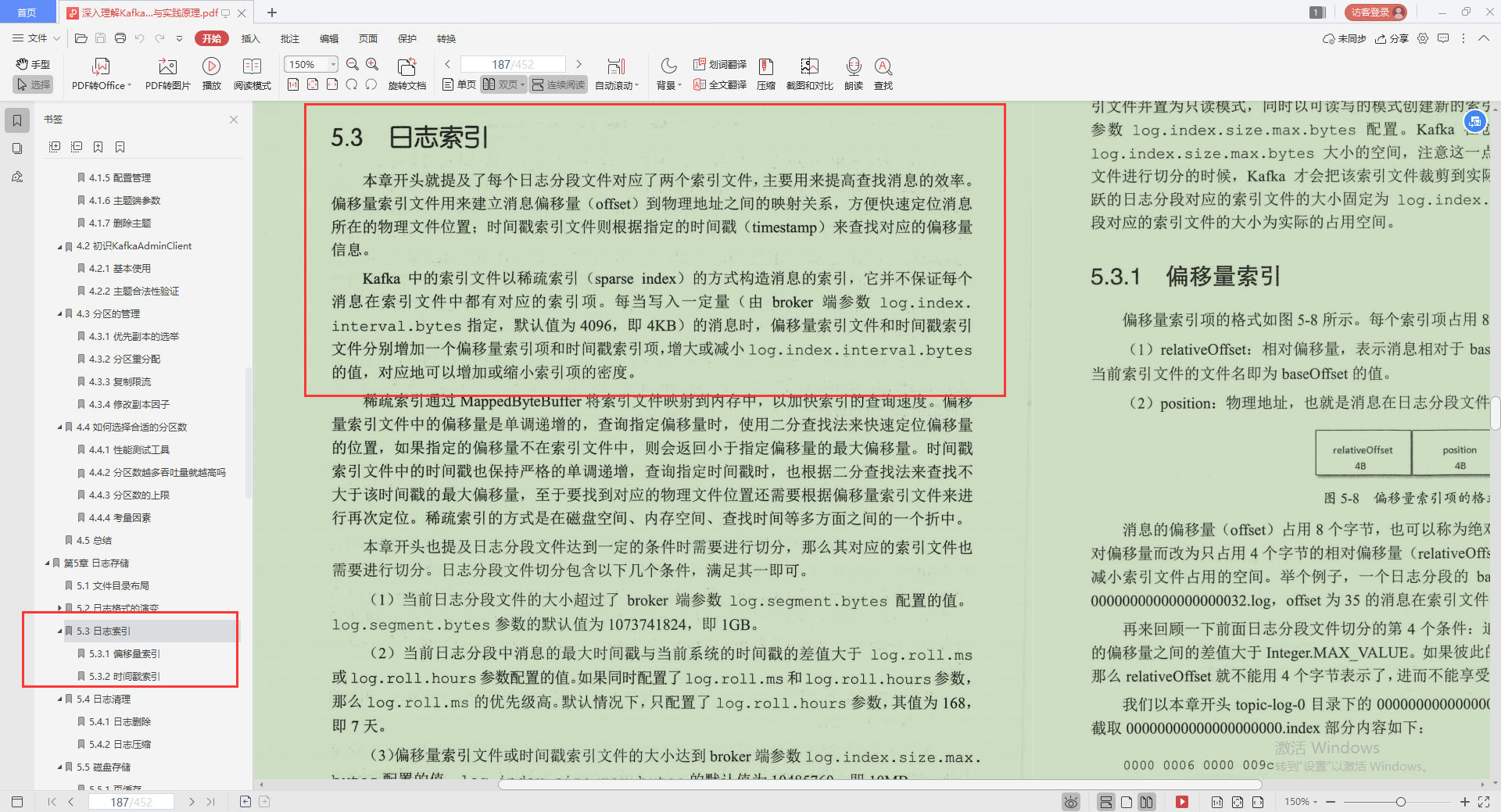
3.日志索引
- 偏移量索引
- 時間戳索引
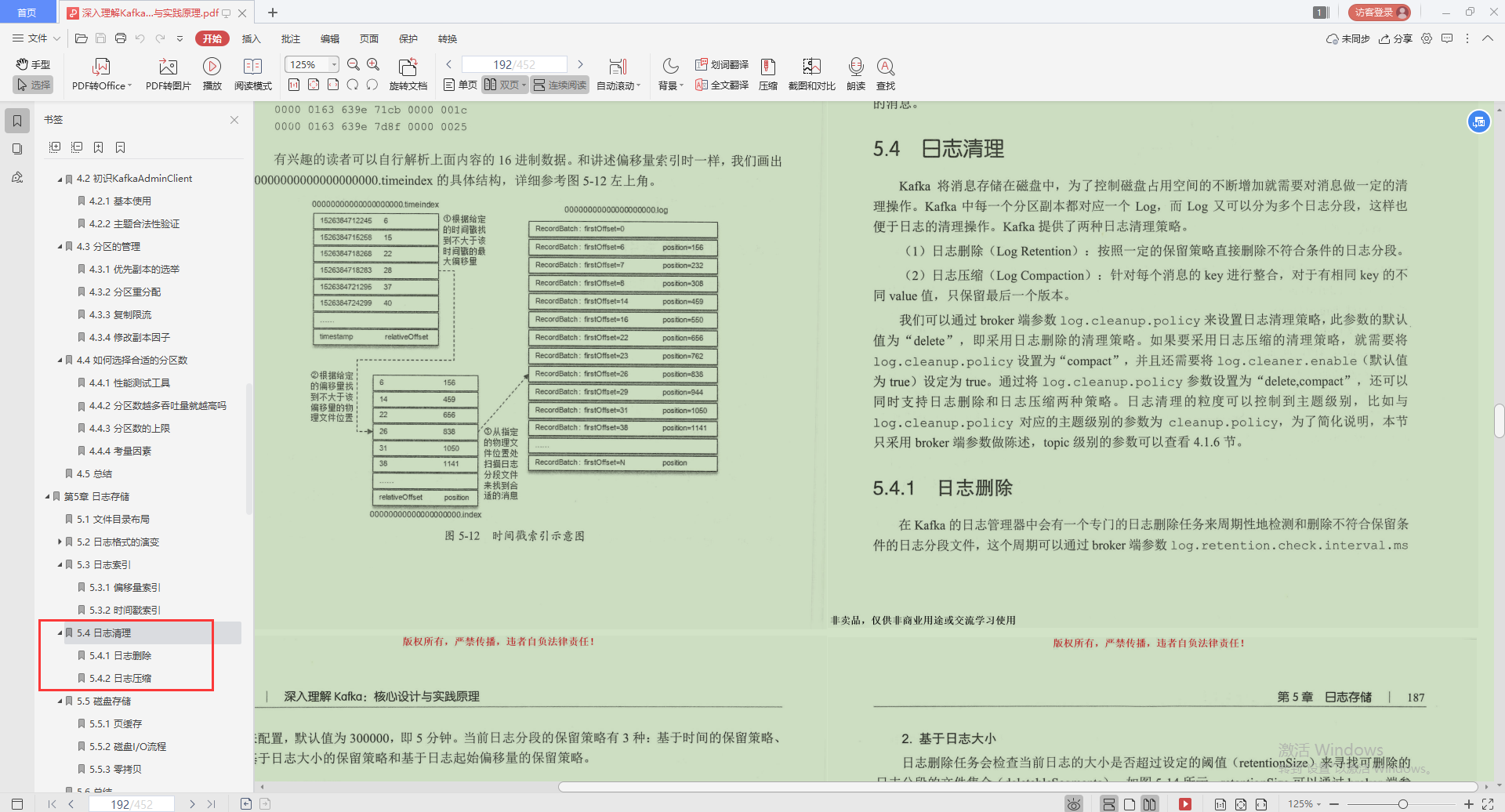
4.日志清理
- 日志刪除
- 日志壓縮
5.磁盤存儲
- 頁緩存
- 磁盤I/O流程
- 零拷貝
六、深入服務端
1.協議設計
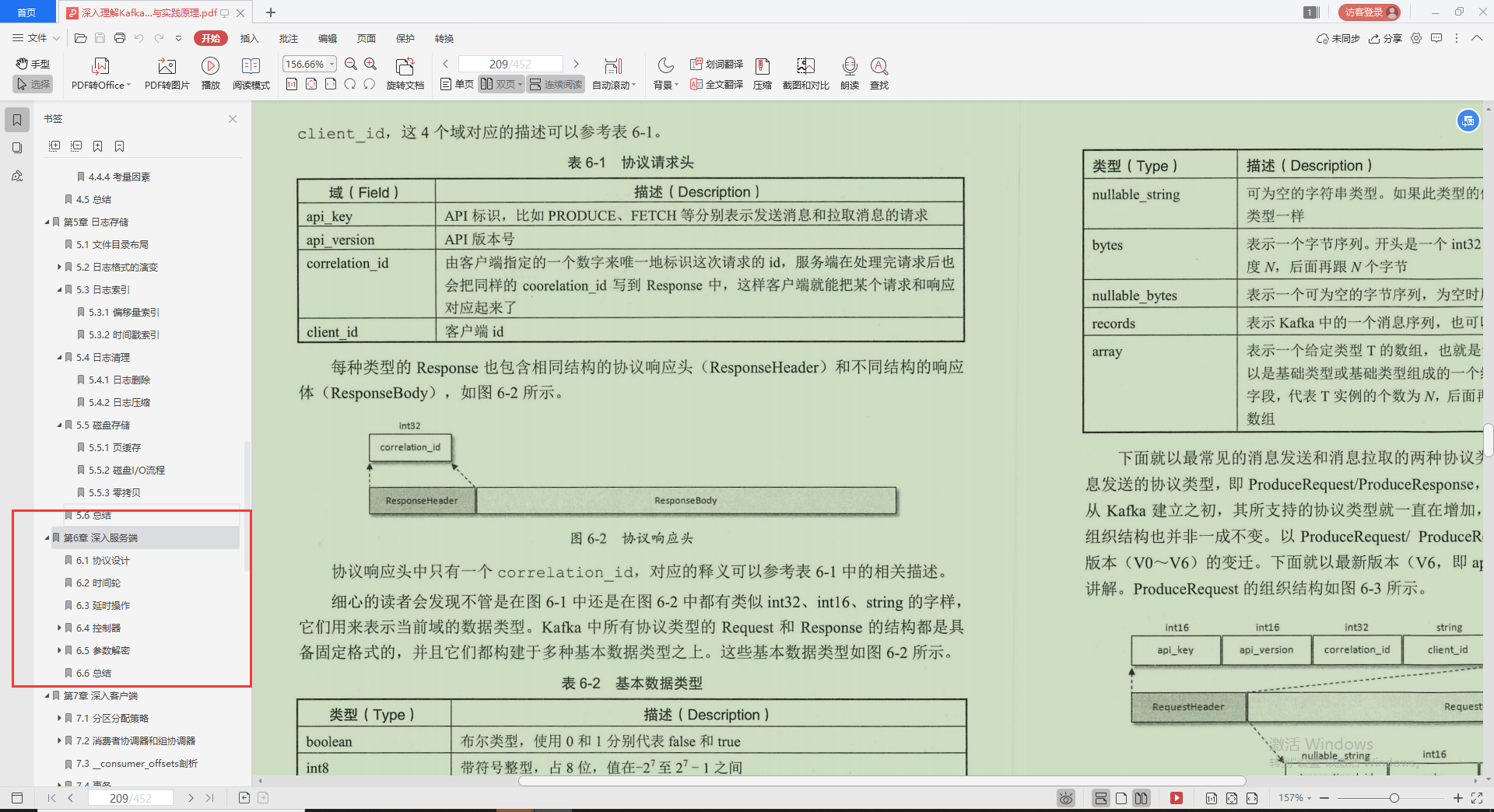
2.時間輪
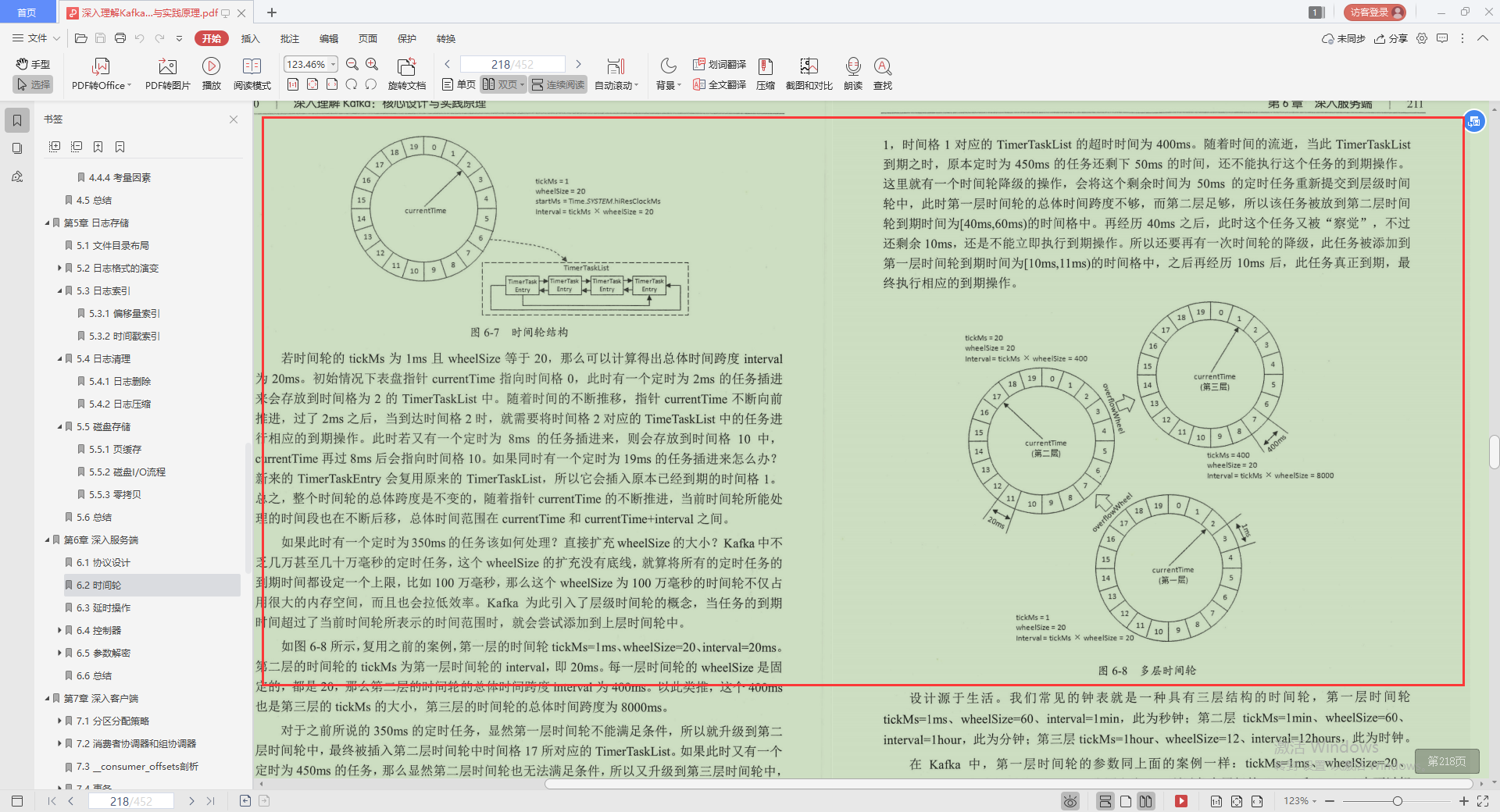
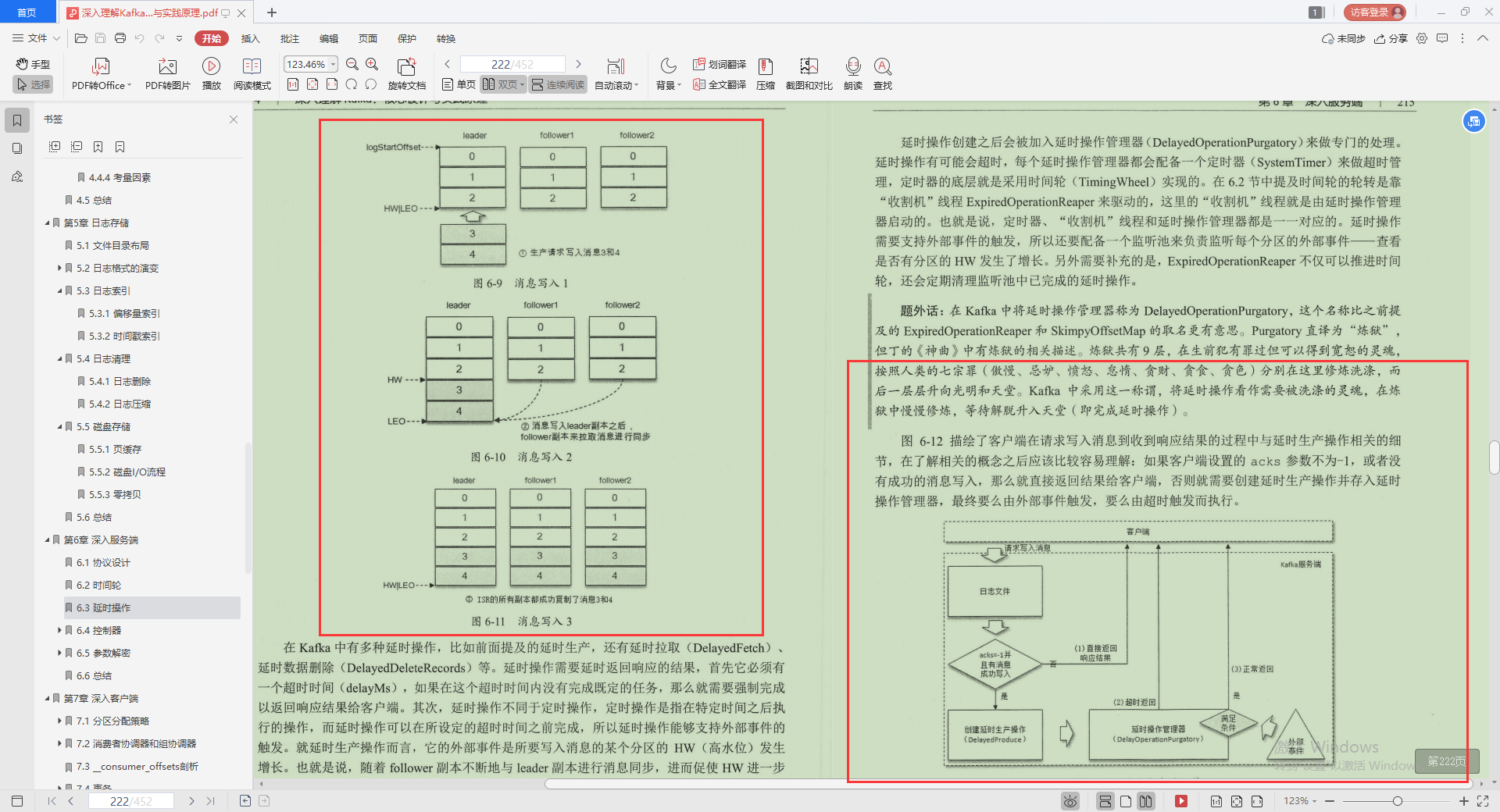
3.延時操作
4.控制器
5.參數解密
七、深入客戶端
1.分區分配策略
2.消費者協調器和組協調器

3._consumer_offsets剖析
4.事務
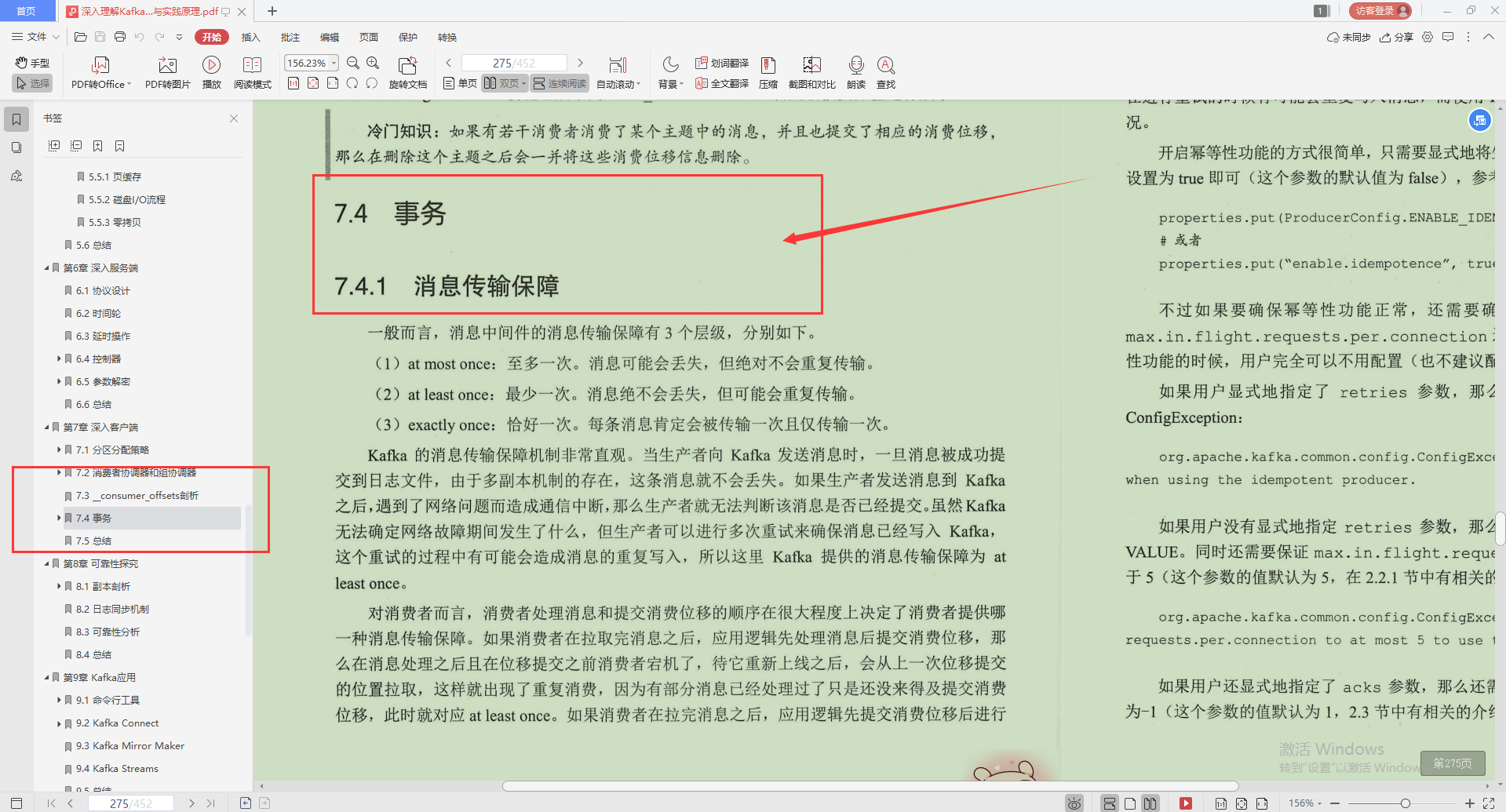
八、可靠性探究
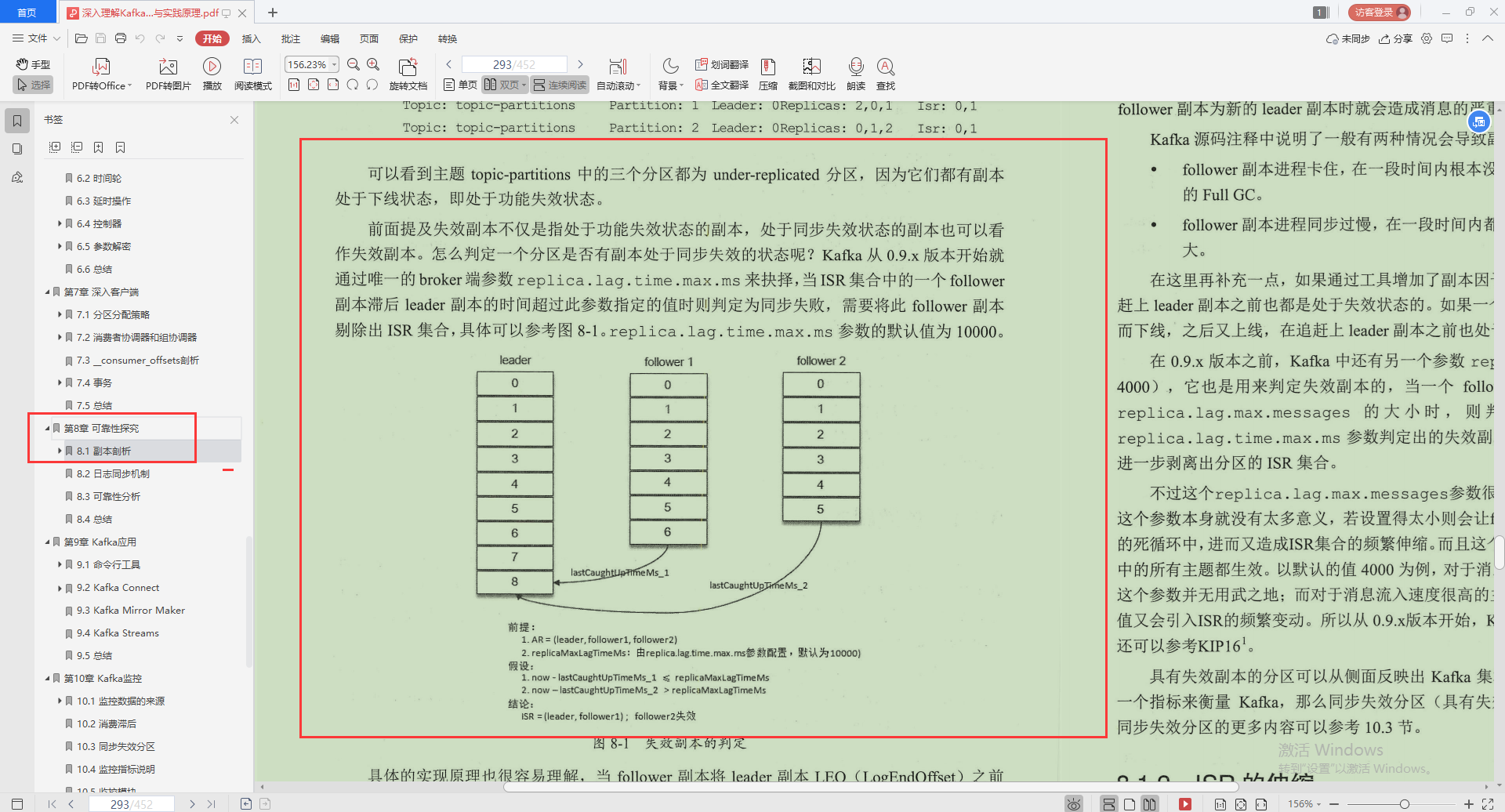
1.副本剖析
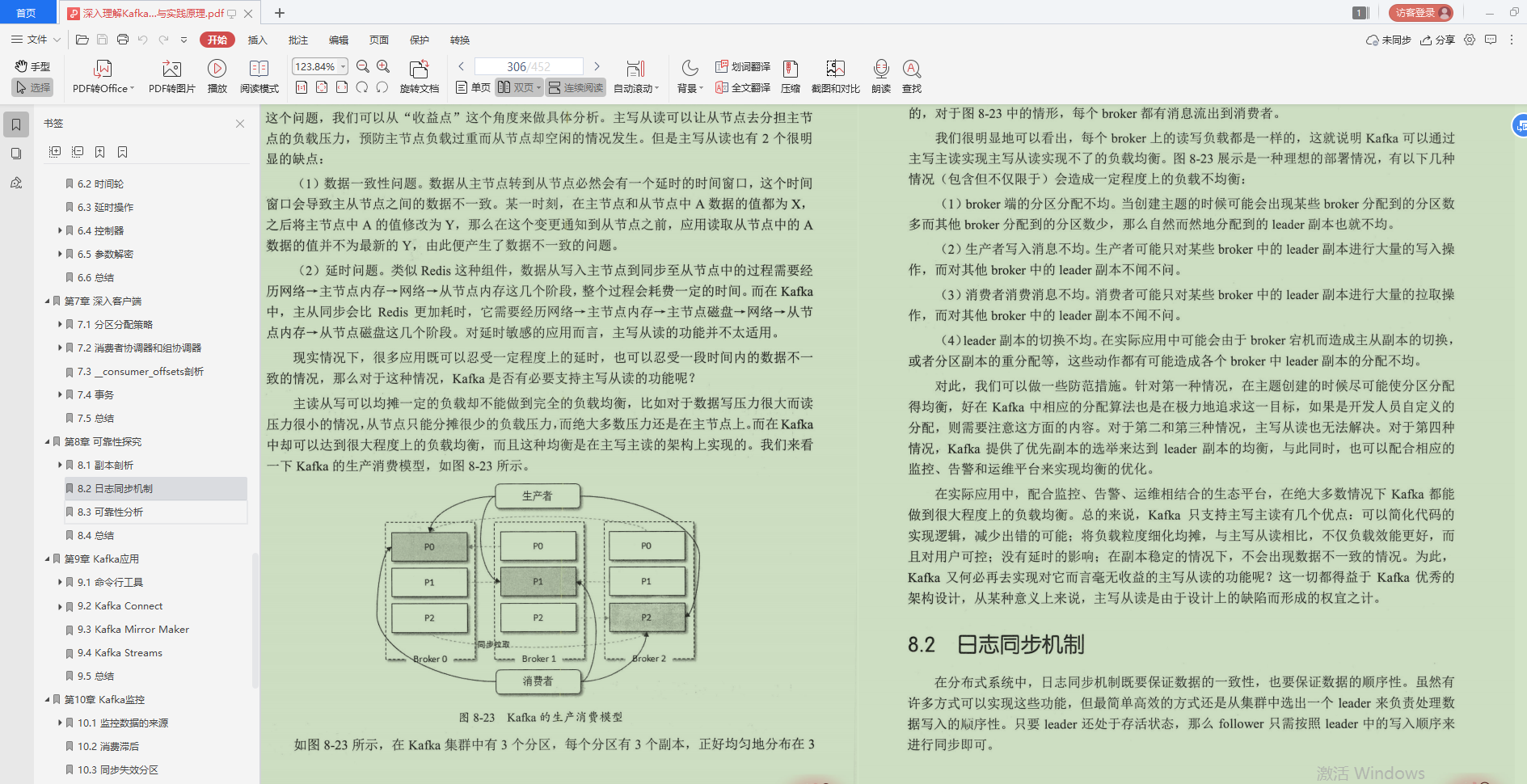
2.日志同步機制
3.可靠性分析

九、Kafka應用
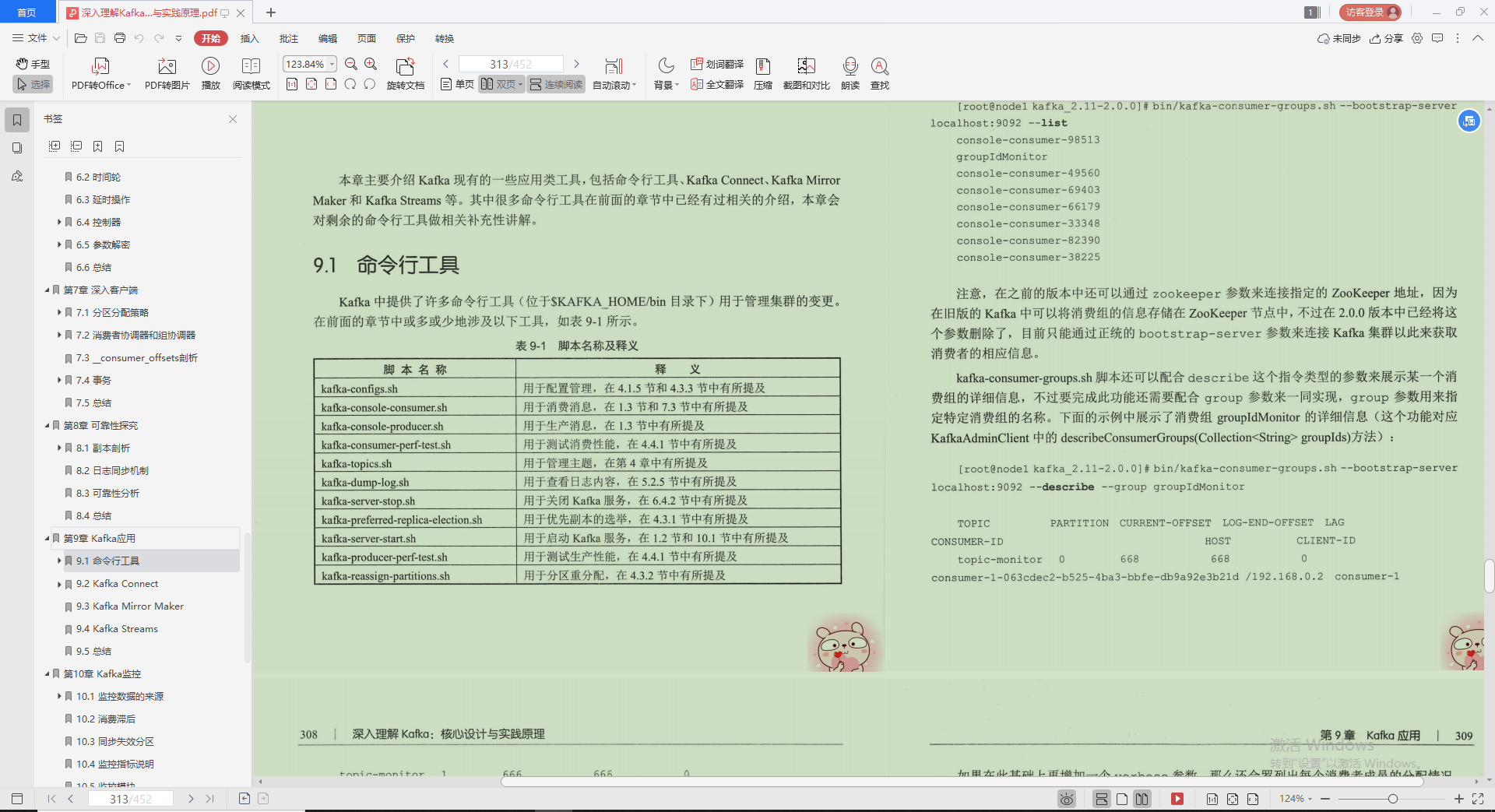
1.命令行工具
2.Kafka Connect
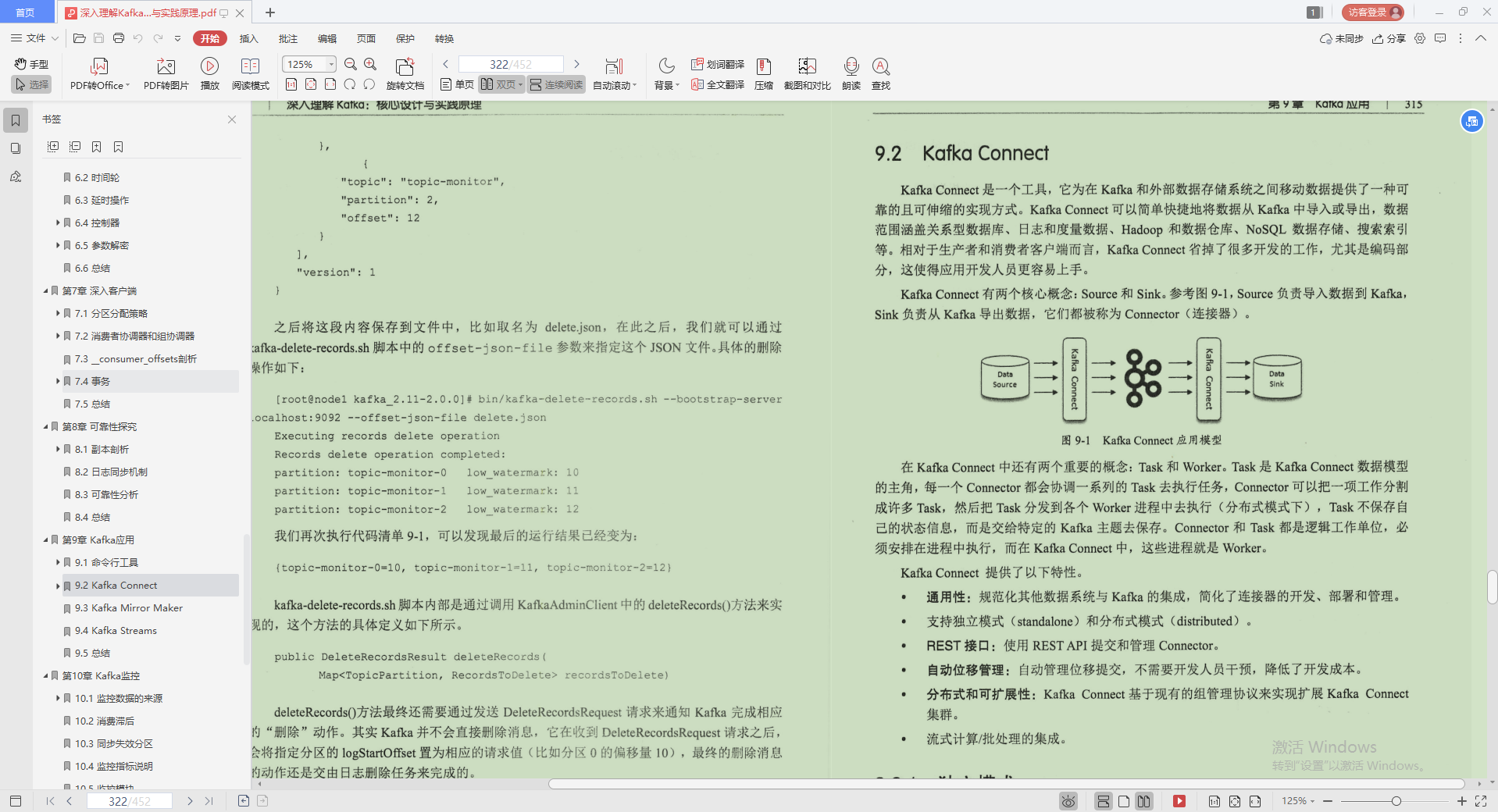
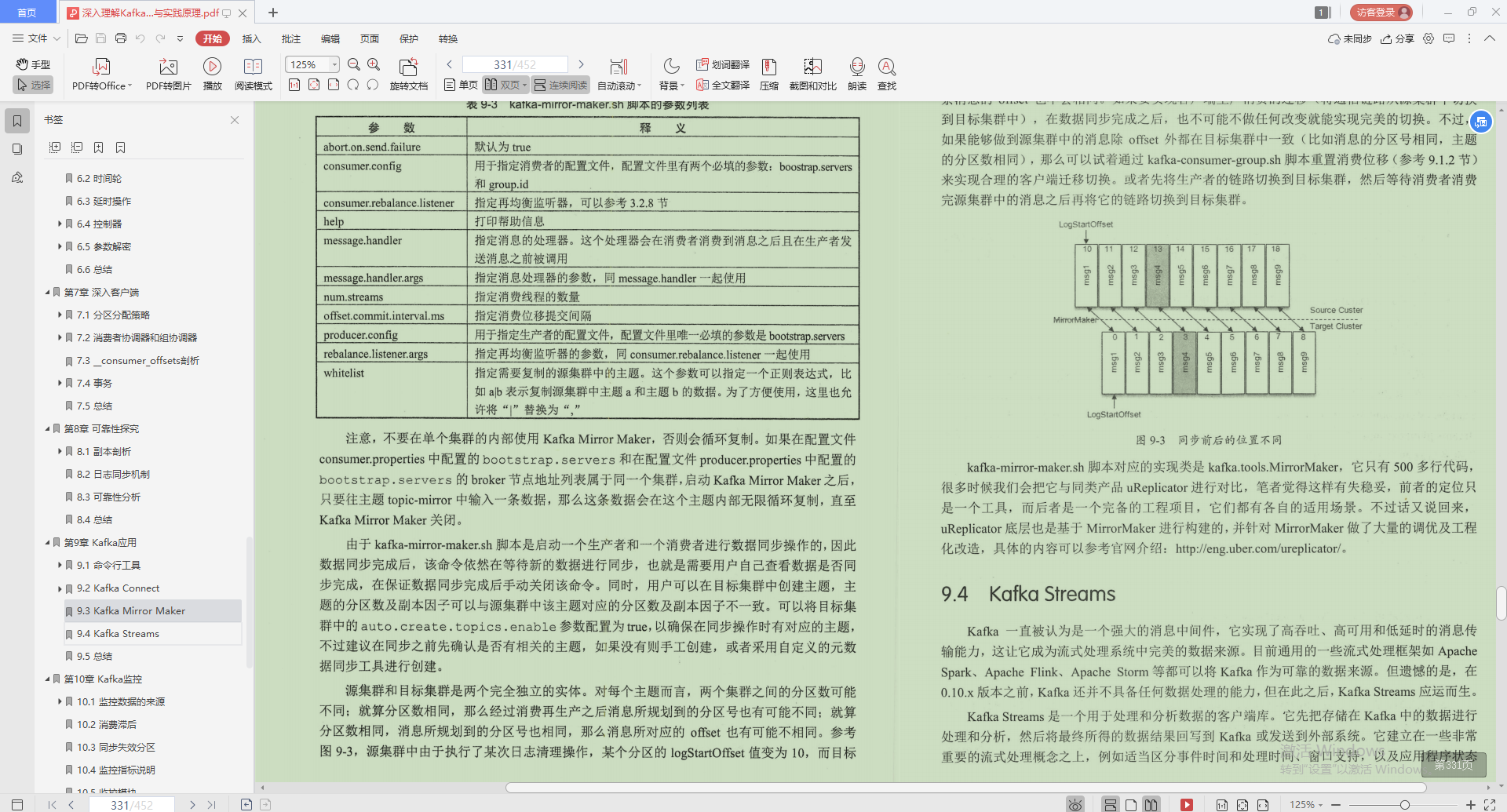
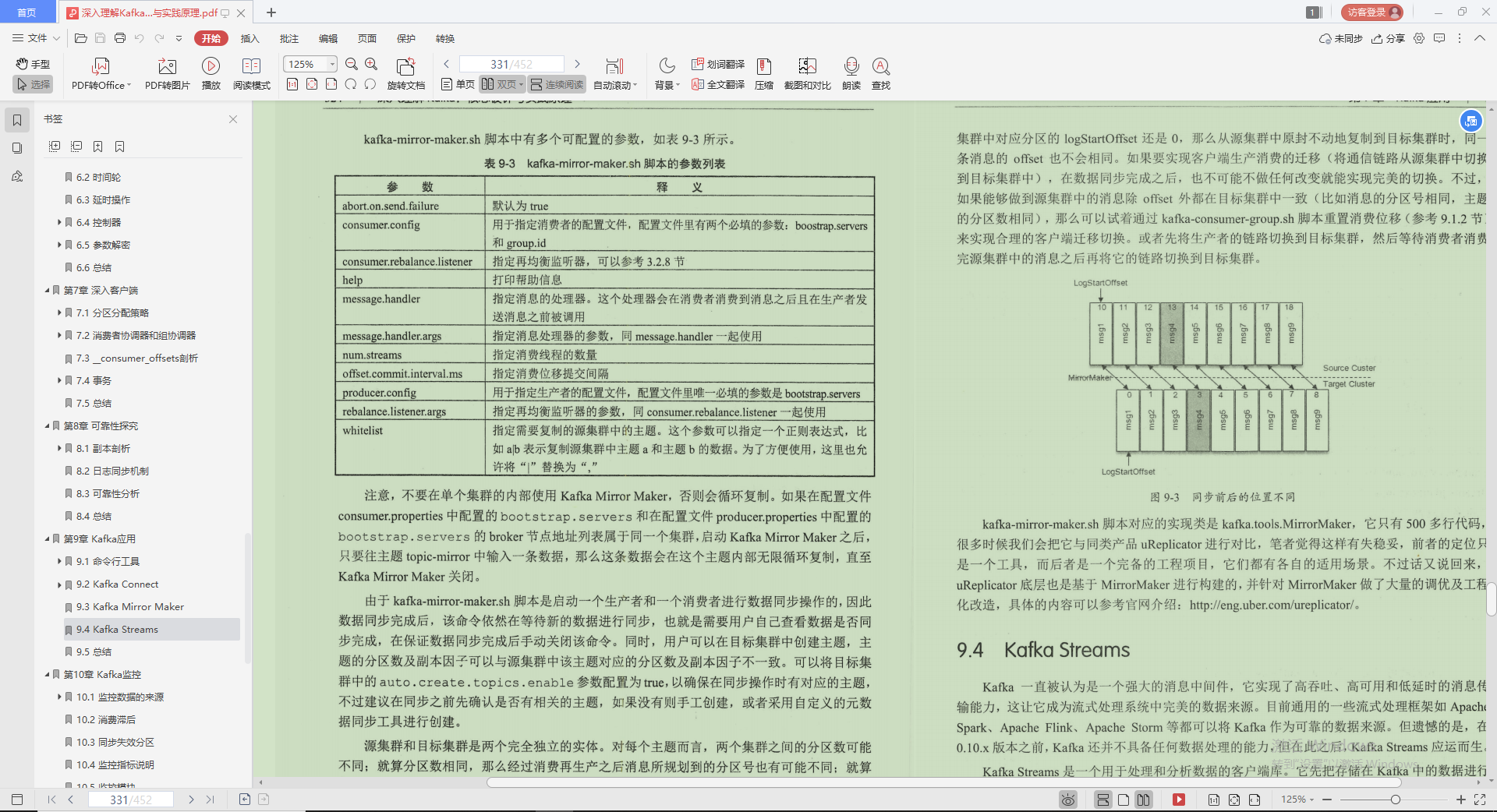
3.Kafka Mirror Maker
4.Kafka Streams
十、Kafka監控
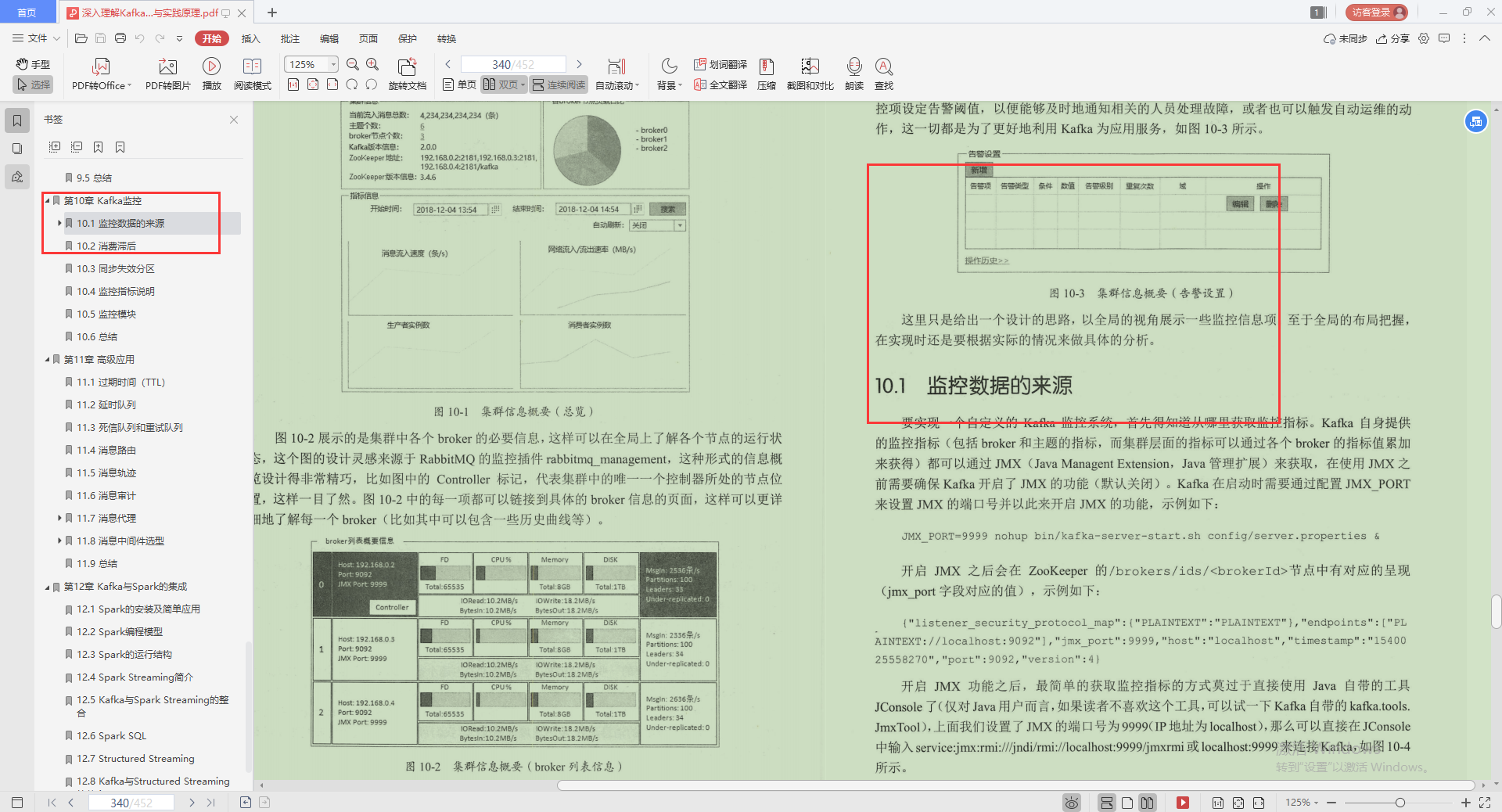
1.監控數據的來源
2.消費滯后
3.同步失效分區
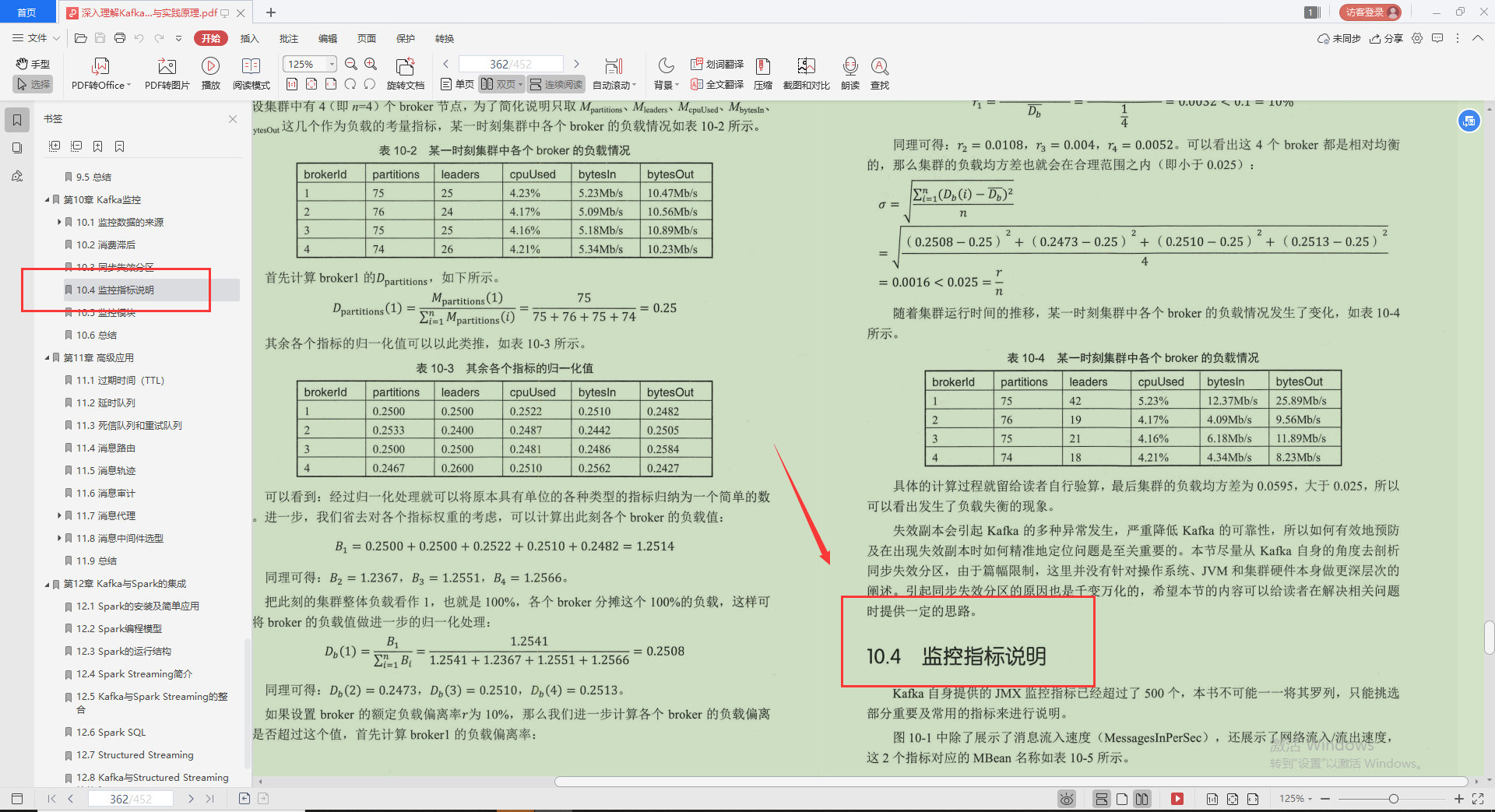
4.監控指標說明
5.監控模塊

十一、高級應用
1.過期時間(TTL)
2.延時隊列
3.死信隊列和重試隊列

4.消息路由
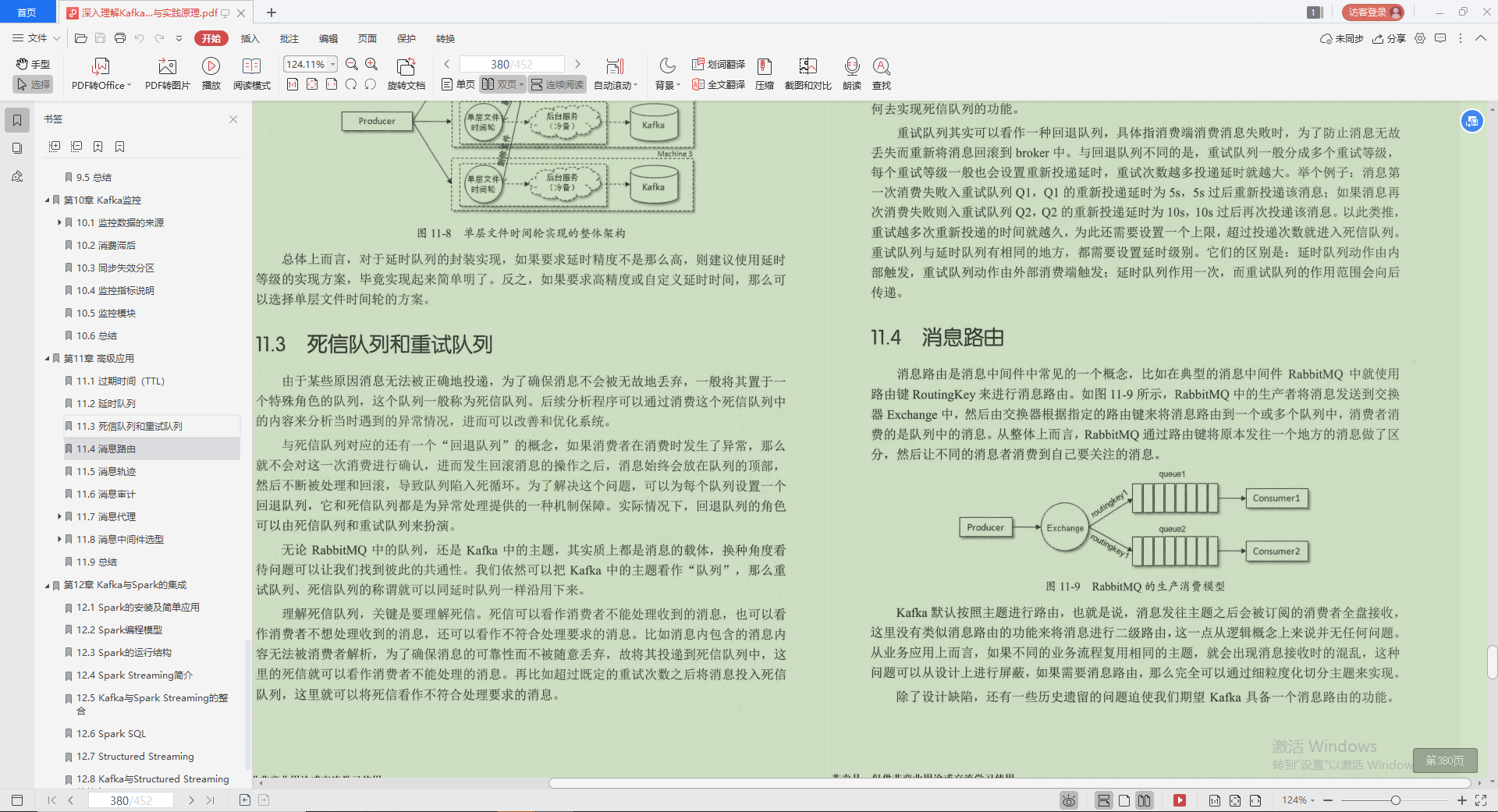
5.消息軌跡
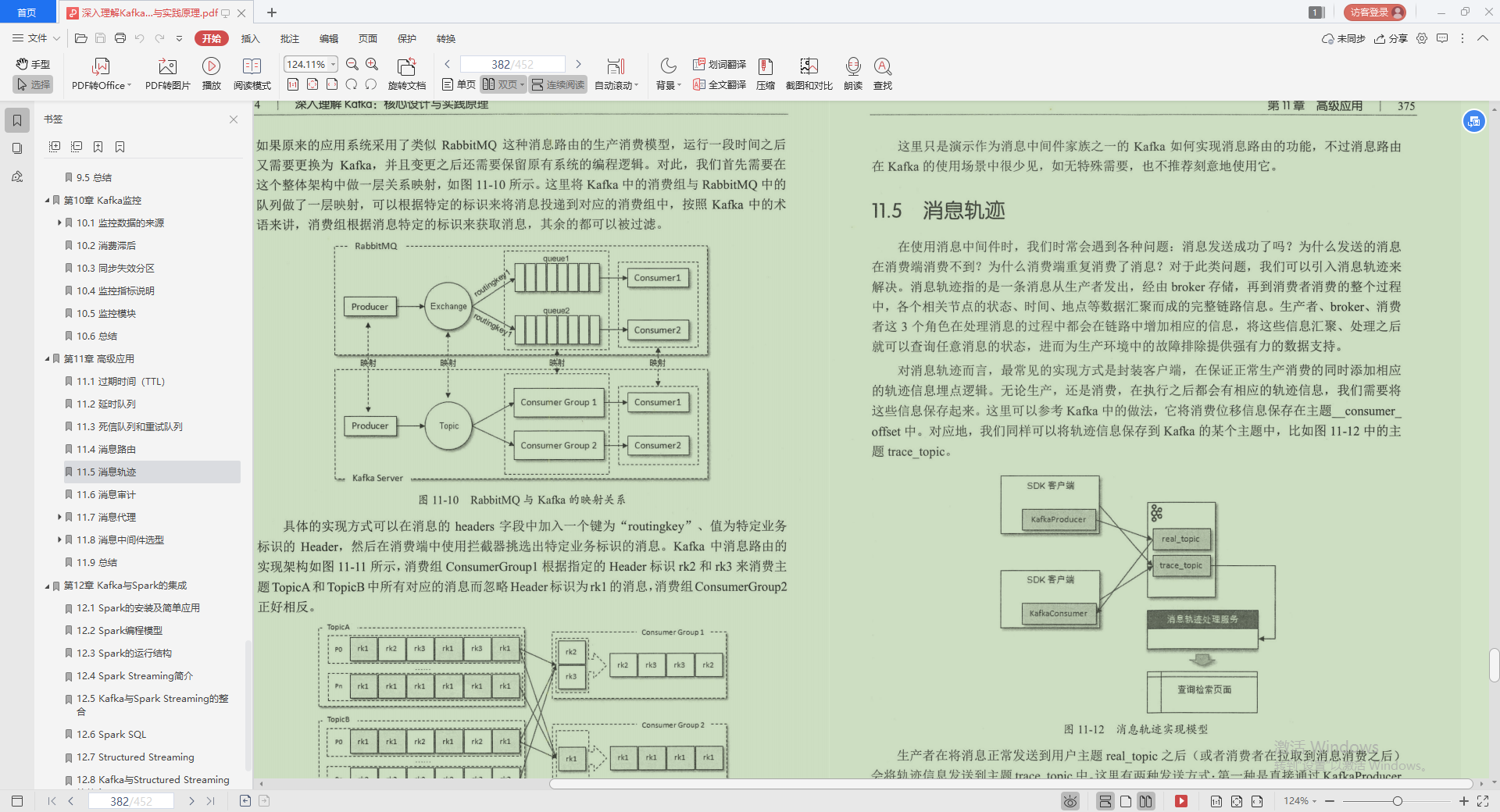
6.消息審計
7.消息代理
8.消息中間件選型
十二、Kafka與Spark的集成
1.Spark的安裝及簡單應用
2.Spark編程模型
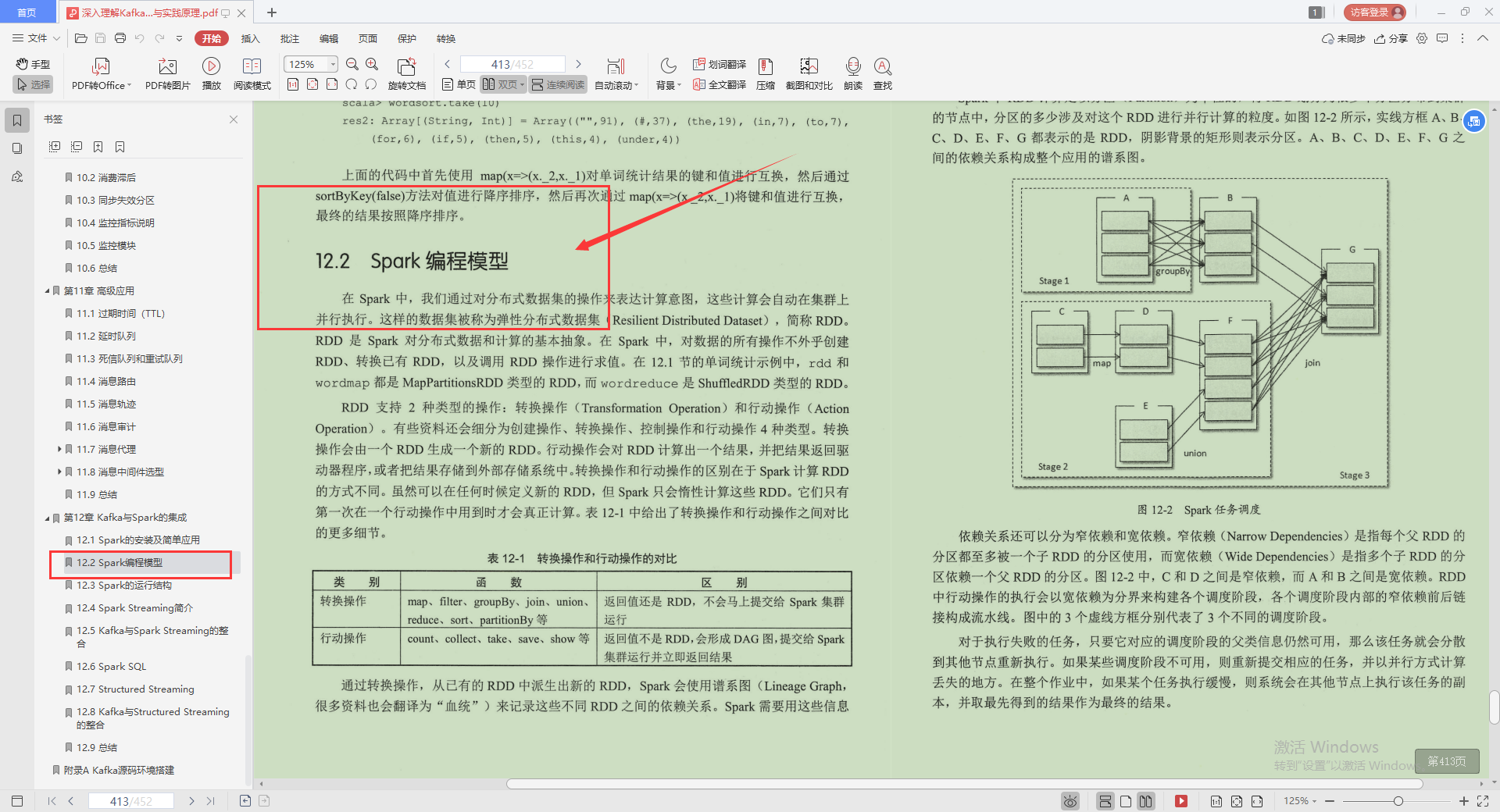
3.Spark的運行結構
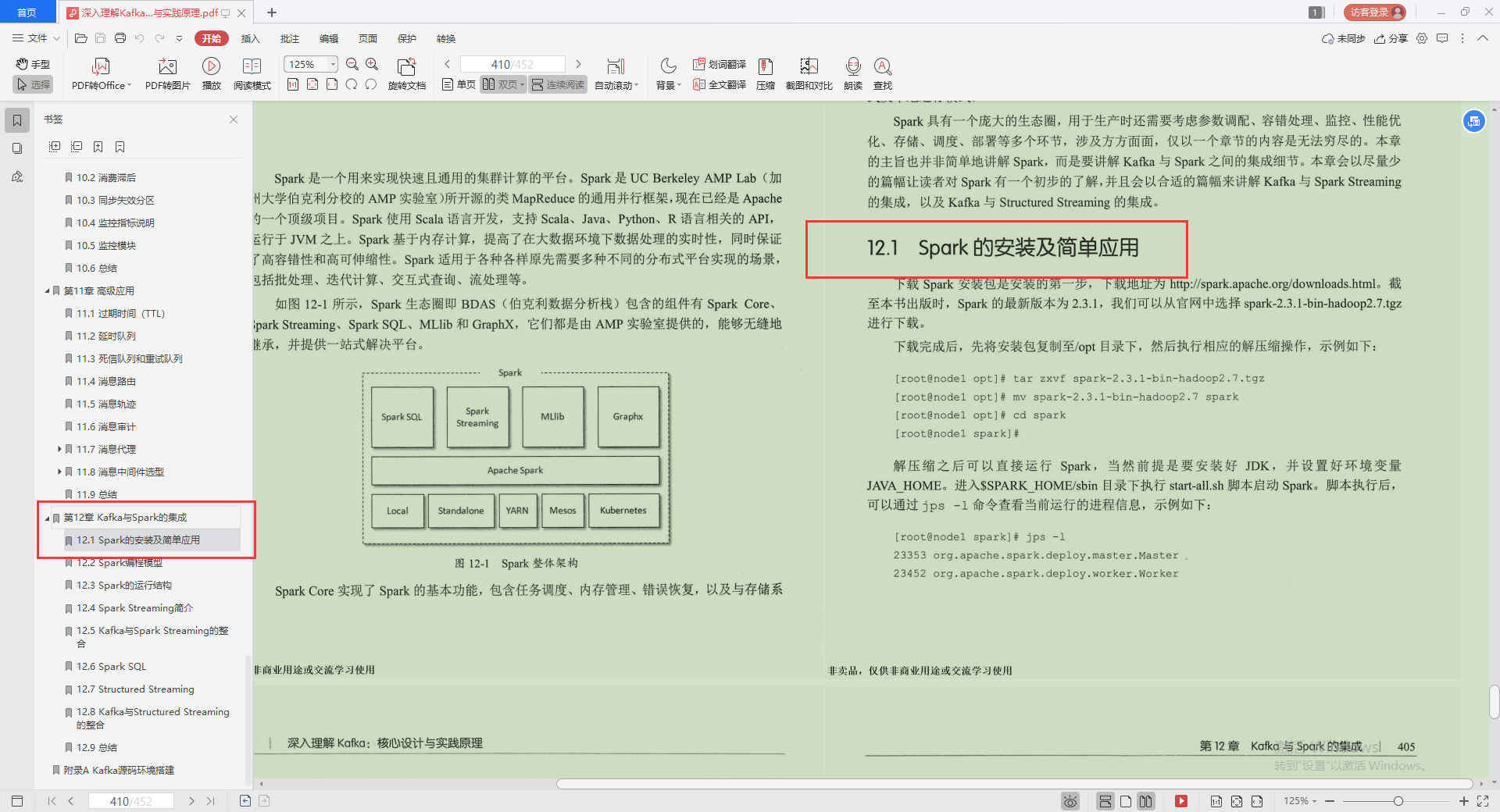
4.Spark Streaming簡介
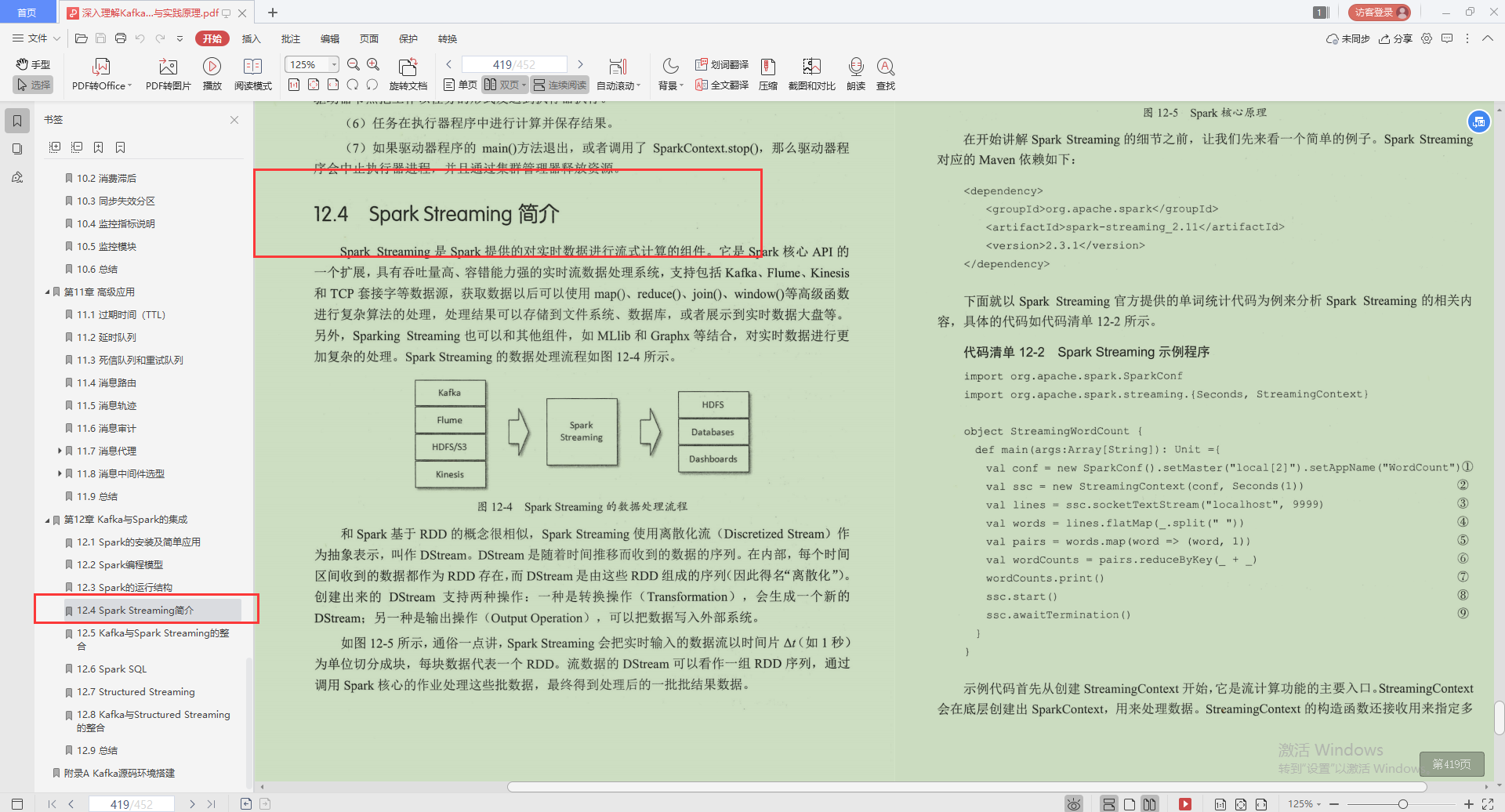
5.Kafka與Spark Streaming的整合
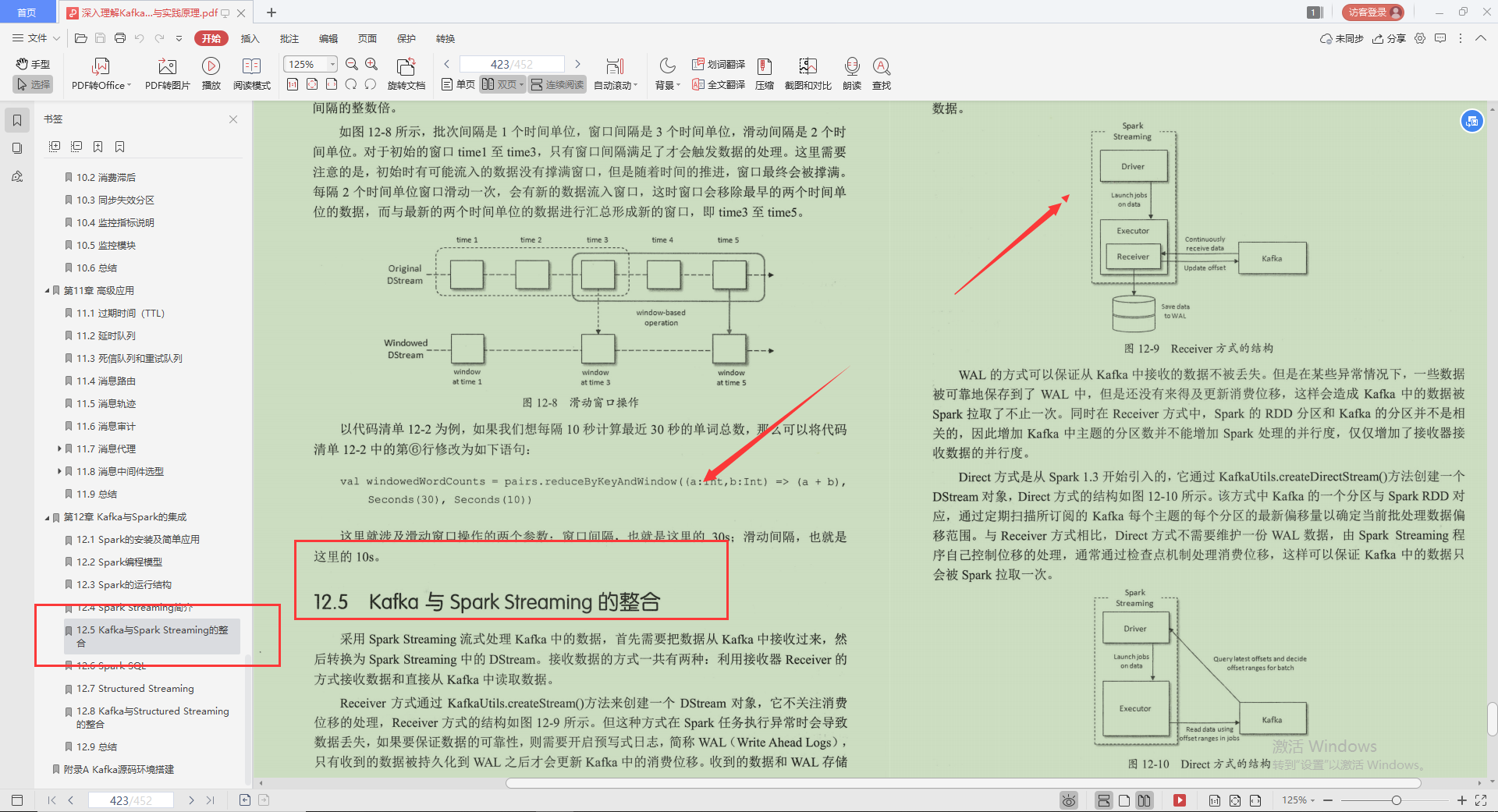
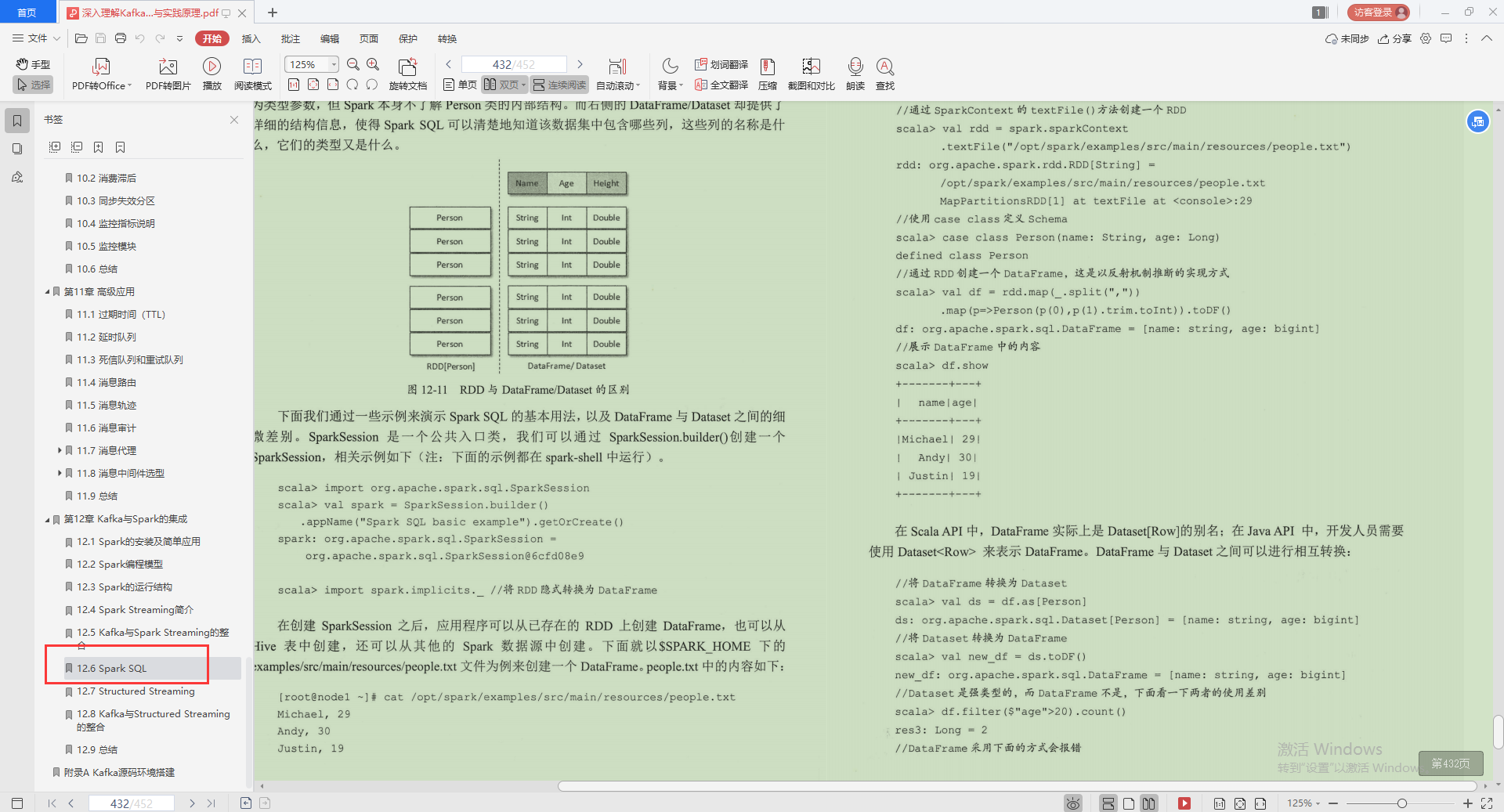
6.Spark SQL
7.Structured Streaming
8.Kafka與Structured Streaming的整合
Ending
Tip:由于文章篇幅有限制,下面還有20個關于MySQL的問題,我都復盤整理成一份pdf文檔了,后面的內容我就把剩下的問題的目錄展示給大家看一下,點擊這里即可解鎖全部內容!
如果覺得有幫助不妨【轉發+點贊+關注】支持我,后續會為大家帶來更多的技術類文章以及學習類文章!(阿里對MySQL底層實現以及索引實現問的很多)

nding
Tip:由于文章篇幅有限制,下面還有20個關于MySQL的問題,我都復盤整理成一份pdf文檔了,后面的內容我就把剩下的問題的目錄展示給大家看一下,點擊這里即可解鎖全部內容!
如果覺得有幫助不妨【轉發+點贊+關注】支持我,后續會為大家帶來更多的技術類文章以及學習類文章!(阿里對MySQL底層實現以及索引實現問的很多)
[外鏈圖片轉存中…(img-uliK74Ye-1625414459540)]
[外鏈圖片轉存中…(img-uvFo1G7U-1625414459540)]
吃透后這份pdf,你同樣可以跟面試官侃侃而談MySQL。其實像阿里p7崗位的需求也沒那么難(但也不簡單),扎實的Java基礎+無短板知識面+對某幾個開源技術有深度學習+閱讀過源碼+算法刷題,這一套下來p7崗差不多沒什么問題,還是希望大家都能拿到高薪offer吧。



















