目錄
?
1.ElasticSearch的簡介
2.用數據庫實現搜素的功能
3.ES的核心概念
3.1 NRT(Near Realtime)近實時
3.2 cluster集群,ES是一個分布式的系統
3.3 Node節點,就是集群中的一臺服務器
3.4 index 索引(索引庫)
3.5 type類型
3.6 document:文檔
3.7 Field 字段
3.8 shard:分片
3.9 relica:副本
總結:
4. ES集群的安裝
4.1 下載
4.2 安裝并啟動ES
5. 安裝 Kibana
5.1 為什么要安裝
5.2 安裝并啟動
5.3 參數解析:
6. ES的相關命令
7. ES的CURD操作
8.DSL語言
9.聚合分析
10.ES的隱藏性
11.ES集群的擴容問題
12.對等式架構
13.ES的primary shard和replica shard
14.ES的容錯機制
15.自動生成ID號
16.version之悲觀鎖和樂觀鎖
1.ElasticSearch的簡介
ElasticSearch:智能搜索,分布式的搜索引擎
是ELK的一個組成,是一個產品,而且是非常完善的產品,ELK代表的是:E就是ElasticSearch,L就是Logstach,K就是kibana
E:EalsticSearch 搜索和分析的功能
L:Logstach 搜集數據的功能,類似于flume(使用方法幾乎跟flume一模一樣),是日志收集系統
K:Kibana 數據可視化(分析),可以用圖表的方式來去展示,文不如表,表不如圖,是數據可視化平臺

分析日志的用處:假如一個分布式系統有 1000 臺機器,系統出現故障時,我要看下日志,還得一臺一臺登錄上去查看,是不是非常麻煩?
但是如果日志接入了 ELK 系統就不一樣。比如系統運行過程中,突然出現了異常,在日志中就能及時反饋,日志進入 ELK 系統中,我們直接在 Kibana 就能看到日志情況。如果再接入一些實時計算模塊,還能做實時報警功能。
這都依賴ES強大的反向索引功能,這樣我們根據關鍵字就能查詢到關鍵的錯誤日志了。
什么是搜索?
1)百度,谷歌,必應。我們可以通過他們去搜索我們需要的東西。但是我們的搜索不只是包含這些,還有京東站內搜索啊。
2)互聯網的搜索:電商網站。招聘網站。新聞網站。各種APP(百度外賣,美團等等)
3)windows系統的搜索,OA軟件,淘寶SSM網站,前后臺的搜索功能
總結:搜索無處不在。通過一些關鍵字,給我們查詢出來跟這些關鍵字相關的信息
什么是全文檢索
全文檢索是指計算機索引程序通過掃描文章中的每一個詞,對每一個詞建立一個索引,指明該詞在文章中出現的次數和位置,當用戶查詢時,檢索程序就根據事先建立的索引進行查找,并將查找的結果反饋給用戶的檢索方式。這個過程類似于通過字典中的檢索字表查字的過程。
全文檢索的方法主要分為按字檢索和按詞檢索兩種。按字檢索是指對于文章中的每一個字都建立索引,檢索時將詞分解為字的組合。對于各種不同的語言而言,字有不同的含義,比如英文中字與詞實際上是合一的,而中文中字與詞有很大分別。按詞檢索指對文章中的詞,即語義單位建立索引,檢索時按詞檢索,并且可以處理同義項等。英文等西方文字由于按照空白切分詞,因此實現上與按字處理類似,添加同義處理也很容易。中文等東方文字則需要切分字詞,以達到按詞索引的目的,關于這方面的問題,是當前全文檢索技術尤其是中文全文檢索技術中的難點,在此不做詳述。
什么是倒排索引
以前是根據ID查內容,倒排索引之后是根據內容查ID,然后再拿著ID去查詢出來真正需要的東西。

什么是Lucene
Lucene就是一個jar包,里面包含了各種建立倒排索引的方法,java開發的時候只需要導入這個jar包就可以開發了。
Lucene的介紹及使用
典型的用空間換時間。
ES 和 Lucene的區別
Lucene不是分布式的。
ES的底層就是Lucene,ES是分布式的
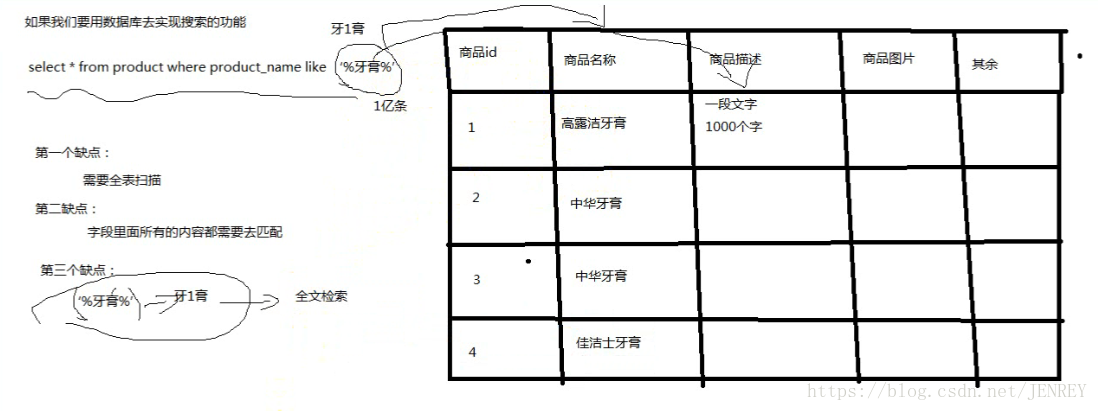
為什么不用數據庫去實現搜索功能?
我們用搜索“牙膏”商品為例

如果用我們平時數據庫來實現搜索的功能在性能上就很差。
ES的官網
ES官網點我
簡單使用如下圖,可以切換成中文的文檔
或者使用spark的中文網站,也有ES的文檔,傳送門在下面
ES中文文檔
ES的由來
因為Lucene有兩個難以解決的問題,
1)數據越大,存不下來,那我就需要多臺服務器存數據,那么我的Lucene不支持分布式的,那就需要安裝多個Lucene然后通過代碼來合并搜索結果。這樣很不好
2)數據要考慮安全性,一臺服務器掛了,那么上面的數據不就消失了。
ES就是分布式的集群,每一個節點其實就是Lucene,當用戶搜索的時候,會隨機挑一臺,然后這臺機器自己知道數據在哪,不用我們管這些底層、
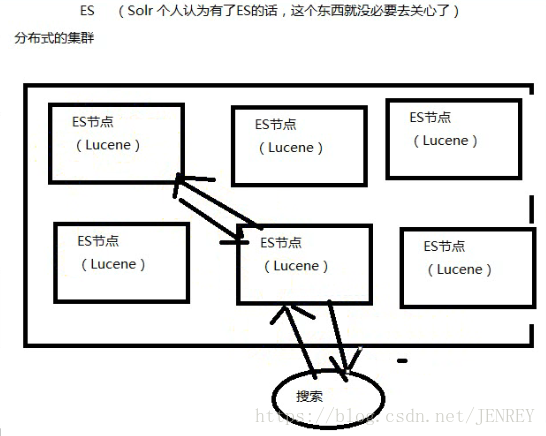
ES的優點
1.分布式的功能
2、數據高可用,集群高可用
3.API更簡單
4.API更高級。
5.支持的語言很多
6.支持PB級別的數據
7.完成搜索的功能和分析功能
基于Lucene,隱藏了Lucene的復雜性,提供簡單的API
ES的性能比HBase高,咱們的競價引擎最后還是要存到ES中的。
搜索引擎原理
- 反向索引又叫倒排索引,是根據文章內容中的關鍵字建立索引。
- 搜索引擎原理就是建立反向索引。
- Elasticsearch 在 Lucene 的基礎上進行封裝,實現了分布式搜索引擎。
- Elasticsearch 中的索引、類型和文檔的概念比較重要,類似于 MySQL 中的數據庫、表和行。
- Elasticsearch 也是 Master-slave 架構,也實現了數據的分片和備份。
- Elasticsearch 一個典型應用就是 ELK 日志分析系統。
ES支持的語言
Curl、java、c#、python、JavaScript、php、perl、ruby
Curl 'www.baidu.com' 就是linux的shell命令。可以訪問百度,返回的是百度的網頁代碼
ES的作用
1)全文檢索:
類似 select * from product where?product_name like '%牙膏%'
類似百度效果(電商搜索的效果)
2)結構化搜索:
類似 select * from product where product_id = '1'
3)數據分析
類似 select count (*) from product
ES的安裝
直接解壓就能用(針對中小型項目),大型項目還是要調一調參數的
2.用數據庫實現搜素的功能
3.ES的核心概念
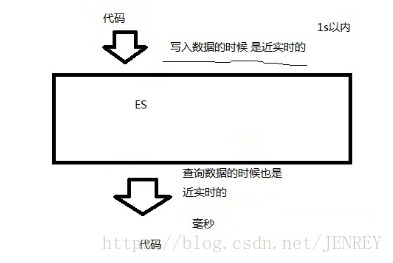
3.1 NRT(Near Realtime)近實時
3.2 cluster集群,ES是一個分布式的系統
ES直接解壓不需要配置就可以使用,在hadoop1上解壓一個ES,在hadoop2上解壓了一個ES,接下來把這兩個ES啟動起來。他們就構成了一個集群。
在ES里面默認有一個配置,clustername?默認值就是ElasticSearch,如果這個值是一樣的就屬于同一個集群,不一樣的值就是不一樣的集群。
3.3 Node節點,就是集群中的一臺服務器
3.4 index 索引(索引庫)
我們為什么使用ES?因為想把數據存進去,然后再查詢出來。
我們在使用Mysql或者Oracle的時候,為了區分數據,我們會建立不同的數據庫,庫下面還有表的。
其實ES功能就像一個關系型數據庫,在這個數據庫我們可以往里面添加數據,查詢數據。
ES中的索引非傳統索引的含義,ES中的索引是存放數據的地方,是ES中的一個概念詞匯
index類似于我們Mysql里面的一個數據庫 create database user; 好比就是一個索引庫
3.5 type類型
類型是用來定義數據結構的
在每一個index下面,可以有一個或者多個type,好比數據庫里面的一張表。
相當于表結構的描述,描述每個字段的類型。
3.6 document:文檔
文檔就是最終的數據了,可以認為一個文檔就是一條記錄。
是ES里面最小的數據單元,就好比表里面的一條數據
3.7 Field 字段
好比關系型數據庫中列的概念,一個document有一個或者多個field組成。
例如:
朝陽區:一個Mysql數據庫
房子:create database chaoyaninfo
房間:create table people
3.8 shard:分片
一臺服務器,無法存儲大量的數據,ES把一個index里面的數據,分為多個shard,分布式的存儲在各個服務器上面。
kafka:為什么支持分布式的功能,因為里面是有topic,支持分區的概念。所以topic A可以存在不同的節點上面。就可以支持海量數據和高并發,提升性能和吞吐量
3.9 replica:副本
一個分布式的集群,難免會有一臺或者多臺服務器宕機,如果我們沒有副本這個概念。就會造成我們的shard發生故障,無法提供正常服務。
我們為了保證數據的安全,我們引入了replica的概念,跟hdfs里面的概念是一個意思。
可以保證我們數據的安全。
在ES集群中,我們一模一樣的數據有多份,能正常提供查詢和插入的分片我們叫做 primary shard,其余的我們就管他們叫做 replica shard(備份的分片)?
當我們去查詢數據的時候,我們數據是有備份的,它會同時發出命令讓我們有數據的機器去查詢結果,最后誰的查詢結果快,我們就要誰的數據(這個不需要我們去控制,它內部就自己控制了)
總結:
在默認情況下,我們創建一個庫的時候,默認會幫我們創建5個主分片(primary shrad)和5個副分片(replica shard),所以說正常情況下是有10個分片的。
同一個節點上面,副本和主分片是一定不會在一臺機器上面的,就是擁有相同數據的分片,是不會在同一個節點上面的。
所以當你有一個節點的時候,這個分片是不會把副本存在這僅有的一個節點上的,當你新加入了一臺節點,ES會自動的給你在新機器上創建一個之前分片的副本。

3.10 舉例
比如一首詩,有詩題、作者、朝代、字數、詩內容等字段,那么首先,我們可以建立一個名叫 Poems 的索引,然后創建一個名叫 Poem 的類型,類型是通過 Mapping 來定義每個字段的類型。
比如詩題、作者、朝代都是 Keyword 類型,詩內容是 Text 類型,而字數是 Integer 類型,最后就是把數據組織成 Json 格式存放進去了。

Keyword 類型是不會分詞的,直接根據字符串內容建立反向索引,Text 類型在存入 Elasticsearch 的時候,會先分詞,然后根據分詞后的內容建立反向索引。

?
4. ES集群的安裝
4.1 下載
點擊上面的官網傳送門,點擊downloads
下載ES點我

關于ES的版本,現在大多數網上和書寫的都是ES 2.x系列的書,有部分比較新的講的是ES 5的
沒有3,4一說。是這樣的,ELK 產品是一個非常完善的系統,跟大數據沒什么關系,后來我們發現可以處理一些大數據的東西。可以和hadoop和spark整合。因為ELK三個產品是不同的公司出的。有一天一個人想把它們整合在一起,發現E發展到了2的版本,L發展到了3的版本,K發展到了4的版本。這樣會有一個問題,什么樣的hive和hbase配合什么樣的hadoop,這樣引發了一個匹配不匹配的問題。三個廠家就決定,從下一代產品我們一起升級就從5版本開始,所以如果你E用5.6,L也應該用5.6,K也應該用5.6,這樣就進行了匹配。
這里我們下載安裝目前最新版本的6.3.2的ES,注意需要安裝好JDK,因為是由java開發的。
4.2 安裝并啟動ES
直接解壓即可,進入bin目錄,本文為 G:\myProgram\ElasticSearch\elasticsearch-6.3.2\bin 下進入cmd,
輸入elasticsearch
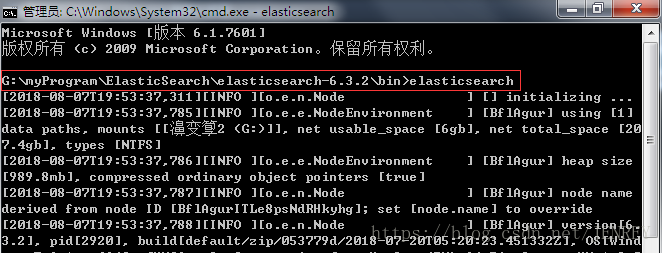
驗證ES是否啟動成功
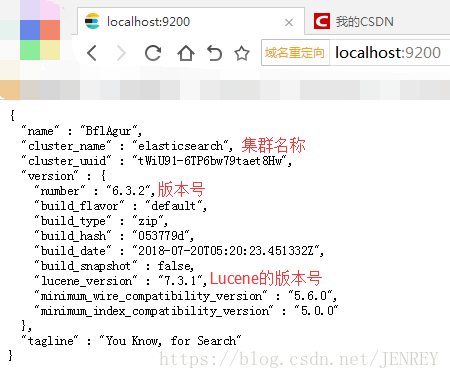
在瀏覽器中輸入?http://localhost:9200?看到如下所示圖片即為成功
4.3 ES的分布式原理
Elasticsearch 也是會對數據進行切分,同時每一個分片會保存多個副本,其原因和 HDFS 是一樣的,都是為了保證分布式環境下的高可用。

在 Elasticsearch 中,是master-slave架構。節點是對等的,節點間會通過自己的一些規則選取集群的 Master,Master 會負責集群狀態信息的改變,并同步給其他節點。

這樣寫入性能會不會很低???注意,只有建立索引和類型需要經過 Master,數據的寫入有一個簡單的 Routing 規則,可以 Route 到集群中的任意節點,所以數據寫入壓力是分散在整個集群的。
?
5. 安裝 Kibana
5.1 為什么要安裝
為了方便我們去操作ES,如果不安裝去操作ES很麻煩,需要通過shell命令的方式。
下載Kibana
5.2 安裝并啟動
直接解壓即可,進入bin目錄下,本文為G:\myProgram\kibana\kibana-6.3.2-windows-x86_64\bin 的cmd,執行kibana
不需要配置任何參數,自動識別localhost
在瀏覽器中輸入 ?http://localhost:5601
然后在左側找到Dev Tools,在這里就可以進行操作了

輸入GET _cat/health 查看集群的健康狀況

5.3 參數解析:
green:每個索引的primary shard和replica shard 都處于active的狀態。
下圖是一個ES集群有兩個節點。主分片是支撐用戶的讀寫。副只支持讀數據。這樣就造成主分片壓力會大一點,所以ES集群在分配分片的時候會考慮負載均衡,依據就是按照主分片的情況來。
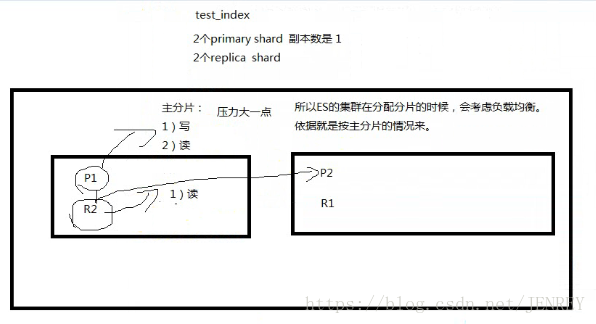
yellow:每個索引的primary shard是active的狀態,但是部分replica shard不是active的狀態,處于不可用的狀態。
使用GET _cat/indices 命令查詢ES中所有的index

但是可能查詢的不全,我們使用下面的命令
GET _all
但是可能會質疑,我們剛搭建好什么數據也沒插入,為什么會有數據查出來。
下面這段話講的是5.6.3版本。

我們通過啟動Kibana進行對接的ES,默認自動在ES上創建了一個index庫,這個庫有個特點,這個庫有一個主分片primary shard,有一個replica shard 副分片
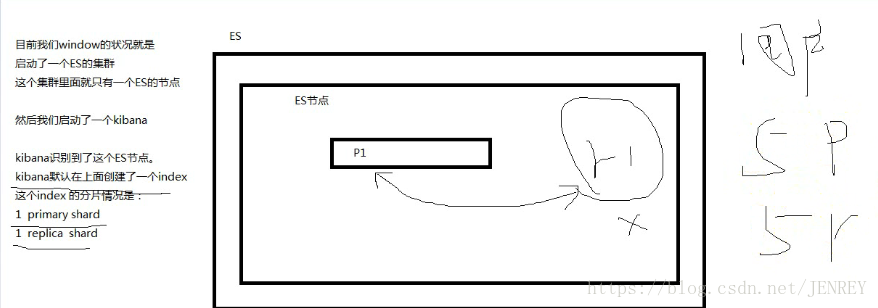
如下圖所示,我們目前windows的狀況是啟動了一個ES的集群,這個集群里面只有一個ES的節點。

然后我們啟動了一個kibana
kibana識別到了這個ES節點,kibana默認在上面創建了一個index,這個index的分片情況是 1 primary shard 和1 replica shard
但是可能咱們現在用的這個版本有了一些優化可能就跟上面說的不一樣了。我們現在ES的狀態是green
如何把集群的狀態由yellow變成green?
我再啟動一個節點(換個路徑再次解壓ES的壓縮包在啟動起來),讓之前的那個有地方放置就好了。
再次執行查詢健康的命令,效果圖如下

?
red:不是所有的primary shard 都是active的狀態,這時候是危險的,至少我們不能保證寫數據是安全的。
6. ES的相關命令
這里的效果圖是沒有搭建第二個ES的節點的(因為電腦空間不太夠了)
GET _cat/health 查看集群的健康狀況
GET _all
PUT 類似于SQL中的增
DELETE 類似于SQL中的刪
POST 類似于SQL中的改
GET 類似于SQL中的查
index的操作:
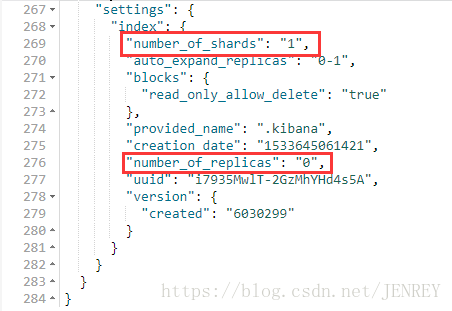
PUT /aura_index 增加一個aura_index的index庫

GET _cat/indices 命令查詢ES中所有的index索引庫

5:代表的是 primary shard的個數
1:代表的是replica shard的個數是5,因為副本數為1代表有5個副分片,注意這個地方說的1是不包括自己本身的,我們的HDFS block3代表的是包括自己本身的
DELETE /aura_index 刪除一個aura_index的index庫
7. ES的CURD操作
通過演示一個電商的例子,感受到ES的語法特點
1)插入一條商品數據
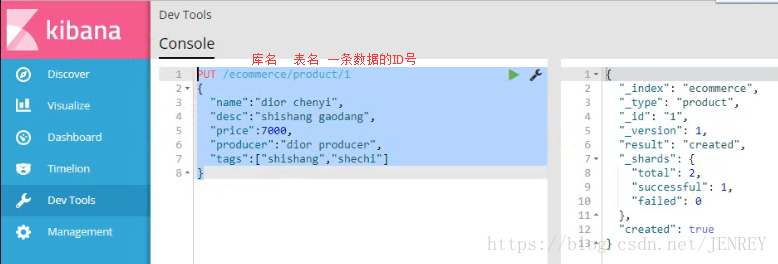
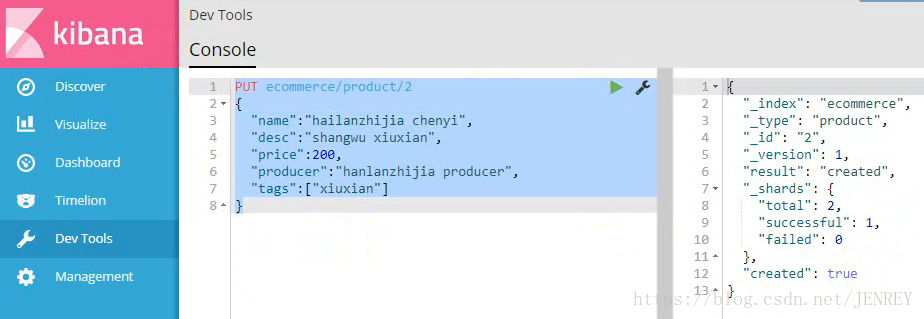
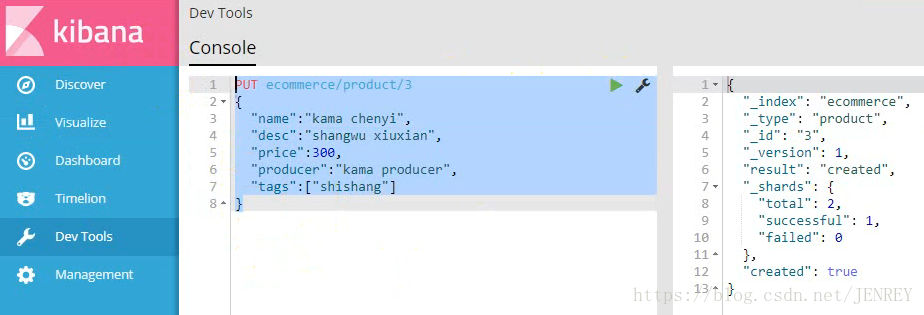
注意:我們插入數據的時候,如果我們的語句中指明了index和type,如果ES里面不存在,默認幫我們自動創建
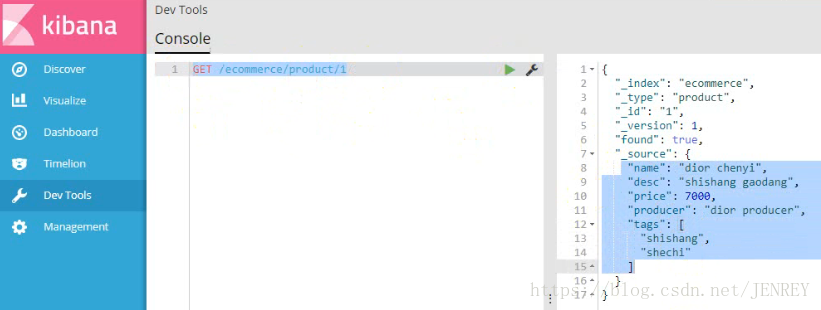
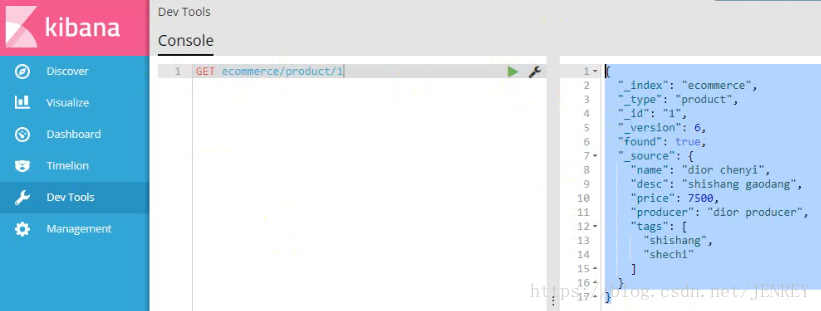
2)查詢商品數據
使用這種語法: GET /index/type/id
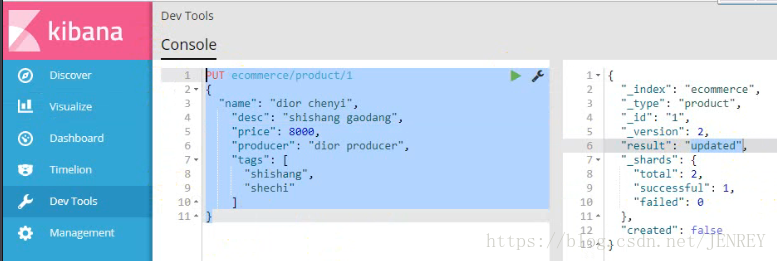
3)修改商品數據
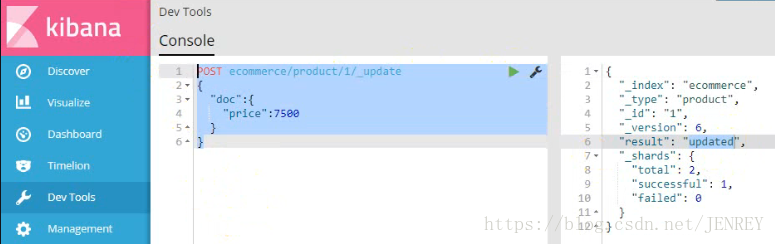
使用POST來修改數據,其實使用PUT也可以實現修改數據,原理和hbase比較像。POST的修改數據的方法在第4條中
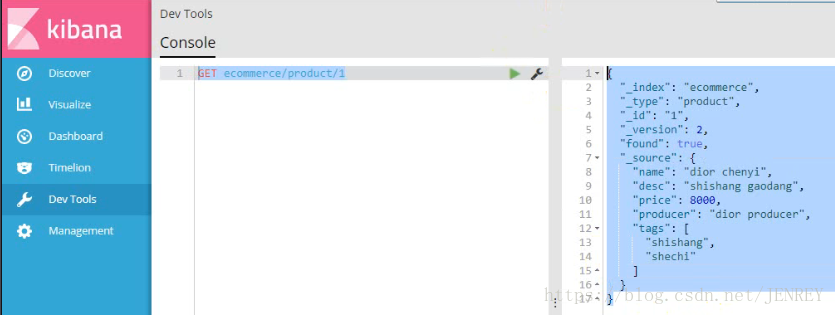
換個方式,下面這種操作也是成功的,會丟數據,是全局的修改
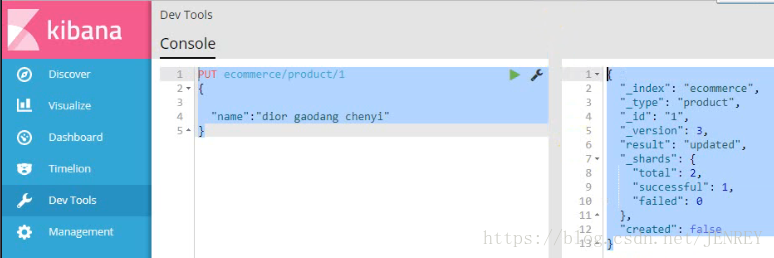
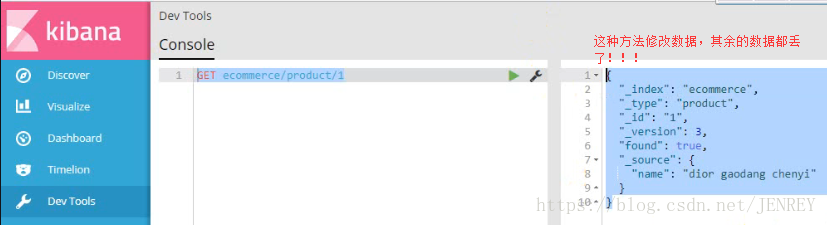
4)刪除商品數據
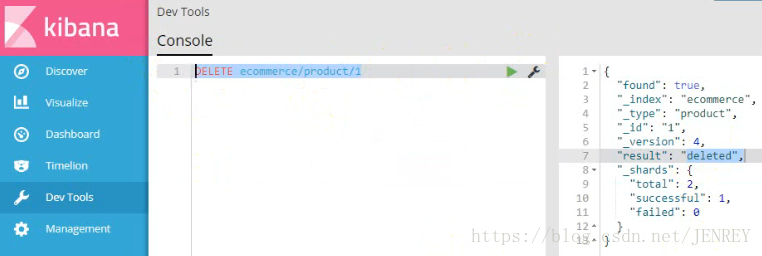
再次插入之前的數據,發現version是5,這就說明跟hbase是類似的,不會立刻刪除,會在合適的時機進行刪除。
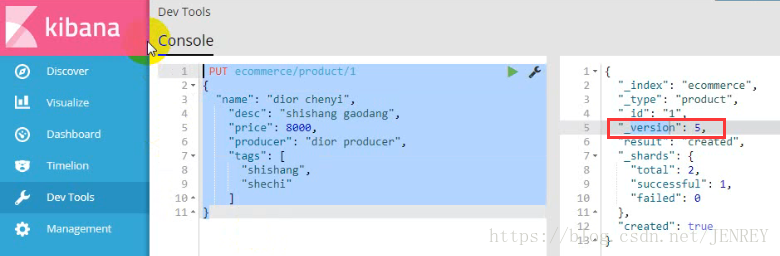
這次我們使用POST的方式進行修改數據,POST是局部更新數據,別的數據不動。PUT是全局更新
5)接著插入兩條數據
現在查看所有數據,類似于全表掃描
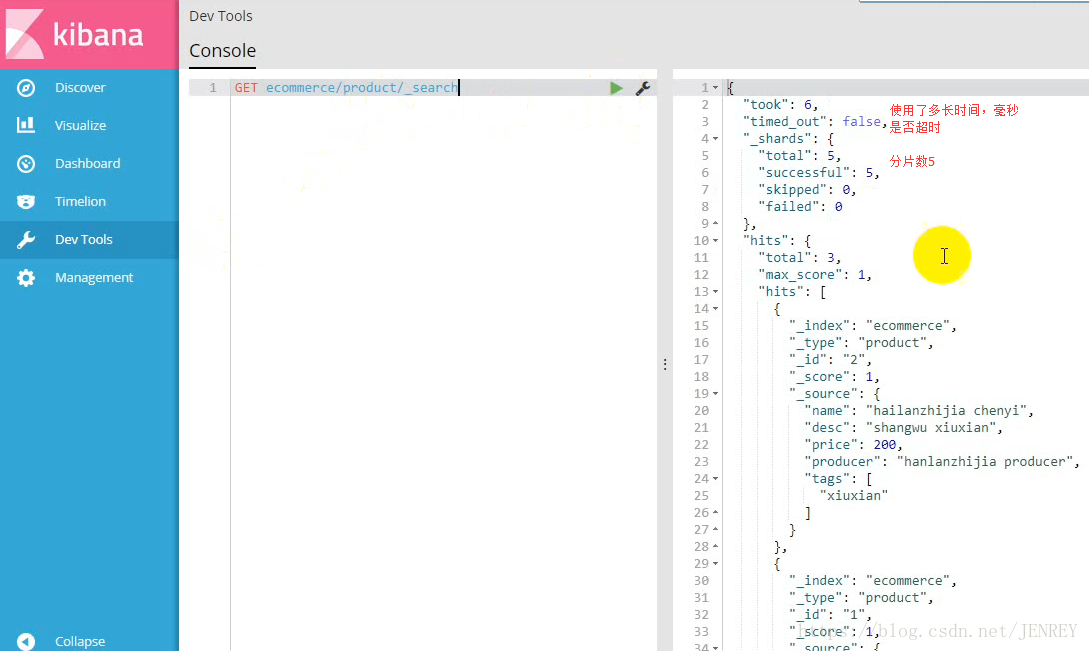
took:耗費了6毫秒
shards:分片的情況
hits:獲取到的數據的情況
total:3 總的數據條數
max_score:1 所有數據里面打分最高的分數
_index:"ecommerce" index名稱
_type:"product" type的名稱
_id:"2" id號
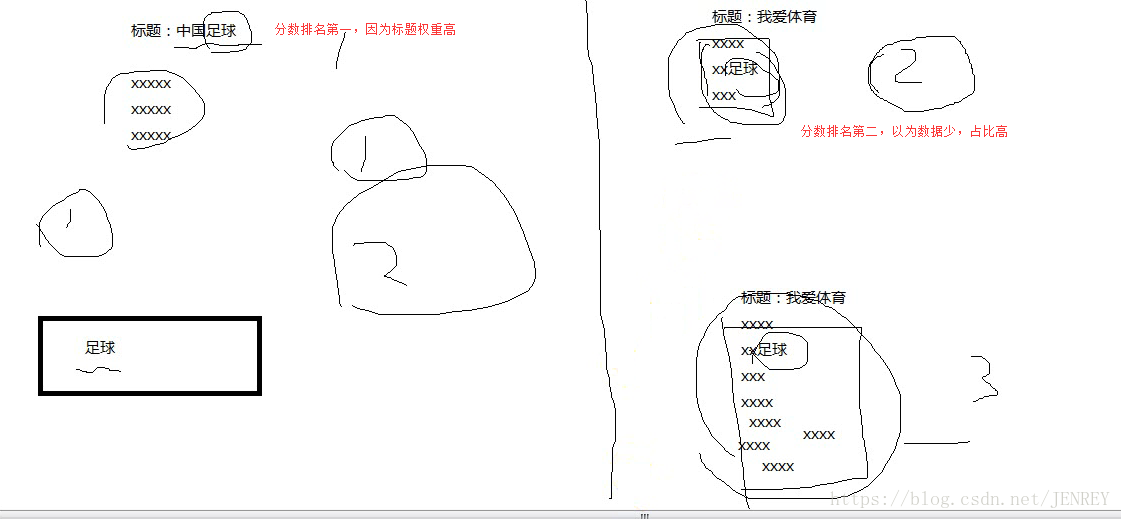
_score:1 分數,這個分數越大越靠前出來,百度也是這樣。除非是花錢。否則匹配度越高越靠前

8.DSL語言
ES最主要是用來做搜索和分析的。所以DSL還是對于ES很重要的
下面我們寫的代碼都是RESTful風格
query? DSL:domain Specialed Lanaguage 在特定領域的語言
案例:我們要進行全表掃描使用DSL語言,查詢所有的商品

使用match_all?可以查詢到所有文檔,是沒有查詢條件下的默認語句。
案例:查詢所有名稱里面包含chenyi的商品,同時按價格進行降序排序
如上圖所示,name為dior chenyi的數據會在ES中進行倒排索引分詞的操作,這樣的數據也會被查詢出來。
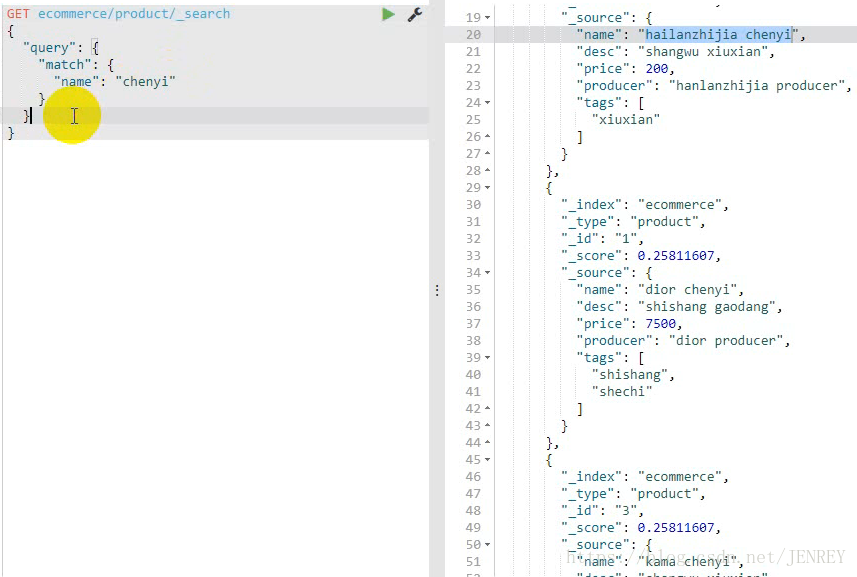
match查詢是一個標準查詢,不管你需要全文本查詢還是精確查詢基本上都要用到它。
下面我們按照價格進行排序:因為不屬于查詢的范圍了。所以要寫一個 逗號
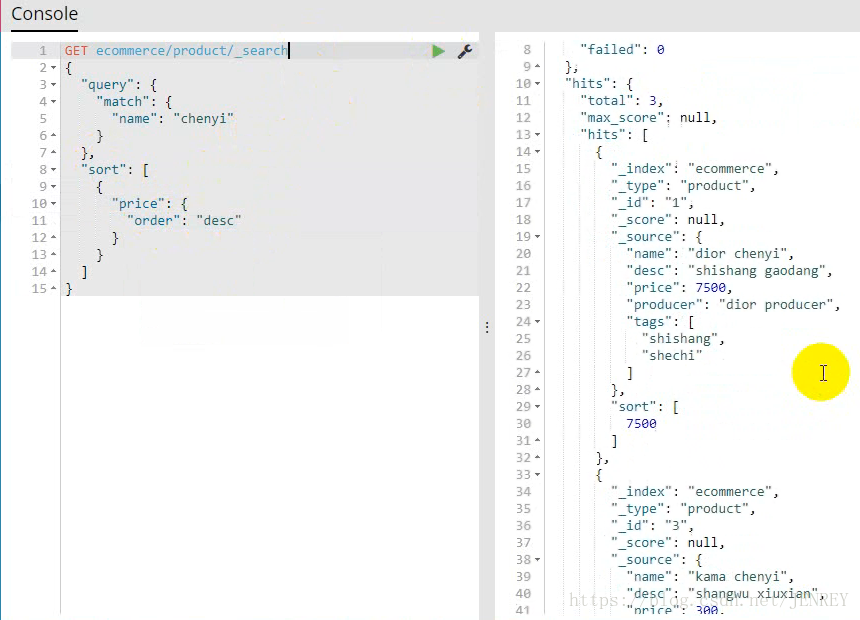
這樣我們的排序就完成了
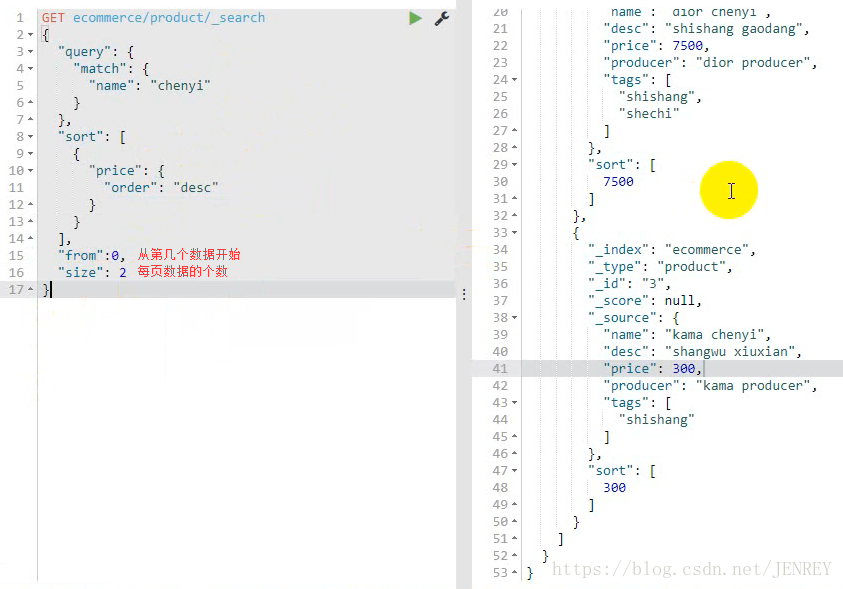
案例:實現分頁查詢
條件:根據查詢結果(包含chenyi的商品),再進行每頁展示2個商品
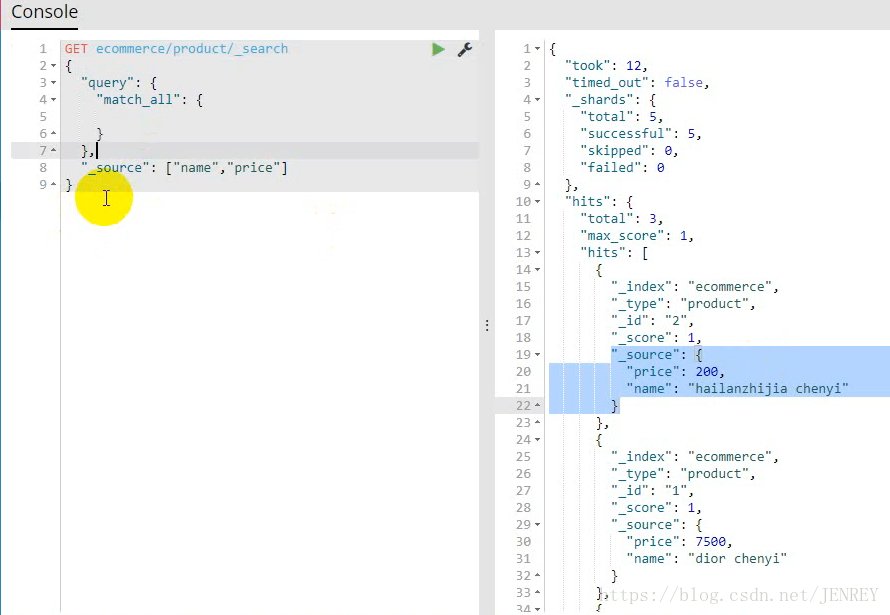
案例:進行全表掃面,但返回指定字段的數據
現在的情況是把所有的數據都返回了,但是我們想返回指定字段的數據內容就需要下面的方法了
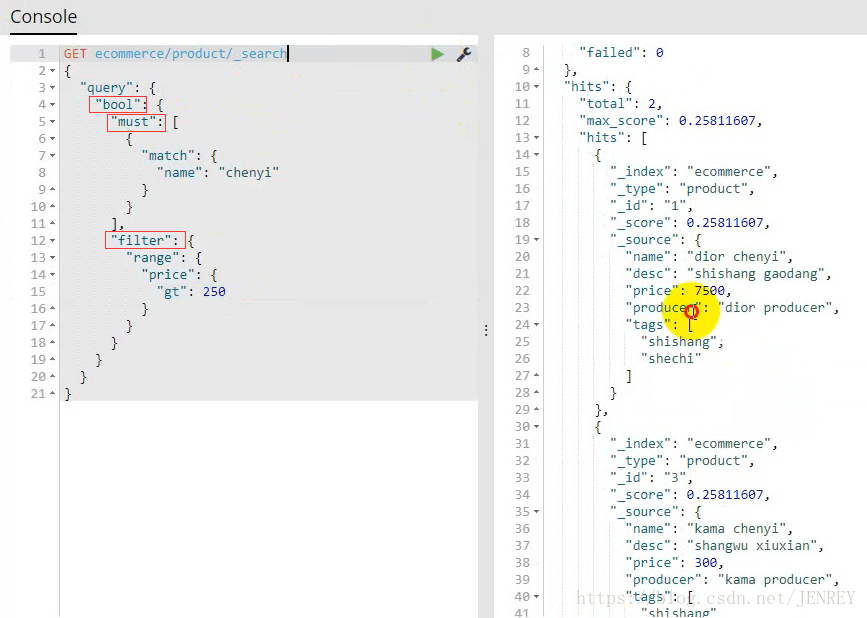
案例:搜索名稱里面包含chenyi的,并且價格大于250元的商品
相當于 select * form product where name like %chenyi% and price >250;
因為有兩個查詢條件,我們就需要使用下面的查詢方式
如果需要多個查詢條件拼接在一起就需要使用bool
?bool?過濾可以用來合并多個過濾條件查詢結果的布爾邏輯,它包含以下操作符:
? ??must?:: 多個查詢條件的完全匹配,相當于?and。
? ??must_not?:: 多個查詢條件的相反匹配,相當于?not。
? ??should?:: 至少有一個查詢條件匹配, 相當于?or。
? ??這些參數可以分別繼承一個過濾條件或者一個過濾條件的數組
案例:展示一個全文檢索的效果
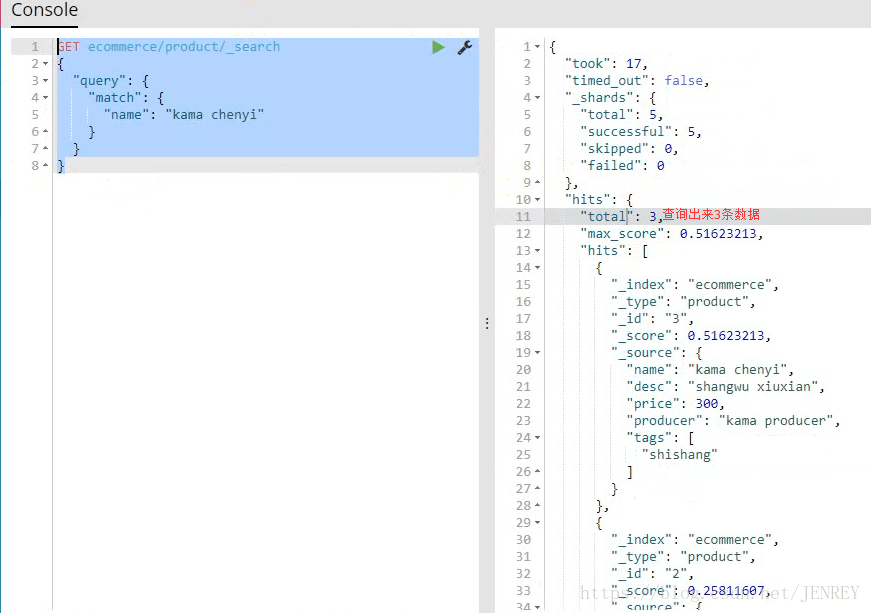
首先查詢條件也會進行分詞
kama
chenyi
并集
案例:不要把條件分詞,要精確匹配
但是我們現有有一種需求我就是想查詢kama chenyi不要分詞,要精確匹配到
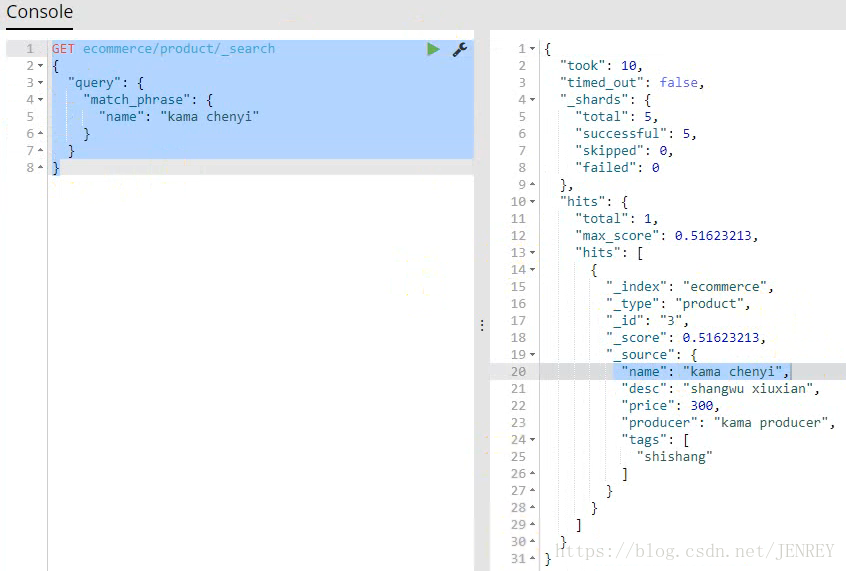
百度就類似于這樣
案例:把查詢結果進行高亮展示
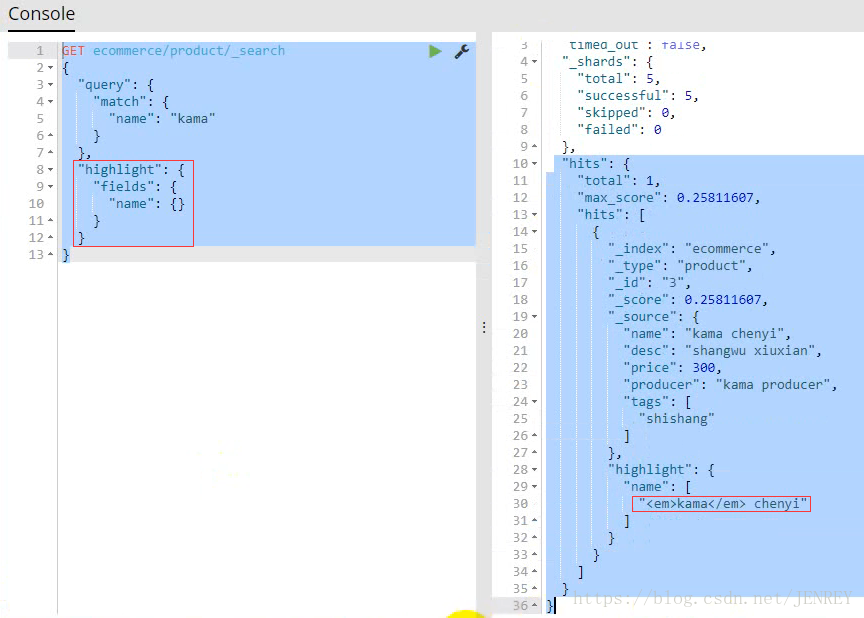
?
<em>kama</em>這個標簽是默認的標簽,是可以自定義的進行替換的,比如我們可以替換成<span style="color:red">kama</span>,把這個輸出到網頁上,自然而然就是紅色的了。
9.聚合分析
案例:計算每個標簽tag下商品的數量
按標簽進行分組類似于 select count(*) from product group by tag;
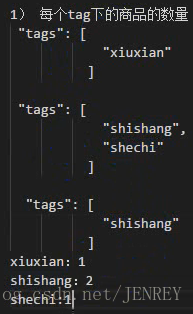
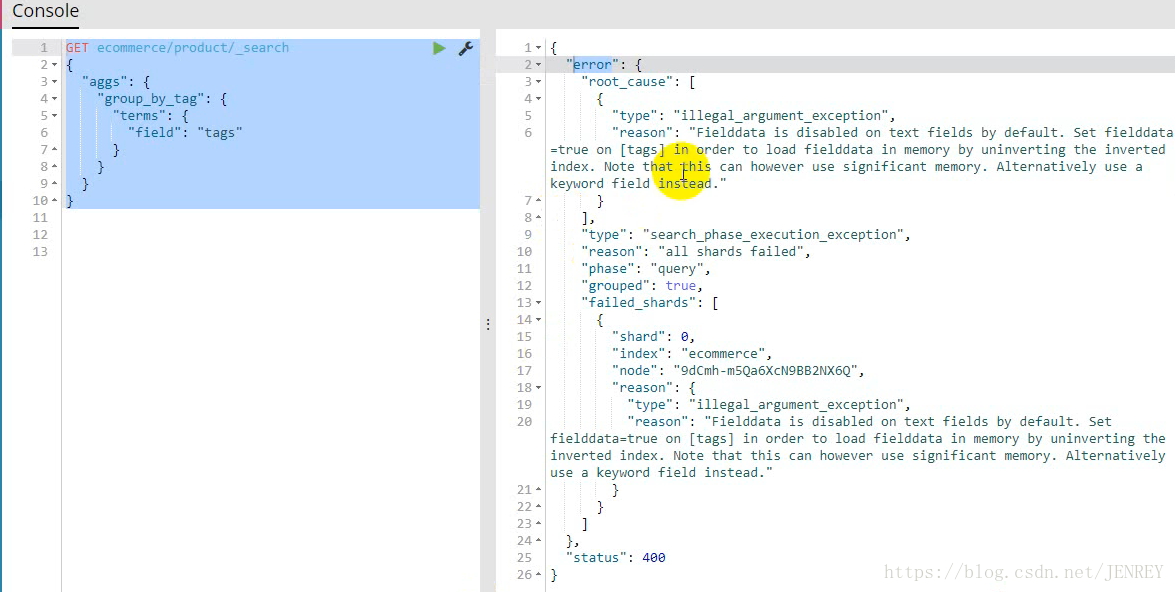
terms?跟?term?有點類似,但?terms?允許指定多個匹配條件。 如果某個字段指定了多個值,那么文檔需要一起去做匹配
error是報錯,但是這個語句是對的,這個報錯在ES2之前是沒有的,在ES5以后才有的,在5中fielddata=true 默認是false,以前都是true
group_by_tag是個名字隨意取
所以我們需要先執行下面的代碼進行一下設置的修改:

再次執行一次
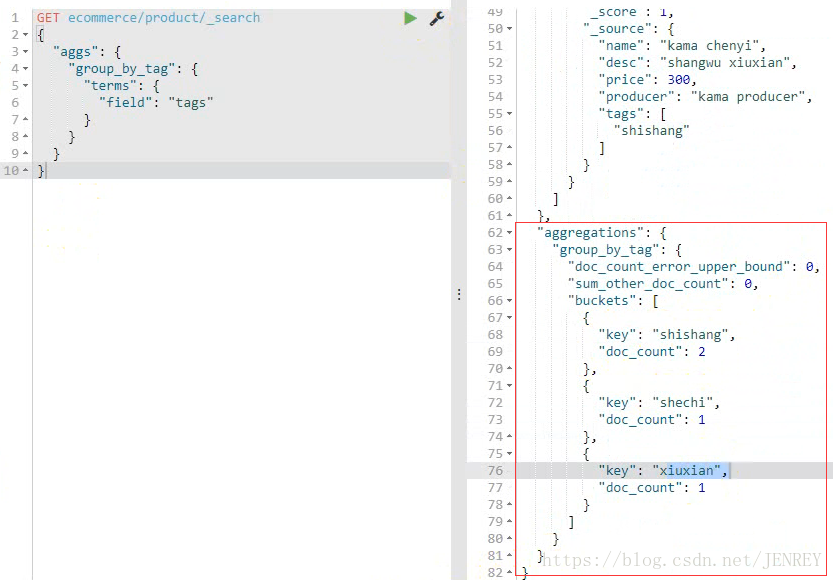
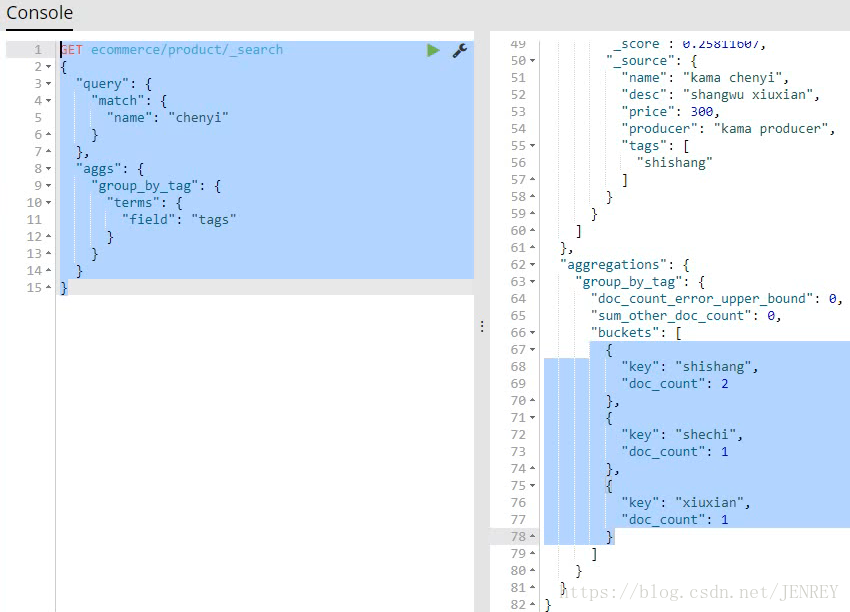
案例:對商品名稱里面包含chenyi的,計算每個tag下商品的數量
?
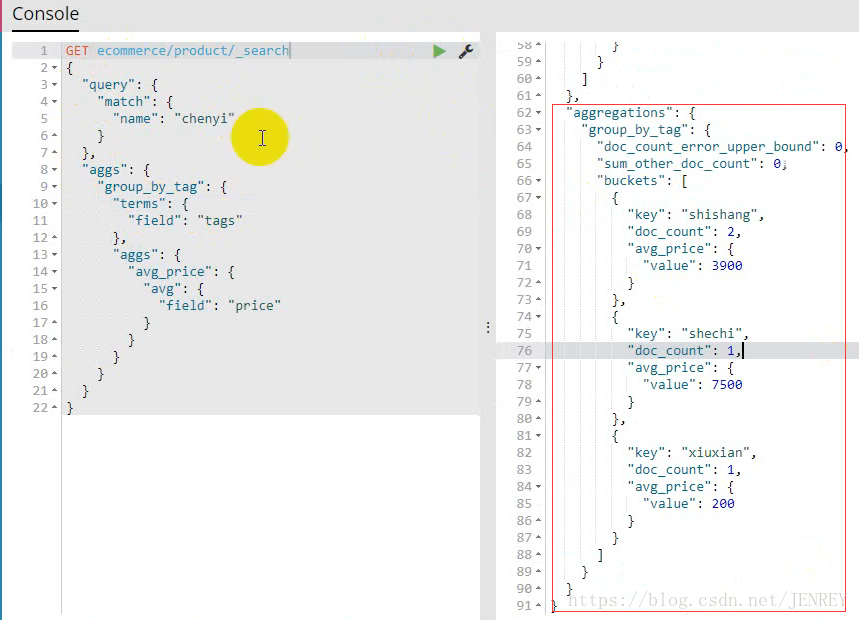
案例:查詢商品名稱里面包含chenyi的數據,并且按照tag進行分組,計算每個分組下的平均價格
案例:查詢商品名稱里面包含chenyi的數據,并且按照tag進行分組,計算每個分組下的平均價格,按照平均價格進行降序排序
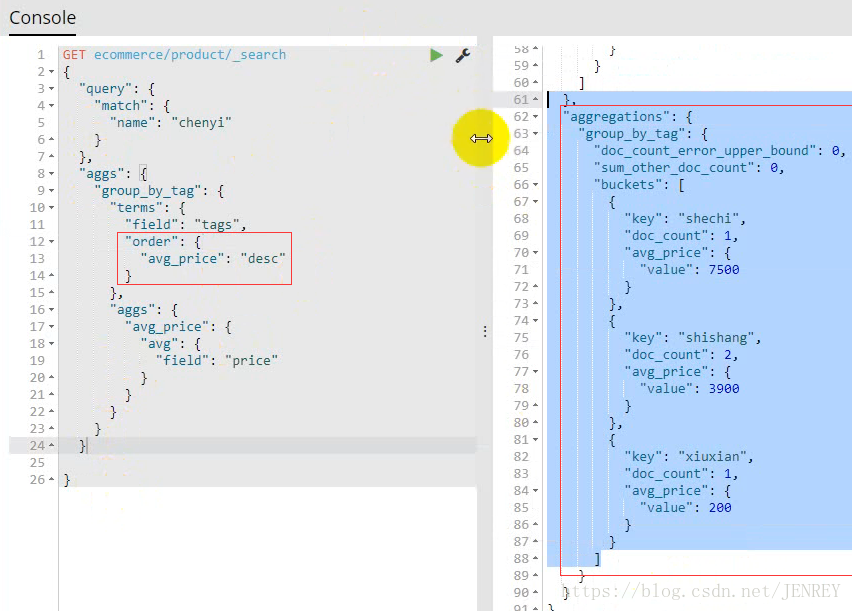
注意寫的位置
案例:查詢出producer里面包含producer的數據,按照指定的價格區間進行分組,在每個組內再按tag進行分組,分完組以后再求每個組的平均價格,并且按照降序進行排序
range過濾允許我們按照指定范圍查找一批數據


10.ES的隱藏性
ES是一個分布式的系統,里面我們在使用的時候隱藏了復雜的分布式的機制
1)分片機制
插入數據的時候不是根據負載均衡來插入的,是根據一定的路由規則,比如我們就取哈希值取模,
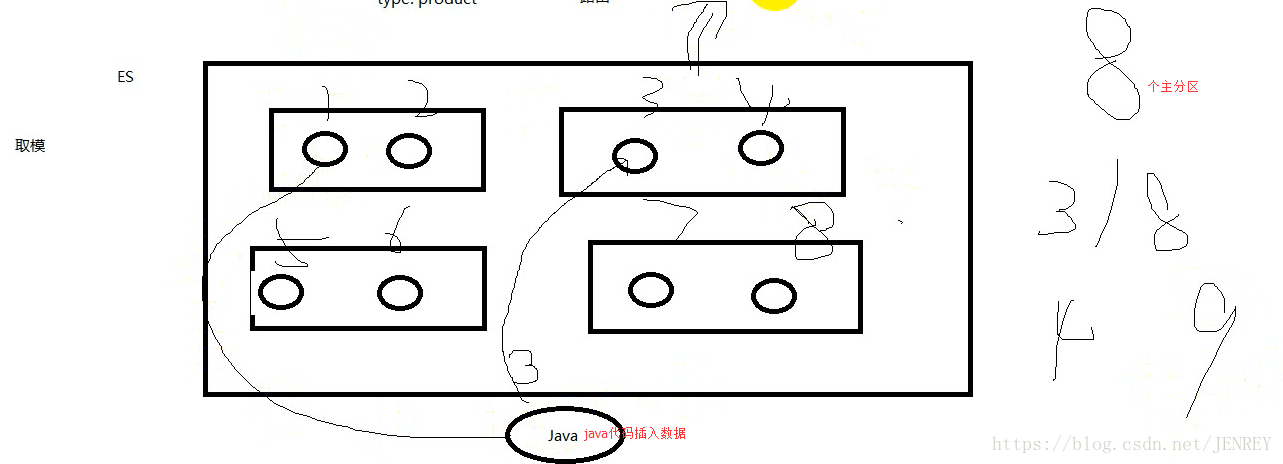
我們在創建一個index庫的時候,我們可以指定primary shard的數量,也可以指定replica的數量,如果不指定,那么默認primary shard=5 replica=1 所以 replica shard=5,過了一段時間發現數據量很大,我們primary shard不夠用了,那么這個時候想修改shard 的個數,能不能改成20個?答案:不能!!原來本應該插入到8的位置,結果插入到了9的位置,這樣計算查詢規則就錯了。所以主分片個數是不能修改的,但是副分片的個數是可以進行修改的。具體怎么完成的那是ES內部的事情,我們先不用考慮。我們寫了段java的代碼插入數據到主分片里面去了。具體怎么插入的,插入到哪個主分片里面是不需要我們來管的。所以就是把這些功能給隱藏起來了。
如果真的遇見了這樣的事,再建一個庫,那個庫的分片是20,用代碼查詢出來再導入到這個庫中,只能用這個方法
總結:我們操作的時候很輕松的就把數據存入到我們的ES里面了。存入的時候我們并不關心,數據存到哪個分片里面去。
2)集群的發現機制
我們做過一個實驗,一開始我們只啟動了一個ES的節點,這個時候這個ES的狀態是yellow,后來我們又啟動了一個ES節點,發現顏色變成了green,這說明,我們后面啟動的這個節點,也自動加入了這個集群。那么這個機制就是集群的發現機制。對于我們也是隱藏起來了。我們沒必要知道
3)shard 會進行負載均衡
Hbase中如果你新加入了一個Hbase節點,不會自動的進行負載均衡,需要執行一個命令
但是ES不一樣。只要你加入了一個節點,會自動幫你進行負載均衡
11.ES集群的擴容問題
擴容分為:垂直和水平擴容
我們之前的大數據技術都是分布式的部署在集群上面的。如果我們的資源不夠用了,這個時候就涉及到了擴容,我們是垂直擴容還是水平擴容呢?
假設我們每個節點能存儲1T的數據,現在我們要存儲5T的數據,
垂直擴容就是把其中的一臺換了,換成性能更強的節點。有可能一臺節點就能存5T。
水平擴容就是新加服務器直到能存下來5T的數據,我們一般都是用水平擴容,比如1T是1萬。5臺5萬,但是單臺5T的價錢可能是50萬。所以我們幾乎不太可能用這種方式。
但是可能那么namenode節點可能是采用垂直擴容
12.對等式架構
在分布式的技術里面。我們大多都是主從式架構
ES是對等式的架構。ES里面也有master節點一說。但是我們不太關心。只需要在配置文件中指定一下讓哪幾個節點有機會成為主節點。
ES中master的作用
1)管理集群的元數據,比如說索引的創建,和刪除等等
2)集群里面master也是自動選舉的。
看到這里有個疑問這不也是主從式架構么?為什么叫對等式架構呢?
HDFS是主從式架構,有namenode和datanode,我們無論是上傳數據也好還是下載數據也好都要跟namenode進行交互,交互完才能到datanode中,但是我們的ES無論上傳和下載數據也好,我們不需要跟master進行交互。節點之間的關系都是對等的,每個節點都可以進行接收請求和響應請求。
在ES中,我們開發好了java代碼要跟ES進行交互。他會隨意找一臺節點,但是這臺節點不一定有我們要查詢的數據,但是我們不知道,ES節點是知道的,每個ES里面都知道其他的數據存在哪,ES的節點會自動幫你把請求發到要查詢數據的節點上。這樣就真的查詢出來了。而我們隨意找的這個節點叫做協調節點,真正數據存放的節點會把數據返回給協調節點。協調節點再給我們java的代碼
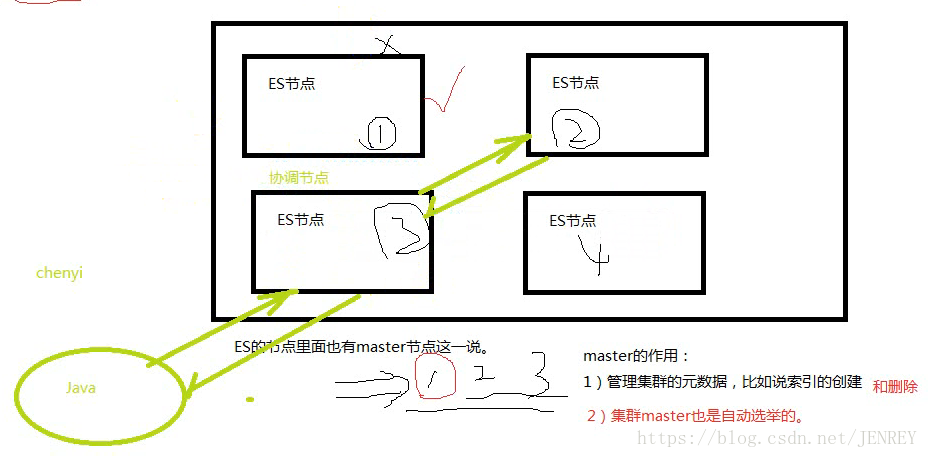
每一個節點都可以接受和相應請求。如果隨機找的剛好是數據所在的節點,那么這個節點即是協調節點又是響應節點。
13.ES的primary shard和replica shard
1)index可以包含多個type,同樣一個index下面也可以有多個shard
2)在ES里面每個shard就是最小的一個工作單元,承載了部分數據
3)如果在ES集群里面增加或減少節點,shard會自動的實現負載均衡
4)primary shard樂意進行讀和寫,replica shard負責讀
5)primary shard在創建index的時候就固定了,不能修改了。
6)默認創建一個index的時候,primary shard的數量是5,replica的數量是1,也就是說默認情況下有10個shard,其中有5個primary shard,5個是replica shard
7)primary shard和自己的replica shard是不能在同一臺服務器上的。
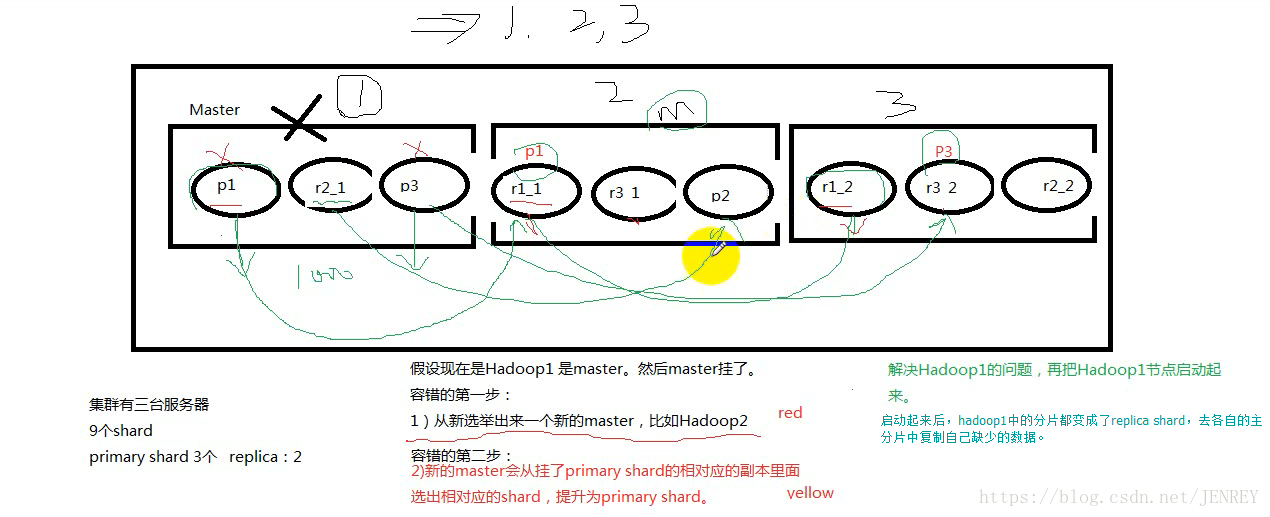
14.ES的容錯機制
1)master的選舉
2)replica的容錯
3)數據恢復
15.自動生成ID號
下圖是指定ID號的方式
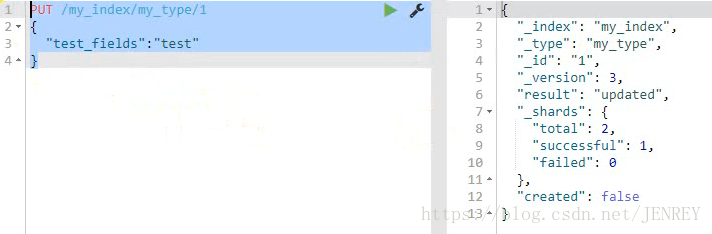

下圖是自動生成ID號
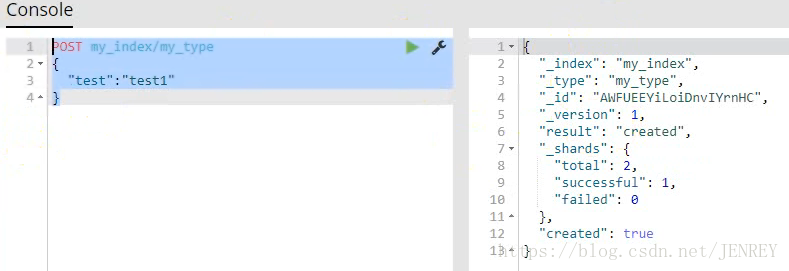

16.version之悲觀鎖和樂觀鎖
悲觀鎖:很悲觀,自己操作的時候別的線程就不能進行操作。所以在電商的情況下體驗性很不好,但是不容易出錯
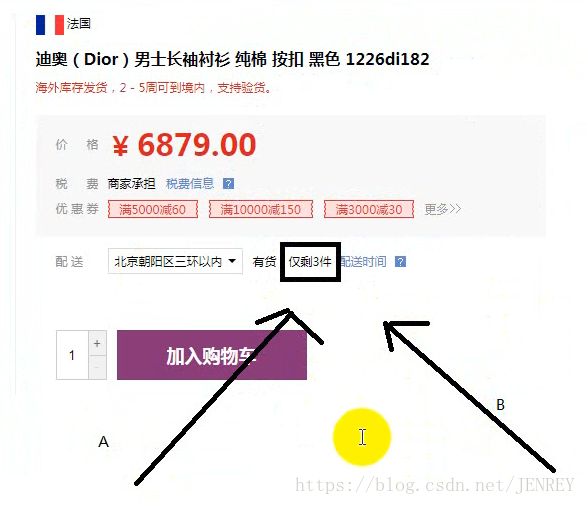
樂觀鎖:很樂觀,因為現在剩3件了,假設version號是5,A,B線程同時進行訪問操作,AB線程拿到的都是3件,version都是5,A線程先購買了一件就是3-1=2 ,然后A線程拿著2和version號5去更新數據,發現version是5就把3件更新為2件,同時version變成了6;然后B線程買了一件就是3-1=2 然后拿著2和version號5去更新,發現version號不匹配,此時重新獲取一下version號和僅剩的件數2,然后2-1=1,然后拿著1和version號6去更新數據,發現version對上了。此時更新成功。
17.用java實現對ES的增刪改查
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/38476.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/38476.shtml 英文地址,請注明出處:http://en.pswp.cn/news/38476.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

【佳佳怪文獻分享】MVFusion: 利用語義對齊的多視角 3D 物體檢測雷達和相機融合

kubernetes企業級高可用部署

強制Edge或Chrome使用獨立顯卡【WIN10】

Linux/centos上如何配置管理NFS服務器?

LAXCUS如何通過技術創新管理數千臺服務器

Jtti:Windows server如何備份與還原注冊表

企業數據庫遭到360后綴勒索病毒攻擊,360勒索病毒解密
)
代理模式(Java實現)

threejs使用gui改變相機的參數
如何轉換為VOC格式數據集(.xml))
YOLO格式數據集(.txt)如何轉換為VOC格式數據集(.xml)


Medical Isolated Power Supply System in Angola

【UE4 RTS】07-Camera Boundaries

【TypeScript】this指向,this內置組件

華為OD機試-字符串序列判定

Docker容器:docker基礎及安裝

【科研論文配圖繪制】task1 掌握科研繪圖的基本知識

機器學習筆記 - 基于C++的??深度學習 三、實現成本函數

【Go 基礎篇】Go語言指針解析:深入理解內存與引用的奧秘
登錄態校驗Directive)