目錄
1、Kubernetes高可用項目介紹
2、項目架構設計
2.1、項目主機信息
2.2、項目架構圖
1、Kubernetes高可用項目介紹
2、項目架構設計
2.1、項目主機信息
2.2、項目架構圖
2.3、項目實施思路
3、項目實施過程
3.1、系統初始化
3.2、配置部署keepalived服務
3.3、配置部署haproxy服務
3.4、配置部署Docker服務
3.5、部署kubelet kubeadm kubectl工具
3.6、部署Kubernetes Master
3.6、部署Kubernetes Master
3.7、安裝集群網絡
3.8、添加master節點
3.9、加入Kubernetes Node
3.10、測試Kubernetes集群
4、項目總結
1、Kubernetes高可用項目介紹
單master節點的可靠性不高,并不適合實際的生產環境。Kubernetes 高可用集群是保證 Master 節點中 API Server 服務的高可用。API Server 提供了 Kubernetes 各類資源對象增刪改查的唯一訪問入口,是整個 Kubernetes 系統的數據總線和數據中心。采用負載均衡(Load Balance)連接多個 Master 節點可以提供穩定容器云業務。
2、項目架構設計
2.1、項目主機信息
準備6臺虛擬機,3臺master節點,3臺node節點,保證master節點數為>=3的奇數。
硬件:2核CPU+、2G內存+、硬盤20G+
網絡:所有機器網絡互通、可以訪問外網
| 操作系統 | IP地址 | 角色 | 主機名 |
| CentOS7-x86-64 | 192.168.200.111 | master | k8s-master1 |
| CentOS7-x86-64 | 192.168.200.112 | master | k8s-master2 |
| CentOS7-x86-64 | 192.168.200.113 | master | k8s-master3 |
| CentOS7-x86-64 | 192.168.200.114 | node | k8s-node1 |
| CentOS7-x86-64 | 192.168.200.115 | node | k8s-node2 |
| CentOS7-x86-64 | 192.168.200.116 | node | k8s-node3 |
| 192.168.200.154 | VIP | master.k8s.io |
2.2、項目架構圖
多master節點負載均衡的kubernetes集群。官網給出了兩種拓撲結構:堆疊control plane node和external etcd node,本文基于第一種拓撲結構進行搭建。
1、Kubernetes高可用項目介紹
單master節點的可靠性不高,并不適合實際的生產環境。Kubernetes 高可用集群是保證 Master 節點中 API Server 服務的高可用。API Server 提供了 Kubernetes 各類資源對象增刪改查的唯一訪問入口,是整個 Kubernetes 系統的數據總線和數據中心。采用負載均衡(Load Balance)連接多個 Master 節點可以提供穩定容器云業務。
2、項目架構設計
2.1、項目主機信息
準備6臺虛擬機,3臺master節點,3臺node節點,保證master節點數為>=3的奇數。
硬件:2核CPU+、2G內存+、硬盤20G+、開啟虛擬化
網絡:所有機器網絡互通、可以訪問外網
| 操作系統 | IP地址 | 角色 | 主機名 |
| CentOS7-x86-64 | 192.168.147.137 | master | k8s-master1 |
| CentOS7-x86-64 | 192.168.147.139 | master | k8s-master2 |
| CentOS7-x86-64 | 192.168.147.140 | master | k8s-master3 |
| CentOS7-x86-64 | 192.168.147.141 | node | k8s-node1 |
| CentOS7-x86-64 | 192.168.147.142 | node | k8s-node2 |
| CentOS7-x86-64 | 192.168.147.143 | node | k8s-node3 |
| 192.168.147.154 | VIP | master.k8s.io |
2.2、項目架構圖
多master節點負載均衡的kubernetes集群。官網給出了兩種拓撲結構:堆疊control plane node和external etcd node,本文基于第一種拓撲結構進行搭建。
?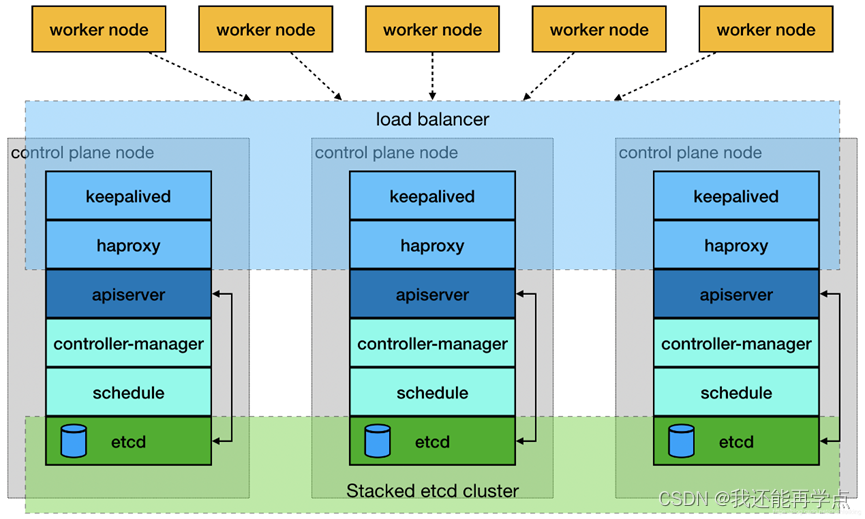
?(堆疊control plane node)

?(external etcd node)
2.3、項目實施思路
master節點需要部署etcd、apiserver、controller-manager、scheduler這4種服務,其中etcd、controller-manager、scheduler這三種服務kubernetes自身已經實現了高可用,在多master節點的情況下,每個master節點都會啟動這三種服務,同一時間只有一個生效。因此要實現kubernetes的高可用,只需要apiserver服務高可用。
keepalived是一種高性能的服務器高可用或熱備解決方案,可以用來防止服務器單點故障導致服務中斷的問題。keepalived使用主備模式,至少需要兩臺服務器才能正常工作。比如keepalived將三臺服務器搭建成一個集群,對外提供一個唯一IP,正常情況下只有一臺服務器上可以看到這個IP的虛擬網卡。如果這臺服務異常,那么keepalived會立即將IP移動到剩下的兩臺服務器中的一臺上,使得IP可以正常使用。
haproxy是一款提供高可用性、負載均衡以及基于TCP(第四層)和HTTP(第七層)應用的代理軟件,支持虛擬主機,它是免費、快速并且可靠的一種解決方案。使用haproxy負載均衡后端的apiserver服務,達到apiserver服務高可用的目的。
本文使用的keepalived+haproxy方案,使用keepalived對外提供穩定的入口,使用haproxy對內均衡負載。因為haproxy運行在master節點上,當master節點異常后,haproxy服務也會停止,為了避免這種情況,我們在每一臺master節點都部署haproxy服務,達到haproxy服務高可用的目的。由于多master節點會出現投票競選的問題,因此master節點的數據最好是單數,避免票數相同的情況。
3、項目實施過程
3.1、系統初始化
所有主機:
關閉防火墻、selinux、swap
[root@client2 ~]# systemctl stop firewalld
[root@client2 ~]# systemctl disable firewalld
Removed symlink /etc/systemd/system/multi-user.target.wants/firewalld.service.
Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service.
[root@client2 ~]# sed -i 's/enforcing/disabled/' /etc/selinux/config
[root@client2 ~]# setenforce 0
[root@client2 ~]# swapoff -a
[root@client2 ~]# sed -ri 's/.*swap.*/#&/' /etc/fstab
修改主機名(根據主機角色不同,做相應修改)
[root@client2 ~]# hostnamectl set-hostname k8s-master1
[root@client2 ~]# hostnamectl set-hostname k8s-master2
[root@client2 ~]# hostnamectl set-hostname k8s-master3
[root@k8s-node1 ~]# hostnamectl set-hostname k8s-node1
[root@k8s-node1 ~]# hostnamectl set-hostname k8s-node2
[root@k8s-node1 ~]# hostnamectl set-hostname k8s-node3[root@k8s-node1 ~]# vim /etc/hosts
192.168.147.137 master 1.k8s.io k8s-master1
192.168.147.139 master 2.k8s.io k8s-master2
192.168.147.140 master 3.k8s.io k8s-master3
192.168.147.141 node1.k8s.io k8s-node1
192.168.147.142 node2.k8s.io k8s-node2
192.168.147.143 node3.k8s.io k8s-node3
192.168.147.154 master.k8s.io k8s-vip
[root@k8s-node1 ~]# scp /etc/hosts 192.168.147.137:/etc/hosts
[root@k8s-node1 ~]# scp /etc/hosts 192.168.147.139:/etc/hosts
[root@k8s-node1 ~]# scp /etc/hosts 192.168.147.140:/etc/hosts
[root@k8s-node1 ~]# scp /etc/hosts 192.168.147.142:/etc/hosts
[root@k8s-node1 ~]# scp /etc/hosts 192.168.147.143:/etc/hosts
將橋接的IPv4流量傳遞到iptables的鏈
[root@k8s-master1 ~]# cat << EOF >> /etc/sysctl.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
[root@k8s-master1 ~]# modprobe br_netfilter
[root@k8s-master1 ~]# sysctl -p
時間同步
[root@k8s-master1 ~]# yum install ntpdate -y
[root@k8s-master1 ~]# ntpdate time.windows.com
3.2、配置部署keepalived服務
安裝Keepalived(所有master主機)
[root@k8s-master1 ~]# yum install -y keepalivedk8s-master1節點配置?
[root@k8s-master1 ~]# cat > /etc/keepalived/keepalived.conf <<EOF
! Configuration File for keepalived
global_defs {router_id k8s
}
vrrp_script check_haproxy {script "killall -0 haproxy"interval 3weight -2fall 10rise 2
}
vrrp_instance VI_1 {state MASTERinterface ens33virtual_router_id 51priority 100advert_int 1authentication {auth_type PASSauth_pass 1111}
virtual_ipaddress {192.168.147.154
}
track_script {check_haproxy
}
}
EOF
k8s-master2節點配置
[root@k8s-master2 ~]# cat > /etc/keepalived/keepalived.conf <<EOF
! Configuration File for keepalived
global_defs {router_id k8s
}
vrrp_script check_haproxy {script "killall -0 haproxy"interval 3weight -2fall 10rise 2
}
vrrp_instance VI_1 {state BACKUPinterface ens33virtual_router_id 51priority 90adver_int 1authentication {auth_type PASSauth_pass 1111}
virtual_ipaddress {192.168.147.154
}
track_script {check_haproxy
}
}
EOF
?k8s-master3節點配置
[root@k8s-master3 ~]# cat > /etc/keepalived/keepalived.conf <<EOF
! Configuration File for keepalived
global_defs {router_id k8s
}
vrrp_script check_haproxy {script "killall -0 haproxy"interval 3weight -2fall 10rise 2
}
vrrp_instance VI_1 {state BACKUPinterface ens33virtual_router_id 51priority 80adver_int 1authentication {auth_type PASSauth_pass 1111}
virtual_ipaddress {192.168.147.154
}
track_script {check_haproxy
}
}
EOF
啟動和檢查
所有master節點都要執行
[root@k8s-master1 ~]# systemctl start keepalived
[root@k8s-master1 ~]# systemctl enable keepalived
Created symlink from /etc/systemd/system/multi-user.target.wants/keepalived.service to /usr/lib/systemd/system/keepalived.service.
?查看啟動狀態
[root@k8s-master1 ~]# systemctl status keepalived
● keepalived.service - LVS and VRRP High Availability MonitorLoaded: loaded (/usr/lib/systemd/system/keepalived.service; enabled; vendor preset: disabled)Active: active (running) since 二 2023-08-15 13:38:02 CST; 10s agoMain PID: 18740 (keepalived)CGroup: /system.slice/keepalived.service├─18740 /usr/sbin/keepalived -D├─18741 /usr/sbin/keepalived -D└─18742 /usr/sbin/keepalived -D8月 15 13:38:04 k8s-master1 Keepalived_vrrp[18742]: Sending gratuitous ARP on ens33 for 192.168.147.154
8月 15 13:38:04 k8s-master1 Keepalived_vrrp[18742]: Sending gratuitous ARP on ens33 for 192.168.147.154
8月 15 13:38:04 k8s-master1 Keepalived_vrrp[18742]: Sending gratuitous ARP on ens33 for 192.168.147.154
8月 15 13:38:04 k8s-master1 Keepalived_vrrp[18742]: Sending gratuitous ARP on ens33 for 192.168.147.154
8月 15 13:38:09 k8s-master1 Keepalived_vrrp[18742]: Sending gratuitous ARP on ens33 for 192.168.147.154
8月 15 13:38:09 k8s-master1 Keepalived_vrrp[18742]: VRRP_Instance(VI_1) Sending/queueing gratuitous ARPs on ens33 f....154
8月 15 13:38:09 k8s-master1 Keepalived_vrrp[18742]: Sending gratuitous ARP on ens33 for 192.168.147.154
8月 15 13:38:09 k8s-master1 Keepalived_vrrp[18742]: Sending gratuitous ARP on ens33 for 192.168.147.154
8月 15 13:38:09 k8s-master1 Keepalived_vrrp[18742]: Sending gratuitous ARP on ens33 for 192.168.147.154
8月 15 13:38:09 k8s-master1 Keepalived_vrrp[18742]: Sending gratuitous ARP on ens33 for 192.168.147.154
Hint: Some lines were ellipsized, use -l to show in full.
啟動完成后在master1查看網絡信息
[root@k8s-master1 ~]# ip a s ens33
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000link/ether 00:0c:29:c7:3f:d6 brd ff:ff:ff:ff:ff:ffinet 192.168.147.137/24 brd 192.168.147.255 scope global noprefixroute ens33valid_lft forever preferred_lft foreverinet 192.168.147.154/32 scope global ens33valid_lft forever preferred_lft foreverinet6 fe80::bd67:1ba:506d:b021/64 scope link tentative noprefixroute dadfailed valid_lft forever preferred_lft foreverinet6 fe80::146a:2496:1fdc:4014/64 scope link tentative noprefixroute dadfailed valid_lft forever preferred_lft foreverinet6 fe80::5d98:c5e3:98f8:181/64 scope link tentative noprefixroute dadfailed 3.3、配置部署haproxy服務
所有master主機安裝haproxy
[root@k8s-master1 ~]# yum install -y haproxy
每臺master節點中的配置均相同,配置中聲明了后端代理的每個master節點服務器,指定了haproxy的端口為16443,因此16443端口為集群的入口。
[root@k8s-master1 ~]# cat > /etc/haproxy/haproxy.cfg << EOF
> #-------------------------------
> # Global settings
> #-------------------------------
> global
> log 127.0.0.1 local2
> chroot /var/lib/haproxy
> pidfile /var/run/haproxy.pid
> maxconn 4000
> user haproxy
> group haproxy
> daemon
> stats socket /var/lib/haproxy/stats
> #--------------------------------
> # common defaults that all the 'listen' and 'backend' sections will
> # usr if not designated in their block
> #--------------------------------
> defaults
> mode http
> log global
> option httplog
> option dontlognull
> option http-server-close
> option forwardfor except 127.0.0.0/8
> option redispatch
> retries 3
> timeout http-request 10s
> timeout queue 1m
> timeout connect 10s
> timeout client 1m
> timeout server 1m
> timeout http-keep-alive 10s
> timeout check 10s
> maxconn 3000
> #--------------------------------
> # kubernetes apiserver frontend which proxys to the backends
> #--------------------------------
> frontend kubernetes-apiserver
> mode tcp
> bind *:16443
> option tcplog
> default_backend kubernetes-apiserver
> #---------------------------------
> #round robin balancing between the various backends
> #---------------------------------
> backend kubernetes-apiserver
> mode tcp
> balance roundrobin
> server master1.k8s.io 192.168.147.137:6443 check
> server master2.k8s.io 192.168.147.139:6443 check
> server master3.k8s.io 192.168.147.140:6443 check
> #---------------------------------
> # collection haproxy statistics message
> #---------------------------------
> listen stats
> bind *:1080
> stats auth admin:awesomePassword
> stats refresh 5s
> stats realm HAProxy\ Statistics
> stats uri /admin?stats
> EOF
啟動和檢查
所有master節點都要執行
[root@k8s-master1 ~]# systemctl start haproxy
[root@k8s-master1 ~]# systemctl enable haproxy
查看啟動狀態
[root@k8s-master1 ~]# systemctl status haproxy
● haproxy.service - HAProxy Load BalancerLoaded: loaded (/usr/lib/systemd/system/haproxy.service; enabled; vendor preset: disabled)Active: active (running) since 二 2023-08-15 13:43:11 CST; 15s agoMain PID: 18812 (haproxy-systemd)CGroup: /system.slice/haproxy.service├─18812 /usr/sbin/haproxy-systemd-wrapper -f /etc/haproxy/haproxy.cfg -p /run/haproxy.pid├─18814 /usr/sbin/haproxy -f /etc/haproxy/haproxy.cfg -p /run/haproxy.pid -Ds└─18818 /usr/sbin/haproxy -f /etc/haproxy/haproxy.cfg -p /run/haproxy.pid -Ds8月 15 13:43:11 k8s-master1 systemd[1]: Started HAProxy Load Balancer.
8月 15 13:43:11 k8s-master1 haproxy-systemd-wrapper[18812]: haproxy-systemd-wrapper: executing /usr/sbin/haproxy -f... -Ds
8月 15 13:43:11 k8s-master1 haproxy-systemd-wrapper[18812]: [WARNING] 226/134311 (18814) : config : 'option forward...ode.
8月 15 13:43:11 k8s-master1 haproxy-systemd-wrapper[18812]: [WARNING] 226/134311 (18814) : config : 'option forward...ode.
Hint: Some lines were ellipsized, use -l to show in full.
檢查端口
[root@k8s-master1 ~]# netstat -lntup|grep haproxy
tcp 0 0 0.0.0.0:1080 0.0.0.0:* LISTEN 18818/haproxy
tcp 0 0 0.0.0.0:16443 0.0.0.0:* LISTEN 18818/haproxy
udp 0 0 0.0.0.0:40763 0.0.0.0:* 18814/haproxy 3.4、配置部署Docker服務
所有主機上分別部署 Docker 環境,因為 Kubernetes 對容器的編排需要 Docker 的支持。
[root@k8s-master ~]# wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
[root@k8s-master ~]# yum install -y yum-utils device-mapper-persistent-data lvm2
使用 YUM 方式安裝 Docker 時,推薦使用阿里的 YUM 源
[root@k8s-master ~]# yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
[root@k8s-master ~]# yum clean all && yum makecache fast [root@k8s-master ~]# yum -y install docker-ce
[root@k8s-master ~]# systemctl start docker
[root@k8s-master ~]# systemctl enable docker
鏡像加速器(所有主機配置)
[root@k8s-master ~]# cat << END > /etc/docker/daemon.json
{"registry-mirrors":[ "https://nyakyfun.mirror.aliyuncs.com" ]
}
END
[root@k8s-master ~]# systemctl daemon-reload
[root@k8s-master ~]# systemctl restart docker
3.5、部署kubelet kubeadm kubectl工具
使用 YUM 方式安裝Kubernetes時,推薦使用阿里的yum。
所有主機配置
[root@k8s-master ~]# cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpghttps://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF[root@k8s-master ~]# ls /etc/yum.repos.d/
[root@k8s-node3 ~]# ls /etc/yum.repos.d
backup CentOS-Base.repo CentOS-Media.repo docker-ce.repo kubernetes.repo
安裝kubelet kubeadm kubectl
所有主機配置
[root@k8s-master ~]# yum install -y kubelet-1.20.0 kubeadm-1.20.0 kubectl-1.20.0
[root@k8s-master ~]# systemctl enable kubelet
3.6、部署Kubernetes Master
在具有vip的master上操作。此處的vip節點為k8s-master1。
創建kubeadm-config.yaml文件
[root@k8s-master1 ~]# cat > kubeadm-config.yaml << EOF
apiServer:certSANs:- k8s-master1- k8s-master2- k8s-master3- master.k8s.io- 192.168.147.137- 192.168.147.139- 192.168.147.140- 192.168.147.154- 127.0.0.1extraArgs:authorization-mode: Node,RBACtimeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta1
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controlPlaneEndpoint: "master.k8s.io:6443"
controllerManager: {}
dns:type: CoreDNS
etcd:local:dataDir: /var/lib/etcd
imageRepository: registry.aliyuncs.com/google_containers
kind: ClusterConfiguration
kubernetesVersion: v1.20.0
networking:dnsDomain: cluster.localpodSubnet: 10.244.0.0/16serviceSubnet: 10.1.0.0/16
scheduler: {}
EOF
3.6、部署Kubernetes Master
在具有vip的master上操作。此處的vip節點為k8s-master1。
創建kubeadm-config.yaml文件
[root@k8s-master1 ~]# cat > kubeadm-config.yaml << EOF
apiServer:certSANs:- k8s-master1- k8s-master2- k8s-master3- master.k8s.io- 192.168.147.137- 192.168.147.139- 192.168.147.140- 192.168.147.154- 127.0.0.1extraArgs:authorization-mode: Node,RBACtimeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta1
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controlPlaneEndpoint: "master.k8s.io:6443"
controllerManager: {}
dns:type: CoreDNS
etcd:local:dataDir: /var/lib/etcd
imageRepository: registry.aliyuncs.com/google_containers
kind: ClusterConfiguration
kubernetesVersion: v1.20.0
networking:dnsDomain: cluster.localpodSubnet: 10.244.0.0/16serviceSubnet: 10.1.0.0/16
scheduler: {}
EOF
查看所需鏡像信息
[root@k8s-master1 ~]# kubeadm config images list --config kubeadm-config.yaml
W0815 13:55:35.933304 19444 common.go:77] your configuration file uses a deprecated API spec: "kubeadm.k8s.io/v1beta1". Please use 'kubeadm config migrate --old-config old.yaml --new-config new.yaml', which will write the new, similar spec using a newer API version.
registry.aliyuncs.com/google_containers/kube-apiserver:v1.20.0
registry.aliyuncs.com/google_containers/kube-controller-manager:v1.20.0
registry.aliyuncs.com/google_containers/kube-scheduler:v1.20.0
registry.aliyuncs.com/google_containers/kube-proxy:v1.20.0
registry.aliyuncs.com/google_containers/pause:3.2
registry.aliyuncs.com/google_containers/etcd:3.4.13-0
registry.aliyuncs.com/google_containers/coredns:1.7.0
上傳k8s所需的鏡像并導入(所有master主機)
[root@k8s-master1 ~]# mkdir master
[root@k8s-master1 ~]# cd master/
[root@k8s-master1 master]# rz -E
rz waiting to receive.
[root@k8s-master1 master]# ls
coredns_1.7.0.tar kube-apiserver_v1.20.0.tar kube-proxy_v1.20.0.tar pause_3.2.tar
etcd_3.4.13-0.tar kube-controller-manager_v1.20.0.tar kube-scheduler_v1.20.0.tar
[root@k8s-master1 master]# ls | while read line
> do
> docker load < $line
> done
225df95e717c: Loading layer 336.4kB/336.4kB
96d17b0b58a7: Loading layer 45.02MB/45.02MB[root@k8s-master1 ~]# scp master/* 192.168.147.139:/root/master
[root@k8s-master1 ~]# scp master/* 192.168.147.140:/root/master
[root@k8s-master2/3 master]# ls | while read line
> do
> docker load < $line
> done使用kubeadm命令初始化k8s
[root@k8s-master1 ~]# kubeadm init --config kubeadm-config.yamlYour Kubernetes control-plane has initialized successfully!To start using your cluster, you need to run the following as a regular user:mkdir -p $HOME/.kubesudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/configsudo chown $(id -u):$(id -g) $HOME/.kube/configAlternatively, if you are the root user, you can run:export KUBECONFIG=/etc/kubernetes/admin.confYou should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:https://kubernetes.io/docs/concepts/cluster-administration/addons/You can now join any number of control-plane nodes by copying certificate authorities
and service account keys on each node and then running the following as root:kubeadm join master.k8s.io:6443 --token zus2jc.brtsxszpyv03a57j \--discovery-token-ca-cert-hash sha256:20a551796d33309f20ad7579c710ea766ef39b64b98c37a4a4029a903f23300a \--control-plane Then you can join any number of worker nodes by running the following on each as root:kubeadm join master.k8s.io:6443 --token zus2jc.brtsxszpyv03a57j \--discovery-token-ca-cert-hash sha256:20a551796d33309f20ad7579c710ea766ef39b64b98c37a4a4029a903f23300如果——初始化中的錯誤:
[ERROR FileContent--proc-sys-net-bridge-bridge-nf-call-iptables]: /proc/sys/net/bridge/bridge-nf-call-iptables contents are not set to 1執行以下命令后重新執行初始化命令echo "1" >/proc/sys/net/bridge/bridge-nf-call-iptables根據初始化的結果操作
[root@k8s-master1 ~]# mkdir -p $HOME/.kube
[root@k8s-master1 ~]# sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[root@k8s-master1 ~]# sudo chown $(id -u):$(id -g) $HOME/.kube/config
查看集群狀態
[root@k8s-master1 ~]# kubectl get cs
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
scheduler Unhealthy Get "http://127.0.0.1:10251/healthz": dial tcp 127.0.0.1:10251: connect: connection refused
controller-manager Unhealthy Get "http://127.0.0.1:10252/healthz": dial tcp 127.0.0.1:10252: connect: connection refused
etcd-0 Healthy {"health":"true"} 注意:出現以上錯誤情況,是因為/etc/kubernetes/manifests/下的kube-controller-manager.yaml和kube-scheduler.yaml設置的默認端口為0導致的,解決方式是注釋掉對應的port即可
修改kube-controller-manager.yaml文件、kube-scheduler.yaml文件
[root@k8s-master1 ~]# vim /etc/kubernetes/manifests/kube-controller-manager.yaml - --leader-elect=true
# - --port=0- --requestheader-client-ca-file=/etc/kubernetes/pki/front-proxy-ca.crt[root@k8s-master1 ~]# vim /etc/kubernetes/manifests/kube-scheduler.yaml - --leader-elect=true
# - --port=0image: registry.aliyuncs.com/google_containers/kube-scheduler:v1.20.0
查看集群狀態
[root@k8s-master1 ~]# kubectl get cs
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
controller-manager Healthy ok
scheduler Healthy ok
etcd-0 Healthy {"health":"true"}查看pod信息
[root@k8s-master1 ~]# kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-7f89b7bc75-hdvw8 0/1 Pending 0 5m51s
coredns-7f89b7bc75-jbn4h 0/1 Pending 0 5m51s
etcd-k8s-master1 1/1 Running 0 6m
kube-apiserver-k8s-master1 1/1 Running 0 6m
kube-controller-manager-k8s-master1 1/1 Running 0 2m56s
kube-proxy-x25rz 1/1 Running 0 5m51s
kube-scheduler-k8s-master1 1/1 Running 0 2m17s
查看節點信息
[root@k8s-master1 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master1 NotReady control-plane,master 6m34s v1.20.0
3.7、安裝集群網絡
在k8s-master1節點執行
[root@k8s-master1 ~]# rz -E
rz waiting to receive.
[root@k8s-master1 ~]# ll
總用量 52512
-rw-r--r--. 1 root root 53746688 12月 16 2020 flannel_v0.12.0-amd64.tar
-rw-r--r--. 1 root root 14366 11月 13 2020 kube-flannel.yml
[root@k8s-master1 ~]# docker load < flannel_v0.12.0-amd64.tar
256a7af3acb1: Loading layer 5.844MB/5.844MB
d572e5d9d39b: Loading layer 10.37MB/10.37MB
57c10be5852f: Loading layer 2.249MB/2.249MB
7412f8eefb77: Loading layer 35.26MB/35.26MB
05116c9ff7bf: Loading layer 5.12kB/5.12kB
Loaded image: quay.io/coreos/flannel:v0.12.0-amd64
[root@k8s-master1 ~]# kubectl apply -f kube-flannel.yml
podsecuritypolicy.policy/psp.flannel.unprivileged created
Warning: rbac.authorization.k8s.io/v1beta1 ClusterRole is deprecated in v1.17+, unavailable in v1.22+; use rbac.authorization.k8s.io/v1 ClusterRole
clusterrole.rbac.authorization.k8s.io/flannel created
Warning: rbac.authorization.k8s.io/v1beta1 ClusterRoleBinding is deprecated in v1.17+, unavailable in v1.22+; use rbac.authorization.k8s.io/v1 ClusterRoleBinding
clusterrolebinding.rbac.authorization.k8s.io/flannel created
serviceaccount/flannel created
configmap/kube-flannel-cfg created
daemonset.apps/kube-flannel-ds-amd64 created
daemonset.apps/kube-flannel-ds-arm64 created
daemonset.apps/kube-flannel-ds-arm created
daemonset.apps/kube-flannel-ds-ppc64le created
daemonset.apps/kube-flannel-ds-s390x created
再次查看節點信息:
[root@k8s-master1 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master1 NotReady control-plane,master 8m27s v1.20.0還是沒有變成Ready:下載cni網絡插件
[root@k8s-master1 ~]# tar xf cni-plugins-linux-amd64-v0.8.6.tgz
[root@k8s-master1 ~]# cp flannel /opt/cni/bin/
[root@k8s-master1 ~]# kubectl apply -f kube-flannel.yml
configmap/kube-flannel-cfg unchanged
daemonset.apps/kube-flannel-ds-amd64 unchanged
daemonset.apps/kube-flannel-ds-arm64 unchanged
daemonset.apps/kube-flannel-ds-arm unchanged
daemonset.apps/kube-flannel-ds-ppc64le unchanged
daemonset.apps/kube-flannel-ds-s390x unchanged
[root@k8s-master1 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master1 Ready control-plane,master 11m v1.20.0
3.8、添加master節點
在k8s-master2和k8s-master3節點創建文件夾
[root@k8s-master2 ~]# mkdir -p /etc/kubernetes/pki/etcd[root@k8s-master3 ~]# mkdir -p /etc/kubernetes/pki/etcd
在k8s-master1節點執行
從k8s-master1復制秘鑰和相關文件到k8s-master2和k8s-master3
[root@k8s-master1 ~]# scp /etc/kubernetes/admin.conf root@192.168.147.139:/etc/kubernetes
[root@k8s-master1 ~]# scp /etc/kubernetes/admin.conf root@192.168.147.140:/etc/kubernetes[root@k8s-master1 ~]# scp /etc/kubernetes/pki/{ca.*,sa.*,front-proxy-ca.*} root@192.168.147.139:/etc/kubernetes/pki
[root@k8s-master1 ~]# scp /etc/kubernetes/pki/{ca.*,sa.*,front-proxy-ca.*} root@192.168.147.140:/etc/kubernetes/pki[root@k8s-master1 ~]# scp /etc/kubernetes/pki/etcd/ca.* root@192.168.147.139:/etc/kubernetes/pki/etcd
[root@k8s-master1 ~]# scp /etc/kubernetes/pki/etcd/ca.* root@192.168.147.140:/etc/kubernetes/pki/etcd
將其他master節點加入集群
注意:kubeadm init生成的token有效期只有1天,生成不過期token
[root@k8s-master1 ~]# kubeadm token create --ttl 0 --print-join-command
kubeadm join master.k8s.io:6443 --token 4vd7c0.x8z96hhh4808n4fv --discovery-token-ca-cert-hash sha256:20a551796d33309f20ad7579c710ea766ef39b64b98c37a4a4029a903f23300a [root@k8s-master1 ~]# kubeadm token list
TOKEN TTL EXPIRES USAGES DESCRIPTION EXTRA GROUPS
p9u7gb.o9naimgqjauiuzr6 <forever> <never> authentication,signing <none> system:bootstrappers:kubeadm:default-node-token
xhfagw.6wkdnkdrd2rhkbe9 23h 2023-08-16T14:03:32+08:00 authentication,signing <none> system:bootstrappers:kubeadm:default-node-token
k8s-master2和k8s-master3都需要加入
[root@k8s-master3 master]# kubeadm join master.k8s.io:6443 --token zus2jc.brtsxszpyv03a57j --discovery-token-ca-cert-hash sha256:20a551796d33309f20ad7579c710ea766ef39b64b98c37a4a4029a903f23300a --control-plane [preflight] Running pre-flight checks[WARNING IsDockerSystemdCheck]: detected "cgroupfs" as the Docker cgroup driver. The recommended driver is "systemd". Please follow the guide at https://kubernetes.io/docs/setup/cri/[WARNING SystemVerification]: this Docker version is not on the list of validated versions: 24.0.5. Latest validated version: 19.03
[preflight] Reading configuration from the cluster...
[preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Starting the kubelet
[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap...This node has joined the cluster:
* Certificate signing request was sent to apiserver and a response was received.
* The Kubelet was informed of the new secure connection details.Run 'kubectl get nodes' on the control-plane to see this node join the cluster.[root@k8s-master3 master]# mkdir -p $HOME/.kube
[root@k8s-master3 master]# sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[root@k8s-master3 master]# sudo chown $(id -u):$(id -g) $HOME/.kube/config如果master2/3加入時報錯
[ERROR FileAvailable--etc-kubernetes-pki-ca.crt]: /etc/kubernetes/pki/ca.crt already exists?是一個錯誤消息,表示?/etc/kubernetes/pki/ca.crt?文件已經存在
直接刪除改文件,在執行命令即可
[root@k8s-master2 master]# rm -rf /etc/kubernetes/pki/ca.crtmaster2/3添加cni
[root@k8s-master3 master]# tar -xf cni-plugins-linux-amd64-v0.8.6.tgz
[root@k8s-master3 master]# rz -E
rz waiting to receive.
[root@k8s-master3 master]# cp flannel /opt/cni/bin/
[root@k8s-master3 master]# kubectl apply -f kube-flannel.yml
podsecuritypolicy.policy/psp.flannel.unprivileged configured
Warning: rbac.authorization.k8s.io/v1beta1 ClusterRole is deprecated in v1.17+, unavailable in v1.22+; use rbac.authorization.k8s.io/v1 ClusterRole
clusterrole.rbac.authorization.k8s.io/flannel unchanged
Warning: rbac.authorization.k8s.io/v1beta1 ClusterRoleBinding is deprecated in v1.17+, unavailable in v1.22+; use rbac.authorization.k8s.io/v1 ClusterRoleBinding
clusterrolebinding.rbac.authorization.k8s.io/flannel unchanged
serviceaccount/flannel unchanged
configmap/kube-flannel-cfg unchanged
daemonset.apps/kube-flannel-ds-amd64 unchanged
daemonset.apps/kube-flannel-ds-arm64 unchanged
daemonset.apps/kube-flannel-ds-arm unchanged
daemonset.apps/kube-flannel-ds-ppc64le unchanged
daemonset.apps/kube-flannel-ds-s390x unchanged
master1查看nodes
[root@k8s-master1 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master1 Ready control-plane,master 8m14s v1.20.0
k8s-master2 Ready control-plane,master 48s v1.20.0
k8s-master3 Ready control-plane,master 13s v1.20.0
3.9、加入Kubernetes Node
直接在node節點服務器上執行k8s-master1初始化成功后的消息即可:
[root@k8s-node3 ~]# kubeadm join master.k8s.io:6443 --token zus2jc.brtsxszpyv03a57j \
> --discovery-token-ca-cert-hash sha256:20a551796d33309f20ad7579c710ea766ef39b64b98c37a4a4029a903f23300a[root@k8s-node1 ~]# docker load < flannel_v0.12.0-amd64.tar
Loaded image: quay.io/coreos/flannel:v0.12.0-amd64添加cni 同master操作?查看節點信息
[root@k8s-master1 demo]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master1 Ready control-plane,master 45m v1.20.0
k8s-master2 Ready control-plane,master 37m v1.20.0
k8s-master3 Ready control-plane,master 37m v1.20.0
k8s-node1 Ready <none> 32m v1.20.0
k8s-node2 Ready <none> 31m v1.20.0
k8s-node3 Ready <none> 31m v1.20.03.10、測試Kubernetes集群
所有node主機導入測試鏡像
[root@k8s-node1 ~]# docker load < nginx-1.19.tar
[root@k8s-node1 ~]# docker tag nginx nginx:1.19.6
在Kubernetes集群中創建一個pod,驗證是否正常運行。
[root@k8s-master1 ~]# mkdir demo
[root@k8s-master1 ~]# cd demo
[root@k8s-master1 demo]# vim nginx-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:name: nginx-deploymentlabels:app: nginx
spec:replicas: 3selector: matchLabels:app: nginxtemplate:metadata:labels:app: nginxspec:containers:- name: nginximage: nginx:1.19.6ports:- containerPort: 80
創建完 Deployment 的資源清單之后,使用 create 執行資源清單來創建容器。通過 get pods 可以查看到 Pod 容器資源已經自動創建完成。
[root@k8s-master1 demo]# kubectl create -f nginx-deployment.yaml
deployment.apps/nginx-deployment created[root@k8s-master1 demo]# kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-deployment-76ccf9dd9d-dhcl8 1/1 Running 0 11m
nginx-deployment-76ccf9dd9d-psn8p 1/1 Running 0 11m
nginx-deployment-76ccf9dd9d-xllhp 1/1 Running 0 11m[root@k8s-master1 demo]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-deployme-596f5df7f-8mhzz 1/1 Running 0 5m10s 10.244.4.4 k8s-node3 <none> <none>
nginx-deployme-596f5df7f-ql7l7 1/1 Running 0 5m10s 10.244.4.3 k8s-node3 <none> <none>
nginx-deployme-596f5df7f-x6pgv 1/1 Running 0 5m10s 10.244.4.2 k8s-node3 <none> <none>
創建Service資源清單
在創建的 nginx-service 資源清單中,定義名稱為 nginx-service 的 Service、標簽選擇器為 app: nginx、type 為 NodePort 指明外部流量可以訪問內部容器。在 ports 中定義暴露的端口庫號列表,對外暴露訪問的端口是 80,容器內部的端口也是 80。
[root@k8s-master1 demo]# vim nginx-service.yaml
kind: Service
apiVersion: v1
metadata:name: nginx-service
spec:selector:app: nginxtype: NodePortports:- protocol: TCPport: 80
targetPort: 80[root@k8s-master1 demo]# kubectl create -f nginx-service.yaml
service/nginx-service created
[root@k8s-master1 demo]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.1.0.1 <none> 443/TCP 52m
nginx-service NodePort 10.1.39.231 <none> 80:31418/TCP 14s
[root@k8s-master1 demo]#
通過瀏覽器訪問nginx:http://master.k8s.io:31418 域名或者VIP地址
[root@k8s-master1 demo]# elinks --dump http://master.k8s.io:31418Welcome to nginx!If you see this page, the nginx web server is successfully installed andworking. Further configuration is required.For online documentation and support please refer to [1]nginx.org.Commercial support is available at [2]nginx.com.Thank you for using nginx.ReferencesVisible links1. http://nginx.org/2. http://nginx.com/
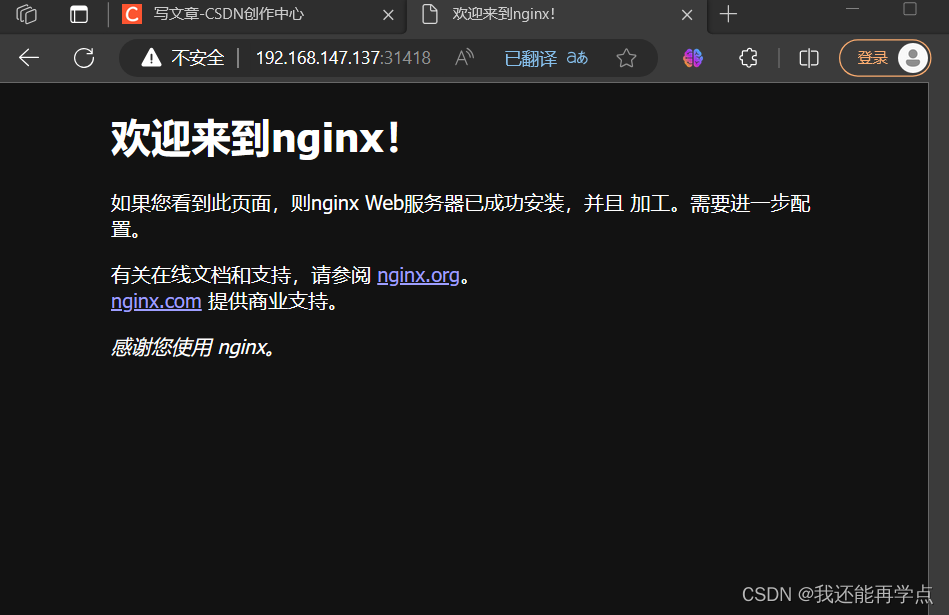
?
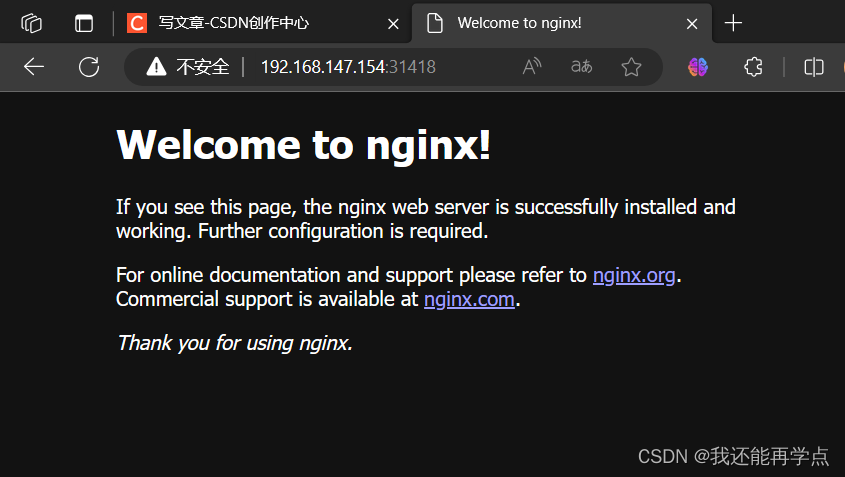
掛起k8s-master1節點,刷新頁面還是能訪問nginx,說明高可用集群部署成功。

?
?
檢查會發現VIP已經轉移到k8s-master2節點上
[root@k8s-master2 master]# ip a s ens33
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000link/ether 00:0c:29:ae:1d:c6 brd ff:ff:ff:ff:ff:ffinet 192.168.147.139/24 brd 192.168.147.255 scope global noprefixroute ens33valid_lft forever preferred_lft foreverinet 192.168.147.154/32 scope global ens33valid_lft forever preferred_lft foreverinet6 fe80::bd67:1ba:506d:b021/64 scope link tentative noprefixroute dadfailed valid_lft forever preferred_lft foreverinet6 fe80::146a:2496:1fdc:4014/64 scope link tentative noprefixroute dadfailed valid_lft forever preferred_lft foreverinet6 fe80::5d98:c5e3:98f8:181/64 scope link noprefixroute valid_lft forever preferred_lft forever至此Kubernetes企業級高可用環境完美實現。
4、項目總結
1、集群中只要有一個master節點正常運行就可以正常對外提供業務服務。
2、如果需要在master節點使用kubectl相關的命令,必須保證至少有2個master節點正常運行才可以使用,不然會有?Unable to connect to the server: net/http: TLS handshake timeout?這樣的錯誤。
3、Node節點故障時pod自動轉移:當pod所在的Node節點宕機后,根據 controller-manager的–pod-eviction-timeout 配置,默認是5分鐘,5分鐘后k8s會把pod狀態設置為unkown, 然后在其它節點啟動pod。當故障節點恢復后,k8s會刪除故障節點上面的unkown pod。如果你想立即強制遷移,可以用 kubectl drain nodename
4、為了保證集群的高可用性,建議master節點和node節點至少分別部署3臺及以上,且master節點應該部署基數個實例(3、5、7、9)。





)

如何轉換為VOC格式數據集(.xml))









登錄態校驗Directive)
)
