標題:MVFusion: Multi-View 3D Object Detection with Semantic-aligned Radar and Camera Fusion
作者:Zizhang Wu , Guilian Chen , Yuanzhu Gan , Lei Wang , Jian Pu
來源:2023 IEEE International Conference on Robotics and Automation (ICRA 2023)
這是佳佳怪分享的第2篇文章
摘要
多視角雷達-攝像頭融合三維物體檢測為自動駕駛提供了更遠的檢測范圍和更多有用的功能,尤其是在惡劣天氣下。目前的雷達-相機融合方法提供了多種將雷達信息與相機數據融合的設計。然而,這些融合方法通常采用多模態特征之間的直接串聯操作,忽略了雷達特征的語義一致性和模態之間的充分相關性。在本文中,我們提出了一種新穎的多視圖雷達-攝像機融合方法 MVFusion,以實現雷達特征的語義對齊并增強跨模態信息交互。為此,我們通過語義對齊雷達編碼器(SARE)將語義對齊注入雷達特征,生成圖像引導的雷達特征。然后,我們提出了雷達引導融合變換器(RGFT)來融合雷達和圖像特征,通過交叉注意機制從全局范圍加強兩種模態的相關性。大量實驗表明 MVFusion 在 nuScenes 數據集上實現了最先進的性能(51.7% NDS 和 45.3% mAP)。我們將在論文發表后公布我們的代碼和訓練有素的網絡。

圖 1. 基于攝像頭的方法 [13] 和我們的 MVFusion 的探測對比。(a) 圖像和雷達輸入,雷達點的顏色表示與雷達的距離。(b) 3D 檢測地面實況。? 基于攝像頭的方法 [13] 的結果,該方法未能檢測到遠處的汽車和近處的行人。(d) 我們的方法利用語義對齊的雷達信息進行了充分的雷達-攝像機融合,成功檢測到了丟失的汽車和行人。
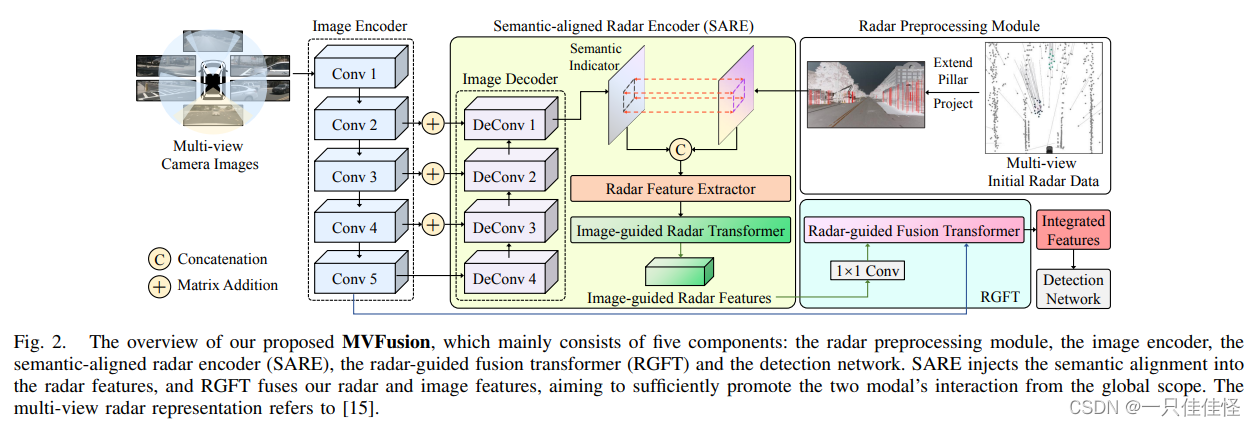
圖 2. 我們提出的 MVFusion 概覽,主要由五個部分組成:雷達預處理模塊、圖像編碼器、語義對齊雷達編碼器(SARE)、雷達引導融合變換器(RGFT)和檢測網絡。SARE 將語義配準注入雷達特征,而 RGFT 則 RGFT 融合雷達和圖像特征,旨在從全局范圍充分促進兩種模態的互動。多視角雷達表示法參考了文獻[15]。
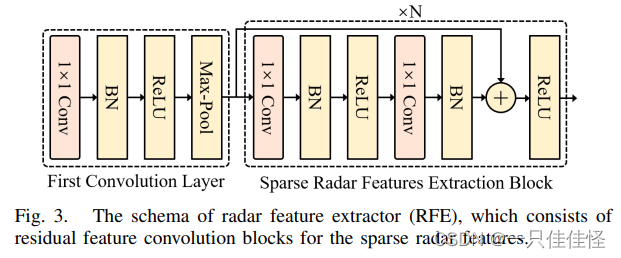
圖 3. 雷達特征提取器(RFE)的結構圖,其中包括 用于稀疏雷達特征的殘差特征卷積塊。
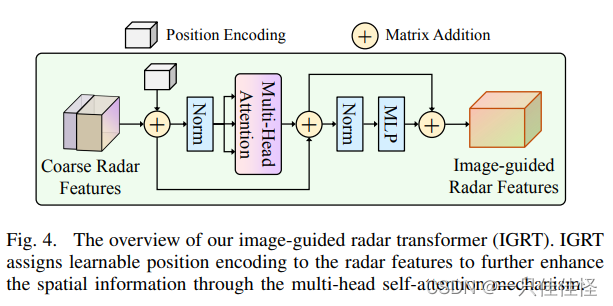
圖 4. 圖像制導雷達變換器(IGRT)概覽。IGRT 為雷達特征分配可學習的位置編碼,以通過多頭自注意機制進一步增強 空間信息。
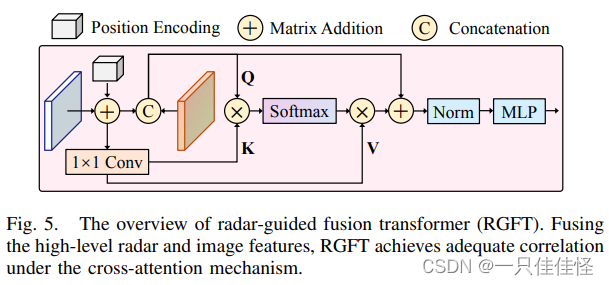
圖 5. 雷達引導融合變換器(RGFT)概述。RGFT 融合了高級雷達和圖像特征,在交叉注意機制下實現了充分的相關性。

圖 6. 我們的方法與之前的方法 [13] 的環視檢測結果對比。我們用 黃色圓圈表示我們的方法,藍色圓圈表示 [13] 的方法。我們的方法在不同視角下都能實現正確的目標檢測,而我們的方法在不同視角下都能實現充分的目標檢測。在不同視角下,我們的方法都能正確檢測到物體,其中語義對齊的雷達特征與視覺特征之間充分的雷達-相機互動為三維檢測提供了更多有用的線索。
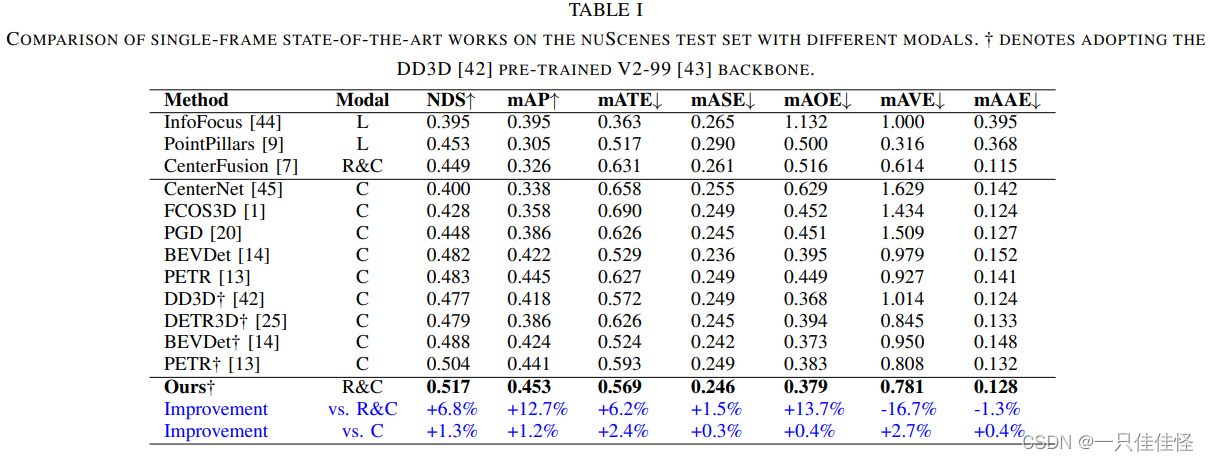
表1. 在 nuscenes 測試集上使用不同模態的單幀最先進作品比較。表示采用 dd3d [42] 預訓練 v2-99 [43] 主干網
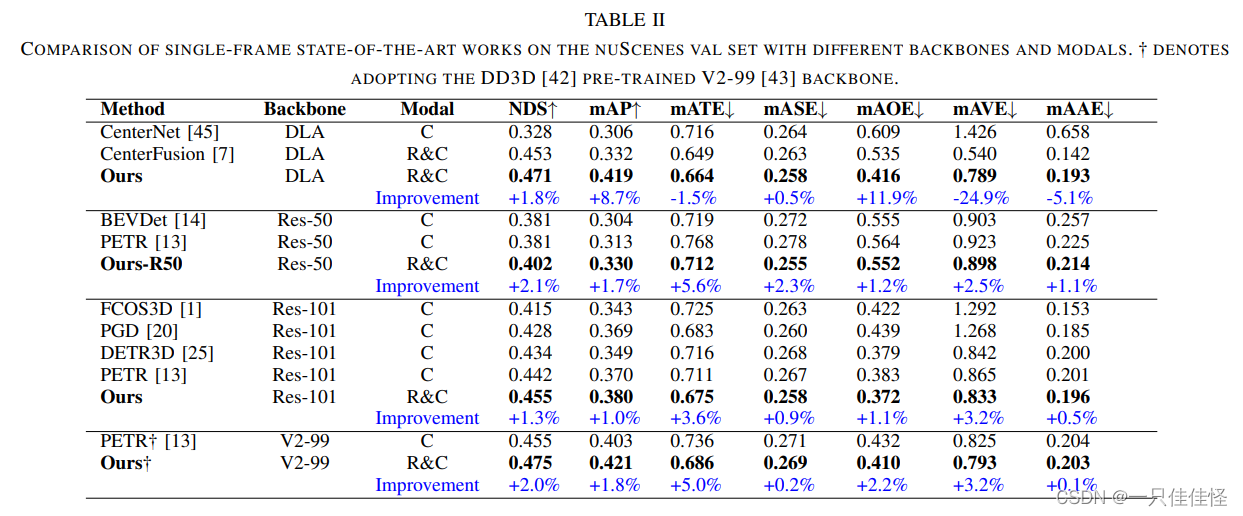
表2. 采用不同骨干網和模態對 nuscenes val 集進行的單幀最新研究成果比較。? 表示采用 dd3d [42] 預先訓練的 v2-99 [43] 骨架。
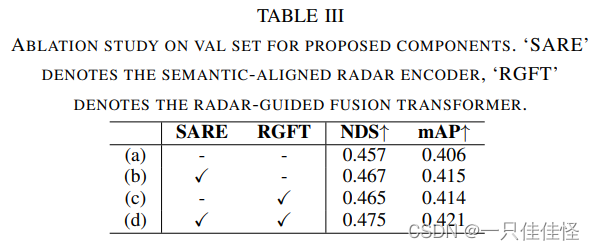
表3. 對擬議組件的值集進行消融研究。sare "表示語義對齊雷達編碼器,"rgft "表示雷達制導融合變換器。
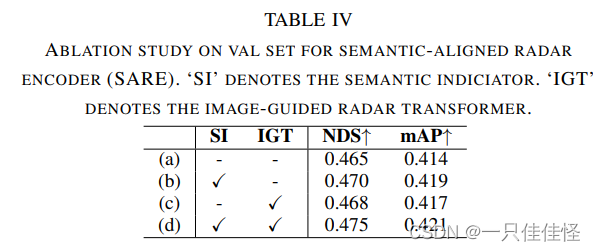
表4. 語義對齊雷達編碼器(SARE)閥值集消融實驗。si "表示語義指示器。igt "表示圖像制導雷達變換器。

表5. 雷達制導融合變壓器(RGFT)閥組燒蝕研究 變壓器(RGFT)。w "表示 “有”,"w/o "表示 “無”。表示 “無”。q’、‘k’、‘v’表示查詢、鍵、值。IMG. 表示圖像。concat.’ 表示 “連接”。
結論
本文提供了一種用于三維物體檢測的新型多視圖雷達-攝像機融合方法 MVFusion,該方法實現了語義對齊雷達特征和魯棒跨模態信息交互。具體來說,我們提出了語義對齊雷達編碼器(SARE)來提取圖像引導的雷達特征。在提取雷達特征后,我們提出了雷達引導融合變換器(RGFT),將增強的雷達特征與高級圖像特征進行融合。在 nuScenes 數據集上進行的大量實驗驗證了我們的模型達到了單幀雷達-攝像機融合的最先進性能。未來,我們將匯集多視角相機的時空信息,進一步促進雷達-相機融合。??






)

如何轉換為VOC格式數據集(.xml))









登錄態校驗Directive)
)