0 提綱
7.1 循環神經網絡RNN
7.2 LSTM
7.3 Transformer
7.4 U-Net
1 循環神經網絡RNN
把上一時刻的輸出作為下一時刻的輸入之一.
1.1 全連接神經網絡的缺點
現在的任務是要利用如下語料來給apple打標簽:
- 第一句話:I like eating apple!(我喜歡吃蘋果!)
- 第二句話:The Apple is a great company!(蘋果真是一家很棒的公司!)
第一個apple是一種水果,第二個apple是蘋果公司。
全連接神經網絡沒有利用上下文來訓練模型,模型在訓練的過程中,預測的準確程度,取決于訓練集中哪個標簽多一些,如果水果多,就打上水果的標簽,如果蘋果公司多,就打上蘋果公司;顯然這樣的模型不能對未知樣本進行準確的預測。
循環神經網絡 (Recurrent Neural Network, RNN) 用于處理序列數據.
1.2 動機
序列數據中, 前后數據之間不是獨立的, 而是會產生上下文影響. 如:
- 文本, 機器翻譯一個句子的時候, 不是逐個單詞的翻譯 (你可以發現近 10 年機器翻譯的質量大幅提升, 最近的 chatGPT 更是火得一蹋糊涂);
- 音頻, 可以在微信中讓機器把你講的話轉成文字;
- 投票, 雖然股價預測不靠譜, 但根據時序進行預測卻是人們最喜歡干的事情。
1.3 RNN的結構
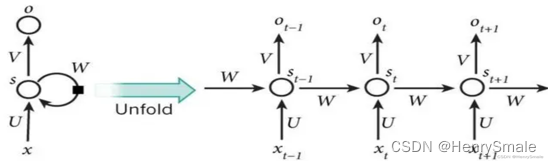
左圖如果不考慮 W W W,就是一個全連接神經網絡:
- 輸入層:向量 x x x,假設維度為3;
- 隱藏層:向量 s s s,假設維度為4;
- 輸出層:向量 o o o,假設維度為2;
- U U U:輸入層到隱藏層的參數矩陣,維度為 3 × 4 3×4 3×4;
- V V V:隱藏層到輸出層的參數矩陣,維度為 4 × 2 4×2 4×2。
左圖如果考慮 W W W,可以展開為右圖:
- x t ? 1 x_{t?1} xt?1?:表示 t ? 1 t?1 t?1時刻的輸入;
- x t x_t xt?:表示 t t t時刻的輸入;
- x t + 1 x_{t+1} xt+1?:表示 t + 1 t+1 t+1時刻的輸入;
- W W W:每個時間點的權重矩陣;
- o t o_t ot?:表示 t t t時刻的輸出;
- s t s_t st?:表示 t t t時刻的隱藏層;
RNN 把前一時刻 (簡便起見, 前一個單詞我也稱為前一時刻) 的輸出, 當作本階段輸入的一部分. 這里 x t ? 1 x_{t?1} xt?1?為前一時刻的輸入, 而 s t ? 1 s_{t-1} st?1? 為前一時刻的輸出. 這樣, 就把數據的前后聯系體現出來了.
1.4 RNN的缺點
每一時刻的隱藏狀態都不僅由該時刻的輸入決定,還取決于上一時刻的隱藏層的值,如果一個句子很長,到句子末尾時,它將記不住這個句子的開頭的內容詳細內容。
2 長短期記憶網絡LSTM
選擇性的存儲.
2.1 LSTM的原理
LSTM是高級的RNN,與RNN的主要區別在于:
- RNN每個時刻都會把隱藏層的值存下來,到下一時刻再拿出來使用,RNN沒有挑選的能力;
- LSTM不一樣,它有門控裝置,會選擇性的存儲信息。既有記憶 (重要信息) 的功能, 也有遺忘 (不重要信息) 的功能.
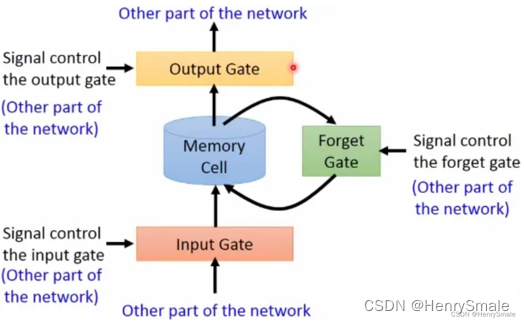
LSTM多了三個門:
- 輸入門:輸入的信息經過輸入門,輸入門的開關決定這一時刻是否會將信息輸入到Memory Cell;
- 輸出門:每一時刻是否有信息從Memory Cell輸出取決于這一道門;
- 遺忘門:每一時刻Memory Cell里的值都會經歷一個是否被遺忘的過程.
2.2 討論?
遺忘也是一種功能嗎? 當然是了.
所謂好了傷疤忘了痛, 如果一個人不會遺忘, 很快就精神失常了.
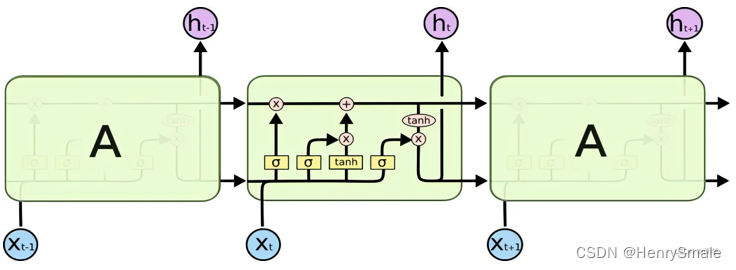
詳細分析見:
https://mp.weixin.qq.com/s?__biz=MzU0MDQ1NjAzNg==&mid=2247535325&idx=1&sn=7d805b06916a3da299e20c0445f59a07&chksm=fb3aefd6cc4d66c06b0f2d5779c83861474d2442f9b3387a4b87f45f3218efc92c3335602678&scene=27
3 變形金剛Transformer:注意力機制
定位到感興趣的信息, 抑制無用信息 (怎么有點像 PCA).
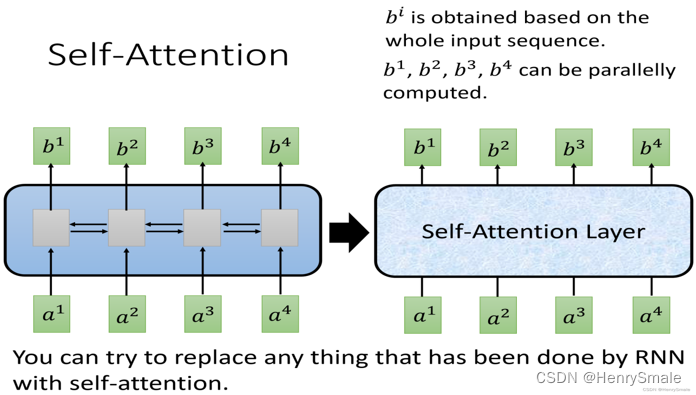
3.1 CNN及RNN的缺點
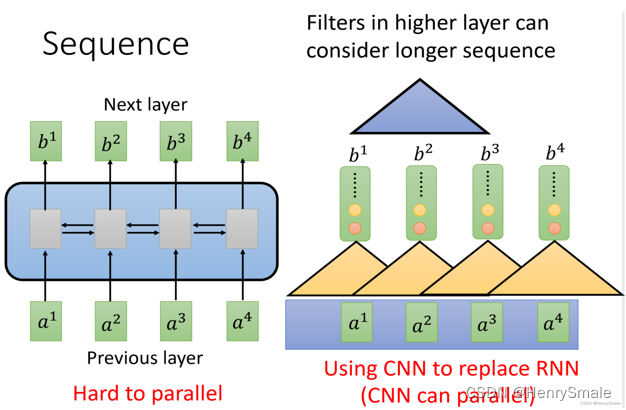
- RNN:很難實現并行(左圖,計算 b 4 b^4 b4需要串行查詢 a 1 , a 2 , a 3 , a 4 a^1,a^2,a^3,a^4 a1,a2,a3,a4);
- CNN:可以實現并行,需要堆疊多層的CNN才能學習到整個序列的特征(右圖).
3.2 自注意力機制(self-attention)
采用自注意力機制層取代RNN來處理序列,同時實現序列的并行處理。
自注意力機制具體內容見https://blog.csdn.net/search_129_hr/article/details/129522922
3.3 注意力機制
數據有重要的數據和不重要的數據。在模型處理數據的過程中,如果只關注較為重要的數據部分,忽略不重要的部分,那訓練的速度、模型的精度就會變得更好。
如果給你一張這個圖,你眼睛的重點會聚焦在紅色區域:
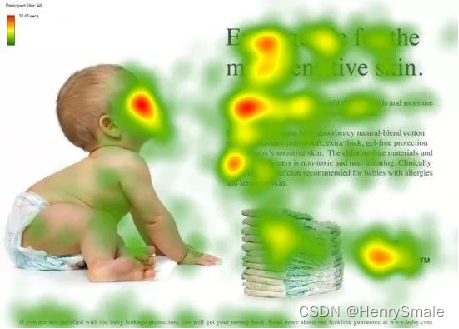
- 人看臉
- 文章看標題
- 段落看開頭
在訓練過程中,輸入的權重也都是不同的,注意力機制就是學習到這些權重。
最開始attention機制在CV領域被提出來,后面廣泛應用在NLP領域。
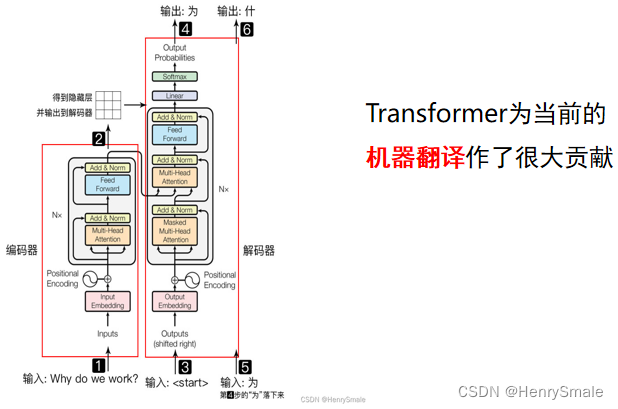
3.4 Tranformer的原理
Transformer 主要分為兩部分:Encoder編碼器 和 Decoder解碼器
- Encoder:負責把輸入(語言序列)隱射成隱藏層(圖中第 2 步九宮格表示),即把自然語言序列映射為隱藏層的數學表達的過程;
- Decoder:把隱藏層映射為自然語言序列。
4 U-Net
先編碼獲得內部表示, 再解碼獲得目標數據 (怎么有點像矩陣分解).
4.1 U-Net核心思想
U-Net 集編碼-解碼于一體, 是一種常見的網絡架構.
如圖所示, U-Net 就是 U 形狀的網絡, 前半部分 (左邊) 進行編碼, 后半部分 (右邊) 進行解碼.
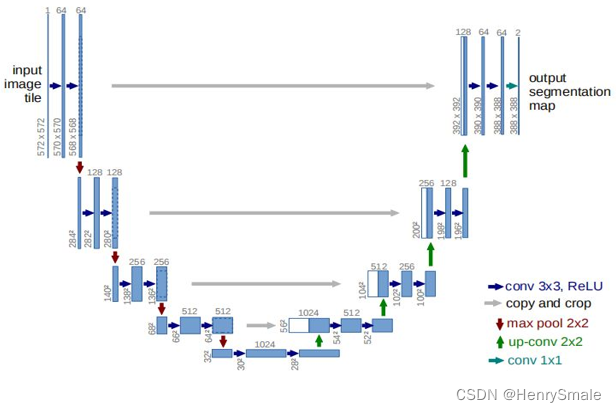
編碼部分, 將一個圖像經過特征提取, 變成一個小矩陣(28 × 28). 前面說過: 深度學習本質上只做一件事情, 就是特征提取.
解碼部分, 將壓縮表示解壓, 又變回大矩陣,完成圖像分割任務.
從思想上, 壓縮與解壓, 這與矩陣分解有幾分類似, 都是把數據進行某種形式的壓縮表示.
輸入的是原始圖像,通過網絡結構后得到的是分割后的圖像。
最特殊的部分是結構的后半部分,該網絡結構沒有全連接層,只采用了卷積層,每個標準的卷積層后面都緊跟著一個Relu激活函數層。
4.2 U-Net的應用
自編碼器. 直接將輸入數據作為標簽, 看編碼導致的損失 (更像矩陣分解了).
風格遷移:從一種風格轉換為另一種風格. 如將自然照片轉換成卡通風格, 將地震數據轉換成速度模型 (2010年如果你這么做會被業內人士笑話的).
圖像分割, 或提取圖片的邊緣. 嗯, 這個和轉成卡通風格也差不多.
機器翻譯. 把句子編碼成機器內部的表示 (一種新的世界語言?), 然后轉成其它語言的句子.
輸入一個頭, 輸出多個頭, 就可以做多任務. 如在速度模型反演的同時, 進行邊緣提取, 這樣導致反演的結果更絲滑.


: 從嵌入式系統到嵌入式Servlet SpingBoot 的進化之路)





)



)

圖像增強opencv實現)




