? ??
目錄
一. 前言
二. 什么是C++
三. C++關鍵字初探
四. 命名空間
4.1 為什么要引入命名空間
4.2 命名空間的定義
4.3 命名空間使用
五. C++的輸入輸出
六. 缺省參數
6.1 缺省參數的概念
6.2 缺省參數的分類
七. 函數重載?
7.1 函數重載的概念
7.2 函數重載的條件
7.3 C++支持函數重載的原因
一. 前言
? ? ? ? 舊坑未填,新坑又起。今天我們又要開啟一個新的系列:C++深入淺出。振奮人心的C++學習終于來了![]() 在本系列中,你能感受到C++相比C語言特有的魅力,盡管學習的過程中可能會充滿坎坷,但風雨之后,仰望天空,即使沒有彩虹,也會是睛空。學完C++后,你甚至可以在C++中用短短幾行代碼就搞定C語言幾十上百行的代碼,是不是很神奇,這還只是C++其中的一個強大之處哦。所以,不要恐懼,讓我們一起懷著激動的心情打開C++的大門吧
在本系列中,你能感受到C++相比C語言特有的魅力,盡管學習的過程中可能會充滿坎坷,但風雨之后,仰望天空,即使沒有彩虹,也會是睛空。學完C++后,你甚至可以在C++中用短短幾行代碼就搞定C語言幾十上百行的代碼,是不是很神奇,這還只是C++其中的一個強大之處哦。所以,不要恐懼,讓我們一起懷著激動的心情打開C++的大門吧![]()
二. 什么是C++

????????C語言是結構化和模塊化的語言,適合處理較小規模的程序。對于復雜的問題,規模較大的
程序,需要高度的抽象和建模時,C語言則不合適。為了解決軟件危機, 20世紀80年代, 計算機
界提出了OOP(object oriented programming:面向對象)思想,支持面向對象的程序設計語言
應運而生。
????????1982年,Bjarne Stroustrup博士在C語言的基礎上引入并擴充了面向對象的概念,發明了一
種新的程序語言。為了表達該語言與C語言的淵源關系,命名為C++。因此:C++是基于C語言而
產生的,它既可以進行C語言的過程化程序設計(C++兼容C語言),又可以進行以抽象數據類型為特點的基于對象的程序設計,還可以進行面向對象的程序設計。
三. C++關鍵字初探
? ? ? ? 在C語言的學習過程中,我們前前后后一共學到了32個關鍵字。而C++作為C語言的擴展,一共多達63個關鍵字,如下表所示:
?注:這里稍微知道一下有這些關鍵字即可,后面學到具體應用時再進行細講
四. 命名空間
4.1 為什么要引入命名空間
在寫C語言代碼時,你是否寫過類似這樣的代碼:
#include<stdio.h>
#include<stdlib.h>int rand = 0;
int main()
{printf("%d", rand);return 0;
}當你Ctrl+F5興沖沖的編譯運行時,發現不解情的編譯器報出了重定義的錯誤:

由于預處理階段會將頭文件進行展開,而在我們的stdlib.h頭文件中存在著名為rand的隨機數函數,而C語言是不允許在相同作用域下定義多個同名符號的,因此會報出重定義的錯誤。
#include<stdio.h> #include<stdlib.h>int rand = 0; //前面已經將rand全局定義為函數,這里又定義為全局變量,顧重定義 int main() {int rand = 0; //這里rand是局部變量,作用域不同,局部優先,因此不會報錯rand(); //由于rand是局部優先,這里的rand是個局部變量,顧無法作為函數使用,報錯printf("%d", rand);return 0; }在上面的代碼中,我們無論將rand定義成全局變量還是局部變量,都無法實現我們想要的效果,那怎么辦呢?將rand變量的名字換一個唄,得不到就不要強求啦
但是在C++中,新增了命名空間來對標識符的名稱進行本地化,以避免命名沖突或名字污染,上面的問題就被很好的解決了。
所以說,努力拓展提升自己,能力夠了自然也就得到了
4.2 命名空間的定義
定義命名空間,需要使用到namespace關鍵字,后面跟命名空間的名字,然后接一對{}即可。{}中的內容即為命名空間的成員。命名空間內的成員可以是變量,也可以是函數、類型,甚至可以是另一個命名空間。
namespace Dream //namespace關鍵字 + 命名空間名稱
{//命名空間內定義變量int a;int b = 10;//命名空間內定義函數int add(int x,int y){return x + y;}//命名空間內定義類型struct Stack{int* a;int top;int capacity;};//命名空間嵌套定義namespace other{int a;int b = 10;}}注意:一個命名空間定義了一個新的作用域,命名空間中的所有內容都局限于該命名空間中
此外, 如果我們在同一工程中定義了兩個相同名稱的命名空間(無論在哪個文件),編譯器最終會合并到同一個命名空間中![]()
//test1.cpp
namespace Dream
{int a = 5;int b = 10;
}//test2.cpp
namespace Dream
{int Add(int x, int y){return x + y;}
}//上面兩個同名命名空間編譯器最終會進行合并,結果如下:
namespace Dream
{int a = 5;int b = 10;int Add(int x, int y){return x + y;}
}4.3 命名空間使用
那么,定義了命名空間后,我們要如何使用它呢?如果我們直接對命名空間的成員進行訪問,編譯器會報錯:
#include<stdio.h>
namespace Dream
{int b = 10;
}
int main()
{printf("%d", b); //報錯,b只在Dream作用域內有效return 0;
}
?我們一般有一下三種使用方法:
1、變量名前加命名空間名稱及作用域限定符
namespace Dream
{int b = 10;namespace other{int b = 5;}
}int main()
{printf("%d", Dream::b); //表示Dream命名空間內的b,即輸出10printf("%d", Dream::other::b); //表示Dream命名空間內的other命名空間內的b,即輸出5return 0;
}分析:兩個變量b雖然名稱相同,但被劃分到了兩個命名空間中,作用域不同,因此不會出現重定義的問題。并且,通過在前面加上對應的命名空間我們可以實現對這兩個變量b的訪問。
2、使用using將命名空間中某個成員展開
? ? ? 但是如果命名空間中的某個變量需要在程序中頻繁的進行使用,每次都要在前面加上命名空間未免顯得過于繁瑣,因此C++還允許我們使用using關鍵字將命名空間中某個成員展開![]()
namespace Dream
{int a = 5;int b = 10;
}using Dream::a;//int a = 10; //由于上方將變量a展開,a的作用域相當于全局,這里如果再定義a會重定義
int main()
{a += 10; //引入了a,顧不需要再前面加上命名空間printf("%d\n", a);printf("%d", Dream::b); //而變量b沒有展開,故需加上命名空間return 0;
}3、使用using naespace 將整個命名空間展開
? ? ? 當然,如果你愿意的話,你也可以將整個命名空間展開,這樣整個命名空間的東西都將暴露在全局。具體方式如下![]()
namespace Dream
{int a = 5;int b = 10;
}using namespace Dream; //展開后使用命名空間內的變量就無需再加前綴
int main()
{a += 10;printf("%d\n", a);printf("%d", b);return 0;
}????????下面,我們再來看看許多C++程序中經常出現的寫法就很清楚了:
#include<iostream>
using namespace std;
int main()
{return 0;
}
- 第一條語句的作用是包含輸入輸出流,下面我們會進行說明,這里我們可以暫且將理解為C語言的#include<stdio.h>
- 第二條語句是不是很熟悉啦,沒錯,就是用來展開命名空間std的。std的英文全拼是Standard,即標準的意思。C++標準程序庫中的所有標識符都被定義在這個命名空間中。顧這里將整個命名空間引入是為了后續更方便的使用C++標準程序庫的標識符,如函數、類型等等。
但是,雖然方便,但在實際工程中并不建議直接將整個命名空間展開。原因是在大規模工程中,定義的變量太多,可能會出現定義的變量名與std命名空間的標識符出現重復的情況,此時如果將std全部展開就會出現重定義的BUG。
故比起將命名空間全部展開,我們更推薦使用第一種或者第二種使用方式。
?五. C++的輸入輸出
在學習C語言時,我們寫的第一個代碼就是hello world,那么在我們第一次接觸C++時,是不是也應該使用C++對美好的世界打個招呼呢?我們來試試C++是怎么實現輸入輸出的吧!![]()
#include<iostream>
using namespace std; //展開std命名空間
int main()
{cout << "hello world!!!" << endl; //打印輸出return 0;
}
?下面我們來分析分析上面的代碼
1、使用cout標準輸出對象(控制臺)和cin標準輸入對象(鍵盤)時,必須包含<iostream>頭文件
以及按命名空間使用方法使用std。是的,iostream也是一個頭文件噢。2、cout和cin是全局的流對象,它們分別是ostream和istream類型的對象。而endl是特殊的C++符號,表示換行輸出,他們都包含在包含在<iostream>頭文件中。
3、<<是流插入運算符,>>是流提取運算符。它們是不是和我們C語言學到的左移和右移一模一樣?是的,這實際上是一種運算符重載,我們后續會提到。
4、使用C++輸入輸出更方便,不需要像printf/scanf輸入輸出時那樣需要手動控制格式,即%d、%f等等。C++的輸入輸出可以自動識別變量類型。
注意:早期標準庫將所有功能在全局域中實現,聲明在.h后綴的頭文件中,使用時只需包含對應頭文件即可,后來將其實現在std命名空間下,為了和C語言頭文件區分,也為了正確使用命名空間,規定C++頭文件不帶.h,這就是為什么<iostream>也是頭文件的原因。舊編譯器(vc 6.0)中還支持<iostream.h>格式,后續編譯器已不支持,因此推薦使用<iostream>+std的方式。
六. 缺省參數
6.1 缺省參數的概念
? ? ??缺省參數是聲明或定義函數時為函數的參數指定一個缺省值(默認值)。在調用該函數時,如果沒有指定實參則采用該形參的缺省值,否則使用指定的實參。具體形式如下:
#include<iostream>
using namespace std;void Func(int a = 0) //給定缺省值0
{cout << a << endl;
}int main()
{Func(); // 沒有傳參時,使用參數的默認值Func(10); // 傳參時,使用指定的實參return 0;
}
6.2 缺省參數的分類
? ? ? ?缺省參數分為全缺省參數和半缺省參數
? ? ? ?全缺省參數
? ? ? ?即所以參數都帶有缺省值![]()
void Func(int a = 10, int b = 20, int c = 30)
{cout<<"a = "<<a<<endl;cout<<"b = "<<b<<endl;cout<<"c = "<<c<<endl;
}
int main()
{Func(); Func(10); Func(20,30,40); return 0;
}? ? ? ?半缺省參數
? ? ? ??即部分參數都帶有缺省值![]()
void Func(int a, int b = 10, int c = 20) //除了a其余參數都有缺省值
{cout<<"a = "<<a<<endl;cout<<"b = "<<b<<endl;cout<<"c = "<<c<<endl;
}int main()
{Func(); //錯誤調用,第一個參數沒有缺省值,需要傳參Func(10); //第一個參數傳入10,其余參數用缺省值Func(20,30,40); //全部用指定的實參return 0;
}????????注意事項
- 規定半缺省參數必須從右往左依次給出,不能間隔著給。示例如下:
//錯誤寫法,必須從右往左不間斷 void Func(int a = 10, int b, int c) {}; void Func(int a = 10, int b = 20, int c) {}; void Func(int a = 10, int b, int c = 30) {};//正確寫法 void Func(int a, int b, int c = 30) {}; void Func(int a, int b = 20, int c = 30) {}; -
缺省參數不能在函數聲明和定義中同時出現。其目的是為了防止我們在聲明和定義中給出了不同的缺省值,從而導致歧義。
//錯誤的寫法 //test.h void Func(int a = 10); // a test.cpp void Func(int a = 20) {} -
缺省值必須是常量或者全局變量
-
C語言不支持帶缺省參數的函數(編譯器不支持)
七. 函數重載?
7.1 函數重載的概念
函數重載:它是一種函數的特殊情況。C++允許在同一作用域中聲明幾個功能類似的同名函數,這
些同名函數的形參列表(參數個數 或 類型 或 類型順序)不同,常用來處理實現功能類似、數據類型不同的問題。
假設我們要寫一個Add函數實現兩個整型以及兩個浮點型的相加,在C語言中,我們應該這么寫:
//C語言寫法
int iAdd(int x, int y)
{return x + y;
}
double dAdd(double x, double y)
{return x + y;
}
int main()
{iAdd(1, 2);dAdd(1.0, 2.0);return 0;
}由于實參的類型不同,我們需要寫兩個Add函數分別實現整形和浮點型的相加,并且為了避免重定義,兩個函數名必須不同,難道這不覺得很別扭嗎![]()
而C++引入了函數重載,我們就能很舒服的使用相同名稱來定義這兩個參數不同的函數:
//C++寫法,兩個Add函數構成函數重載
int Add(int x, int y)
{return x + y;
}double Add(double x, double y)
{return x + y;
}int main()
{Add(1, 2);Add(1.0, 2.0);return 0;
}7.2 函數重載的條件
? ? ? ?C++構成函數重載的條件是形參列表必須不同。形參列表不同分為以下三種:
? ? ? ? 1、參數個數不同
#include<iostream>
using namespace std;
//2、參數個數不同
void Fun(int x)
{cout << "void Fun(int x)" << endl;
}
void Fun()
{cout << "void Fun()" << endl;
}int main()
{Fun(1); //調用第一個Fun(); //調用第二個
}
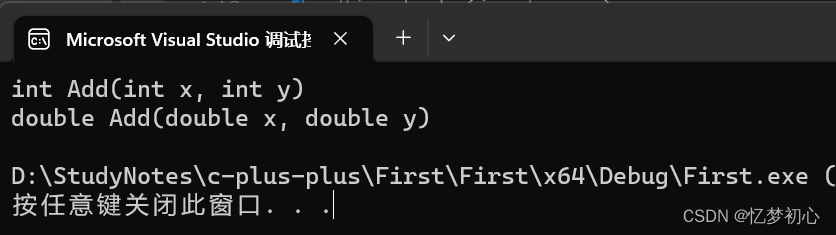
? ? ? ? 2、參數類型不同
#include<iostream>
using namespace std;
//2、參數類型不同
int Add(int x, int y)
{cout << "int Add(int x, int y)" << endl;return x + y;
}
double Add(double x, double y)
{cout << "double Add(double x, double y)" << endl;return x + y;
}int main()
{Add(1, 2); //調用第一個Add(1.0, 2.0); //調用第二個
}
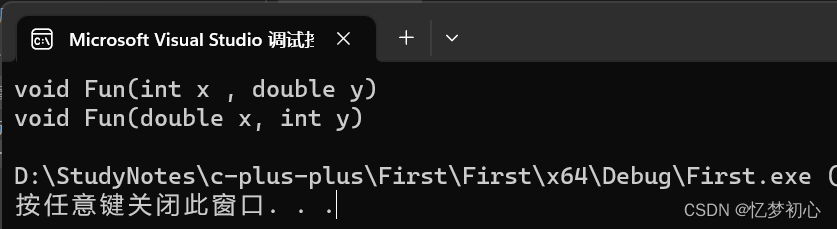
? ? ? ? 3、參數順序不同
#include<iostream>
using namespace std;
//3、參數順序不同
void Fun(int x , double y)
{cout << "void Fun(int x , double y)" << endl;
}
void Fun(double x, int y)
{cout << "void Fun(double x, int y)" << endl;
}int main()
{Fun(1,2.0); //調用第一個Fun(2.0,1); //調用第二個
}
注意:是參數類型的順序不同,而不是變量名順序不同,即以下寫法不構成函數重載:
//變量名順序不同不構成函數重載,形參的名稱只是標識,本質上還是同一個函數 void Fun(int x , double y){}; void Fun(int y , double x){};
?? ? ? ? 4、缺省函數的重載
? ? ? ? ?此外,帶缺省參數的函數也可以構成函數重載,編譯并不會報錯,但使用上可能會出現一些很尷尬的問題,舉例如下![]()
#include<iostream>
using namespace std;
//4、缺省函數的重載
void Fun(int x, double y = 1.0)
{cout << "void Fun(int x , double y = 1.0 )" << endl;
}
void Fun(int x)
{cout << "void Fun(int x)" << endl;
}
int main()
{Fun(1, 2.0); //這里會調用第一個函數沒問題Fun(1); //此時既可以調用第一個函數,也可以調用第二個函數,存在歧義,會報錯
}由于缺省函數的重載很容易引發歧義,顧我們一般不也會這么寫
??
7.3 C++支持函數重載的原因
????????可能會有很多小伙伴會疑惑:為什么C++支持函數重載,而C語言不支持函數重載呢?、
????????在C/C++中,一個程序要運行起來,需要經歷以下幾個階段:預處理、編譯、匯編、鏈接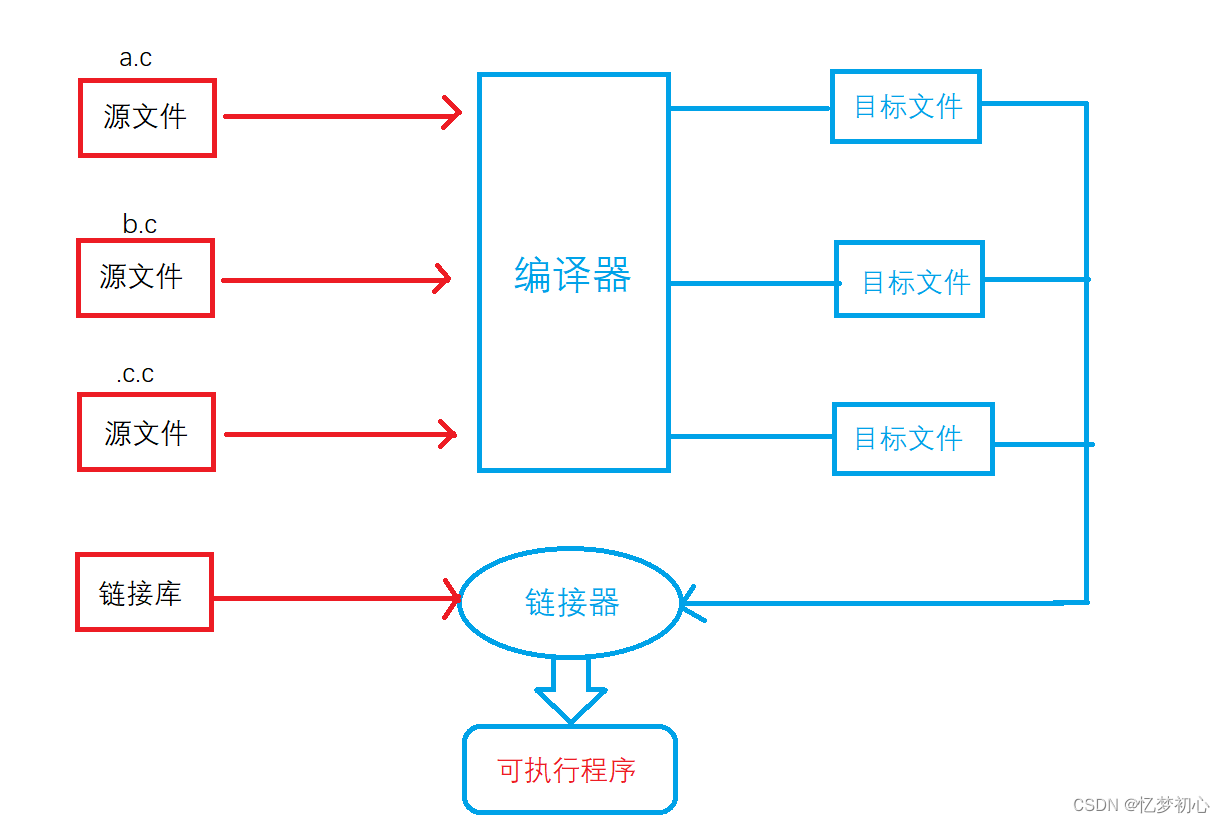

我們發現,每個.c文件都會生成屬于自己的符號表。main.c文件中sum函數只是聲明,故在符號表中并沒有sum函數的地址。而sum.c文件中的sum函數是定義,故在符號表中存在著sum函數的地址。當鏈接器進行鏈接時,就會將兩張符號表進行合并,此時符號表中既有main函數的地址,也有sum函數的地址,程序便可以正常運行。
但是,如果兩個文件中的sum函數都是定義呢?如下:?
由于兩個符號表中的sum函數都是有效地址,進行符號表合并后,符號表就會出現上面的相同符號不同地址的情況,會引發符號表的歧義,此時我們就不知道該去哪個地方找sum函數了,會報重定義的錯誤。
?這就是為什么C語言不能定義同名函數的原因:重定義會引發符號表的歧義。



那就有人會想:C語言不行,那憑什么放到C++就可以呢,搞特殊?![]()
首先要說明的是,上面的兩個Add函數放到C++依然不構成函數重載,因為它們的類型相同。那C++為什么類型不同就允許同名函數的存在呢?這是因為C++引入了函數名修飾規則,函數在符號表中除了名稱,還一并將參數類型代入修飾。
不同的編譯器下的函數名修飾規則可能有所不同,由于VS的函數名修飾規則過于復雜,下面我們采用Linux下的g++來進行演示![]()
源代碼清單
int Add(int x,int y)
{return x + y;
}double Add(double x,double y)
{return x + y;
}int main()
{return 0;
}
采用gcc編譯(C語言)
為了正確進行編譯,將第一個Add函數改為Add1,第二個改為Add2。編譯后查看匯編代碼如下:

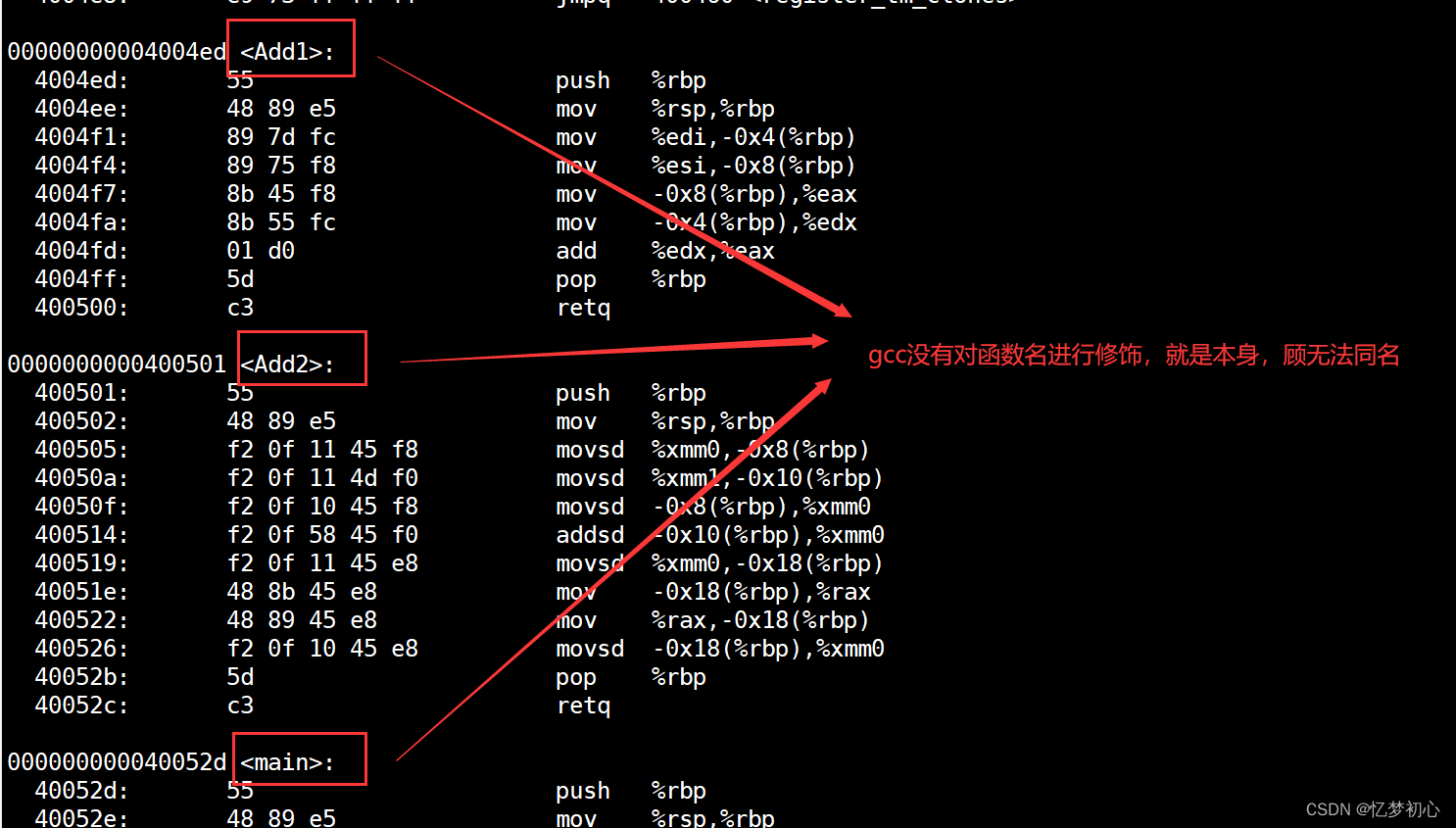
采用g++編譯(C++)

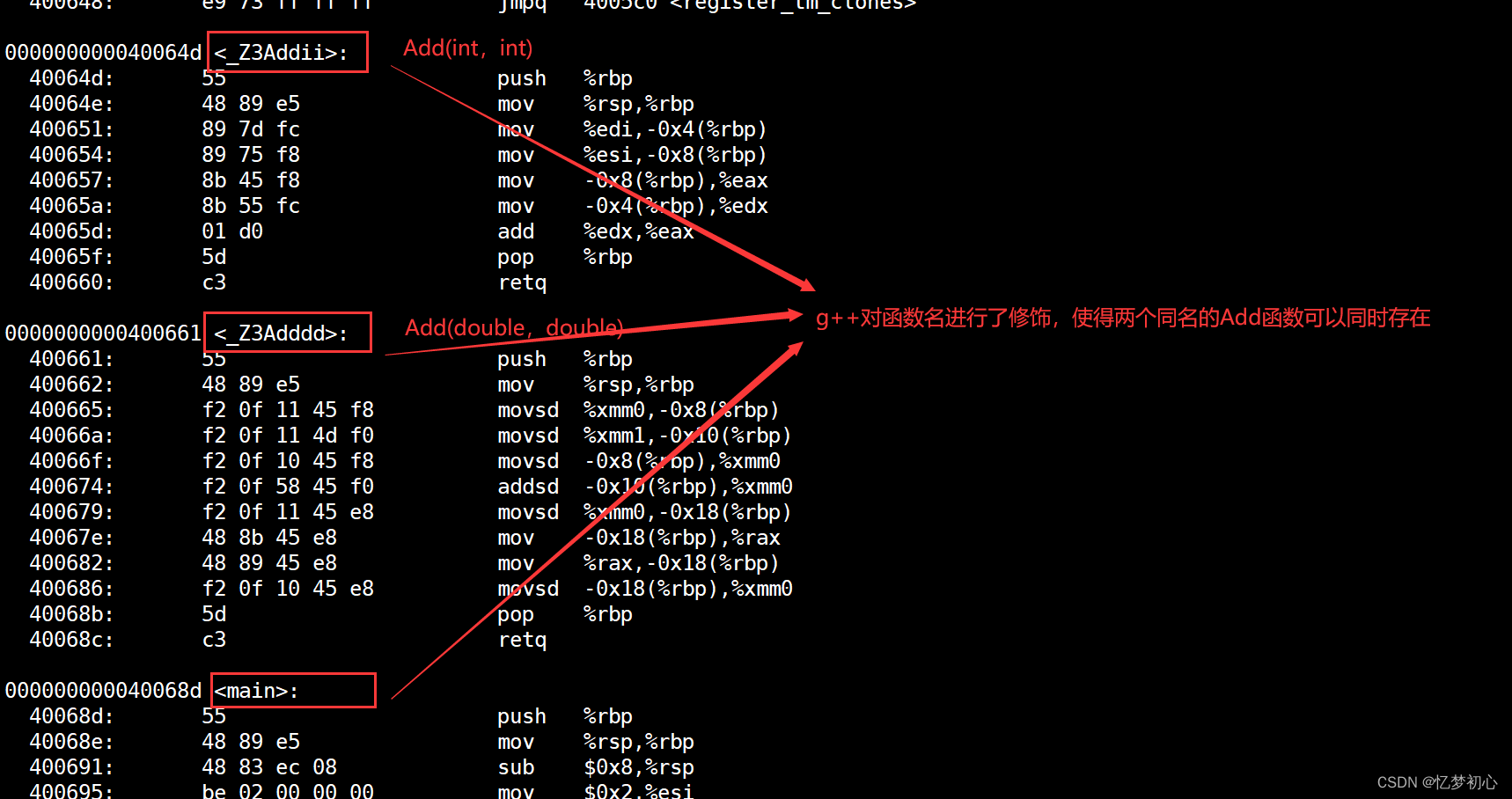
Linux系統下的g++編譯器將函數修飾后變成【_Z+函數長度+函數名+類型首字母】的形式,形參的個數、順序以及類型不同都會使得修飾后的函數名不同![]()
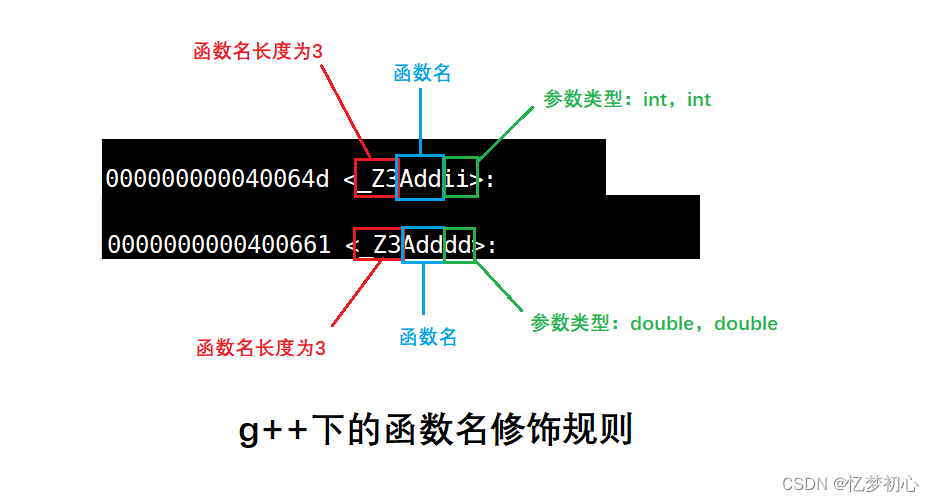
?總結提煉
- 在linux下,采用gcc編譯完成后,函數名字沒有發生改變。
- 在linux下,采用g++編譯完成后,函數名字的修飾發生改變,編譯器將函數參數類型信息添加到修改后的名字中。
- C語言沒辦法支持重載是因為同名函數沒辦法區分。而C++是通過函數修飾規則來區分,只要參數不同,修飾出來的名字就不一樣,顧支持重載。
- 如果兩個函數僅僅是返回值不同是不構成重載的,因為調用時編譯器沒辦法區分。
以上,就是本期的全部內容啦🌸
制作不易,能否點個贊再走呢🙏

)





concurrent.futures高級別異步執行封裝)



:實現 ZIP 壓縮與解壓)
![[Leetcode] [Tutorial] 多維動態規劃(未完待續)](http://pic.xiahunao.cn/[Leetcode] [Tutorial] 多維動態規劃(未完待續))



 的對應關系)


