引入
為了更好的理解5種IO模型的區別,在介紹IO模型之前,我先介紹幾個概念
1.進程的切換
(1)定義
為了控制進程的執行,內核必須有能力掛起正在CPU上運行的進程,并恢復以前掛起的某個進程的執行。即從用戶態(較低的3G字節)切換到內核態(最高的1G字節),非常消耗系統資源。
(2)過程
- 保存處理機上下文,包括程序計數器和其他寄存器。
- 更新PCB信息。
- 把進程的PCB移入相應的隊列,如就緒、在某事件阻塞等隊列。
- 選擇另一個進程執行,并更新其PCB。
- 更新內存管理的數據結構。
- 恢復處理機上下文。
2.進程的阻塞
(1)定義
正在執行的進程,由于期待的某些事件未發生,由運行狀態變為阻塞狀態。
(2)特點
- 只有處于運行狀態的進程(獲得CPU)才能被阻塞
- 阻塞是主動行為
- 不占用CPU資源
3.文件描述符
(1) 定義
用于描述指向文件的引用的抽象化概念
(2) 特點
- 一個非負整數
- 本質是一個索引值,指向內核為每一個進程所維護的該進程打開文件的記錄表
4.緩存IO
-
IO的數據緩存在文件系統的頁緩存中(先拷貝到內核的緩沖區)
-
在應用程序和內核間多次數據拷貝,帶來很大的CPU開銷
5.并發與并行
-
并發:同時進行的任務數
-
并行:同時工作的物理資源數量(如CPU核數)
5種IO模型
- IO的本質是socket的讀取,數據先拷貝到內核的緩沖區中,然后拷貝到應用程序的地址空間(進程)
1.BIO(blocking IO):同步阻塞 I/O
(1)過程
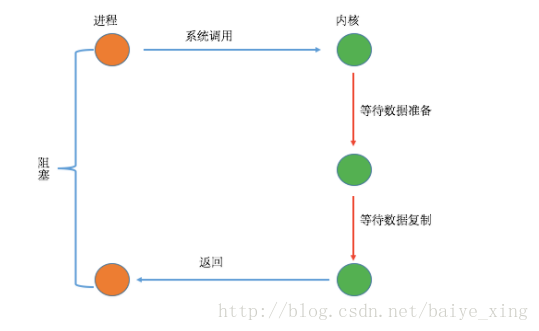
分析:從上圖可以看到在整個過程中,當用戶進程進行系統調用時,內核就開始了I/O的第一個階段,準備數據到緩沖區中,當數據都準備完成后,則將數據從內核緩沖區中拷貝到用戶進程的內存中,這時用戶進程才解除block的狀態重新運行。
(2)實例
-
Blocking I/O是在I/O執行的兩個階段都被block了。
-
例如:我要去飯堂吃飯,這時飯堂的人很多,我就得排隊買飯,排隊的時間被浪費了,
(3)特點
- 能夠及時返回數據,無延遲
- 性能下降
2.NIO(nonblocking IO):同步非阻塞 I/O
(1)過程
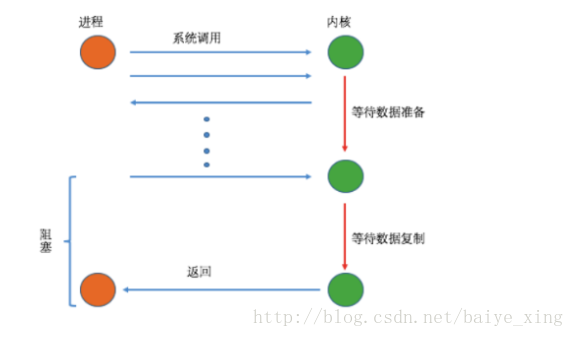
分析:從上圖可以看到在I/O執行的兩個階段中,用戶進程只有在第二個階段被阻塞了,而第一個階段沒有阻塞,但是在第一個階段中,用戶進程需要盲等,不停的去輪詢內核,看數據是否準備好了。
(2)實例
-
nonblocking I/O是在I/O執行的第二個階段(數據復制)被block了,而第一個階段并未阻塞(數據準備)。
-
例如:我要去飯堂吃飯,這時飯堂的人很多,一般來說我需要排隊買飯,但我們飯堂的管理最近變的比較人性化,你點完飯后,會給你一個號碼,但飯堂噪聲很大,我不得不頻繁的詢問我的飯是否做好了,但是我可以利用之前排隊的時間去買瓶飲料喝!
(3)特點
- 拷貝數據的整個過程,進程仍然是阻塞的
- 需要不斷詢問數據是否準備好了
- 能夠在等待任務完成的過程中處理其他事件
- 由于需要輪詢,所以延遲會增加
3.多路復用IO( IO multiplexing)
(1)過程
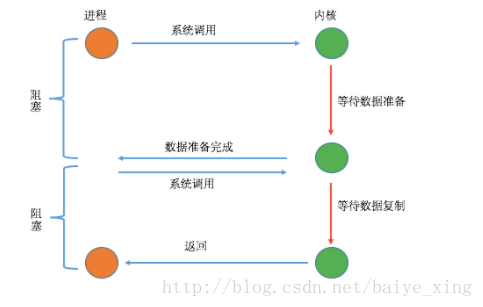
分析:
-
從上圖可以看到在I/O復用模型中,由于同步非阻塞方式需要不斷主動輪詢,輪詢占據了很大一部分過程,輪詢會消耗大量的CPU時間,而 “后臺” 可能有多個任務在同時進行,
-
如果循環查詢多個任務的完成狀態,只要有任何一個任務完成,就去處理它。輪詢不是進程的用戶態。這時 “IO 多路復用”就出現了。即UNIX/Linux 的 select、poll、epoll,
-
IO多路復用是阻塞在select,epoll這樣的系統調用之上,而沒有阻塞在真正的I/O系統調用如recvfrom之上。
-
從整個IO過程來看,他們都是順序執行的,因此可以歸為同步模型(synchronous)。都是進程主動等待且向內核檢查狀態
(2)實例
-
多路復用I/O執行的兩個階段用戶進程都是阻塞的,但是兩個階段是獨立的。
-
例如:我要去飯堂吃飯,這時飯堂的人很多,點完飯后,我會拿到一個號碼,以前我不得不頻繁的詢問我的飯做好了沒,但是最近飯堂安裝了一塊電子顯示屏,你的飯好了就會在屏上顯示出來,這時候我就不用頻繁的去問了,直接看電子顯示屏就醒了,然后我就可以利用這個時間去超市買個牙膏了。
(3)特點
-
select/poll調用后會阻塞進程,但可以同時阻塞多個IO事件操作(文件描述符),有數據可讀或可寫(就緒事件),就通知用戶進程。
-
select 需要每次注冊事件(輪詢),而epoll不需要每次注冊事件(沒有輪詢,回調函數)
-
IO多路復用阻塞在select/epoll的系統調用之上的,而真正的IO系統調用如recvfrom是非阻塞的。
(4)適用場景
-
服務器需要同時處理多個處于監聽狀態或連接狀態的套接字
-
服務器需要處理多種網絡協議的套接字
4.信號驅動I/O( signal driven IO)
(1)過程
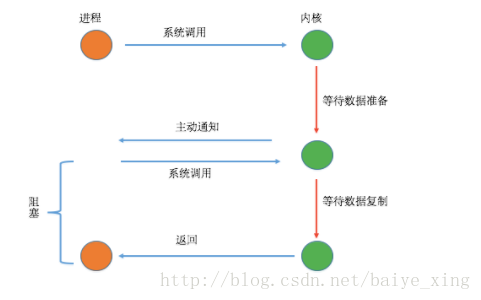
分析:從上圖可以看出,只有在I/O執行的第二階段阻塞了用戶進程,而在第一階段是沒有阻塞的。該模型在I/O執行的第一階段,當數據準備完成之后,會主動的通知用戶進程數據已經準備完成,即對用戶進程做一個回調。該通知分為兩種,一為水平觸發,即如果用戶進程不響應則會一直發送通知,二為邊緣觸發,即只通知一次。
(2)實例
-
信號驅動I/O執行的第一階段阻塞,而第二階段不阻塞。
-
例如:我要去飯堂吃飯,這時飯堂的人很多,點完飯后,我會拿到一個號碼,雖然說飯堂安裝了一塊電子顯示屏,但我在玩手機時還不得不抬頭看一下顯示屏上有我的號碼沒,最近飯堂買了一個大喇叭,哪個號碼好了,賣飯的阿姨就會用喊,雖說飯堂有點吵,但這個聲音還是可以聽到的,這樣我就可以專心的低頭玩手機了。
5.異步 I/O(asynchronous IO)
(1)過程
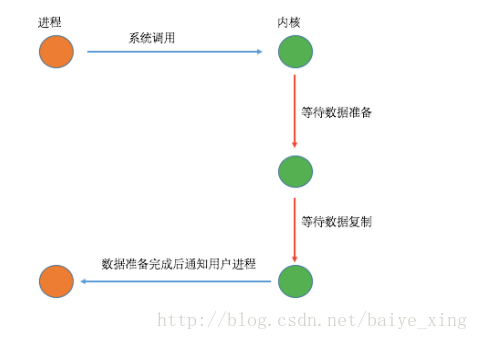
分析:從上圖可以看出,在該模型中,當用戶進程發起系統調用后,立刻就可以開始去做其它的事情,然后直到I/O執行的兩個階段都完成之后,內核會給用戶進程發送通知,告訴用戶進程操作已經完成了。
(2)實例
-
異步 I/O執行的兩個階段都不會阻塞。
-
例如:我要去飯堂吃飯,估計這會飯堂的人很多,但最近我們飯堂可以叫外賣了,這樣就省事多了,我直接打個電話,訂份飯送到我們宿舍,而我現在就可以利用原來去飯堂路上和等飯的時間寫博客了。
-
這就是同步和異步的區別,原來我得親自去飯堂買飯,而現在我可以在宿舍叫外賣。
(3)特點
- 讀寫操作由內核完成,完成后內核將數據放到指定的緩沖區,通知應用程序來取。
總結
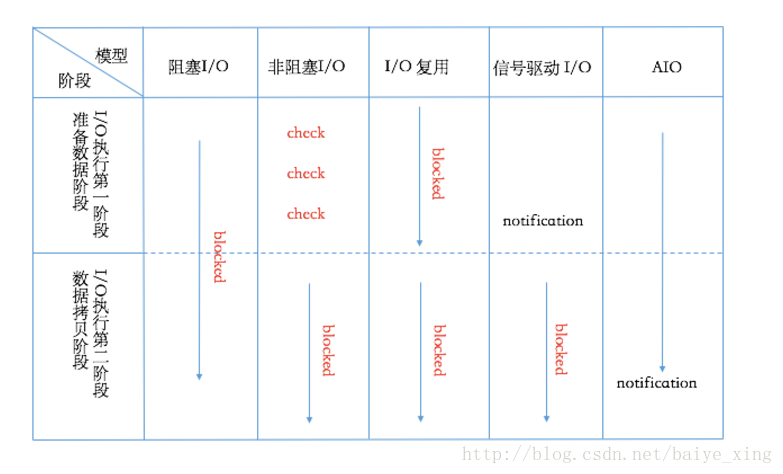
-
阻塞IO和非阻塞IO的區別:數據準備的過程中,進程是否阻塞。
-
同步IO和異步IO的區別:數據拷貝的過程中,進程是否阻塞。
本人才疏學淺,若有錯,請指出,謝謝!?
如果你有更好的建議,可以留言我們一起討論,共同進步!?
衷心的感謝您能耐心的讀完本篇博文!
參考資料:聊聊Linux 五種IO模型



















