名字修飾(name Mangling)
在C/C++中,一個程序要運行起來,需要經歷以下幾個階段:預處理、編譯、匯編、鏈接。
Name Mangling是一種在編譯過程中,將函數、變量的名稱重新改編的機制,簡單來說就是編譯器為了區分各 個函數,將函數通過某種算法,重新修飾為一個全局唯一的名稱。
C語言的名字修飾規則非常簡單,只是在函數名字前面添加了下劃線。比如,對于以下代碼,在后鏈接時就 會出錯:
int Add(int left, int right);int main()
{ Add(1, 2);
return ;
}
編譯器報錯:error LNK2019: 無法解析的外部符號 _Add,該符號在函數 _main 中被引用。
上述Add函數只給了聲明沒有給定義,因此在鏈接時就會報錯,提示:在main函數中引用的Add函數找不到函 數體。從報錯結果中可以看到,C語言只是簡單的在函數名前添加下劃線。因此當工程中存在相同函數名的函 數時,就會產生沖突。
具體例子看上篇博客有詳細介紹。
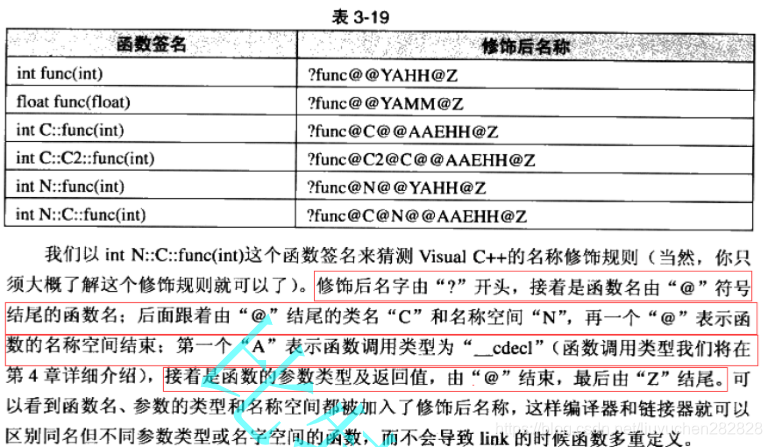
由于C++要支持函數重載,命名空間等,使得其修飾規則比較復雜,不同編譯器在底層的實現方式可能都有差 異。
int Add(int left, int right);int main() { Add(1, 2); return 0; }
int Add(int left, int right); double Add(double left, double right);int main() { Add(1, 2); Add(1.0, 2.0); return 0; }
在vs下,對上述代碼進行編譯鏈接,后編譯器報錯:
error LNK2019: 無法解析的外部符號 “double cdecl Add(double,double)” (?Add@@YANNN@Z) error LNK2019: 無法解析的外部符號 “int __cdecl Add(int,int)” (?Add@@YAHHH@Z)
通過上述錯誤可以看出,編譯器實際在底層使用的不是Add名字,而是被重新修飾過的一個比較復雜的名字, 被重新修飾后的名字中包含了:函數的名字以及參數類型。這就是為什么函數重載中幾個同名函數要求其參數 列表不同的原因。只要參數列表不同,編譯器在編譯時通過對函數名字進行重新修飾,將參數類型包含在終 的名字中,就可保證名字在底層的全局唯一性。
extern “C”
c++的函數庫,c語言中并不能直接用。
有時候在C++工程中可能需要將某些函數按照C的風格來編譯,在函數前加extern “C”,意思是告訴編譯器,將 該函數按照C語言規則來編譯
extern "C" int Add(int left, int right);int main(){ Add(1,2); return 0;}
鏈接時報錯:error LNK2019: 無法解析的外部符號_Add,該符號在函數 _main 中被引用
而不是c++中的報錯。
引用
在之前的學習中,我們傳參數的兩種方式分別為,傳值和傳地址。
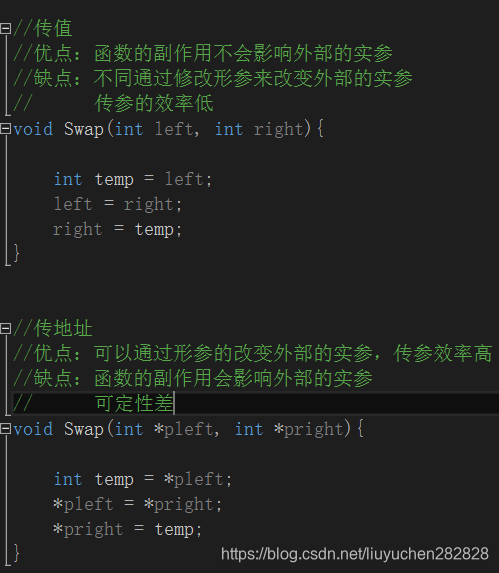
有沒有什么方法能夠將讓傳值的方式也能夠起到交換的作用?
引用不是新定義一個變量,而是給已存在變量取了一個別名,編譯器不會為引用變量開辟內存空間,它和它引 用的變量共用同一塊內存空間。
使用方法
類型& 引用變量名(對象名) = 引用實體;
注意:引用類型必須和引用實體是同種類型的
引用特性
- 引用在定義時必須初始化
- 一個變量可以有多個引用
- 引用一旦引用一個實體,再不能引用其他實體
常引用


因為10本身是常量,修改不了

類型不同
使用場景
-
做參數
void Swap(int& left, int& right)
{ int temp = left;
left = right;
right = temp
} -
做返回值
int& TestRefReturn(int& a)
{ a += 10;
return a;
}
int& Add(int a, int b)
{ int c = a + b; return c; }int main() { int& ret = Add(1, 2); Add(3, 4); cout << "Add(1, 2) is :"<< ret <<endl; return 0; }
注意:如果函數返回時,離開函數作用域后,其棧上空間已經還給系統,因此不能用棧上的空間作為引用類型 返回。如果以引用類型返回,返回值的生命周期必須不受函數的限制(即比函數生命周期長)。
具體參考https://blog.csdn.net/qq_40550018/article/details/81225519函數棧幀
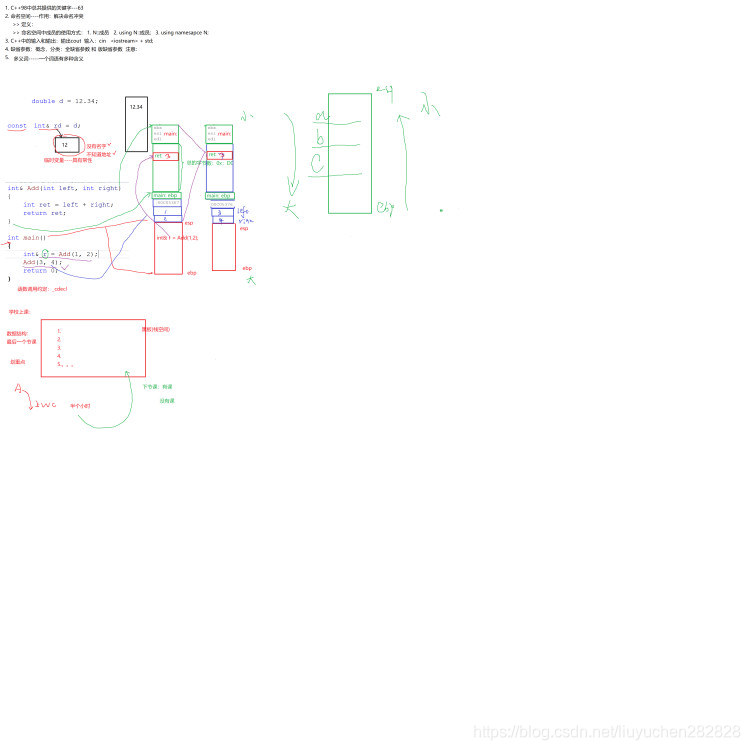
傳值、傳引用效率比較
以值作為參數或者返回值類型,在傳參和返回期間,函數不會直接傳遞實參或者將變量本身直接返回,而是傳遞實 參或者返回變量的一份臨時的拷貝,因此用值作為參數或者返回值類型,效率是非常低下的,尤其是當參數或者返回 值類型非常大時,效率就更低
#include <time.h> struct A { int a[10000]; };void TestFunc1(A a) {}void TestFunc2(A& a) {}void TestRefAndValue() { A a;// 以值作為函數參數 size_t begin1 = clock(); for (size_t i = 0; i < 10000; ++i) TestFunc1(a); size_t end1 = clock();// 以引用作為函數參數 size_t begin2 = clock(); for (size_t i = 0; i < 10000; ++i) TestFunc2(a); size_t end2 = clock();// 分別計算兩個函數運行結束后的時間cout << "TestFunc1(int*)-time:" << end1 - begin1 << endl; cout << "TestFunc2(int&)-time:" << end2 - begin2 << endl;}// 運行多次,檢測值和引用在傳參方面的效率區別
int main(){ for (int i = 0; i < 10; ++i) { TestRefAndValue(); } return 0; }
值和引用的作為返回值類型的性能比較
#include <time.h> struct A { int a[10000]; };A a;A TestFunc1() { return a; }A& TestFunc2() { return a; }void TestReturnByRefOrValue() { // 以值作為函數的返回值類型 size_t begin1 = clock(); for (size_t i = 0; i < 100000; ++i) TestFunc1(); size_t end1 = clock();// 以引用作為函數的返回值類型 size_t begin2 = clock(); for (size_t i = 0; i < 100000; ++i) TestFunc2(); size_t end2 = clock();// 計算兩個函數運算完成之后的時間 cout << "TestFunc1 time:" << end1 - begin1 << endl; cout << "TestFunc2 time:" << end2 - begin2 << endl; }
通過上述代碼的比較,發現傳值和指針在作為傳參以及返回值類型上效率相差很大。
引用和指針的區別
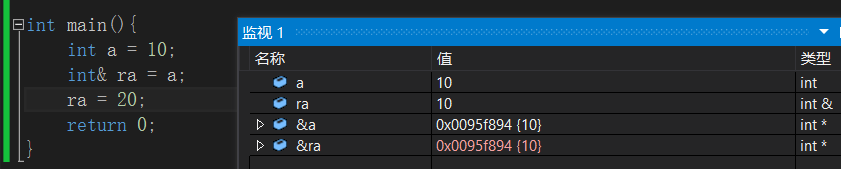
在語法概念上引用就是一個別名,沒有獨立空間,和其引用實體共用同一塊空間。
int main() {int a = 10; int& ra = a;cout<<"&a = "<<&a<<endl; cout<<"&ra = "<<&ra<<endl;return 0; }
在底層實現上實際是有空間的,因為引用是按照指針方式來實現的
int main() {
int a = 10;int& ra = a;ra = 20;int* pa = &a;*pa = 20;return 0;}
我們來看下引用和指針的匯編代碼對比:

引用和指針的不同點:
- 引用在定義時必須初始化,指針沒有要求
- 引用在初始化時引用一個實體后,就不能再引用其他實體,而指針可以在任何時候指向任何一個同類型實 體
- 沒有NULL引用,但有NULL指針
- 在sizeof中含義不同:引用結果為引用類型的大小,但指針始終是地址空間所占字節個數(32位平臺下占4 個字節)
- 引用自加即引用的實體增加1,指針自加即指針向后偏移一個類型的大小
- 有多級指針,但是沒有多級引用
- 訪問實體方式不同,指針需要顯式解引用,引用編譯器自己處理 8. 引用比指針使用起來相對更安全



調度方法))
)
)


基于范圍的for循環(C++11). 指針空值nullptr(C++11)))

)

電話簿(文件存儲))


)

)

