系統編程:
進程概念->進程控制->基礎IO->進程間通信->進程信號->多線程
進程概念
馮諾依曼體系結構----現代計算機硬件體系結構

馮諾依曼體系結構----現代計算機硬件體系結構
計算機五大硬件單元:輸入設備:鍵盤輸出設備:顯示器存儲器:內存-外存---固態接口類型SATA SATA3 PCI-E(目前最好)運算器:CPU—主頻2.5GHz,主頻越大代表時鐘震蕩周期越高,代表1s中處理的指令也就越多控制器:CPU所有設備都是圍繞存儲器工作的
關于馮諾依曼,必須強調幾點:
- 這里的存儲器指的是內存 不考慮緩存情況,
- 這里的CPU能且只能對內存進行讀寫,
- 不能訪問外設(輸入或輸出設備) 外設(輸入或輸出設備)要輸入或者輸出數據,也只能寫入內存或者從內存中讀取。
- 一句話,所有設備都只能直接和內存打交道。
對馮諾依曼的理解,不能停留在概念上,要深入到對軟件數據流理解上,請解釋,從你登錄上qq開始和某位朋友聊 天開始,數據的流動過程。從你打開窗口,開始給他發消息,到他的到消息之后的數據流動過程。如果是在qq上發 送文件呢?
硬件決定了軟件的行為
操作系統—管理

操作系統:
一個軟件安裝在計算機硬件上
目的:
為了讓計算機更加好用—功能:合理統籌管理計算機上邊的軟硬件資源
管理:
先描述使用pcb描述進程,使用雙向鏈表將pcb串起來進行管理,再組織。
庫函數與系統調用接口的關系:
封裝關系:庫函數封裝了系統調用接口,是上下級的調用關系
進程概念----進程是什么
進行中的程序
linux是一個多任務操作系統,表示有大量的程序需要被cpu調度運行,這時候cpu使用了分時技術,分別輪詢處理每一個進程,在進程程序切換調度時,需要記錄運行信息,因此操作系統在調度進程在cpu上運行時,使用pcb對運行中的程序進行描述,通過調度pcb完成對進程的調度,因此進程是pcb。
pcb對運行中程序進行描述
每一個運行的程序都是pcb
在操作系統角度,操作系統通過pcb來控制一個進程的運行,這個pcb也叫進程描述符,描述了一個運行中的程序
Linux操作系統下的PCB是task_struct結構體(用雙向鏈表進行組織的)
什么時task_struct結構體
參考鏈接
task_struct結構體中的內容
- 標示符: 描述本進程的唯一標示符,用來區別其他進程。
- 狀態: 任務狀態,退出代碼,退出信號等。
- 優先級: 相對于其他進程的優先級。
- 程序計數器: 程序中即將被執行的下一條指令的地址。
- 內存指針: 包括程序代碼和進程相關數據的指針,還有和其他進程共享的內存塊的指針
- 上下文數據: 進程執行時處理器的寄存器中的數據[休學例子,要加圖CPU,寄存器]。
- I/O狀態信息: 包括顯示的I/O請求,分配給進程的I/O設備和被進程使用的文件列表。
- 記賬信息: 可能包括處理器時間總和,使用的時鐘數總和,時間限制,記賬號等。
- 其他信息
內存指針
pcb中有一個指針指向了當前要運行的程序
cpu通過pcb內存指針知道代碼在什么位置,然后加載到內存上面
cpu分時機制
不會體會到卡頓的原因,調度進程時,不會一直在一個進程上面運行,輪詢調度pcb 。
每個都執行一段時間,切換速度很快。
每個進程只運行很短的一段時間(時間片)
程序計數器
即將執行的指令的地址
上下文數據
cpu正在處理的數據是什么
標識符PID
每一個進程都有一個ID
進程狀態
當前進程處于什么狀態
優先級
前臺進程(交互式進程)優先級更高
批處理(后臺進程)
IO狀態信息
每一個進程里面都會打開很多的文件,打開文件就要進行管理
記錄描述文件,所以需要保存下來這些信息
記賬信息
一個進程大致在cpu上運行了多長時間
進程查看
ps
-ef
-aux 查看系統所有進程信息
- /proc 保存系統中正在運行的程序信息
- pid_t getpid() 獲取調用進程的pid

- 根目錄下的proc/目錄存放的就是當前操作系統上面正在運行中的程序的運行信息
例如
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main()
{ while(1){ sleep(1); } return 0;
}

通過系統調用獲取進程標示符
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main()
{ printf("pid: %d\n", getpid()); printf("ppid: %d\n", getppid()); return 0;
}

進程創建
創建進程就是創建pcb

用fork創建進程
fork()—通過復制調用進程(父進程)創建一個新的進程(子進程)
子進程與父進程完全相同

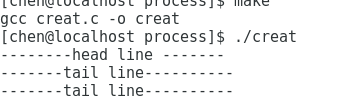
head line 打印了一次
tail line 打印了兩次

復制了父進程的pcb(意味著和父進程擁有一樣的內存指針,程序計數器,上下文數據):
和父進程運行相同的代碼,相同的運行位置,
處理一樣的數據
父子進程代碼共享,數據獨有 。
同一個內存區域,打印的值相同
子進程創建成功都是從下一步指令開始運行
如何分辨父子進程:通過返回值

父子進程不一定誰先運行,要看cpu調哪個pcb
父進程:
返回子進程的pid,pid>0
子進程:
返回0
失敗:
返回-1
為什么要創建子進程?意義何在?
- 分攤壓力,cpu資源足夠的情況父子進程同時處理數據,效率高
- 希望子進程完成其他的任務
進程狀態
普遍的系統的三種狀態
就緒,運行,阻塞

Linux進程狀態:
- 運行態(R)
- 可中斷睡眠態(S)
- 不可中斷睡眠態(D)
- 停止態(T)
- 僵死態(Z)
- 死亡態(X)
- 追蹤態(t)

加號代表前臺進程
cpu使用率非常高,什么原因?
死循環。
殺死進程
kill 進程ID
普通殺死進程殺不死停止態進程

要用強殺
kill -9 進程ID

僵尸進程:
處于僵死態的進程----進程退出后,資源沒有完全釋放(沒有完全退出)
強殺都殺不死
如何產生?

子進程先于父進程退出,將自己退出原因保存在pcb中,操作系統檢測到子進程退出,因為父進程有可能關注退出原因,所以不敢隨意釋放所有資源,通知父進程子進程的退出,但是這時父進程可能正在打麻將,沒有關注到這個通知,導致子進程退出了
但是資源一直沒有 釋放,處于僵尸進程,處于僵死狀態,成為僵尸進程。
危害:資源泄露,一個用戶能夠創建的進程是有限的,導致新進程創建失敗
處理:干掉父進程
如何避免:
進程等待
孤兒進程:
父進程先于子進程退出,子進程成為孤兒進程,運行在操作系統后臺,父進程成為1號進程(被領養)
孤兒進程的使命就是不斷奮斗最后成為守護進程
守護進程/精靈進程
特殊的孤兒進程 一個特殊的孤兒進程(脫離終端,脫離登會話的孤兒進程)
進程優先級
通過一個評級來決定一個進程的cpu資源優先分配權
為了讓計算機運行的更加合理
(因為進程的性質各有不同—批處理/交互式)
查看:
ps -l
修改:優先級無法直接修改,但是可以通過修改NI的值,來調整PRI的值
PRI=PRI+NI
renice程序運行后修改 (nice的范圍(-20~19))
Renic -n ni_val -p pid
nice程序運行時指定
nice -n ni_val ./main
優先級調整更多的是針對cpu密集型程序(對cpu資源要求比較高)
磁盤密集型程序因為本事呢對cpu資源要求不是很高,因此大多數情況下,沒必要調整

我們很容易注意到其中的幾個重要信息,有下:
UID : 代表執行者的身份
PID : 代表這個進程的代號PPID :代表這個進程是由哪個進程發展衍生而來的,亦即父進程的代號PRI :代表這個進程可被執行的優先級,其值越小越早被執行 NI :代表這個進程的nice值
PRI and NI
PRI也還是比較好理解的,即進程的優先級,或者通俗點說就是程序被CPU執行的先后順序,此值越小 進程的優先級別越高那NI呢?就是我們所要說的nice值了,其表示進程可被執行的優先級的修正數值 PRI值越小越快被執行,那么加入nice值后,將會使得PRI變為:PRI(new)=PRI(old)+nice這樣,當nice值為負值的時候,那么該程序將會優先級值將變小,即其優先級會變高,則其越快被執行 所以,調整進程優先級,在Linux下,就是調整進程nice值 nice其取值范圍是-20至19,一共40個級別需要強調一點的是,進程的nice值不是進程的優先級,他們不是一個概念,但是進程nice值會影響到進 程的優先級變化。可以理解nice值是進程優先級的修正修正數據
用top命令更改已存在進程的nice
top 進入top后按“r”–>輸入進程PID–>輸入nice的值
競爭性:
系統進程數目眾多,而CPU資源只有少量,甚至1個,所以進程之間是具有競爭屬性的。為了高 效完成任務,更合理競爭相關資源,便具有了優先級
獨立性:
多進程運行,需要獨享各種資源,多進程運行期間互不干擾
并行:
多個進程在多個CPU下分別,同時進行運行,這稱之為并行
并發:
多個進程在一個CPU下采用進程切換的方式,在一段時間之內,讓多個進程都得以推進,稱之為 并發
環境變量
環境變量(environment variables)一般是指在操作系統中用來指定操作系統運行環境的一些參數 如:我們在編寫C/C++代碼的時候,在鏈接的時候,從來不知道我們的所鏈接的動態靜態庫在哪里,但 是照樣可以鏈接成功,生成可執行程序,原因就是有相關環境變量幫助編譯器進行查找。 環境變量通常具有某些特殊用途,還有在系統當中通常具有全局特性
就是內存解釋
和環境變量相關的命令
- echo: 顯示某個環境變量值
- export: 設置一個新的環境變量
- env: 顯示所有環境變量
- unset: 清除環境變量
- set: 顯示本地定義的shell變量和環境變量
環境變量的組織方式

每個程序都會收到一張環境表,環境表是一個字符指針數組,每個指針指向一個以’\0’結尾的環境字符串
常見環境變量:HOME SHLL PATH
通過第三方變量environ獲取
**int argc 參數個數
char argv[] 字符串指針數組放的是參數
char env[] 這個字符串指針數組所保存的就是環境變量
#include <stdio.h>int main(int argc, char *argv[], char *env[]){ int i = 0; for(; env[i]; i++){ printf("%s\n", env[i]); } return 0; }
通過系統調用獲取或設置環境變量
#include <stdio.h> #include <stdlib.h>int main()
{ printf("%s\n", getenv("PATH"));
return 0; }
環境變量通常是具有全局屬性的
環境變量通常具有全局屬性,可以被子進程繼承下去
#include <stdio.h> #include <stdlib.h>
int main()
{ char * env = getenv("MYENV"); if(env){ printf("%s\n", env); } return 0;}
直接查看,發現沒有結果,說明該環境變量根本不存在
導出環境變量 export MYENV=“hello world”
再次運行程序,發現結果有了!說明:環境變量是可以被子進程繼承下去的!想想為什么?
子進程崩潰了,對shell本身沒有影響
程序地址空間
為什么要用虛擬地址空間+頁表:保持進程獨立性+充分利用內存+內存訪問控制
段頁式內存管理:段號+段內地址+頁內偏移
段式內存管理:段號+段內地址
頁式內存管理:頁號+頁內偏移

#include <stdio.h> #include <unistd.h> #include <stdlib.h>
int g_val = 0;
int main(){ pid_t id = fork(); if(id < 0){ perror("fork"); return 0; }else if(id == 0){ //childprintf("child[%d]: %d : %p\n", getpid(), g_val, &g_val); }else{ //parent printf("parent[%d]: %d : %p\n", getpid(), g_val, &g_val); } sleep(1); return 0; }
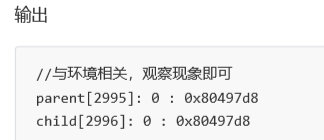
我們發現,輸出出來的變量值和地址是一模一樣的,很好理解呀,因為子進程按照父進程為模版,父子并沒有對變 量進行進行任何修改。可是將代碼稍加改動:
#include <stdio.h>#include <unistd.h>#include <stdlib.h>int g_val = 0;int main()
{
pid_t id = fork(); if(id < 0){ perror("fork"); return 0; } else if(id == 0){ //child,子進程肯定先跑完,也就是子進程先修改,完成之后,父進程再讀取 g_val=100; printf("child[%d]: %d : %p\n", getpid(), g_val, &g_val); }else{ //parent sleep(3); printf("parent[%d]: %d : %p\n", getpid(), g_val, &g_val); } sleep(1); return 0; }

我們發現,父子進程,輸出地址是一致的,但是變量內容不一樣!能得出如下結論
變量內容不一樣,所以父子進程輸出的變量絕對不是同一個變量
但地址值是一樣的,說明,該地址絕對不是物理地址!在Linux地址下,這種地址叫做 虛擬地址 我們在用C/C++語言所看到的地址,全部都是虛擬地址!物理地址,用戶一概看不到,由OS統一管理
OS必須負責將 虛擬地址 轉化成 物理地址 。
地址:內存區域的編號
-----進程的虛擬地址空間—內存描述符----mm_struct
操作系統通過mm_struct這個結構體給進程描述了一個虛擬的地址
如何描述:
mm_struct{
ulong size;
ulong code_start;
ulong code_end;
ulong data_start;
ulong data_end;
}

為什么要使用虛擬地址空間虛擬地址空間+頁表
通過頁表進行映射,頁表可以進行標記,當前地址是可讀還是可寫
提高內存利用率
對內存訪問進行控制
保證進程獨立性
虛擬內存的方式
寫時拷貝技術:提高子進程創建效率
父進程創建了子進程,但是并沒有直接給子進程開辟內存,拷貝數據,
而是跟父進程映射到同一位置,
但是如果內存中數據發生的改變,那么對于改變的這塊內存,
需要重新給子進程開辟內存,并且更新頁表信息。
進程O(1)調度方法
一個CPU擁有一個runqueue
普通優先級:100~139(我們都是普通的優先級,想想nice值的取值范圍,可與之對應!實時優先級:0~99(不關心)
活動隊列
時間片還沒有結束的所有進程都按照優先級放在該隊列 nr_active: 總共有多少個運行狀態的進程
queue[140]: 一個元素就是一個進程隊列,相同優先級的進程按照FIFO規則進行排隊調度,所以,數組下 標就是優先級!
從該結構中,選擇一個最合適的進程,過程是怎么的呢?
- 從0下表開始遍歷queue[140]
- 找到第一個非空隊列,該隊列必定為優先級最高的隊列
- 拿到選中隊列的第一個進程,開始運行,調度完成!
- 遍歷queue[140]時間復雜度是常數!但還是太低效了!
bitmap[5]:一共140個優先級,一共140個進程隊列,為了提高查找非空隊列的效率,就可以用5*32個 比特位表示隊列是否為空,這樣,便可以大大提高查找效率
過期隊列
過期隊列和活動隊列結構一模一樣過期隊列上放置的進程,都是時間片耗盡的進程 當活動隊列上的進程都被處理完畢之后,對過期隊列的進程進行時間片重新計算
active指針和expired指針
-
active指針永遠指向活動隊列
-
expired指針永遠指向過期隊列
-
可是活動隊列上的進程會越來越少,過期隊列上的進程會越來越多,因為進程時間片到期時一直都存在 的。
-
沒關系,在合適的時候,只要能夠交換active指針和expired指針的內容,就相當于有具有了一批新的活 動進程!
在系統當中查找一個最合適調度的進程的時間復雜度是一個常數,不隨著進程增多而導致時間成本增 加,我們稱之為進程調度O(1)算法
)
)


基于范圍的for循環(C++11). 指針空值nullptr(C++11)))

)

電話簿(文件存儲))


)

)





