文章目錄
- 整數集合
- 跳躍表
- 壓縮列表
- 總結
整數集合
當一個集合只包含整數,且這個集合的元素不多的時候,Redis 就會使用整數集合 intset 。首先看 intset 的數據結構:
typedef struct intset {// 編碼方式uint32_t encoding;// 集合包含的元素數量uint32_t length;// 保存元素的數組int8_t contents[];
} intset;
其實 intset 的數據結構比較好理解。一個數據保存元素,length 保存元素的數量,也就是contents的大小,encoding 用于保存數據的編碼方式。
通過代碼我們可以知道,encoding 的編碼類型包括了:
#define INTSET_ENC_INT16 (sizeof(int16_t))
#define INTSET_ENC_INT32 (sizeof(int32_t))
#define INTSET_ENC_INT64 (sizeof(int64_t))
實際上我們可以看出來。 Redis encoding的類型,就是指數據的大小。作為一個內存數據庫,采用這種設計就是為了節約內存。
既然有從小到大的三個數據結構,在插入數據的時候盡可能使用小的數據結構來節約內存,如果插入的數據大于原有的數據結構,就會觸發擴容。
擴容有三個步驟:
- 根據新元素的類型,修改整個數組的數據類型,并重新分配空間
- 將原有的的數據,裝換為新的數據類型,重新放到應該在的位置上,且保存順序性
- 再插入新元素
整數集合不支持降級操作,一旦升級就不能降級了。
跳躍表
跳躍表是鏈表的一種,是一種利用空間換時間的數據結構。跳表平均支持 O(logN),最壞O(N)復雜度的查找。
跳表是由一個zskiplist 和 多個 zskiplistNode 組成。我們先看看他們的結構:
/* ZSETs use a specialized version of Skiplists */
/** 跳躍表節點*/
typedef struct zskiplistNode {// 成員對象robj *obj;// 分值double score;// 后退指針struct zskiplistNode *backward;// 層struct zskiplistLevel {// 前進指針struct zskiplistNode *forward;// 跨度unsigned int span;} level[];} zskiplistNode;/** 跳躍表*/
typedef struct zskiplist {// 表頭節點和表尾節點struct zskiplistNode *header, *tail;// 表中節點的數量unsigned long length;// 表中層數最大的節點的層數int level;} zskiplist;
所以根據這個代碼我們可以畫出如下的結構圖:
[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-8veqZuZy-1573628505436)(media/15663755251342/15663757297856.jpg)]
其實跳表就是一個利用空間換時間的數據結構,利用 level 作為鏈表的索引。
之前有人問過 Redis 的作者 為什么使用跳躍表,而不是 tree 來構建索引?作者的回答是:
- 省內存。
- 服務于 ZRANGE 或者 ZREVRANGE 是一個典型的鏈表場景。時間復雜度的表現和平衡樹差不多。
- 最重要的一點是跳躍表的實現很簡單就能達到 O(logN)的級別。
壓縮列表
壓縮鏈表 Redis 作者的介紹是,為了盡可能節約內存設計出來的雙向鏈表。
對于一個壓縮列表代碼里注釋給出的數據結構如下:
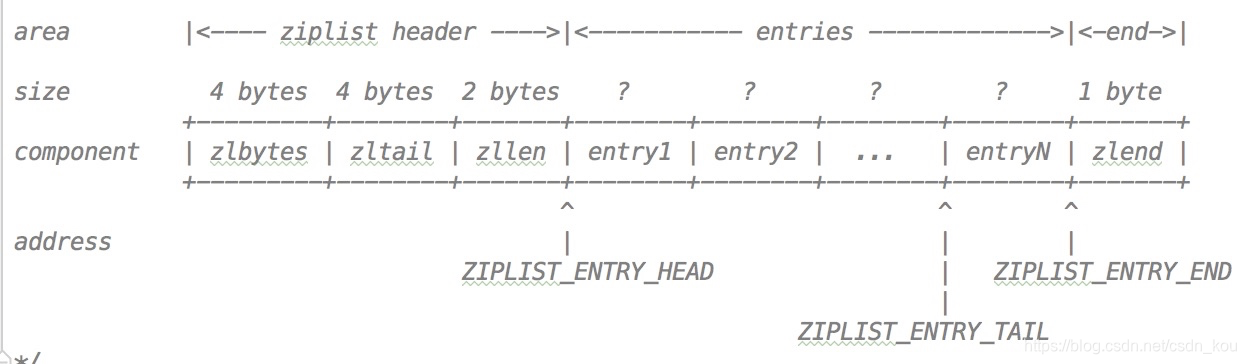
zlbytes 表示的是整個壓縮列表使用的內存字節數zltail 指定了壓縮列表的尾節點的偏移量zllen 是壓縮列表 entry 的數量entry 就是 ziplist 的節點zlend 標記壓縮列表的末端
這個列表中還有單個指針:
ZIPLIST_ENTRY_HEAD 列表開始節點的頭偏移量ZIPLIST_ENTRY_TAIL 列表結束節點的頭偏移量ZIPLIST_ENTRY_END 列表的尾節點結束的偏移量
再看看一個 entry 的結構:
/** 保存 ziplist 節點信息的結構*/
typedef struct zlentry {// prevrawlen :前置節點的長度// prevrawlensize :編碼 prevrawlen 所需的字節大小unsigned int prevrawlensize, prevrawlen;// len :當前節點值的長度// lensize :編碼 len 所需的字節大小unsigned int lensize, len;// 當前節點 header 的大小// 等于 prevrawlensize + lensizeunsigned int headersize;// 當前節點值所使用的編碼類型unsigned char encoding;// 指向當前節點的指針unsigned char *p;} zlentry;
依次解釋一下這幾個參數。
prevrawlen 前置節點的長度,這里多了一個 size,其實是記錄了 prevrawlen 的尺寸。Redis 為了節約內存并不是直接使用默認的 int 的長度,而是逐漸升級的。
同理 len 記錄的是當前節點的長度,lensize 記錄的是 len 的長度。
headersize 就是前文提到的兩個 size 之和。
encoding 就是這個節點的數據類型。這里注意一下 encoding 的類型只包括整數和字符串。
p 節點的指針,不用過多的解釋。
需要注意一點,因為每個節點都保存了前一個節點的長度,如果發生了更新或者刪除節點,則這個節點之后的數據也需要修改,有一種最壞的情況就是如果每個節點都處于需要擴容的零界點,就會造成這個節點之后的節點都要修改 size 這個參數,引發連鎖反應。這個時候就是 壓縮鏈表最壞的時間復雜度 O(n^2)。 不過所有節點都處于臨界值,這樣的概率可以說比較小。
總結
至此Redis的基本數據結構就介紹完了。我們可以看到 Redis 對內存的使用真是“斤斤計較”,對于內存是使用特別節約。同時 Redis 作為一個單線程應用,不用考慮并發的問題,將很多類似 size 或者 length 的參數暴露出來,將很多 O(n) 的操作降低為 O(1)。


—— 字符串,列表,哈希,集合,有序集合)

—— Redis 數據庫、鍵過期的實現)

—— Redis 數據結構dict.c)

—— 當你啟動Redis的時候,Redis做了什么)

—— Redis字符串相關函數實現)








