其實這一次課還蠻好理解的:
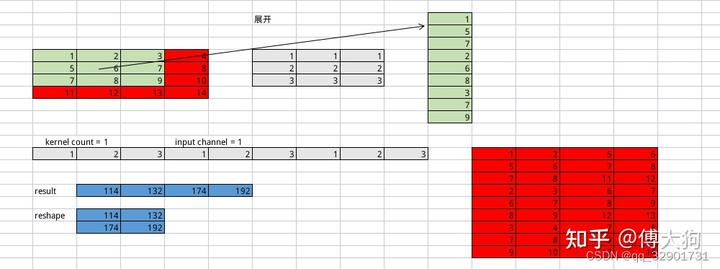
?首先將kernel展平:
for (uint32_t g = 0; g < groups; ++g) {std::vector<arma::fmat> kernel_matrix_arr(kernel_count_group);arma::fmat kernel_matrix_c(1, row_len * input_c_group);for (uint32_t k = 0; k < kernel_count_group; ++k) {const std::shared_ptr<Tensor<float>> &kernel =weights.at(k + g * kernel_count_group);for (uint32_t ic = 0; ic < input_c_group; ++ic) {memcpy(kernel_matrix_c.memptr() + row_len * ic,kernel->at(ic).memptr(), row_len * sizeof(float));}LOG(INFO) << "kernel展開后: " << "\n" << kernel_matrix_c;kernel_matrix_arr.at(k) = kernel_matrix_c;}
將原來的kernel放到kernel_matrix_c里面,之后如果是多個channel,也就是input_c有多個,那就按照rowlen*ic依次存放到里面。
將輸入input展平:
//按照上面的圖就是input = 3*9 ,4的這樣一個空間arma::fmat input_matrix(input_c_group * row_len, col_len);for (uint32_t ic = 0; ic < input_c_group; ++ic) {const arma::fmat &input_channel = input_->at(ic + g * input_c_group);int current_col = 0;
//下面是以窗口滑動的順序選取for (uint32_t w = 0; w < input_w - kernel_w + 1; w += stride_w) {for (uint32_t r = 0; r < input_h - kernel_h + 1; r += stride_h) {float *input_matrix_c_ptr =input_matrix.colptr(current_col) + ic * row_len;//對準窗口位置,比如對第一個就是對準紅色, 黃色, 綠色current_col += 1;for (uint32_t kw = 0; kw < kernel_w; ++kw) {const float *region_ptr = input_channel.colptr(w + kw) + r;memcpy(input_matrix_c_ptr, region_ptr, kernel_h * sizeof(float));input_matrix_c_ptr += kernel_h;}}}}LOG(INFO) << "input展開后: " << "\n" << input_matrix;
對于:
for (uint32_t kw = 0; kw < kernel_w; ++kw) {const float *region_ptr = input_channel.colptr(w + kw) + r;memcpy(input_matrix_c_ptr, region_ptr, kernel_h * sizeof(float));input_matrix_c_ptr += kernel_h;}w+kw指向的是窗口的列,r指向的是窗口的行
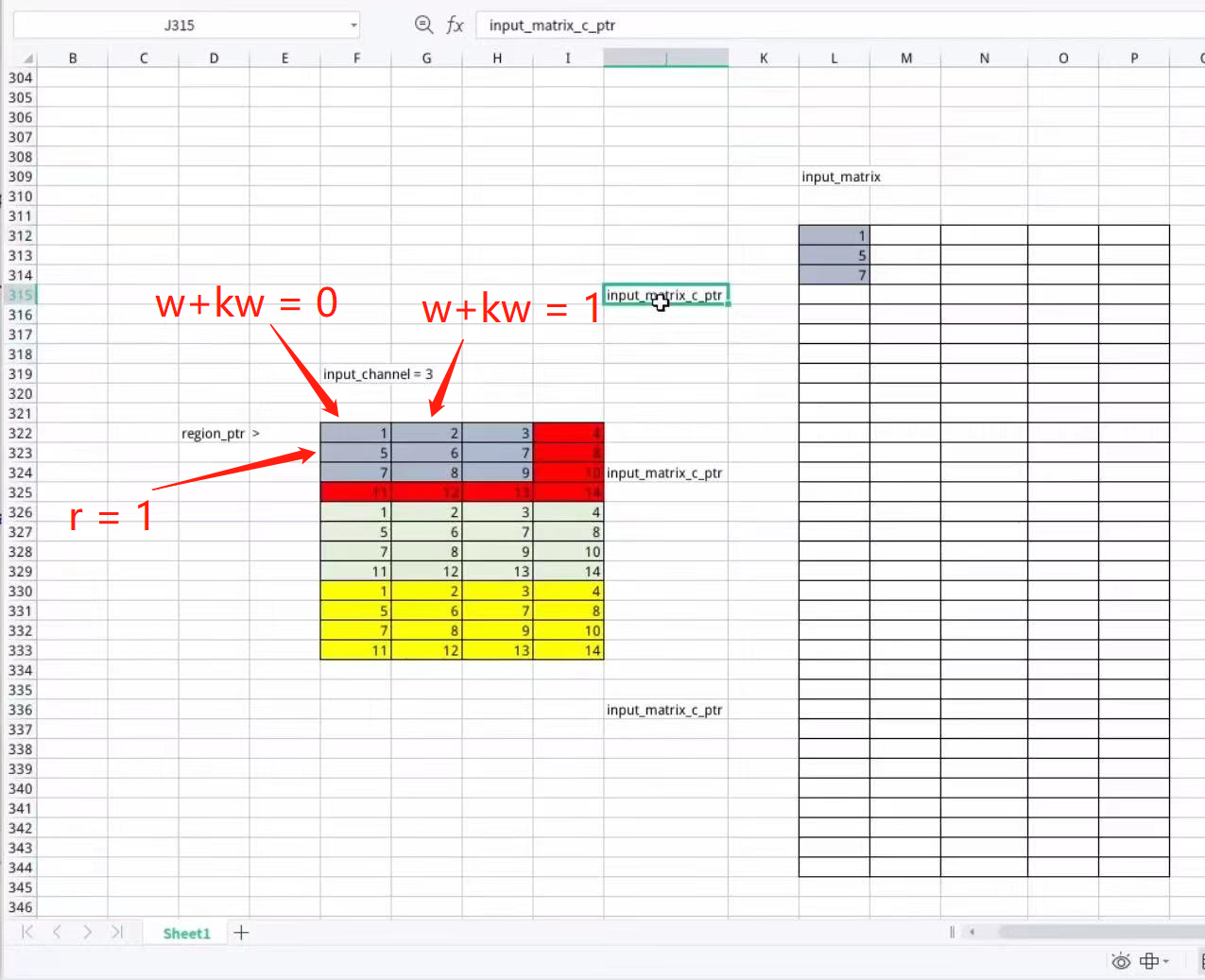
然后對于每個窗口的以kernel的列為標準復制過去。
最后兩個矩陣相乘就可以得到結果
連接服務器及其進行文件傳輸的各種方式的詳解)









 11. 旋轉數組的最小數字 ——【Leetcode每日一題】)




——CentOS7定時任務)


)
)