0x01 re基礎
使用re模塊,必須先導入re模塊
import re
- findall():匹配所有符合正則的內容,返回的是一個列表
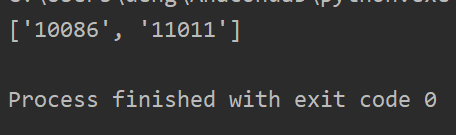
import restr = "我的電話:10086,女朋友電話:11011"
list = re.findall('\d+',str)
print(list)
- finditer():匹配所有符合的內容,返回的是迭代器,使用group可取到內容
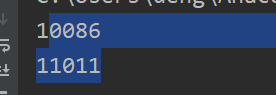
import restr = "我的電話:10086,女朋友電話:11011"
ite = re.finditer('\d+',str)
for i in ite:print(i.group())
- search():只匹配一個,返回的是match對象,獲得匹配數據要使用group()
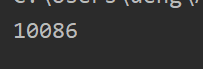
import restr = "我的電話:10086,女朋友電話:11011"
ite = re.search('\d+',str)
print(ite.group())
- match():只在開頭匹配
import restr = "我的電話:10086,女朋友電話:11011"
ite = re.match('\d+',str)
print(ite.group())

將10086放在字符串最前面就可以匹配了
- compile():預加載正則表達式
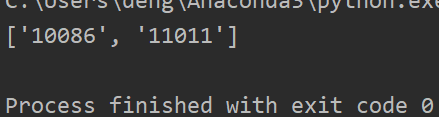
import restr = "我的電話:10086,女朋友電話:11011"com = re.compile('\d+')
lst = com.findall(str)
print(lst)
0x02 案例
案例1
獲取下面字符串里面的名字和ID:
'''
<div class='jcw'><span id='1'>金城武</span></div>
<div class='hg'><span id='2'>胡歌</span></div>
<div class='pyy'><span id='3'>彭于晏</span></div>
<div class='az'><span id='4'>阿祖</span></div>
'''程序:
import restr = '''
<div class='jcw'><span id='1'>金城武</span></div>
<div class='hg'><span id='2'>胡歌</span></div>
<div class='pyy'><span id='3'>彭于晏</span></div>
<div class='az'><span id='4'>阿祖</span></div>
'''com = re.compile("<div class='.*?'><span id='(?P<id>\d+)'>(?P<name>.*?)</span></div>")
result = com.finditer(str)
for i in result:print(i.group('id'),i.group('name'))在預編譯中有(?P\d+),(?P)是告訴處理器,括號里面的內容需要注意,我需要單獨拿出來,<>里面是告訴處理器,這里拿出來的內容叫什么名字,后面可以根據這個名字對(?P)匹配的內容單獨處理,比如后面group('id')直接根據名字取出數據

案例2
爬取豆瓣電影top250的電影名、導演、時間
程序:
import re
import requestsurl = 'https://movie.douban.com/top250'headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362'}
response = requests.get(url=url,headers=headers)
content = response.textobj = re.compile('<li>.*?<div class="item">.*?<div class="info">''.*?<span class="title">(?P<name>.*?)</span>.*?''<p class="">(?P<name2>.*?) .*?<br>(?P<age>.*?) ',re.S)result = obj.finditer(content)
for it in result:print(it.group("name"))print(it.group('name2').strip())print(it.group('age').strip())
結果:

compile中的re.S是讓.匹配任何字符,換行符也匹配

方法及示例)





方法與示例)

)


方法(帶示例))


)

方法與示例)

