0x01 基礎
使用bs4首先要安裝,安裝后導入
import bs4
bs對象有兩個方法,一個是find,另一個是find_all
- find(標簽名,屬性值):只返回一個,返回也是bs對象,可以繼續用find和find_all方法
find(name='table',attrs={'class':'hq_table'})
- find_all(標簽名,屬性值):返回所有符合條件,返回也是bs對象,可以繼續用find和find_all方法
find_all(name='tr')
0x02 案例
爬取http://www.xinfadi.com.cn/marketanalysis/0/list/1.shtml這個頁面菜價相關信息
程序:
import requests
import bs4url = 'http://www.xinfadi.com.cn/marketanalysis/0/list/1.shtml'response = requests.get(url)
page_content = response.text
#print(page_content)
bs_page = bs4.BeautifulSoup(page_content,'html.parser')
table = bs_page.find(name='table',attrs={'class':'hq_table'})
trs = table.find_all(name='tr')
for tr in trs:tds = tr.find_all(name='td')for td in tds:print(td.text,end=' ')print()page_content是我們獲取網頁的源碼,bs4.BeautifulSoup(page_content,'html.parser'),html.parser是告訴BeautifulSoup解析什么文件
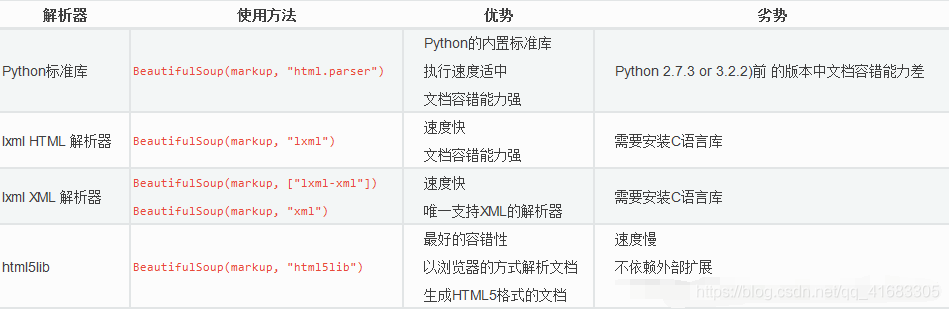
運行結果:

我們將這些數據存儲到文件中
程序:
import requests
import bs4
import csv
url = 'http://www.xinfadi.com.cn/marketanalysis/0/list/1.shtml'fl = open('菜價.csv','w',encoding='utf-8')
csvwrite = csv.writer(fl)response = requests.get(url)
page_content = response.text
#print(page_content)
bs_page = bs4.BeautifulSoup(page_content,'html.parser')
table = bs_page.find(name='table',attrs={'class':'hq_table'})
trs = table.find_all(name='tr')
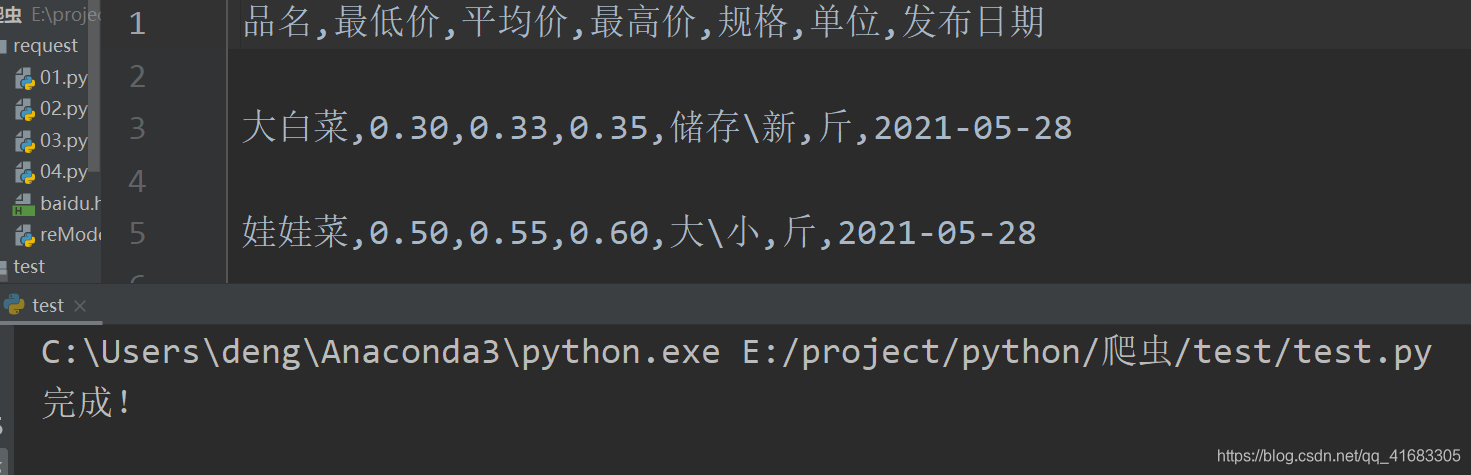
for tr in trs:tds = tr.find_all(name='td')name = tds[0].textprice_low = tds[1].textprice_ave = tds[2].textprice_high = tds[3].textnorm = tds[4].textunit = tds[5].textdata = tds[6].textcsvwrite.writerow([name,price_low,price_ave,price_high,norm,unit,data])fl.close()
print('完成!')結果:
0x03 獲取標簽的屬性值
頁面:獲取a標簽的href值和name值
<!DOCTYPE html>
<html>
<head><meta content="text/html;charset=utf-8" http-equiv="content-type" /><meta content="IE=Edge" http-equiv="X-UA-Compatible" /><meta content="always" name="referrer" /><link href="https://ss1.bdstatic.com/5eN1bjq8AAUYm2zgoY3K/r/www/cache/bdorz/baidu.min.css" rel="stylesheet" type="text/css" /><title>百度一下,你就知道 </title>
</head>
<body link="#0000cc"><div id="wrapper"><div id="head"><div class="head_wrapper"><div id="u1"><a class="mnav" href="http://news.baidu.com" name="tj_trnews">新聞 </a><a class="mnav" href="https://www.hao123.com" name="tj_trhao123">hao123 </a><a class="mnav" href="http://map.baidu.com" name="tj_trmap">地圖 </a><a class="mnav" href="http://v.baidu.com" name="tj_trvideo">視頻 </a><a class="mnav" href="http://tieba.baidu.com" name="tj_trtieba">貼吧 </a><a class="bri" href="//www.baidu.com/more/" name="tj_briicon" style="display: block;">更多產品 </a></div></div></div></div>
</body>
</html>
- 獲取標簽的屬性,可以再我們獲取標簽時,再標簽后面加入屬性值,比如說a就是我們獲得標簽,a[‘href’]就是其鏈接內容
程序:
from bs4 import BeautifulSoupwith open('1.html','r',encoding='utf-8') as f:html = f.read()
soup = BeautifulSoup(html,'html.parser')print(soup.title)#獲取title標簽包含的內容
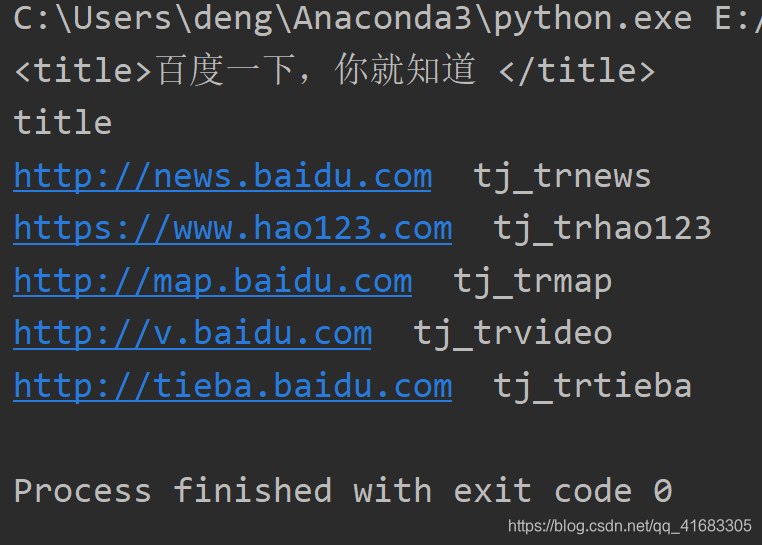
print(soup.title.name)a = soup.find_all(name='a',attrs={'class':'mnav'})
for i in a:print(i['href'],i['name'],sep=' ')運行結果:




方法與示例)

)


方法(帶示例))


)

方法與示例)




