上一篇文章LinkedList實現分析(一)——LinkedList初探與對象創建介紹了LinkedList中的一些重要屬性和構造方法,下面我們將詳細介紹一下LinkedList提高的常用方法的實現原理
元素添加
###add(E e)方法
往LinkedList添加元素,LinkedList提供了多重方式,首先介紹add方法,下面我們使用一個簡單的實例代碼來分析一下add方法的實現原理:
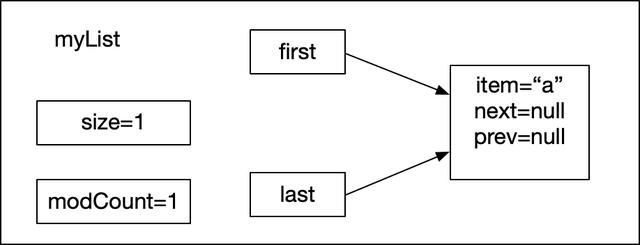
List myList = new LinkedList();//1myList.add("a"); //2myList.add("b"); //3myList.add("c"); //4執行第一行代碼后創建了一個空的myList對象,此時myList如下圖所示:
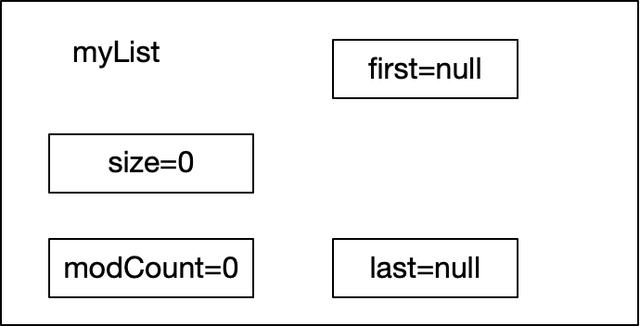
myList
然后執行第2行代碼myList.add("a"),把字符串"a"添加到myList中,通過debug方式進入add方法內部:
public boolean add(E e) { linkLast(e); return true;}add又調用linkLast方法,linkLast方法實現如下:
void linkLast(E e) { final Node l = last; final Node newNode = new Node<>(l, e, null); last = newNode; if (l == null) first = newNode; else l.next = newNode; size++; modCount++;}在linkLast內部,此時e="a"。首先把last,此時myList是新創建的對象,last=null,賦值給一個臨時變量 l,這里的做法是用來保存last的值,然后用元素e創建一個新的Node對象,這里是往myList的尾部添加元素,因此創建的Node節點的構造方法最后一個參數是null,而第一個參數表示的是插入元素e的前一個元素指針,因此需要傳入l,因為在整個LinkedList中last屬性表示的最后一個元素。當創建好包含e的newNode節點的時候,此時newNode就應該是myList的最后一個節點,也是第一個節點(l==null),因此把newNode賦值給last和first,然后把表示myList大學的size進行加一,最后對modCount加一,記錄了修改次數。執行完第2行代碼后,myList的狀態入下圖所示:
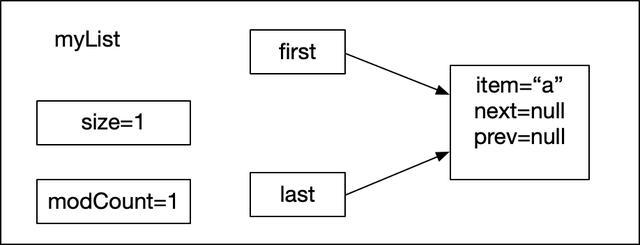
myList
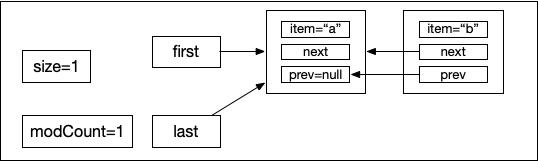
當示例代碼執行第3行代碼的時,同樣會執行linkLast,此時e=“b”。在進入linkLast方法的時候,last的值已經不在是null,而是剛剛創建的包含了“a”的Node節點對象,同樣把last先用一個臨時變量l保存起來,然后創建一個包含“b”的Node節點,這個時候該node節點的前一個節點是“a”所在的節點,因此構造函數 new Node<>(l, e, null),把新創建的newNode作為整個myList的最后一個節點: last = newNode,而由于l不為null,也就是last不為null,所以需要把新創建的節點放到myList中最后一個節點的后面: l.next = newNode,最后修改size和modCount的值,完成“b”元素的添加。此時myList的狀態如下圖所示:
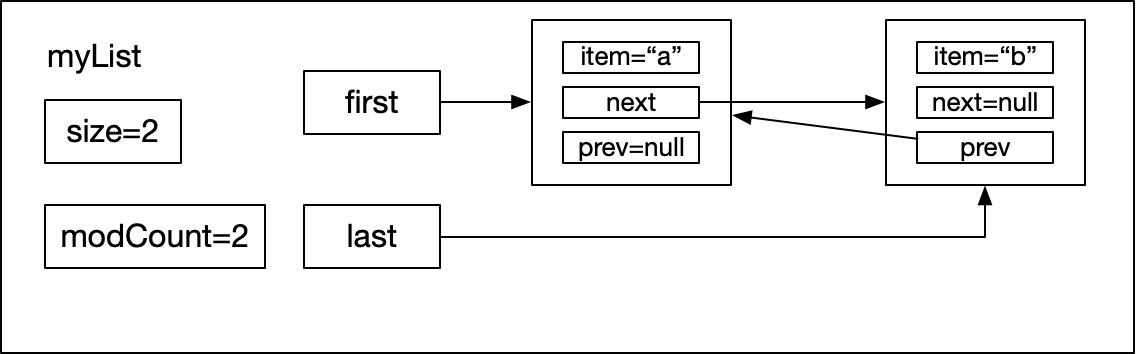
然后示例代碼執行到第4行,此時myList已經有2個node,根據上圖可知last指向了“b”node,然創建“c”的node對象,讓“c”的prev執行“b”,然后myList中的last指向“c”,“b”的next執行“c”,執行完后myList的狀態如下圖所示:
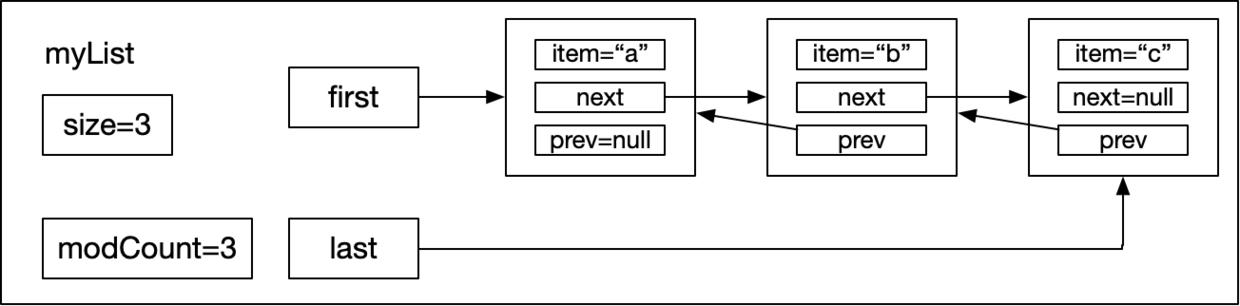
### add(int index, E element)
該方法是在指定的索引的位置插入一個元素,index值指定的索引位置,element是需要插入的元素信息。這里還是以一個示例為基礎進行對 add(int index, E element) 源碼的分析,示例代碼如下:
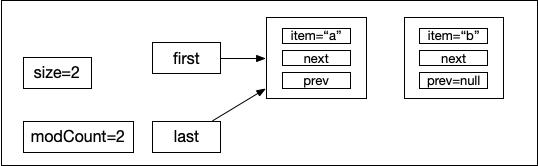
List myList = new LinkedList();//1myList.add("a"); //2myList.add(0,"b")//3當示例代碼執行完第2部的時候,myList的狀態如下圖所示:
然后執行第3行代碼,具體 add(int index, E element) 的源碼如下:
public void add(int index, E element) { checkPositionIndex(index);//index校驗 if (index == size) linkLast(element); else linkBefore(element, node(index));}首先是對傳入的index進行位置校驗,具體實現是要求index不能小于0,不能大于myList當前的大小。根據示例代碼,執行到第3行的時候,此時size=1,index=0,因此程序執行linkBefore方法,linkBefore是第一參數是新添加的元素element,第二個參數表示element需要被添加到myList中哪個元素的后面。這里傳入是位置索引,因此需要調用node(index)方法找到mylist中index對應的node對象,node方法實現如下:
Node node(int index) { if (index < (size >> 1)) { Node x = first; for (int i = 0; i < index; i++) x = x.next; return x; } else { Node x = last; for (int i = size - 1; i > index; i--) x = x.prev; return x;}這里源碼中使用了一個技巧,通過判斷傳入的index與整個list的大小(size)的1/2進行比較,如果index=size/2,那么對myList進行倒序遍歷。這里需要大家注意的是源碼中使用右移操作獲取size的1/2,這個技巧希望大家可以掌握:
>在java中,數字左移表示乘2,數字右移除2
由于當前myList的size=1,右移之后是0,index=0,因此執行else的語句,從last指向的node開始倒序遍歷,此時myList只有一個index=0所指向的元素就是last的值,因此把last返回。node方法執行完之后,開始執行linkBefore方法:
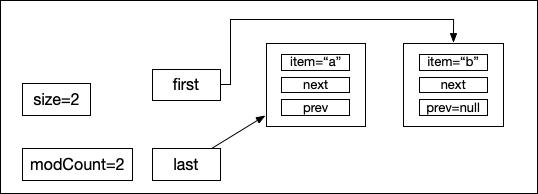
void linkBefore(E e, Node succ) { final Node pred = succ.prev; final Node newNode = new Node<>(pred, e, succ); succ.prev = newNode; if (pred == null) first = newNode; else pred.next = newNode; size++; modCount++;}linkBefore方法就是一個雙向列表的插入操作,首先把succ的前驅節點prev保存到臨時變量pred,使用傳入的e(根據示例代碼,此時e=“b”)創建一個新的Node對象:newNode,由于是在succ節點的前面插入新元素"b",因此newNode的前驅點是之前succ節點的前驅節點,newNode的后節點就是succ節點本身:final Node newNode = new Node<>(pred, e, succ),此時myList的狀態如下圖所示:
然后執行 succ.prev = newNode,是把原來succ指向的前驅節點改成了newNode,因為newNode插入了succ節點前面,因此succ的prev就是newNode,指向完的myList狀態如下:
然后是判斷pred是否為null,在myList的當前狀態中, succ.prev是null,pred也就是null,所以把first指向newNode,也就是在myList的頭結點succ之前添加一個新元素newNode,即 first = newNode;然后對size和modCount加一,執行完最后myList的狀態如下圖:
### addAll(Collection extends E> c)
下面介紹一下使用集合對象給LinkedList添加元素,addAll有兩個重載方法:
public boolean addAll(Collection extends E> c)public boolean addAll(int index, Collection extends E> c)在源碼中,addAll(Collection extends E> c)實際是調用了addAll(int index, Collection extends E> c) :
public boolean addAll(Collection extends E> c) { return addAll(size, c);}因此這里只介紹后面一個addAll的實現:
public boolean addAll(int index, Collection extends E> c) { checkPositionIndex(index); Object[] a = c.toArray(); int numNew = a.length; if (numNew == 0) return false; //下面的代碼是查詢需要插入位置的前驅和后繼節點 Node pred, succ; if (index == size) { succ = null; pred = last; } else { succ = node(index); pred = succ.prev; } //把a中的元素創建為一個列表 //并且讓pred指向a的最后一個節點 for (Object o : a) { Node newNode = new Node<>(pred, e, null); if (pred == null) first = newNode; else pred.next = newNode; pred = newNode; } //如果沒有后繼節點,那么c集合中最后一個節點就是 //整個list的最后節點 if (succ == null) { last = pred; } else { //如果在list找到插入的前驅和后繼節點 //把c中的最后一個節點的后繼節點指向succ //把后繼節點的前驅節點指向c中的最后一個節點 pred.next = succ; succ.prev = pred; } size += numNew; modCount++; return true;}addAll方法內部,首先還是判斷index的值是否合法,然后對傳入的Collection對象c進行驗證, 接著在源碼中定義了兩個變量:
Node pred, succ;pred表示需要插入c的前驅節點,succ表示c的后繼節點。當index=size表示是把c添加到LinkedList的尾部,因此執行succ=null和pred=last;否則調用 node(index)方法,找到后繼節點succ,然后把當前后繼節點的前驅節點賦值給pred。
找到所插入前驅和后繼節點之后,開始循環遍歷c,把c中的每一個元素創建一個Node對象,c中的前一個元素都是后一個元素的前驅節點,把c建立為一個鏈表。然后把c的鏈表插入的LinkedList中,具體見上面源碼的注釋,完成鏈表的連接操作只會,對size和modCount進行加1操作。
### 其他添加元素的方法
下面介紹一個往list頭插入元素的方法:
public void addFirst(E e) {linkFirst(e);}private void linkFirst(E e) { //保存第一個元素 final Node f = first; //頭插法,因此newNode的前驅節點是null,后繼節點是f final Node newNode = new Node<>(null, e, f); //讓新創建節點當整個list的頭節點 first = newNode; if (f == null) //如果f=null,表示當前list沒有一個元素,因此需要給last=newNode last = newNode; else //把之前的first接的前驅節點換成新創建的newNode f.prev = newNode; size++; modCount++; }頭插入的原理就是在整個list中,找到一個元素first,把first的前驅節點換成新插入的元素,然后把新傳入元素的后繼節點指向之前的頭節點,具體實現見上面源碼和注釋
LinkedList提供了offer(E e),offerFirst(E e), offerLast(E e),addFirst(E e) ,addLast(E e),push(E e) 往list中添加一個元素的方法,這些方法的底層都是基于上面介紹的原理實現的:頭插和尾插。這里就不多做說明。
獲取元素
LinkedList獲取元素提供多種方法:
//根據索引獲取元素public E get(int index)//獲取頭元素public E peek()//獲取頭元素,并且把頭元素從list中刪除public E poll()//獲取頭元素,并且把頭元素從list中刪除public E pop()```下面追個介紹這些方法的具體實現:```public E get(int index) {checkElementIndex(index);return node(index).item;}由上面源碼可知,get操作底層是調用的node方法,node方法參考上面的介紹。
下面是peek,peek操作是獲取頭元素,因此只需要獲取到LinkedList的first所執行的元素就可以了。
public E peek() {final Node f = first;return (f == null) ? null : f.item;}下面介紹poll():
public E poll() { final Node f = first; return (f == null) ? null : unlinkFirst(f);}private E unlinkFirst(Node f) { //保存f的具體值 final E element = f.item; final Node next = f.next; f.item = null; f.next = null; // help GC //f的后繼節點賦值給LinkedList的first first = next; //next==null表示要刪除的節點是list的最后一個節點 if (next == null) last = null; else //表示刪除f之后的list列表中,頭結點的prev應該為null,而之前 //prev是執行f的 next.prev = null; size--; modCount++; return element; }由上面源碼可知,當調用poll的時候,會把LinkedList的頭元素返回,然后把頭元素從LinkedList中刪除。
下面看一下pop方法:
public E removeFirst() {final Node f = first;if (f == null) throw new NoSuchElementException();return unlinkFirst(f);}pop方法的底層也是調用unlinkFirst方法完成頭結點的刪除操作。
##To Array的操作
LinkedList提供了兩種方法完成list到數組的轉換:
public Object[] toArray()public T[] toArray(T[] a)第一個方法,是把list轉為Object類型的數組,具體是實現如下:
public Object[] toArray() { Object[] result = new Object[size]; int i = 0; for (Node x = first; x != null; x = x.next) result[i++] = x.item; return result; }該方法的實現原理比較簡單,首先創建一個大小與list相同的object類型數組,然后從頭到尾遍歷list的元素,把每個元素放到創建的數組中,因為數組對象是Object類型,因此list中的任何元素都可以直接放入到數組中,最后把數組返回。
在T[] toArray(T[] a) 方法中,需要傳遞一個T類型的數組對象,這樣可以按照T類型返回T類型數組:
public T[] toArray(T[] a) { if (a.length < size) a = (T[])java.lang.reflect.Array.newInstance( a.getClass().getComponentType(), size); int i = 0; Object[] result = a; for (Node x = first; x != null; x = x.next) result[i++] = x.item; if (a.length > size) a[size] = null; return a;}首先是判斷傳入的數組a的大小是否大于或者等于list的大小,如果小于,那么利用反射機制重新創建一個數組,此時參數a和toArray的數組就不是同一個數組了,如果a的大小大于size的值,假設數組a={"1


方法與示例)

輸出pcm文件)
)

方法與示例)

)

輸出yuv420p文件)
)
隨機產生兩個1~10的正整數,在屏幕上輸出題目,如:5+3=?(2)學生輸入答案,程序檢查學生輸入答案是否正確,若正確,)



方法及示例)

