例1、爬取公眾號文章中的圖片。
1,首先打開要獲取公眾號文章的地址
2,按下F12,再按Ctrl Shift C,然后鼠標移動到圖片位置,然后觀察控制臺中顯示圖片對應的代碼位置
3,分析該位置的代碼段
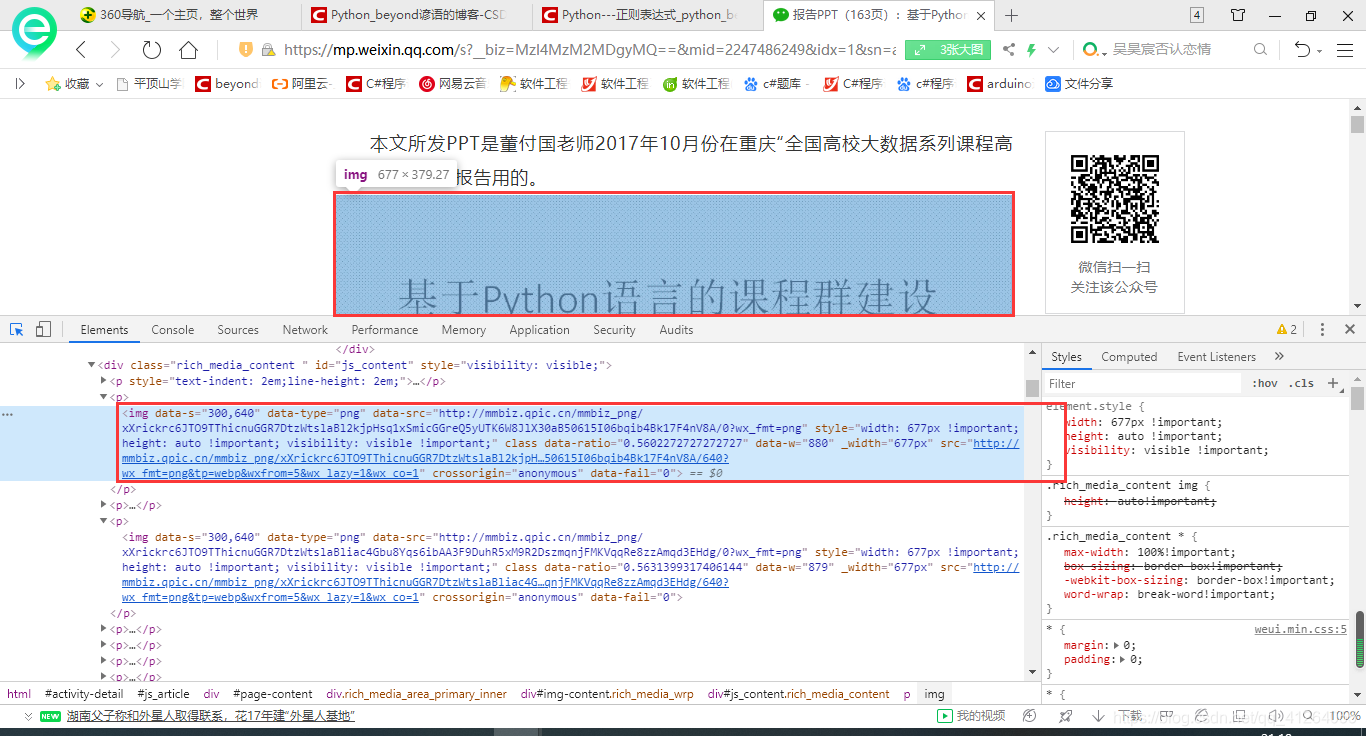
代碼段如下:
<img data-s="300,640" data-type="png" data-src="http://mmbiz.qpic.cn/mmbiz_png/xXrickrc6JTO9TThicnuGGR7DtzWtslaBl2kjpHsq1xSmicGGreQ5yUTK6W8JlX30aB50615I06bqib4Bk17F4nV8A/0?wx_fmt=png" style="width: 677px !important; height: auto !important; visibility: visible !important;" class data-ratio="0.5602272727272727" data-w="880" _width="677px" src="http://mmbiz.qpic.cn/mmbiz_png/xXrickrc6JTO9TThicnuGGR7DtzWtslaBl2kjpH…50615I06bqib4Bk17F4nV8A/640?wx_fmt=png&tp=webp&wxfrom=5&wx_lazy=1&wx_co=1" crossorigin="anonymous" data-fail="0">
這里我們觀察這個代碼段的格式:然后編寫正則表達式
pattern = ‘data-type=“png” data-src="(.+?)"’
? --- 匹配位于?之前的0個或1個字符
+ --- 匹配位于+之前的字符或子模塊的1次或多次的出現
. --- 匹配除換行符以外的任意單個字符
from re import findall
from urllib.request import urlopenurl = 'https://mp.weixin.qq.com/s?__biz=MzI4MzM2MDgyMQ==&mid=2247486249&idx=1&sn=a37d079f541b194970428fb2fd7a1ed4&chksm=eb8aa073dcfd2965f2d48c5ae9341a7f8a1c2ae2c79a68c7d2476d8573c91e1de2e237c98534&scene=21#wechat_redirect' #這個為要爬取公眾號圖片的地址
with urlopen(url) as fp:content=fp.read().decode('utf-8')pattern = 'data-type="png" data-src="(.+?)"'
#查找所有圖片鏈接地址
result = findall(pattern, content) #捕獲分組
#逐個讀取圖片數據,并寫入本地文件
path='f:/test/'#把圖片存放到f盤下的test文件夾中
for index, item in enumerate(result):with urlopen(str(item)) as fp:with open(path+str(index)+'.png','wb') as fp1: fp1.write(fp.read())
例2、使用scrapy框架編寫爬蟲程序。
首先安裝scrapy,打開cmd運行pip install scrapy
若出錯:attrs() got an unexpected keyword argument ‘eq’
則運行:pip3 install attrs==19.2.0 -i http://mirrors.aliyun.com/pypi/simple --trusted-host mirrors.aliyun.com即可
運行cmd開始創建項目,根據指定位置可以切換路徑
創建一個項目:scrapy startproject sqsq為項目名可隨意
cd sq
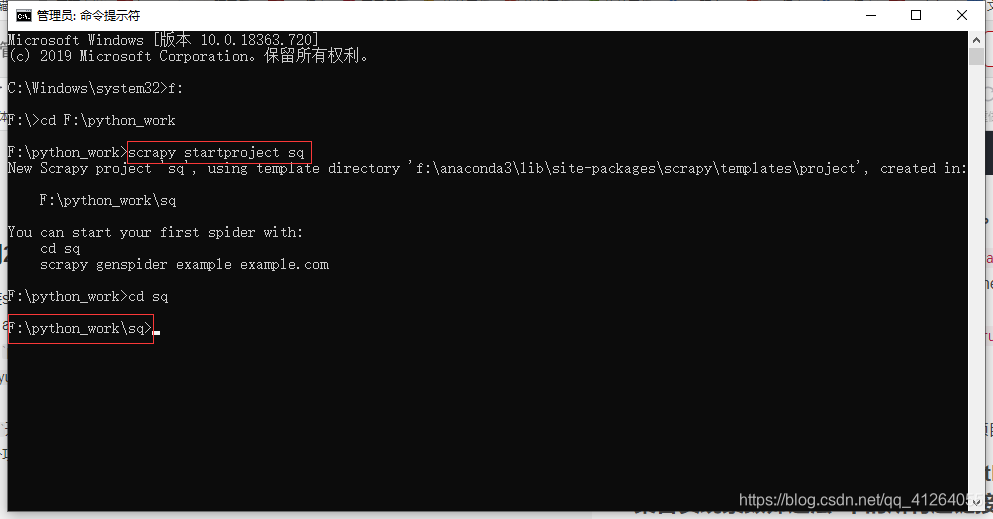
出現這樣表示scrapy框架已經搭建成功
例3、使用scrapy框架編寫爬蟲程序,爬取天涯小說。
這里以例2為基礎繼續
scrapy genspider xiaoshuosq bbs.tianya.cn/post-16-1126849-1.shtml
xiaoshuosq為爬蟲名稱
bbs.tianya.cn/post-16-1126849-1.shtml為爬蟲起始位置,這里是天涯小說第一頁
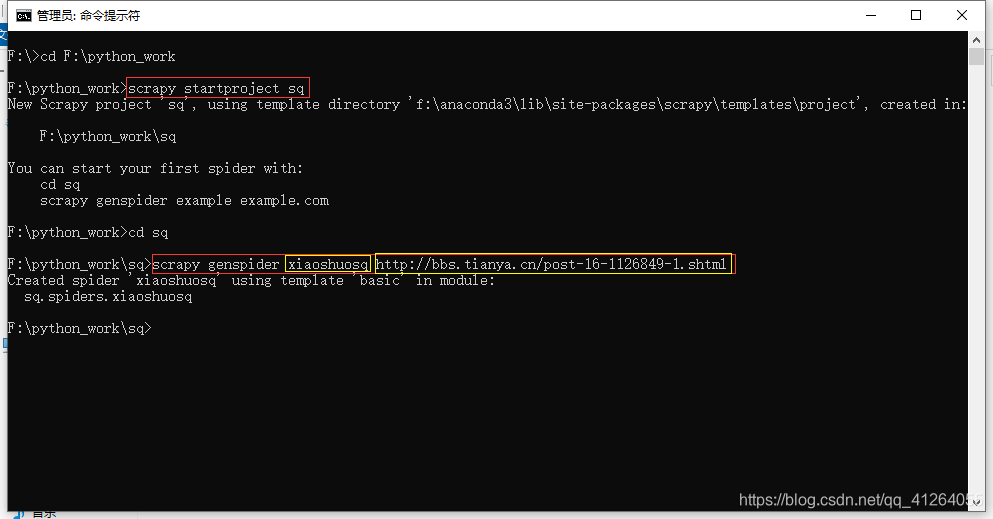
之后打開創建的xiaoshuosq爬蟲
編寫如下代碼:
# -*- coding: utf-8 -*-
import scrapyclass XiaoshuosqSpider(scrapy.Spider):name = 'xiaoshuosq'#這里的是你創建的爬蟲名稱allowed_domains = ['http://bbs.tianya.cn/post-16-1126849-1.shtml']start_urls = ['http://bbs.tianya.cn/post-16-1126849-1.shtml/']def parse(self, response):content=[]for i in response.xpath('//div'):if i.xpath('@_hostid').extract()==['13357319']:for j in i.xpath('div//div'):c = j.xpath('text()').extract()g = lambda x:x.strip('\n\r\u3000').replace('<br>','\n').replace('|','')c = '\n'.join(map(g.c)).strip()content.append(c)with open('F:\result.txt','a+',enconding='utf8') as fp:fp.writelines(content)url=response.urld = url[url.rindex('-')+1:url.rindex('.')]u = 'http://bbs.tianya.cn/post-16-1126849-{0}.shtml'next_url = u.format(int(d)+1)try:yield scrapy.Request(url=next_url,callback=self.parse)except:pass保存該爬蟲
然后scrapy crwal xiaoshuosq這里的xiaoshuosq是你創建的爬蟲名稱
例4、使用requests庫爬取微信公眾號“Python小屋”文章“Python使用集合實現素數篩選法”中的所有超鏈接。
# -*- coding: utf-8 -*-
"""
Created on Mon Jun 1 21:40:19 2020@author: 78708
"""#使用requests庫爬取微信公眾號“Python小屋”文章“Python使用集合實現素數篩選法”中的所有超鏈接
import requests
import re
url = 'https://mp.weixin.qq.com/s?__biz=MzI4MzM2MDgyMQ==&mid=2247486531&idx=1&sn=7eeb27a03e2ee8ab4152563bb110f248&chksm=eb8aa719dcfd2e0f7b1731cfd8aa74114d68facf1809d7cdb0601e3d3be8fb287cfc035002c6#rd'
r = requests.get(url)
print(r.status_code ) #響應狀態碼
#print(r.text[:300] ) #查看網頁源代碼前300個字符
print('篩選法' in r.text )
print(r.encoding )
links = re.findall(r'<a .*?href="(.+?)"', r.text)
#使用正則表達式查找所有超鏈接地址
for link in links:if link.startswith('http'):print(link)from bs4 import BeautifulSoup
soup = BeautifulSoup(r.content, 'lxml')
for link in soup.findAll('a'): #使用BeautifulSoup查找超鏈接地址href = link.get('href')if href.startswith('http'): #只輸出絕對地址print(href)例5、讀取并下載指定的URL的圖片文件。
# -*- coding: utf-8 -*-
"""
Created on Mon Jun 1 21:39:44 2020@author: 78708
"""#讀取并下載指定的URL的圖片文件。import requests
picUrl = r'https://www.python.org/static/opengraph-icon-200x200.png'
r = requests.get(picUrl)
print(r.status_code)
with open('G:\TIM\圖片\wsq.png', 'wb') as fp:#G:\TIM\圖片\wsq.png 為保存路徑以及圖片名稱fp.write(r.content) #把圖像數據寫入本地文件)


方法及示例)
)

)

![[轉載]FPGA/CPLD重要設計思想及工程應用(時序及同步設計)](http://pic.xiahunao.cn/[轉載]FPGA/CPLD重要設計思想及工程應用(時序及同步設計))
方法與示例)





——Linux分區和目錄結構)

、crop filter(裁剪)、vflip filter(垂直向上的翻轉)、overlay filter(合成))

