本章既是一個目前所學的很多技能的概括,也是一個更多標準庫功能的探索。我們將構建一個與文件和命令行輸入/輸出交互的命令行工具來練習現在一些你已經掌握的 Rust 技能。
Rust 的運行速度、安全性、單二進制文件輸出和跨平臺支持使其成為創建命令行程序的絕佳選擇,所以我們的項目將創建一個我們自己版本的經典命令行工具:grep。grep 是 “Globally search a?Regular?Expression and?Print.” 的首字母縮寫。grep?最簡單的使用場景是在特定文件中搜索指定字符串。為此,grep?獲取一個文件名和一個字符串作為參數,接著讀取文件并找到其中包含字符串參數的行,然后打印出這些行。
在這個過程中,我們會展示如何讓我們的命令行工具利用很多命令行工具中用到的終端功能。讀取環境變量來使得用戶可以配置工具的行為。打印到標準錯誤控制流(stderr) 而不是標準輸出(stdout),例如這樣用戶可以選擇將成功輸出重定向到文件中的同時仍然在屏幕上顯示錯誤信息。
12.1?接受命令參數行
一如既往使用cargo new 新建一個項目,我們稱之為minigrep 以便與可能已經安裝在系統上的grep 工具相區別。
第一個任務是讓?minigrep?能夠接受兩個命令行參數:文件名和要搜索的字符串。也就是說我們希望能夠使用?cargo run、要搜索的字符串和被搜索的文件的路徑來運行程序,像這樣:
cargo run searchstring example-filename.txt
讀取參數值
為了確保?minigrep?能夠獲取傳遞給它的命令行參數的值,我們需要一個 Rust 標準庫提供的函數,也就是?std::env::args。這個函數返回一個傳遞給程序的命令行參數的?迭代器(iterator)。但是現在只需理解迭代器的兩個細節:迭代器生成一系列的值,可以在迭代器上調用?collect?方法將其轉換為一個集合,比如包含所有迭代器產生元素的 vector。
use std::env;fn main() {let args : Vec<String> = env::args().collect();println!("{:?}", args);
}
首先使用?use?語句來將?std::env?模塊引入作用域以便可以使用它的?args?函數。注意?std::env::args?函數被嵌套進了兩層模塊中。
注意?
std::env::args?在其任何參數包含無效 Unicode 字符時會 panic。如果你需要接受包含無效 Unicode 字符的參數,使用?std::env::args_os?代替。這個函數返回?OsString?值而不是?String?值。這里出于簡單考慮使用了?std::env::args,因為?OsString?值每個平臺都不一樣而且比?String?值處理起來更為復雜。
在?main?函數的第一行,我們調用了?env::args,并立即使用?collect?來創建了一個包含迭代器所有值的 vector。collect?可以被用來創建很多類型的集合,所以這里顯式注明?args?的類型來指定我們需要一個字符串 vector。雖然在 Rust 中我們很少會需要注明類型,然而?collect?是一個經常需要注明類型的函數,因為 Rust 不能推斷出你想要什么類型的集合。
最后,我們使用調試格式?:??打印出 vector。讓我們嘗試分別用兩種方式(不包含參數和包含參數)運行代碼:

注意 vector 的第一個值是?"target/debug/minigrep",它是我們二進制文件的名稱。這與 C 中的參數列表的行為相匹配,讓程序使用在執行時調用它們的名稱。如果要在消息中打印它或者根據用于調用程序的命令行別名更改程序的行為,通常可以方便地訪問程序名稱,不過考慮到本章的目的,我們將忽略它并只保存所需的兩個參數。
將參數值保存進變量
打印出參數 vector 中的值展示了程序可以訪問指定為命令行參數的值。現在需要將這兩個參數的值保存進變量這樣就可以在程序的余下部分使用這些值了。
use std::env;fn main() {let args : Vec<String> = env::args().collect();let query = &args[1]; // 索引0是文件名,所以從1開始?let file_name = &args[2];println!("Searching for {}", query);println!("In file {}", file_name);
}
結果
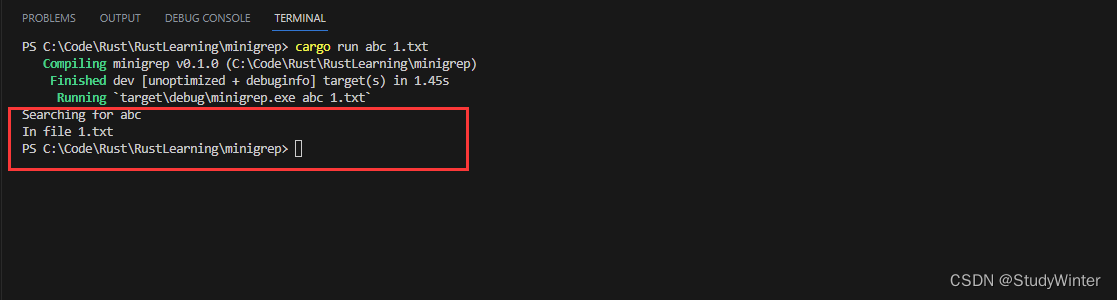
正如之前打印出 vector 時所所看到的,程序的名稱占據了 vector 的第一個值?args[0],所以我們從索引?1?開始。minigrep?獲取的第一個參數是需要搜索的字符串,所以將其將第一個參數的引用存放在變量?query?中。第二個參數將是文件名,所以將第二個參數的引用放入變量?filename?中。
12.2?讀取文件
現在我們要增加讀取由?filename?命令行參數指定的文件的功能。首先,需要一個用來測試的示例文件:用來確保?minigrep?正常工作的最好的文件是擁有多行少量文本且有一些重復單詞的文件。
I'm nobody! Who are you?
Are you nobody, too?
Then there's a pair of us - don't tell!
They'd banish us, you know.How dreary to be somebody!
How public, like a frog
To tell your name the livelong day
To an admiring bog!
創建完這個文件之后,修改代碼:
use std::env;
use std::fs;fn main() {let args: Vec<String> = env::args().collect();let query = &args[1];let filename = &args[2];println!("Searching for {}", query);println!("In file {}", filename);println!("In file {}", filename);let contents = fs::read_to_string(filename).expect("Something went wrong reading the file");println!("With text:\n{}", contents);
}
結果
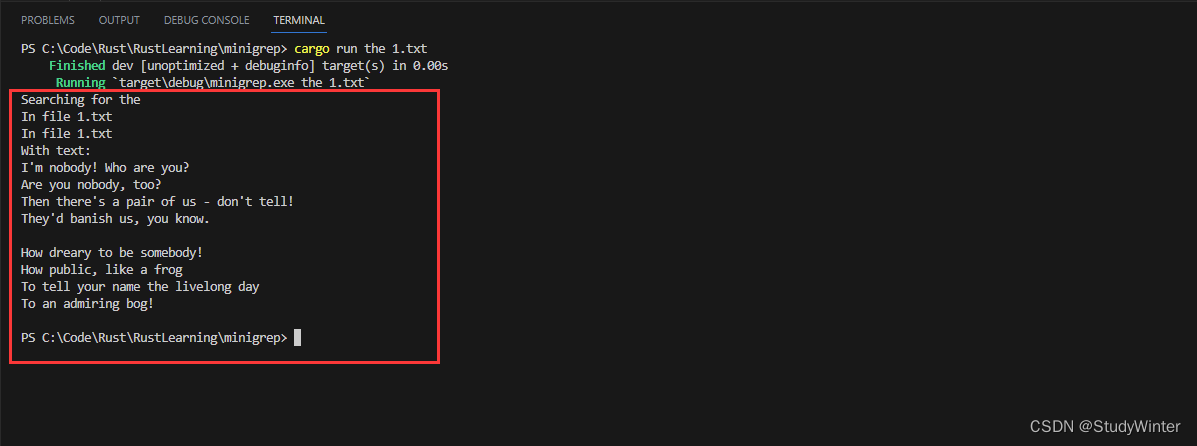
?首先,我們增加了一個?use?語句來引入標準庫中的相關部分:我們需要?std::fs?來處理文件。
在?main?中新增了一行語句:fs::read_to_string?接受?filename,打開文件,接著返回包含其內容的?Result<String>。
在這些代碼之后,我們再次增加了臨時的?println!?打印出讀取文件之后?contents?的值,這樣就可以檢查目前為止的程序能否工作。
12.3?重構改進模塊性和錯誤處理
為了改善我們的程序這里有四個問題需要修復,而且他們都與程序的組織方式和如何處理潛在錯誤有關。
第一,main?現在進行了兩個任務:它解析了參數并打開了文件。對于一個這樣的小函數,這并不是一個大問題。然而如果?main?中的功能持續增加,main?函數處理的獨立任務也會增加。當函數承擔了更多責任,它就更難以推導,更難以測試,并且更難以在不破壞其他部分的情況下做出修改。最好能分離出功能以便每個函數就負責一個任務。
這同時也關系到第二個問題:search?和?filename?是程序中的配置變量,而像?contents?則用來執行程序邏輯。隨著?main?函數的增長,就需要引入更多的變量到作用域中,而當作用域中有更多的變量時,將更難以追蹤每個變量的目的。最好能將配置變量組織進一個結構,這樣就能使他們的目的更明確了。
第三個問題是如果打開文件失敗我們使用?expect?來打印出錯誤信息,不過這個錯誤信息只是說?file not found。除了缺少文件之外還有很多可以導致打開文件失敗的方式:例如,文件可能存在,不過可能沒有打開它的權限。如果我們現在就出于這種情況,打印出的?file not found?錯誤信息就給了用戶錯誤的建議!
第四,我們不停地使用?expect?來處理不同的錯誤,如果用戶沒有指定足夠的參數來運行程序,他們會從 Rust 得到?index out of bounds?錯誤,而這并不能明確地解釋問題。如果所有的錯誤處理都位于一處,這樣將來的維護者在需要修改錯誤處理邏輯時就只需要考慮這一處代碼。將所有的錯誤處理都放在一處也有助于確保我們打印的錯誤信息對終端用戶來說是有意義的。
二進制項目的關注分離
這些過程有如下步驟:
- 將程序拆分成?main.rs?和?lib.rs?并將程序的邏輯放入?lib.rs?中。
- 當命令行解析邏輯比較小時,可以保留在?main.rs?中。
- 當命令行解析開始變得復雜時,也同樣將其從?main.rs?提取到?lib.rs?中。
經過這些過程之后保留在?main?函數中的責任應該被限制為:
- 使用參數值調用命令行解析邏輯
- 設置任何其他的配置
- 調用?lib.rs?中的?
run?函數 - 如果?
run?返回錯誤,則處理這個錯誤
提取參數解析器
首先,我們將解析參數的功能提取到一個?main?將會調用的函數中,為將命令行解析邏輯移動到?src/lib.rs?中做準備。示例中展示了新?main?函數的開頭,它調用了新函數?parse_config。目前它仍將定義在?src/main.rs?中:
use std::env;
use std::fs;fn main() {let args: Vec<String> = env::args().collect();let (query, filename) = parse_config(&args);}fn parse_config(args: &[String]) -> (&str, &str) {let query = &args[1];let filename = &args[2];(query, filename)
}
我們仍然將命令行參數收集進一個 vector,不過不同于在?main?函數中將索引 1 的參數值賦值給變量?query?和將索引 2 的值賦值給變量?filename,我們將整個 vector 傳遞給?parse_config?函數。接著?parse_config?函數將包含決定哪個參數該放入哪個變量的邏輯,并將這些值返回到?main。仍然在?main?中創建變量?query?和?filename,不過?main?不再負責處理命令行參數與變量如何對應。
組合配置值
現在函數返回一個元組,不過立刻又將元組拆成了獨立的部分。這是一個我們可能沒有進行正確抽象的信號。
另一個表明還有改進空間的跡象是?parse_config?名稱的?config?部分,它暗示了我們返回的兩個值是相關的并都是一個配置值的一部分。目前除了將這兩個值組合進元組之外并沒有表達這個數據結構的意義:我們可以將這兩個值放入一個結構體并給每個字段一個有意義的名字。這會讓未來的維護者更容易理解不同的值如何相互關聯以及他們的目的。
use std::env;
use std::fs;fn main() {let args: Vec<String> = env::args().collect();let config = parse_config(&args);println!("Searching for {}", config.query);println!("In file {}", config.filename);println!("In file {}", config.filename);let contents = fs::read_to_string(config.filename).expect("Something went wrong reading the file");println!("With text:\n{}", contents);
}// 抽象成結構體
struct Config {query: String,filename: String,
}fn parse_config(args: &[String]) -> Config {let query = args[1].clone();let filename = args[2].clone();Config{query, filename}
}新定義的結構體?Config?中包含字段?query?和?filename。?parse_config?的簽名表明它現在返回一個?Config?值。在之前的?parse_config?函數體中,我們返回了引用?args?中?String?值的字符串 slice,現在我們定義?Config?來包含擁有所有權的?String?值。main?中的?args?變量是參數值的所有者并只允許?parse_config?函數借用他們,這意味著如果?Config?嘗試獲取?args?中值的所有權將違反 Rust 的借用規則。
還有許多不同的方式可以處理?String?的數據,而最簡單但有些不太高效的方式是調用這些值的?clone?方法。這會生成?Config?實例可以擁有的數據的完整拷貝,不過會比儲存字符串數據的引用消耗更多的時間和內存。不過拷貝數據使得代碼顯得更加直白因為無需管理引用的生命周期,所以在這種情況下犧牲一小部分性能來換取簡潔性的取舍是值得的。
使用clone的權衡取舍
由于其運行時消耗,許多 Rustacean 之間有一個趨勢是傾向于避免使用?clone?來解決所有權問題。在關于迭代器的第十三章中,我們將會學習如何更有效率的處理這種情況,不過現在,復制一些字符串來取得進展是沒有問題的,因為只會進行一次這樣的拷貝,而且文件名和要搜索的字符串都比較短。在第一輪編寫時擁有一個可以工作但有點低效的程序要比嘗試過度優化代碼更好一些。隨著你對 Rust 更加熟練,將能更輕松的直奔合適的方法,不過現在調用?clone?是完全可以接受的。
創建一個Config 的構造函數
還可以將?parse_config?從一個普通函數變為一個叫做?new?的與結構體關聯的函數。做出這個改變使得代碼更符合習慣:可以像標準庫中的?String?調用?String::new?來創建一個該類型的實例那樣,將?parse_config?變為一個與?Config?關聯的?new?函數。
use std::env;
use std::fs;fn main() {let args: Vec<String> = env::args().collect();let config = Config::new(&args);println!("Searching for {}", config.query);println!("In file {}", config.filename);println!("In file {}", config.filename);let contents = fs::read_to_string(config.filename).expect("Something went wrong reading the file");println!("With text:\n{}", contents);
}// 抽象成結構體
struct Config {query: String,filename: String,
}// 構造函數
impl Config {fn new(args: &[String]) -> Config {let query = args[1].clone();let filename = args[2].clone();Config{query, filename}}
}這里將?main?中調用?parse_config?的地方更新為調用?Config::new。我們將?parse_config?的名字改為?new?并將其移動到?impl?塊中,這使得?new?函數與?Config?相關聯。再次嘗試編譯并確保它可以工作。
修復錯誤處理
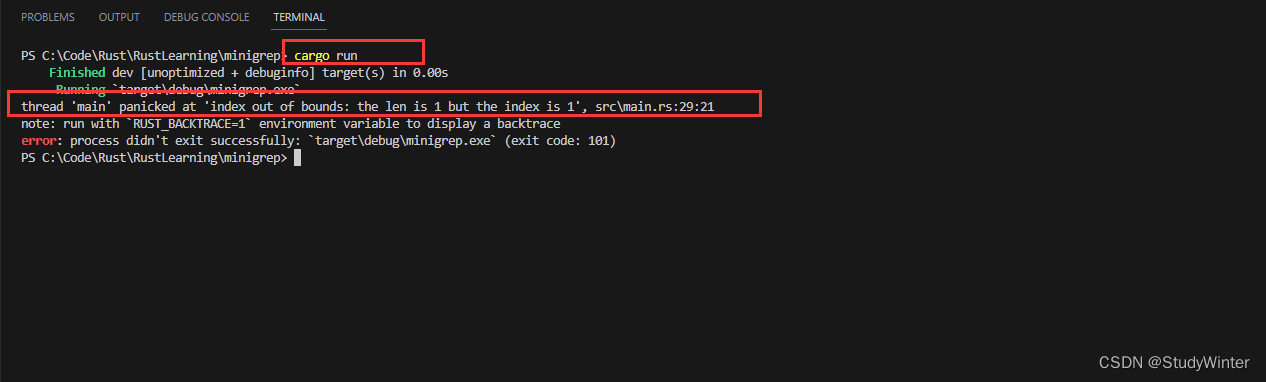
現在我們開始修復錯誤處理。回憶一下之前提到過如果?args?vector 包含少于 3 個項并嘗試訪問 vector 中索引?1?或索引?2?的值會造成程序 panic。嘗試不帶任何參數運行程序;這將看起來像這樣:
改善錯誤信息
在?new?函數中增加了一個檢查在訪問索引?1?和?2?之前檢查 slice 是否足夠長。如果 slice 不夠長,我們使用一個更好的錯誤信息 panic 而不是?index out of bounds?信息:
// 構造函數
impl Config {fn new(args: &[String]) -> Config {if args.len() < 3 {panic!("not enough arguments");}let query = args[1].clone();let filename = args[2].clone();Config{query, filename}}
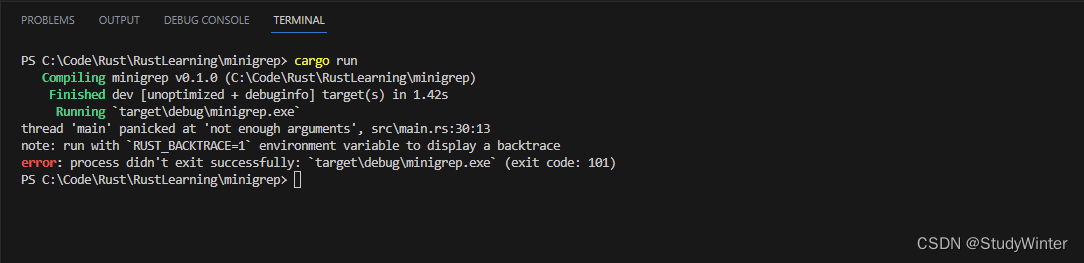
}有了?new?中這幾行額外的代碼,再次不帶任何參數運行程序并看看現在錯誤看起來像什么:
從new中返回Result而不是調用panic!
我們可以選擇返回一個?Result?值,它在成功時會包含一個?Config?的實例,而在錯誤時會描述問題。當?Config::new?與?main?交流時,可以使用?Result?類型來表明這里存在問題。接著修改?main?將?Err?成員轉換為對用戶更友好的錯誤,而不是?panic!?調用產生的關于?thread 'main'?和?RUST_BACKTRACE?的文本。
use std::env;
use std::fs;
use std::process;fn main() {let args: Vec<String> = env::args().collect();// 這詭異的寫法let config = Config::new(&args).unwrap_or_else(|err| {println!("Problem parsing arguments: {}", err);process::exit(1);});println!("Searching for {}", config.query);println!("In file {}", config.filename);println!("In file {}", config.filename);let contents = fs::read_to_string(config.filename).expect("Something went wrong reading the file");println!("With text:\n{}", contents);
}// 抽象成結構體
struct Config {query: String,filename: String,
}// 構造函數,這里返回值有變化
impl Config {fn new(args: &[String]) -> Result<Config, &'static str> {if args.len() < 3 {return Err("not enough arguments");}let query = args[1].clone();let filename = args[2].clone();Ok(Config{query, filename})}
}
現在?new?函數返回一個?Result,在成功時帶有一個?Config?實例而在出現錯誤時帶有一個?&'static str。回憶一下第十章 “靜態生命周期” 中講到?&'static str?是字符串字面值的類型,也是目前的錯誤信息。
new?函數體中有兩處修改:當沒有足夠參數時不再調用?panic!,而是返回?Err?值。同時我們將?Config?返回值包裝進?Ok?成員中。這些修改使得函數符合其新的類型簽名。
通過讓?Config::new?返回一個?Err?值,這就允許?main?函數處理?new?函數返回的?Result?值并在出現錯誤的情況更明確的結束進程。
在上面的示例中,使用了一個之前沒有涉及到的方法:unwrap_or_else,它定義于標準庫的?Result<T, E>?上。使用?unwrap_or_else?可以進行一些自定義的非?panic!?的錯誤處理。當?Result?是?Ok?時,這個方法的行為類似于?unwrap:它返回?Ok?內部封裝的值。然而,當其值是?Err?時,該方法會調用一個?閉包(closure),也就是一個我們定義的作為參數傳遞給?unwrap_or_else?的匿名函數。
新增了一個?use?行來從標準庫中導入?process。在錯誤的情況閉包中將被運行的代碼只有兩行:我們打印出了?err?值,接著調用了?std::process::exit。process::exit?會立即停止程序并將傳遞給它的數字作為退出狀態碼。
寫法太詭異了
從main提取邏輯
目前我們只進行小的增量式的提取函數的改進。我們仍將在?src/main.rs?中定義這個函數:
fn main() {let args: Vec<String> = env::args().collect();// 這詭異的寫法let config = Config::new(&args).unwrap_or_else(|err| {println!("Problem parsing arguments: {}", err);process::exit(1);});println!("Searching for {}", config.query);println!("In file {}", config.filename);run(config);}fn run(config: Config) {let contents = fs::read_to_string(config.filename).expect("Something went wrong reading the file");println!("With text:\n{}", contents);
}// ...從run函數中返回錯誤
進一步以一種對用戶友好的方式統一?main?中的錯誤處理。
use std::error::Error;// --snip--fn run(config: Config) -> Result<(), Box<dyn Error>> {let contents = fs::read_to_string(config.filename)?;println!("With text:\n{}", contents);Ok(())
}
這里我們做出了三個明顯的修改。首先,將?run?函數的返回類型變為?Result<(), Box<dyn Error>>。之前這個函數返回 unit 類型?(),現在它仍然保持作為?Ok?時的返回值。
第二個改變是去掉了?expect?調用并替換為第九章講到的??。不同于遇到錯誤就?panic!,??會從函數中返回錯誤值并讓調用者來處理它。
第三個修改是現在成功時這個函數會返回一個?Ok?值。因為?run?函數簽名中聲明成功類型返回值是?(),這意味著需要將 unit 類型值包裝進?Ok?值中。Ok(())?一開始看起來有點奇怪,不過這樣使用?()?是表明我們調用?run?只是為了它的副作用的慣用方式;它并沒有返回什么有意義的值。
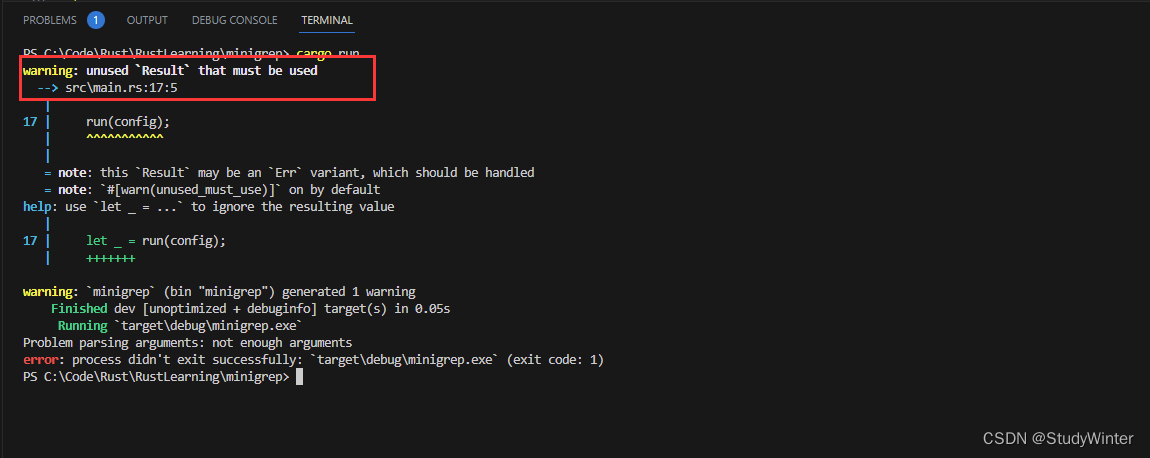
Rust 提示我們的代碼忽略了?Result?值,它可能表明這里存在一個錯誤。雖然我們沒有檢查這里是否有一個錯誤,而編譯器提醒我們這里應該有一些錯誤處理代碼!現在就讓我們修正這個問題。
處理main 中run返回的錯誤
fn main() {// --snip--println!("Searching for {}", config.query);println!("In file {}", config.filename);if let Err(e) = run(config) {println!("Application error: {}", e);process::exit(1);}
}
我們使用?if let?來檢查?run?是否返回一個?Err?值,不同于?unwrap_or_else,并在出錯時調用?process::exit(1)。run?并不返回像?Config::new?返回的?Config?實例那樣需要?unwrap?的值。因為?run?在成功時返回?(),而我們只關心檢測錯誤,所以并不需要?unwrap_or_else?來返回未封裝的值,因為它只會是?()。
將代碼拆分到庫crate
讓我們將所有不是?main?函數的代碼從?src/main.rs?移動到新文件?src/lib.rs?中:
run?函數定義- 相關的?
use?語句 Config?的定義Config::new?函數定義
lib.rs
use std::fs;
use std::error::Error;// 結構體
pub struct Config {pub query: String,pub filename: String,
}// 構造函數,這里返回值有變化
impl Config {pub fn new(args: &[String]) -> Result<Config, &'static str> {if args.len() < 3 {return Err("not enough arguments");}let query = args[1].clone();let filename = args[2].clone();Ok(Config{query, filename})}
}// run函數
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {let contents = fs::read_to_string(config.filename)?;println!("With text:\n{}", contents);Ok(())
}
main.rs
use std::env;
use std::process;
use minigrep::Config;fn main() {let args: Vec<String> = env::args().collect();// 這詭異的寫法let config = Config::new(&args).unwrap_or_else(|err| {println!("Problem parsing arguments: {}", err);process::exit(1);});// 注意run的引用方式if let Err(e) = minigrep::run(config) {println!("Application error: {}", e);process::exit(1);}
}
?這里使用了公有的?pub?關鍵字:在?Config、其字段和其?new?方法,以及?run?函數上。現在我們有了一個擁有可以測試的公有 API 的庫 crate 了。
為了將庫 crate 引入二進制 crate,我們使用了?use minigrep。接著?use minigrep::Config?將?Config?類型引入作用域,并使用 crate 名稱作為?run?函數的前綴。通過這些重構,所有功能應該能夠聯系在一起并運行了。運行?cargo run?來確保一切都正確的銜接在一起。
13.4?采用測試驅動開發完善庫的功能
在這一部分,我們將遵循測試驅動開發(Test Driven Development, TDD)的模式來逐步增加?minigrep?的搜索邏輯。這是一個軟件開發技術,它遵循如下步驟:
- 編寫一個會失敗的測試,并運行它以確保其因為你期望的原因失敗。
- 編寫或修改剛好足夠的代碼來使得新的測試通過。
- 重構剛剛增加或修改的代碼,并確保測試仍然能通過。
- 從步驟 1 開始重復!
這只是眾多編寫軟件的方法之一,不過 TDD 有助于驅動代碼的設計。在編寫能使測試通過的代碼之前編寫測試有助于在開發過程中保持高測試覆蓋率。
編寫失敗測試
去掉?src/lib.rs?和?src/main.rs?中用于檢查程序行為的?println!?語句,因為不再真正需要他們了。加入測試。測試函數指定了?search?函數期望擁有的行為:它會獲取一個需要查詢的字符串和用來查詢的文本,并只會返回包含請求的文本行。
文件名: src/lib.rs
#[cfg(test)]
mod tests {use super::*;#[test]fn one_result() {let query = "duct";let contents = "\
Rust:
safe, fast, productive.
Pick three.";assert_eq!(vec!["safe, fast, productive."],search(query, contents));}
}這里選擇使用?"duct"?作為這個測試中需要搜索的字符串。用來搜索的文本有三行,其中只有一行包含?"duct"。我們斷言?search?函數的返回值只包含期望的那一行。
我們還不能運行這個測試并看到它失敗,因為它甚至都還不能編譯:search?函數還不存在呢!我們將增加足夠的代碼來使其能夠編譯:一個總是會返回空 vector 的?search?函數定義
文件名: src/lib.rs
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {vec![]
}注意需要在?search?的簽名中定義一個顯式生命周期?'a?并用于?contents?參數和返回值。回憶一下第十章中講到生命周期參數指定哪個參數的生命周期與返回值的生命周期相關聯。在這個例子中,我們表明返回的 vector 中應該包含引用參數?contents(而不是參數query) slice 的字符串 slice。
換句話說,我們告訴 Rust 函數?search?返回的數據將與?search?函數中的參數?contents?的數據存在的一樣久。這是非常重要的!為了使這個引用有效那么?被?slice 引用的數據也需要保持有效;如果編譯器認為我們是在創建?query?而不是?contents?的字符串 slice,那么安全檢查將是不正確的。

編寫使測試通過的代碼
目前測試之所以會失敗是因為我們總是返回一個空的 vector。為了修復并實現?search,我們的程序需要遵循如下步驟:
- 遍歷內容的每一行文本。
- 查看這一行是否包含要搜索的字符串。
- 如果有,將這一行加入列表返回值中。
- 如果沒有,什么也不做。
- 返回匹配到的結果列表
讓我們一步一步的來,從遍歷每行開始。
使用lines方法遍歷每—行
Rust有一個有助于一行一行遍歷字符串的方法,出于方便它被命名為lines,它如示例這樣工作。注意這還不能編譯:
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {for line in contents.lines() {// do something}
}lines?方法返回一個迭代器。
用查詢寧符串搜索每一行
接下來將會增加檢查當前行是否包含查詢字符串的功能。幸運的是,字符串類型為此也有一個叫做
contains的實用方法!如示例所示在search函數中加入contains方法調用。注意這仍然不能編譯:
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {for line in contents.lines() {if line.contains(query) {// }}
}存儲匹配的行
我們還需要一個方法來存儲包含查詢字符串的行。為此可以在?for?循環之前創建一個可變的 vector 并調用?push?方法在 vector 中存放一個?line。在?for?循環之后,返回這個 vector
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {let mut results = Vec::new();for line in contents.lines() {if line.contains(query) {results.push(line)}}results
}現在?search?函數應該返回只包含?query?的那些行,而測試應該會通過。讓我們運行測試:
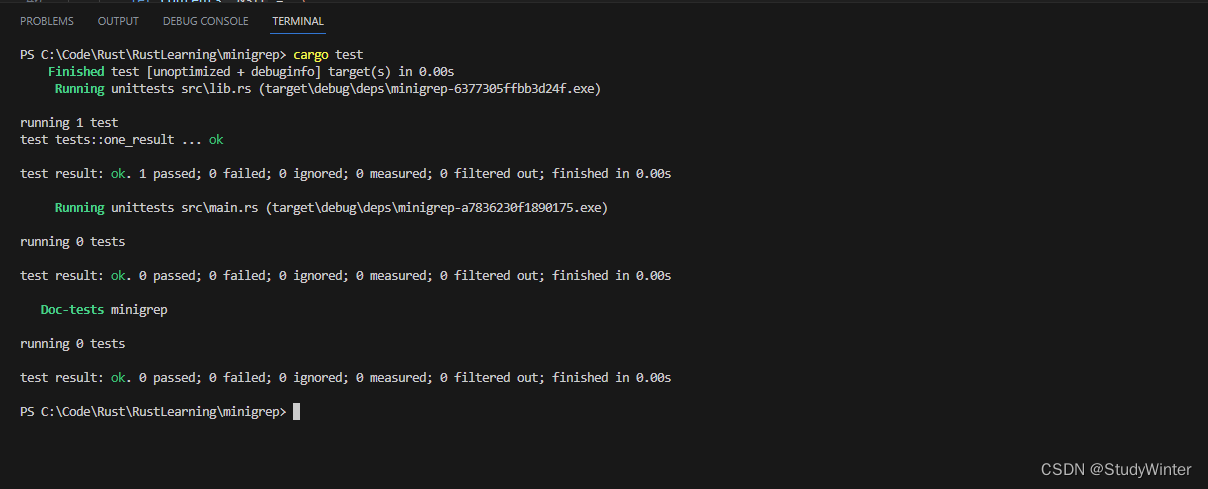
到此為止,我們可以考慮一下重構?search?的實現并時刻保持測試通過來保持其功能不變的機會了。search?函數中的代碼并不壞,不過并沒有利用迭代器的一些實用功能。
在run函數中使用search函數
現在?search?函數是可以工作并測試通過了的,我們需要實際在?run?函數中調用?search。需要將?config.query?值和?run?從文件中讀取的?contents?傳遞給?search?函數。接著?run?會打印出?search?返回的每一行:
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {let contents = fs::read_to_string(config.filename)?;for line in search(&config.query, &contents) {println!("{}", line);}Ok(())
}
?這里仍然使用了?for?循環獲取了?search?返回的每一行并打印出來。
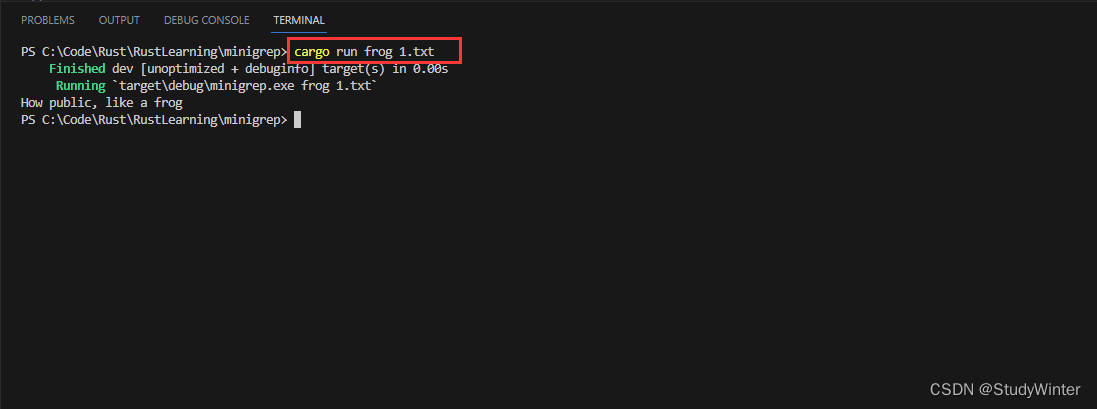
OK了
13.5?處理環境變量
將增加一個額外的功能來改進?minigrep:用戶可以通過設置環境變量來設置搜索是否是大小寫敏感的 。當然,我們也可以將其設計為一個命令行參數并要求用戶每次需要時都加上它,不過在這里我們將使用環境變量。這允許用戶設置環境變量一次之后在整個終端會話中所有的搜索都將是大小寫不敏感的。
編寫一個大小寫不敏感search函數的失敗測試
希望增加一個新函數?search_case_insensitive,并將會在設置了環境變量時調用它。這里將繼續遵循 TDD 過程,其第一步是再次編寫一個失敗測試。我們將為新的大小寫不敏感搜索函數新增一個測試函數,并將老的測試函數從?one_result?改名為?case_sensitive?來更清楚的表明這兩個測試的區別
文件名: src/lib.rs
#[cfg(test)]
mod tests {use super::*;#[test]fn case_sensitive() {let query = "duct";let contents = "\
Rust:
safe, fast, productive.
Pick three.
Duct tape.";assert_eq!(vec!["safe, fast, productive."],search(query, contents));}// 這里是新加的#[test]fn case_insensitive() {let query = "rUsT";let contents = "\
Rust:
safe, fast, productive.
Pick three.
Trust me.";assert_eq!(vec!["Rust:", "Trust me."],search_case_insensitive(query, contents));}
}
注意我們也改變了老測試中?contents?的值。還新增了一個含有文本?"Duct tape."?的行,它有一個大寫的 D,這在大小寫敏感搜索時不應該匹配 "duct"。我們修改這個測試以確保不會意外破壞已經實現的大小寫敏感搜索功能;這個測試現在應該能通過并在處理大小寫不敏感搜索時應該能一直通過。
大小寫?不敏感?搜索的新測試使用?"rUsT"?作為其查詢字符串。在我們將要增加的?search_case_insensitive?函數中,"rUsT"?查詢應該包含帶有一個大寫 R 的?"Rust:"?還有?"Trust me."?這兩行,即便他們與查詢的大小寫都不同。這個測試現在會編譯失敗因為還沒有定義?search_case_insensitive?函數。
實現search_case_insensitive函數
search_case_insensitive?函數,將與?search?函數基本相同。唯一的區別是它會將?query?變量和每一?line?都變為小寫,這樣不管輸入參數是大寫還是小寫,在檢查該行是否包含查詢字符串時都會是小寫。
pub fn search_case_insensitive<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {let query = query.to_lowercase();let mut results = Vec::new();for line in contents.lines() {if line.to_lowercase().contains(&query) {results.push(line);}}results
}首先我們將?query?字符串轉換為小寫,并將其覆蓋到同名的變量中。對查詢字符串調用?to_lowercase?是必需的,這樣不管用戶的查詢是?"rust"、"RUST"、"Rust"?或者?"rUsT",我們都將其當作?"rust"?處理并對大小寫不敏感。
注意?query?現在是一個?String?而不是字符串 slice,因為調用?to_lowercase?是在創建新數據,而不是引用現有數據。如果查詢字符串是?"rUsT",這個字符串 slice 并不包含可供我們使用的小寫的?u?或?t,所以必需分配一個包含?"rust"?的新?String。現在當我們將?query?作為一個參數傳遞給?contains?方法時,需要增加一個 & 因為?contains?的簽名被定義為獲取一個字符串 slice。
接下來在檢查每個?line?是否包含?search?之前增加了一個?to_lowercase?調用將他們都變為小寫。現在我們將?line?和?query?都轉換成了小寫,這樣就可以不管查詢的大小寫進行匹配了。
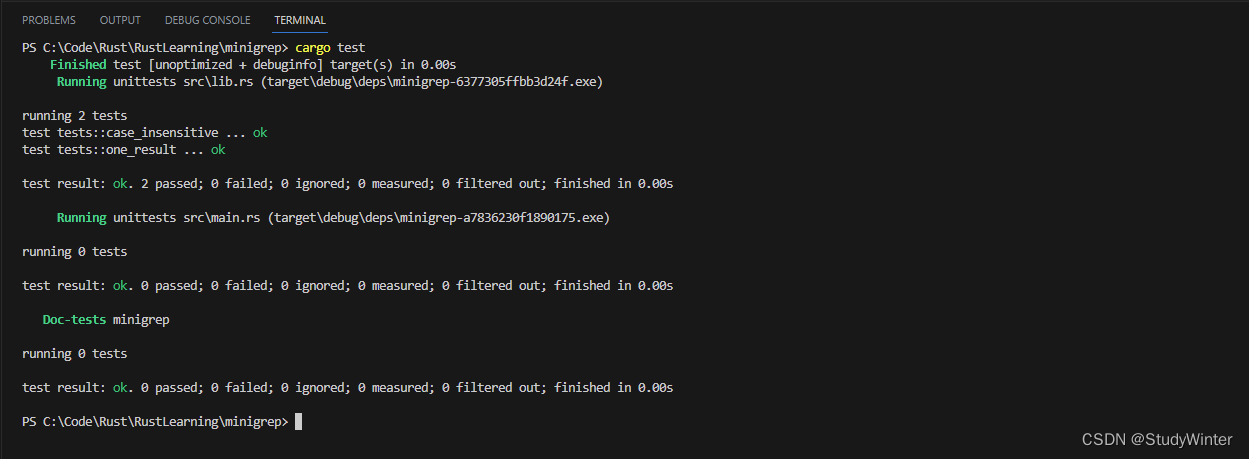
好的!現在,讓我們在?run?函數中實際調用新?search_case_insensitive?函數。首先,我們將在?Config?結構體中增加一個配置項來切換大小寫敏感和大小寫不敏感搜索。增加這些字段會導致編譯錯誤,因為我們還沒有在任何地方初始化這些字段:
pub struct Config {pub query: String,pub filename: String,pub case_sensitive: bool,
}這里增加了?case_sensitive?字符來存放一個布爾值。接著我們需要?run?函數檢查?case_sensitive?字段的值并使用它來決定是否調用?search?函數或?search_case_insensitive?函數,如示例所示。注意這還不能編譯:
文件名: src/lib.rs
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {let contents = fs::read_to_string(config.filename)?;let results = if config.case_sensitive {search(&config.query, &contents)} else {search_case_insensitive(&config.query, &contents)};for line in results {println!("{}", line);}Ok(())
}
最后需要實際檢查環境變量。處理環境變量的函數位于標準庫的?env?模塊中,所以我們需要在?src/lib.rs?的開頭增加一個?use std::env;?行將這個模塊引入作用域中。接著在?Config::new?中使用?env?模塊的?var?方法來檢查一個叫做?CASE_INSENSITIVE?的環境變量。文件名: src/lib.rs
use std::env;// --snip--impl Config {pub fn new(args: &[String]) -> Result<Config, &'static str> {if args.len() < 3 {return Err("not enough arguments");}let query = args[1].clone();let filename = args[2].clone();let case_sensitive = env::var("CASE_INSENSITIVE").is_err();Ok(Config { query, filename, case_sensitive })}
}這里創建了一個新變量?case_sensitive。為了設置它的值,需要調用?env::var?函數并傳遞我們需要尋找的環境變量名稱,CASE_INSENSITIVE。env::var?返回一個?Result,它在環境變量被設置時返回包含其值的?Ok?成員,并在環境變量未被設置時返回?Err?成員。
我們使用?Result?的?is_err?方法來檢查其是否是一個 error(也就是環境變量未被設置的情況),這也就意味著我們?需要?進行一個大小寫敏感搜索。如果CASE_INSENSITIVE?環境變量被設置為任何值,is_err?會返回 false 并將進行大小寫不敏感搜索。我們并不關心環境變量所設置的?值,只關心它是否被設置了,所以檢查?is_err?而不是?unwrap、expect?或任何我們已經見過的?Result?的方法。

?看起來程序仍然能夠工作!現在將?CASE_INSENSITIVE?設置為?1?并仍使用相同的查詢?to。
如果你使用 PowerShell,則需要用兩個命令來設置環境變量并運行程序:
$ $env:CASE_INSENSITIVE=1
$ cargo run to poem.txt
13.6?將錯誤信息輸出到標準錯誤而不是標準輸出
檢查錯誤應該寫入何處
首先,讓我們觀察一下目前?minigrep?打印的所有內容是如何被寫入標準輸出的,包括那些應該被寫入標準錯誤的錯誤信息。可以通過將標準輸出流重定向到一個文件同時有意產生一個錯誤來做到這一點。我們沒有重定向標準錯誤流,所以任何發送到標準錯誤的內容將會繼續顯示在屏幕上。
命令行程序被期望將錯誤信息發送到標準錯誤流,這樣即便選擇將標準輸出流重定向到文件中時仍然能看到錯誤信息。目前我們的程序并不符合期望;相反我們將看到它將錯誤信息輸出保存到了文件中。
我們通過?>?和文件名?output.txt?來運行程序,我們期望重定向標準輸出流到該文件中。在這里,我們沒有傳遞任何參數,所以會產生一個錯誤:
$ cargo run > output.txt
結果

將錯誤打印到標準錯誤
標準庫提供了?eprintln!?宏來打印到標準錯誤流,所以將兩個調用?println!?打印錯誤信息的位置替換為?eprintln!:
fn main() {let args: Vec<String> = env::args().collect();let config = Config::new(&args).unwrap_or_else(|err| {eprintln!("Problem parsing arguments: {}", err);process::exit(1);});if let Err(e) = minigrep::run(config) {eprintln!("Application error: {}", e);process::exit(1);}
}
再次嘗試用同樣的方式運行程序,不使用任何參數并通過?>?重定向標準輸出:
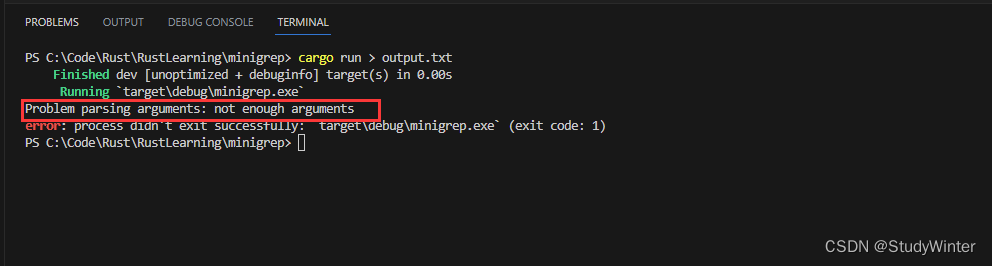
現在我們看到了屏幕上的錯誤信息,同時?output.txt?里什么也沒有,這正是命令行程序所期望的行為。
如果使用不會造成錯誤的參數再次運行程序,不過仍然將標準輸出重定向到一個文件,像這樣:
$ cargo run to poem.txt > output.txt
我們并不會在終端看到任何輸出,同時?output.txt?將會包含其結果:
文件名: output.txt
Are you nobody, too?
How dreary to be somebody!結果
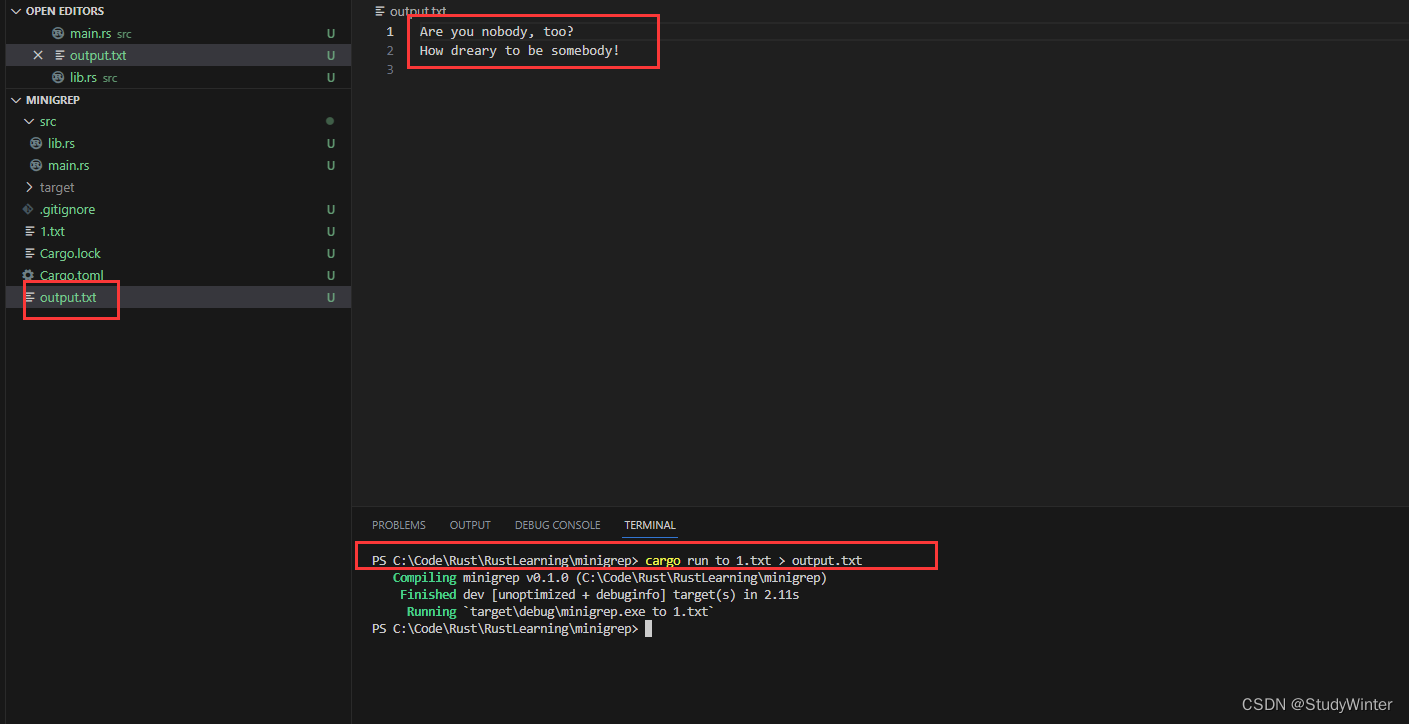
參考:一個 I/O 項目:構建命令行程序 - Rust 程序設計語言 簡體中文版 (bootcss.com)





)


用戶列表查詢接口(下))


)







