一、歸一化
Ⅰ什么是歸一化?
答:其實就是把數據歸一到0-1之間,也就是縮放。
常用的歸一化操作是最大最小值歸一化,公式如下: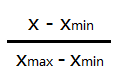
例如:1,3,5,7,9,10,其中max=10,min=1,把數據代入公式可得:
0(1-1 / 10-1),2/9(3-1 / 10-1),4/9(5-1 / 10-1),2/3(7-1 / 10-1),8/9(9-1 / 10-1),1(10-1 / 10-1),這樣就把1-10這些數給歸一化到0-1之間了。
Ⅱ為什么要做歸一化?
答:只要是基于梯度來進行下降求解最優解,都需要歸一化,目的是各個維度梯度可以同時收斂
Ⅲ不做歸一化,產生的問題是什么?
答:如果X1<<X2,那么W1>>W2,那么我們W1初始化之后要到達最優解的位置走的距離就遠大于W2初始化之后要到達最優解的位置走的距離!
因為X1<<X2,那么g1 = (y_hat-y)*x1 ,g2 = (y_hat-y) * x2,那么g1<<g2
因為g1<<g2,那么W調整的幅度等于W_t+1 - W_t = - alpha * g
所以g越小,調整的幅度就越小
總結一下上面的推導:
X1<<X2,W1調整的幅度<<W2調整的幅度,但是W1需要調整的距離>>W2需要調整的距離,矛盾就產生了,如果此時不做歸一化去使用梯度下降求解最優解的話,產生的效果,即會是同樣的迭代次數下,W2已經調整好了,W1還在慢慢的往前挪,整體看起來,就比先做歸一化,再做梯度下降,需要的迭代次數要多了!!!
二、最大最小值歸一化操作
Ⅰ怎么讓多個維度對應的W基本上在同一時刻收斂?
答:對多個維度X來進行統一的歸一化,比如說,最大值最小值歸一化的方法
Ⅱ何為最大值最小值歸一化呢?
答:(X-Xmin)/(Xmax-Xmin),最大值最小值歸一化的特點是一定可以把一列數據歸到0到1之間
Ⅲ什么是過擬合?
答:擬合過度,用算法生成的模型,很好的擬合了你以有的數據,訓練集數據,但是當來新的數據的時候,比如測試集的數據,預測的準確率反而降低了很多,那這個時候就是發生了過擬合現象
Ⅳ如何防止過擬合呢?
答:防止過擬合,等價于提高模型的泛化能力,或者推廣能力,或者說白了就是舉一反三的能力!提高了模型的容錯能力!
學霸:有監督的機器學習!
學神:有很強的學習能力,能自己找到學習的方法!無監督的機器學習!
學渣:你的算法壓根就沒選對,數據預處理也沒對,學習方法不對!
學癡:做練習題都會,考試稍微一變化,就掛!過擬合了!沒有泛化能力!
Ⅴ如何在機器學習里面防止過擬合呢?
答:模型參數W個數,越少越好,無招勝有招
模型參數W的值越小越好,這樣如果X輸入有誤差,也不會太影響y預測結果
通過正則化 到loss function里面去
L1 = n個維度的w絕對值加和
L2 = n個維度的w平方和
讓我們的SGD,在找最優解的過程中,考慮懲罰項的影響
Ⅵ當使用懲罰項,會產生什么影響?
答:使用懲罰項,會提高模型的泛化能力,但是因為人為的改變了損失函數,所以在一定程度上犧牲了正確率,即對訓練集已有數據的擬合效果,但是沒關系,因為我們的模型目的是對未來新的數據進行預測。
在懲罰項里面,會有個alpha,即懲罰項的權重,我們可以通過調整alpha超參數,根據需求來決定是更看重模型的正確率還是模型的泛化能力!
![[轉帖][強烈推薦]網頁表格(Table/GridView)標題欄和列凍結(跨瀏覽器兼容)](http://pic.xiahunao.cn/[轉帖][強烈推薦]網頁表格(Table/GridView)標題欄和列凍結(跨瀏覽器兼容))














函數與示例)


)
