一、加載fashion_mnist數據集
fashion_mnist數據集中數據為28*28大小的10分類衣物數據集
其中訓練集60000張,測試集10000張
from tensorflow import keras
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as npfashion_mnist = keras.datasets.fashion_mnist
(train_images,train_labels),(test_images,test_labels) = fashion_mnist.load_data()print(train_images.shape)
"""
(60000, 28, 28)
"""
print(test_images.shape)
"""
(10000, 28, 28)
"""
print(train_labels.shape)
"""
(60000,)
"""
print(test_labels.shape)
"""
(60000,)
"""
光看像素值是不是能猜到這個圖片是啥了?
print(train_images[0])#看一下訓練集第一張圖片28*28像素點的值
"""
[[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0][ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0][ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0][ 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 13 73 0 0 1 4 0 0 0 0 1 1 0][ 0 0 0 0 0 0 0 0 0 0 0 0 3 0 36 136 127 62 54 0 0 0 1 3 4 0 0 3][ 0 0 0 0 0 0 0 0 0 0 0 0 6 0 102 204 176 134 144 123 23 0 0 0 0 12 10 0][ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 155 236 207 178 107 156 161 109 64 23 77 130 72 15][ 0 0 0 0 0 0 0 0 0 0 0 1 0 69 207 223 218 216 216 163 127 121 122 146 141 88 172 66][ 0 0 0 0 0 0 0 0 0 1 1 1 0 200 232 232 233 229 223 223 215 213 164 127 123 196 229 0][ 0 0 0 0 0 0 0 0 0 0 0 0 0 183 225 216 223 228 235 227 224 222 224 221 223 245 173 0][ 0 0 0 0 0 0 0 0 0 0 0 0 0 193 228 218 213 198 180 212 210 211 213 223 220 243 202 0][ 0 0 0 0 0 0 0 0 0 1 3 0 12 219 220 212 218 192 169 227 208 218 224 212 226 197 209 52][ 0 0 0 0 0 0 0 0 0 0 6 0 99 244 222 220 218 203 198 221 215 213 222 220 245 119 167 56][ 0 0 0 0 0 0 0 0 0 4 0 0 55 236 228 230 228 240 232 213 218 223 234 217 217 209 92 0][ 0 0 1 4 6 7 2 0 0 0 0 0 237 226 217 223 222 219 222 221 216 223 229 215 218 255 77 0][ 0 3 0 0 0 0 0 0 0 62 145 204 228 207 213 221 218 208 211 218 224 223 219 215 224 244 159 0][ 0 0 0 0 18 44 82 107 189 228 220 222 217 226 200 205 211 230 224 234 176 188 250 248 233 238 215 0][ 0 57 187 208 224 221 224 208 204 214 208 209 200 159 245 193 206 223 255 255 221 234 221 211 220 232 246 0][ 3 202 228 224 221 211 211 214 205 205 205 220 240 80 150 255 229 221 188 154 191 210 204 209 222 228 225 0][ 98 233 198 210 222 229 229 234 249 220 194 215 217 241 65 73 106 117 168 219 221 215 217 223 223 224 229 29][ 75 204 212 204 193 205 211 225 216 185 197 206 198 213 240 195 227 245 239 223 218 212 209 222 220 221 230 67][ 48 203 183 194 213 197 185 190 194 192 202 214 219 221 220 236 225 216 199 206 186 181 177 172 181 205 206 115][ 0 122 219 193 179 171 183 196 204 210 213 207 211 210 200 196 194 191 195 191 198 192 176 156 167 177 210 92][ 0 0 74 189 212 191 175 172 175 181 185 188 189 188 193 198 204 209 210 210 211 188 188 194 192 216 170 0][ 2 0 0 0 66 200 222 237 239 242 246 243 244 221 220 193 191 179 182 182 181 176 166 168 99 58 0 0][ 0 0 0 0 0 0 0 40 61 44 72 41 35 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0][ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0][ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]]
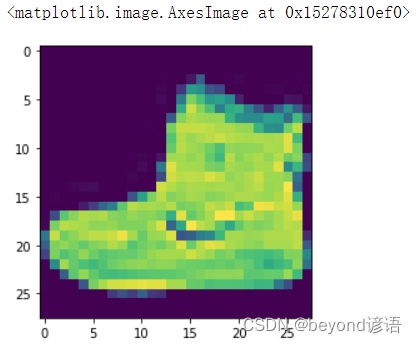
"""輸出以下這個照片
plt.imshow(train_images[0])
二、開始訓練模型
model = keras.Sequential([keras.layers.Flatten(input_shape=(28,28)),#照片完全展平,一維數組形式keras.layers.Dense(128,activation=tf.nn.relu),#128個神經元keras.layers.Dense(10,activation=tf.nn.softmax)#輸出層0-9,一共十個
])
查看模型的結構
第一層784個,flatten層將輸入的2828圖像進行展開,排列成一行,2828=784
第二層128個,128個神經元;100480個參數,第一層的784和第二層的128全排列,784*128=100352,每一個都有一個bias偏置項,100352+128=100480
第三層10個,也就是10分類,10個不同的類別,到時候輸出10個概率值,哪個大就是哪一類;1290個參數,第二層128個神經元,分別于10進行全排列,128*10=1280,每一個都有一個bias偏置項,1280+10=1290
model.summary()
"""
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten (Flatten) (None, 784) 0
_________________________________________________________________
dense (Dense) (None, 128) 100480
_________________________________________________________________
dense_1 (Dense) (None, 10) 1290
=================================================================
Total params: 101,770
Trainable params: 101,770
Non-trainable params: 0
_________________________________________________________________
"""
為了使得效果更好,將數據集中的圖像像素值都歸一化到0-1之間
train_images_y = train_images/255#對訓練圖像歸一化
訓練50次
model.compile(optimizer="adam",loss="sparse_categorical_crossentropy",metrics=['accuracy'])#指定優化方法和損失函數
model.fit(train_images_y,train_labels,epochs=50)#訓練
因為模型訓練的時候傳入的時訓練集歸一化之后的圖像
故,模型評估的時候也需要對測試集進行歸一化圖像
test_images_y = test_images/255#測試評估的時候需要對測試圖像也要歸一化
model.evaluate(test_images_y,test_labels)#evaluate評估效果
"""
[0.5110174604289234, 0.8845]
"""
從測試集中挑選幾個進行測試,實際上會輸出10個值,也就是可能性的概率值,最大的就是預測的類別
model.predict([[test_images[0]/255]])
"""
array([[2.2063166e-16, 1.1835037e-17, 7.4574429e-23, 2.0577940e-22,4.3680589e-17, 2.7080047e-08, 3.8249505e-15, 3.4797877e-06,1.4701404e-10, 9.9999654e-01]], dtype=float32)
"""
篩選模型預測出的值最大的那個
print(np.argmax(model.predict([[test_images[0]/255]])))
"""
9
"""
看下這個圖片的實際標簽
print(test_labels[0])
"""
9
"""
預測值和實際值一樣,說明預測對了
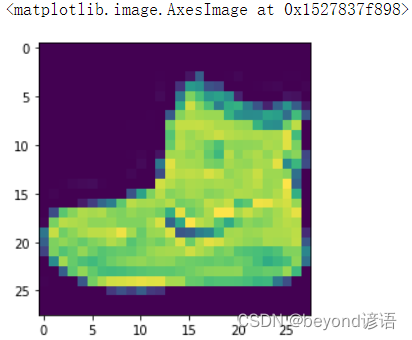
展示下這個圖片
plt.imshow(train_images[0])





![[數據庫]oracle客戶端連服務器錯誤](http://pic.xiahunao.cn/[數據庫]oracle客戶端連服務器錯誤)


)
)









