一、準備數據集
kagglecatsanddogs網上一搜一大堆,這里我就不上傳了,需要的話可以私信
導包
import os
import zipfile
import random
import shutil
import tensorflow as tf
from tensorflow.keras.optimizers import RMSprop
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from shutil import copyfile
貓和狗的照片各12500張
print(len(os.listdir('./temp/cats/')))
print(len(os.listdir('./temp/dogs/')))
"""
12500
12500
"""
生成訓練數據文件夾和測試數據文件夾
import os
import zipfile
import random
import shutil
import tensorflow as tf
from tensorflow.keras.optimizers import RMSprop
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from shutil import copyfiledef create_dir(file_dir):if os.path.exists(file_dir):print("True")shutil.rmtree(file_dir)#刪除再創建os.makedirs(file_dir)else:os.makedirs(file_dir)cat_source_dir = "./temp/cats/"
train_cats_dir = "./temp/train/cats/"
test_cats_dir = "./temp/test/cats/"dot_source_dir = "./temp/dogs/"
train_dogs_dir = "./temp/train/dogs/"
test_dogs_dir = "./temp/test/dogs/"create_dir(train_cats_dir)#創建貓的訓練集文件夾
create_dir(test_cats_dir)#創建貓的測試集文件夾
create_dir(train_dogs_dir)#創建狗的訓練集文件夾
create_dir(test_dogs_dir)#創建狗的測試集文件夾"""
True
True
True
True
"""
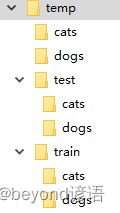
將總的貓狗圖像按9:1分成訓練集和測試集,貓和狗各12500張
最終temp/train/cats和temp/train/dogs兩個文件夾下各12500 * 0.9=11250張
temp/test/cats和temp/test/dogs這兩個文件夾下各12500 * 0.1=1250張
cats和dogs為總共的貓狗圖像
test和train為準備的數據集文件
import os
import zipfile
import random
import shutil
import tensorflow as tf
from tensorflow.keras.optimizers import RMSprop
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from shutil import copyfiledef split_data(source,train,test,split_size):files = []for filename in os.listdir(source):file = source + filenameif os.path.getsize(file)>0:files.append(filename)else:print(filename + "is zero file,please ignoring")train_length = int(len(files)*split_size)test_length = int(len(files)-train_length)shuffled_set = random.sample(files,len(files))train_set = shuffled_set[0:train_length]test_set = shuffled_set[-test_length:]for filename in train_set:this_file = source + filenamedestination = train + filenamecopyfile(this_file,destination)for filename in test_set:this_file = source + filenamedestination = test + filenamecopyfile(this_file,destination)cat_source_dir = "./temp/cats/"
train_cats_dir = "./temp/train/cats/"
test_cats_dir = "./temp/test/cats/"dot_source_dir = "./temp/dogs/"
train_dogs_dir = "./temp/train/dogs/"
test_dogs_dir = "./temp/test/dogs/"split_size = 0.9
split_data(cat_source_dir,train_cats_dir,test_cats_dir,split_size)
split_data(dog_source_dir,train_dogs_dir,test_dogs_dir,split_size)
二、模型的搭建和訓練
先對數據進行歸一化操作,預處理進行優化一下
import os
import zipfile
import random
import shutil
import tensorflow as tf
from tensorflow.keras.optimizers import RMSprop
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from shutil import copyfiletrain_dir = "./temp/train/"
train_datagen = ImageDataGenerator(rescale=1.0/255.0)#優化網絡,先進行歸一化操作
train_generator = train_datagen.flow_from_directory(train_dir,batch_size=100,class_mode='binary',target_size=(150,150))#二分類,訓練樣本的輸入的要一致validation_dir = "./temp/test/"
validation_datagen = ImageDataGenerator(rescale=1.0/255.0)
validation_generator = validation_datagen.flow_from_directory(validation_dir,batch_size=100,class_mode='binary',target_size=(150,150))
"""
Found 22500 images belonging to 2 classes.
Found 2500 images belonging to 2 classes.
"""
搭建模型架構
model = tf.keras.models.Sequential([tf.keras.layers.Conv2D(16,(3,3),activation='relu',input_shape=(150,150,3)),tf.keras.layers.MaxPooling2D(2,2),tf.keras.layers.Conv2D(32,(3,3),activation='relu'),tf.keras.layers.MaxPooling2D(2,2),tf.keras.layers.Conv2D(64,(3,3),activation='relu'),tf.keras.layers.MaxPooling2D(2,2),tf.keras.layers.Flatten(),tf.keras.layers.Dense(512,activation='relu'),tf.keras.layers.Dense(1,activation='sigmoid')
])
model.compile(optimizer=RMSprop(lr=0.001),loss='binary_crossentropy',metrics=['acc'])
訓練模型
225:因為數據一共22500張,貓和狗各12500張,其對于訓練集個11250張,故訓練集共22500張,在預處理第一段代碼中,batch_size=100設置了一批100個,故總共應該有225批
epochs=2:兩輪,也就是所有的樣本全部訓練一次
每輪包含225批,每一批有100張樣本
history = model.fit_generator(train_generator,epochs=2,#進行2輪訓練,每輪255批verbose=1,#要不記錄每次訓練的日志,1表示記錄validation_data=validation_generator)"""
Instructions for updating:
Use tf.cast instead.
Epoch 1/2
131/225 [================>.............] - ETA: 2:03 - loss: 0.7204 - acc: 0.6093
"""
history是模型運行過程的結果
三、分析訓練結果
import matplotlib.image as mpimg
import matplotlib.pyplot as pltacc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']epochs = range(len(acc))
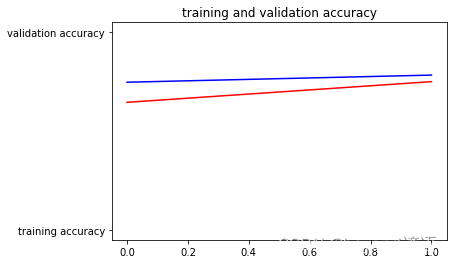
epoch太少了,導致是直線,多訓練幾輪實際應該是折線圖
準確率
plt.plot(epochs,acc,'r',"training accuracy")
plt.plot(epochs,val_acc,'b',"validation accuracy")
plt.title("training and validation accuracy")
plt.figure()
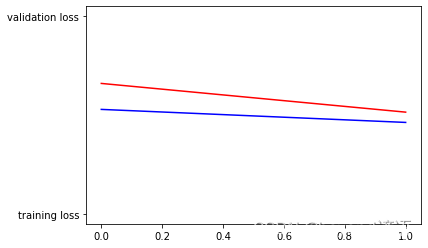
損失值
plt.plot(epochs,loss,'r',"training loss")
plt.plot(epochs,val_loss,'b',"validation loss")
plt.figure()
四、模型的使用驗證
import numpy as np
from google.colab import files
from tensorflow.keras.preprocessing import imageuploaded = files.upload()
for fn in uploaded.keys():path = 'G:/Juptyer_workspace/Tensorflow_mooc/sjj/test/' + fn#該路徑為要用模型測試的路徑img = image.load_img(path,target_size=(150,150))x = image.img_to_array(img)#多維數組x = np.expand_dims(x,axis=0)#拉伸images = np.vstack([x])#水平方向拉直classes = model.predict(images,batch_size=10)print(classes[0])if classes[0]>0.5:print(fn + "it is a dog")else:print(fn + "it is a cat")






函數與示例)






![時間工具類[DateUtil]](http://pic.xiahunao.cn/時間工具類[DateUtil])




:異常日志)
