一、Conv2d
torch.nn.Conv2d官網文檔
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros', device=None, dtype=None)
| 參數 | 解釋 | 官網詳情說明 |
|---|---|---|
| in_channels | 輸入的通道數,如果是彩色照片通道數(RGB)就是3 | (int) – Number of channels in the input image |
| out_channels | 輸出的通道數。若輸入為一張單通道的灰度圖像,輸出通道設置為2,則卷積層會提供2個卷積核(不一定完全相同)來分別對這個單通道圖像進行卷據操作,得到2張特征圖 | (int) – Number of channels produced by the convolution |
| kernel_size | 卷積核的大小,可以輸入一個整數或者一個元組 | (int or tuple) – Size of the convolving kernel |
| stride | 卷積的過程中移動的步數 | (int or tuple, optional) – Stride of the convolution. Default: 1 |
| padding | 是否對原始圖像進行加邊操作 | (int, tuple or str, optional) – Padding added to all four sides of the input. Default: 0 |
| dilation | 卷積核對應位置的距離,卷積的各個元素之間具有位置,并非全部相鄰 | (int or tuple, optional) – Spacing between kernel elements. Default: 1 |
| groups | 分組卷積,一般都是設置為1,幾乎不用分組卷積 | (int, optional) – Number of blocked connections from input channels to output channels. Default: 1 |
| bias | 偏置,常設置為True,也就是最后加個常數進行微調 | (bool, optional) – If True, adds a learnable bias to the output. Default: True |
| padding_mode | 在padding進行加邊操作的時候,需要加的內容是啥,一般都是zero 全填充0 | (string, optional) – ‘zeros’, ‘reflect’, ‘replicate’ or ‘circular’. Default: ‘zeros’ |
相關參數設置的演示,需要科學上網,懂得都懂
二、代碼演示
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriterdataset_test = torchvision.datasets.CIFAR10("CIFAR_10",train=False,transform=torchvision.transforms.ToTensor(),download=True)
#下載CIFAR10數據集到CIFAR_10文件夾下,train=False下載測試集,transform=torchvision.transforms.ToTensor()對數據進行轉換為tensor類型,download=True若沒有則下載數據集dataloader = DataLoader(dataset=dataset_test,batch_size=32)
#dataset=dataset_test指定裝載的數據集為dataset_test也就是CIAFAR10數據集中的測試集;batch_size=32每32張為一組class Beyond(nn.Module):def __init__(self):super(Beyond, self).__init__()self.conv2d_1 = Conv2d(in_channels=3,out_channels=6,kernel_size=3,stride=1,padding=1)#in_channels=3輸入的3通道的彩色圖片#out_channels=6輸出為通過卷積之后得到的6通道的特征圖#kernel_size=3卷積核的大小為(3,3)#stride=1每一步進行(1,1)的移動#padding=1為了防止卷積之后的特征圖大小變化,這里向圖片的加了一圈邊def forward(self,input):result = self.conv2d_1(input)#對傳入的input數據進行卷積,卷積的配置在__init__中進行定義return resultbeyond = Beyond()
print(beyond)
"""
Beyond((conv2d_1): Conv2d(3, 6, kernel_size=(3, 3), stride=(1, 1))#也就是__init__中的定義
)
"""writer = SummaryWriter("y_log")#準備上傳至tensorboardi = 0
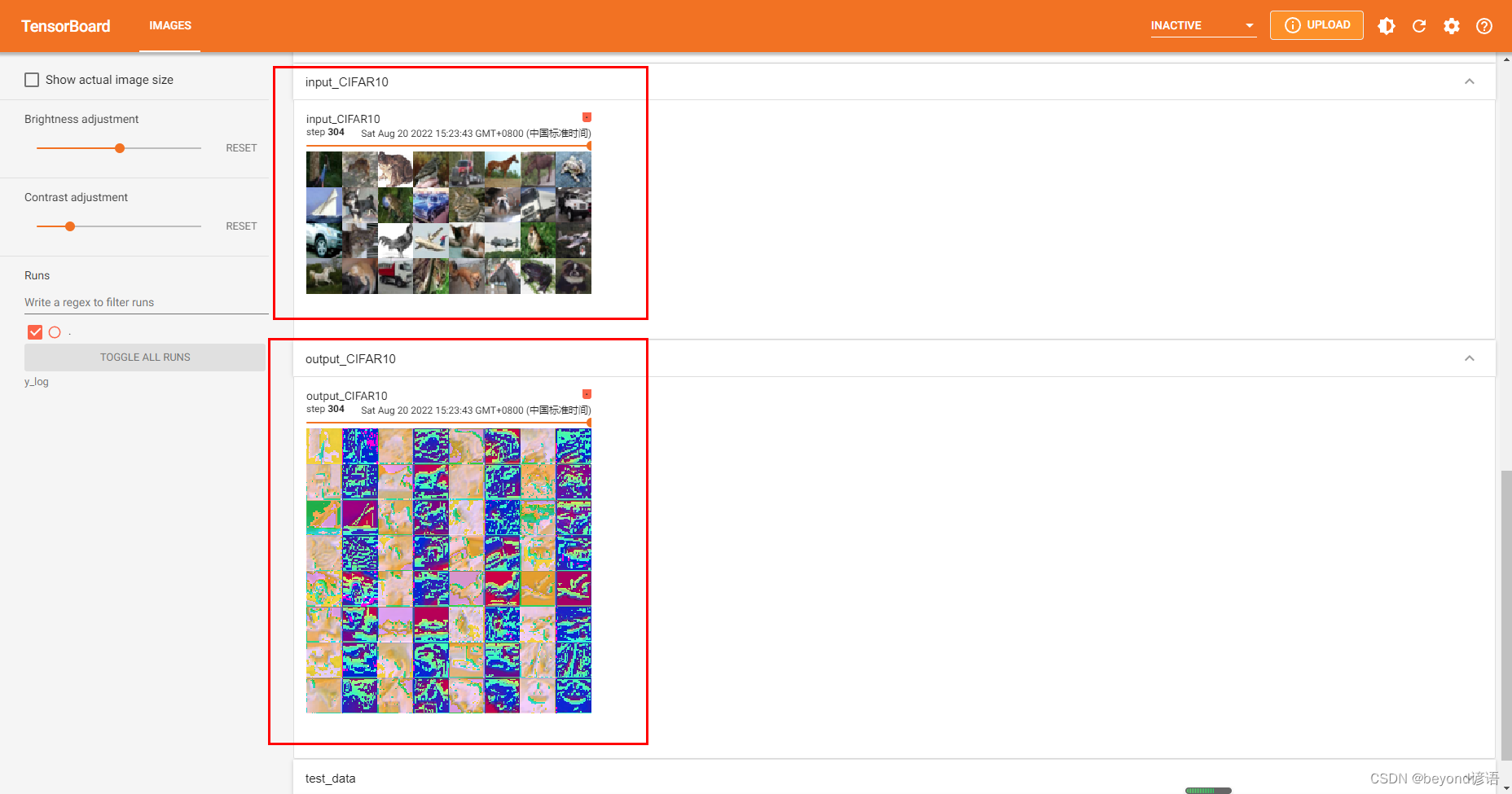
for data in dataloader:imgs,targets = dataoutput = beyond(imgs)#print(imgs.shape)#torch.Size([32, 3, 32, 32])#print(output.shape)#torch.Size([32, 6, 32, 32])#原始的數據為[32, 3, 32, 32],[batch,channel,H,W]#卷積之后變成了6通道,故需要轉換輸出數據output = torch.reshape(output,(-1,3,32,32))#這里的channel為3,而batch為-1表示:輸出就為3個,剩下的往batch上加,相當于多來幾組writer.add_images("input_CIFAR10",imgs,i)writer.add_images("output_CIFAR10",output,i)i = i + 1writer.close()
在Terminal下運行tensorboard --logdir=y_log --port=7870,logdir為打開事件文件的路徑,port為指定端口打開;
通過指定端口2312進行打開tensorboard,若不設置port參數,默認通過6006端口進行打開。

點擊該鏈接或者復制鏈接到瀏覽器打開即可
input_CIFAR10為32張一組,而output_CIFAR10則不一樣
原因是在神經網絡模型構建的時候Conv2d(in_channels=3,out_channels=6,kernel_size=3,stride=1,padding=1),輸入3通道,卷積操作之后輸出6通道
因為通道數的不同,無法上傳至tensorboard展示,故又通過torch.reshape(output,(-1,3,32,32))對output進行了轉換下格式,其中(-1,3,32,32),out_channels將強制轉換為3,而因為是-1故需要將多余的通過batch進行擴展,也就是增加每組圖片的數量,故在tensorboard中顯示的時候input和output顯示的每組數量不一樣。




![[分享]SharePoint移動設備解決方案](http://pic.xiahunao.cn/[分享]SharePoint移動設備解決方案)


)
)








)
函數與示例)
