網絡訓練好了,需要提供輸入進行驗證網絡模型訓練的效果
一、加載測試數據
創建python測試文件,beyond_test.py
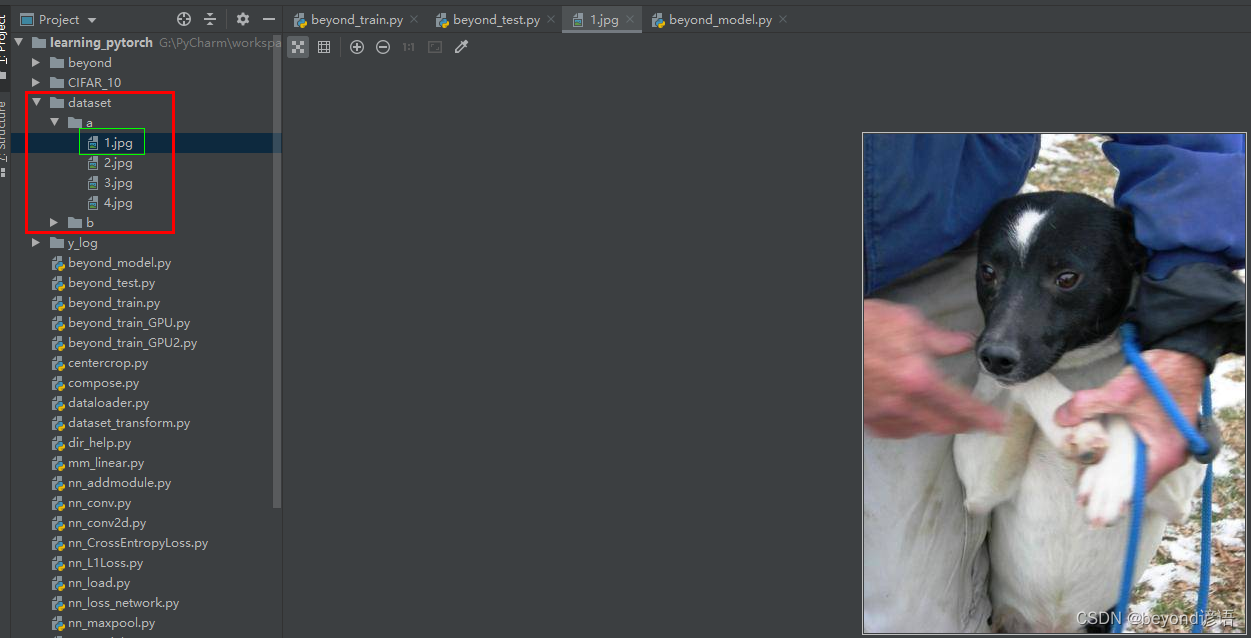
保存在dataset文件夾下a文件夾里的1.jpg小狗圖片
二、讀取測試圖片,重新設置模型所規定的大小(32,32),并轉為tensor類型數據
import torchvision
from PIL import Image
from torch import nn
from torchvision import transforms
img_path = "./dataset/a/1.jpg"#當前路徑下的dataset文件夾下的a文件夾下的1.jpg文件
img = Image.open(img_path)
print(img)#<PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=381x499 at 0x1CE281C2748>
img = img.convert('RGB')#png為四通道,jpg為三通道,這里只需要保存RGB通道,可以適應png和jpg圖片#①剪切尺寸
trans_resize = transforms.Resize((32,32))
#②轉為tensor類型
trans_tensor = transforms.ToTensor()transform = torchvision.transforms.Compose([trans_resize,trans_tensor])
#Compose參數都是transform對象,且第一個輸出必須滿足第二個輸入
#trans_resize為Resize對象,最后輸出為PIL類型
#trans_tensor為ToTensor對象,輸入為PIL,輸出為tensorimg = transform(img)
img = torch.reshape(img,(1,3,32,32))
print(img.shape)#torch.Size([1, 3, 32, 32])
#送入神經網絡需要的格式為(batch_size,channel,H,W)
三、加載模型
由十七、完整神經網絡模型訓練步驟博文所訓練的模型存放在該路徑目錄下,這里只是訓練3次而已,僅作為學習。
class Beyond(nn.Module):def __init__(self):super(Beyond,self).__init__()self.model = nn.Sequential(nn.Conv2d(in_channels=3,out_channels=32,kernel_size=(5,5),stride=1,padding=2),nn.MaxPool2d(2),nn.Conv2d(in_channels=32,out_channels=32,kernel_size=(5,5),stride=1,padding=2),nn.MaxPool2d(2),nn.Conv2d(in_channels=32,out_channels=64,kernel_size=(5,5),stride=1,padding=2),nn.MaxPool2d(2),nn.Flatten(),nn.Linear(in_features=1024,out_features=64),nn.Linear(in_features=64,out_features=10))def forward(self,input):x = self.model(input)return xbeyond = torch.load("./beyond/beyond_3.pth",map_location='cpu')
# map_location='cpu'表示,不管模型是GPU還是CPU進行訓練的,此臺電腦使用CPU進行驗證# 若模型是在GPU下訓練,驗證的時候電腦沒有GPU,需要指明map_location參數
# 若不設置map_location,電腦會根據模型來進行選擇映射方式,例如模型beyond_3.pth在GPU下訓練的,則驗證的時候系統會自動調用GPU進行驗證
print(beyond)
四、模型轉換為測試類型
eval()官網API
beyond.eval()
五、將測試圖片送入模型
beyond.eval()
with torch.no_grad():output = beyond(img)
print(output)
#tensor([[ 0.7499, 0.5700, -1.3467, 0.4218, 0.0798, -0.1516, -1.3209, 0.1138, 1.2504, -0.6495]])print(output.argmax(1))#tensor([8])
六、查看驗證結果
方法一
由CIFAR10官網給的數據可以看出
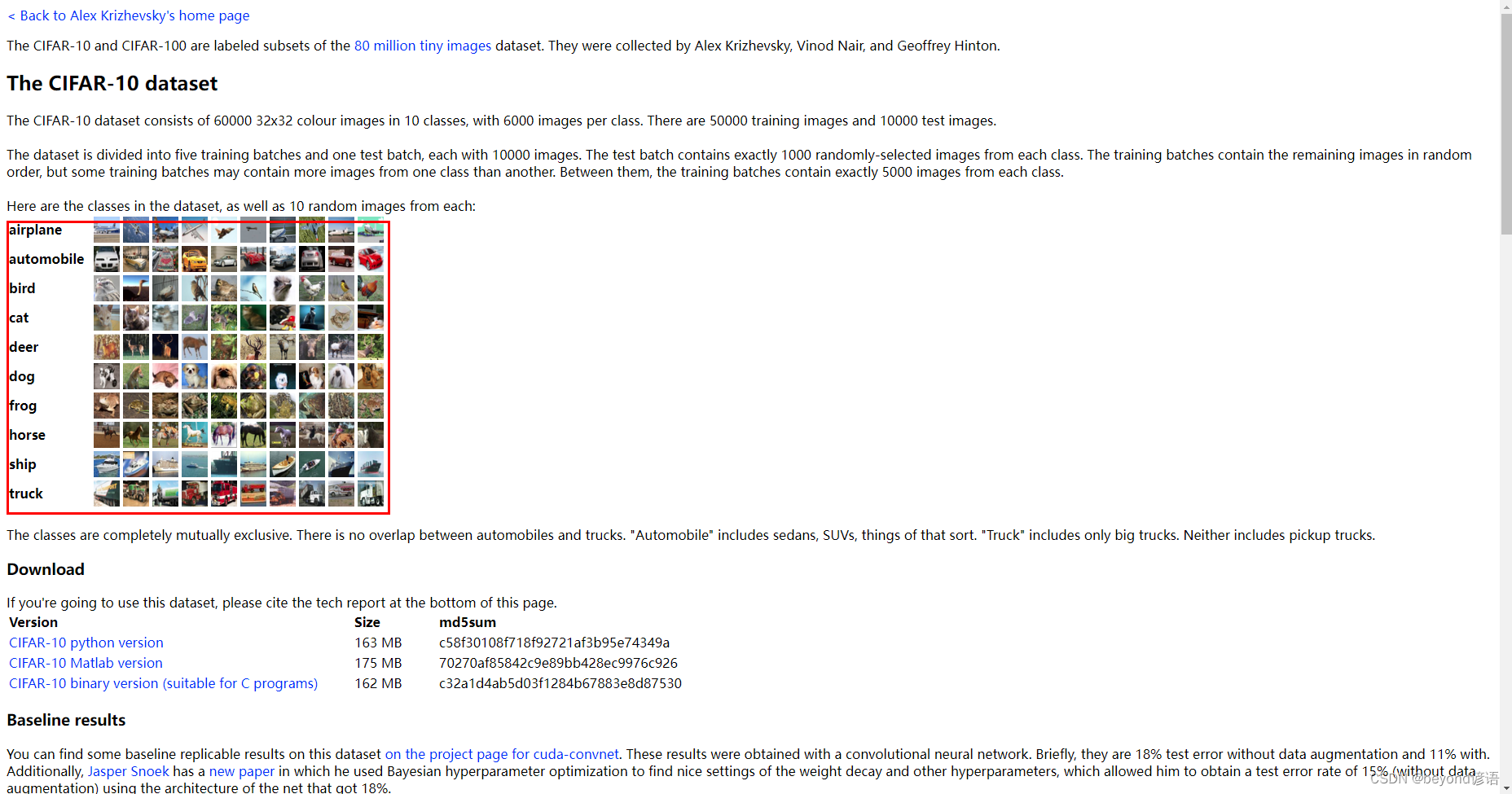
8對應的是ship
dog對應的是5
主要還是模型訓練的次數太少了,主要的目的還是學習模型套路。
方法二
在beyond_train.py文件下,(該文件來自博文十七、完整神經網絡模型訓練步驟)
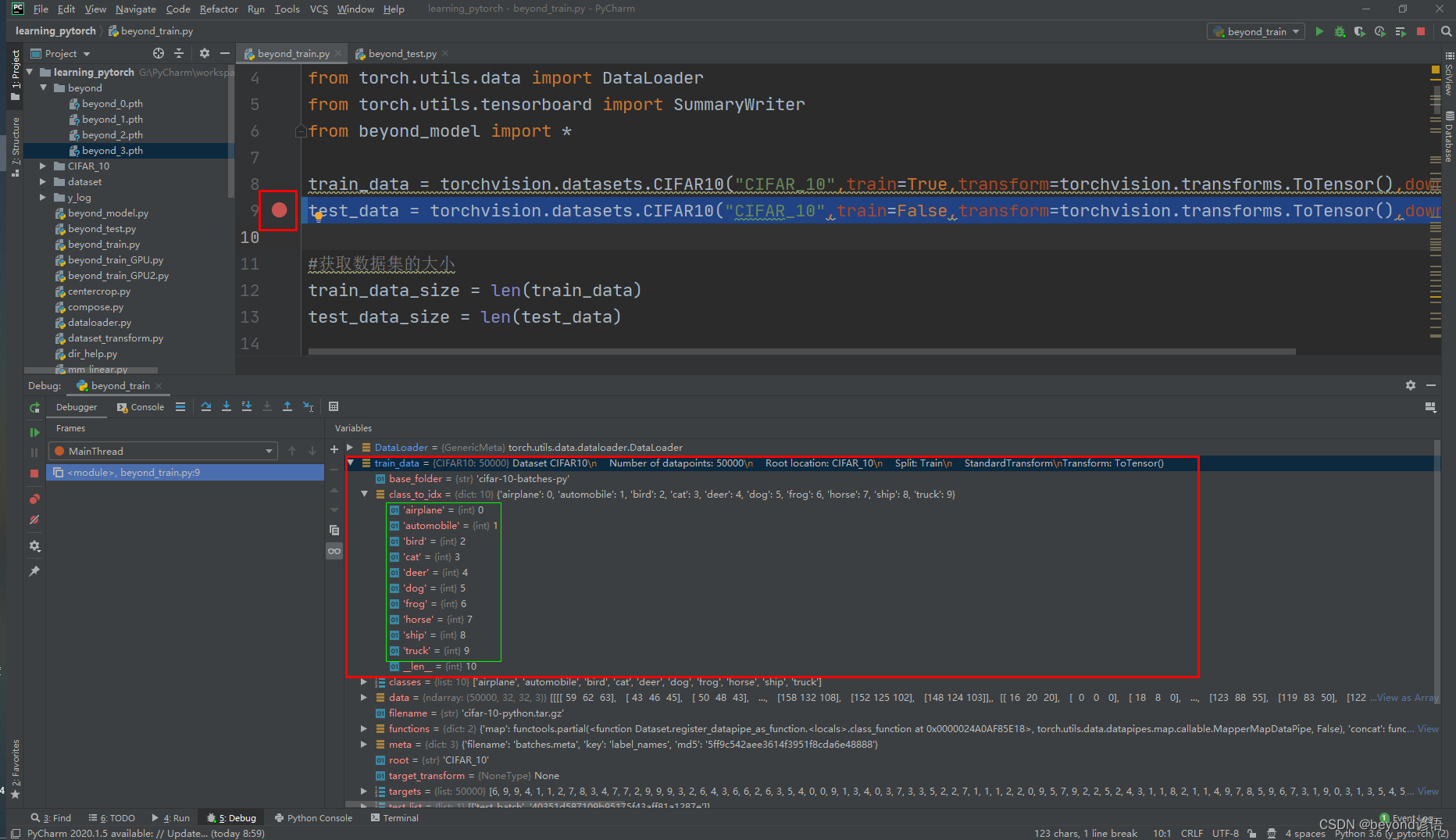
test_data = torchvision.datasets.CIFAR10("CIFAR_10",train=False,transform=torchvision.transforms.ToTensor(),download=True) 處
打個斷點,debug運行下
train_data —> class_to_idx下就存放這類別編號索引
七、完整代碼
import torch
import torchvision
from PIL import Image
from torch import nn
from torchvision import transformsclass Beyond(nn.Module):def __init__(self):super(Beyond,self).__init__()self.model = nn.Sequential(nn.Conv2d(in_channels=3,out_channels=32,kernel_size=(5,5),stride=1,padding=2),nn.MaxPool2d(2),nn.Conv2d(in_channels=32,out_channels=32,kernel_size=(5,5),stride=1,padding=2),nn.MaxPool2d(2),nn.Conv2d(in_channels=32,out_channels=64,kernel_size=(5,5),stride=1,padding=2),nn.MaxPool2d(2),nn.Flatten(),nn.Linear(in_features=1024,out_features=64),nn.Linear(in_features=64,out_features=10))def forward(self,input):x = self.model(input)return xbeyond = torch.load("./beyond/beyond_3.pth")
print(beyond)img_path = "./dataset/a/1.jpg"#當前路徑下的dataset文件夾下的a文件夾下的1.jpg文件
img = Image.open(img_path)
print(img)#<PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=381x499 at 0x1CE281C2748>
img = img.convert('RGB')#png為四通道,jpg為三通道,這里只需要保存RGB通道,可以適應png和jpg圖片#①剪切尺寸
trans_resize = transforms.Resize((32,32))
#②轉為tensor類型
trans_tensor = transforms.ToTensor()transform = torchvision.transforms.Compose([trans_resize,trans_tensor])
#Compose參數都是transform對象,且第一個輸出必須滿足第二個輸入
#trans_resize為Resize對象,最后輸出為PIL類型
#trans_tensor為ToTensor對象,輸入為PIL,輸出為tensorimg = transform(img)
img = torch.reshape(img,(1,3,32,32))
print(img.shape)#torch.Size([1, 3, 32, 32])
#送入神經網絡需要的格式為(batch_size,channel,H,W)beyond.eval()
with torch.no_grad():output = beyond(img)
print(output)
#tensor([[ 0.7499, 0.5700, -1.3467, 0.4218, 0.0798, -0.1516, -1.3209, 0.1138, 1.2504, -0.6495]])print(output.argmax(1))#tensor([8])
)














![C++ 內存基本構件new [] /delete []的意義、內存泄漏原因、VC下cookie的基本布局](http://pic.xiahunao.cn/C++ 內存基本構件new [] /delete []的意義、內存泄漏原因、VC下cookie的基本布局)



