檢測算法回顧
5、6年前的檢測算法大體如下:
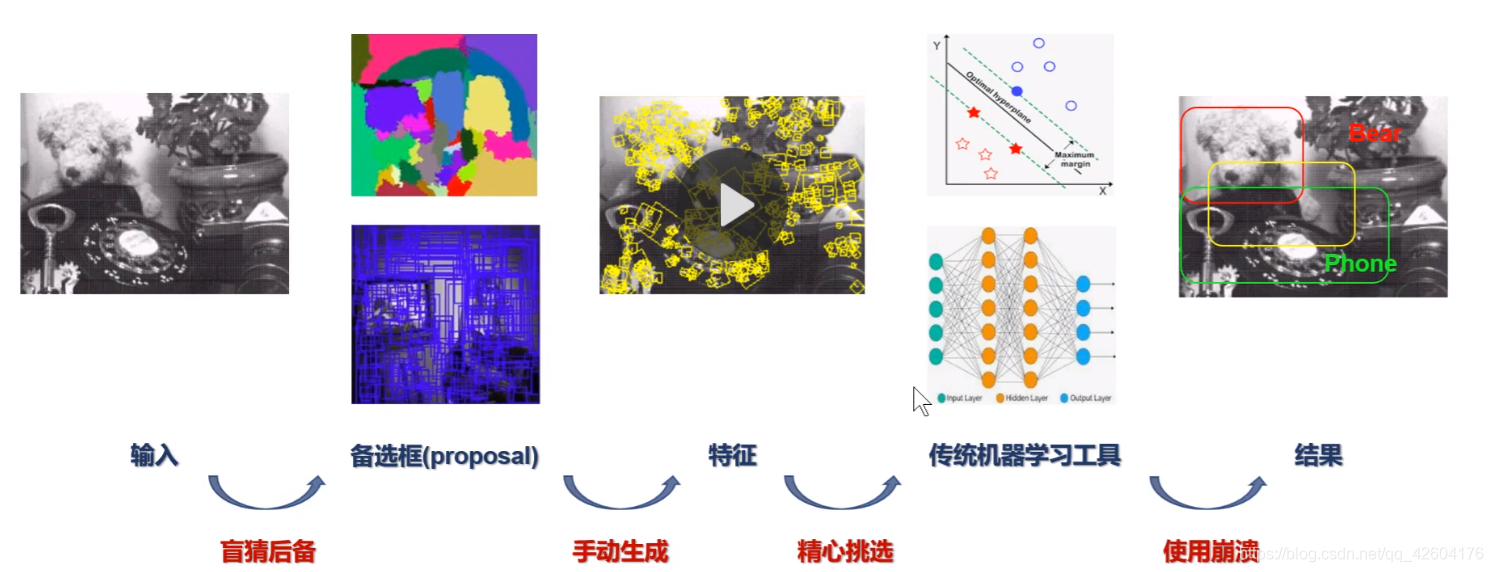
手動涉及特征時應該考慮的因素:
1、尺度不變性 2、光照不變性 3、旋轉不變性
這一步驟稱為特征工程,最重要的一個算法稱為sift,(回顧SIFT講解)體現了上述所有的觀點。
在分類的過程中,經典的工具有SVM、NN。
由于每一個步驟都會存在誤差,隨著鏈路不斷增長,會導致誤差逐步累積,最終帶來錯誤。
stage1生成備選框,stage2進行精準化.

v1講解
一些概念和定義

每個備選框都可以用四個維度唯一標定。
confidence為置信度,置信度表達式中的Pr表示是否為目標物體的概率,IoU表示真實與預測box之間的重合程度。
輸出的張量,(5*B+C)表示channel數目,5代表了box的xywh和置信度,一共有兩個box,C表示分類的個數,原文中給的是20.
B是個武斷的數字,只要比1大就行了,用1個預測框去回歸,并不能保證回歸結果很好。

損失函數解釋

函數1、2代表的是對物體邊框的回歸。3、4代表的是對置信度的回歸。
原本的格子7x7,然后每個格子對應2個bbox,一共有98個點需要估計。然而在我們上圖中只有3個物體,所以需要把超參數調整大一點,平衡非物體bbox過多。
w與h表示bbox的邊框大小,為什么使用根號呢?如果使用線性的,當物體邊框大的時候,loss也就越大,說明我們評測結果容易收到大物體影響。使得網絡只會去學習到大物體的信息,而把小物體給忽略掉了。
w與h表示bbox的邊框大小,使用根號,是為了使得大物體與小物體產生的loss差距不大。取log也可以。

為什么需要加上noobject的損失?
當我們需要學習N類物體的特征時,其實需要學習的時N+1類物體,就是多一個復雜的背景,增強泛化能力。

最后的分類略顯粗糙,需要加上softmax,與交叉熵損失相結合。softmax定義,數學表達式,編碼以及求導需要好好掌握。

v1總結

之前說過yolo是,圖像中物體中心落在哪個格子,那個格子就負責預測那一個物體。如果物體過于擁擠,導致一個格子里面有多個物體中心就不好搞了。

物理信息找邊框,語義信息分類。


很顯然,右邊的更容易回歸

人工撒anchor,不同形狀,





v3



![[轉]粵語固有辭彙與漢語北方話辭彙對照](http://pic.xiahunao.cn/[轉]粵語固有辭彙與漢語北方話辭彙對照)





)

)

方法,帶示例)


)


)

打印矢量/矩陣元素的雙曲正切值 使用Python的線性代數)