hybrid hash join
hybrid hash join是基于grace hash join 的優化。
在postgresql中的grace hash join 是這樣做的:inner table太大不能一次性全部放到內存中,pg會把inner table 和outer table按照join的key分成多個分區,每個分區(有一個inner table子部分也有一個outer table的子部分)保存在disk上。再對每個分區用普通的hash join。每個分區稱為一個batch,通過join key計算出hash value,然后計算出對應的batchNo與BucketNo:計算公式如下:
bucketNo = hash value % nbuckets;
batchNo = (hash value / nbuckets) % nbatch;
//nbuckets為buckets的個數,nbacth為batch的個數。
大致上和mysql差不多,不過mysql并沒有分buckets。
判斷是否需要多個batch的邏輯如下:
若 inner table的size + buckets的開銷 < work_mem,使用單個batch。否則使用多個batch:
plan_rows:預估的inner table的行數
plan_width:預估的inner table的列數
NTUP_PER_BUCKET:單個buckets的tuple數據
Work_mem:為hashjoin分配的內存配額
hybrid hash join的優化在于:對于第一個batch不必寫入disk,從而避免第一個batch的磁盤IO
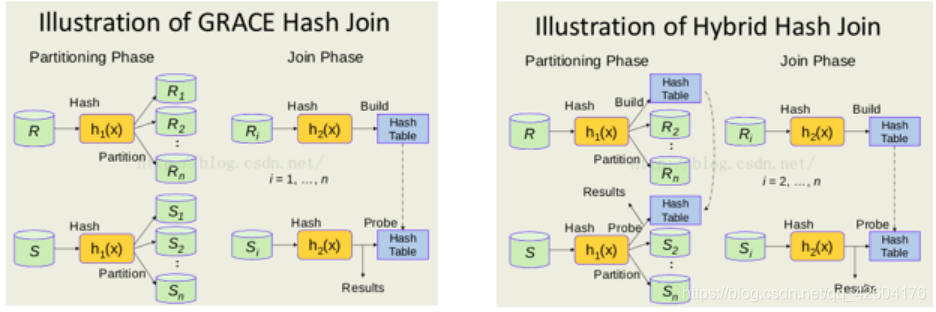
具體過程如下:
1、首先對inner table進行分區/分batch,計算batchNo:
如果該tuple屬于batch0,則加入內存中的hashtable中;
否則寫入batchNo對應的disk file中。
總結就是batch0不用寫如磁盤(當然也有例外,在下文會提到)
2、對outer table進行分區/分batch,計算batchNo:
如果tuple屬于batch0,那么用key去內存hashtable尋找(equal_range or find),匹配則輸出,否則繼續讀下一行probe tuple。
否則寫入batchNo對應的disk file中。
3、outer table掃描完畢,batch0也處理完了。
開始按照No處理下一個batchx:
加載batchx的inner table到內存,build hash table
掃描batchx的outer table,進行probe。
batchx處理完,處理batchx+1,直到所有batch都處理完畢。
現在還有一個問題:如果分割后的batch0仍然太大,不能一次性放到內存中,怎么辦?
postgresql的做法是將batch個數翻倍,從原本的n變為2n。重新掃描batch0的tuples,根據nbatch = 2n,重新計算所屬的batch。如果重新計算后的batcth仍然屬于batch0,就保留在內存中,否則從內存中拿出,寫入到tuple對應的新batch中。
(此時batch0的后半部分數據被分配到batchn上)

注意,此時不會移動磁盤中batch file中已有的tuple,當處理到該batch的時候會處理。
還記得上文提到的hybrid hash join的取模操作嗎?這個操作保證了,batch數目翻倍后,tuple所屬的batch只會向后擴展。
剛剛說的只是batch0,當我們繼續處理batch_i的時候,可能還是會遇到這個問題。那么就繼續將nbatch數目翻倍吧!
當然tuple所屬的batchNo也會變化。

打印矢量/矩陣元素的雙曲正切值 使用Python的線性代數)






| 套裝1)


![得到前i-1個數中比A[i]小的最大值,使用set,然后二分查找](http://pic.xiahunao.cn/得到前i-1個數中比A[i]小的最大值,使用set,然后二分查找)

和vector :: end()函數打印矢量的所有元素...)

)
![[ Java4Android ] Java基本概念](http://pic.xiahunao.cn/[ Java4Android ] Java基本概念)
方法,帶示例)
)
