前言
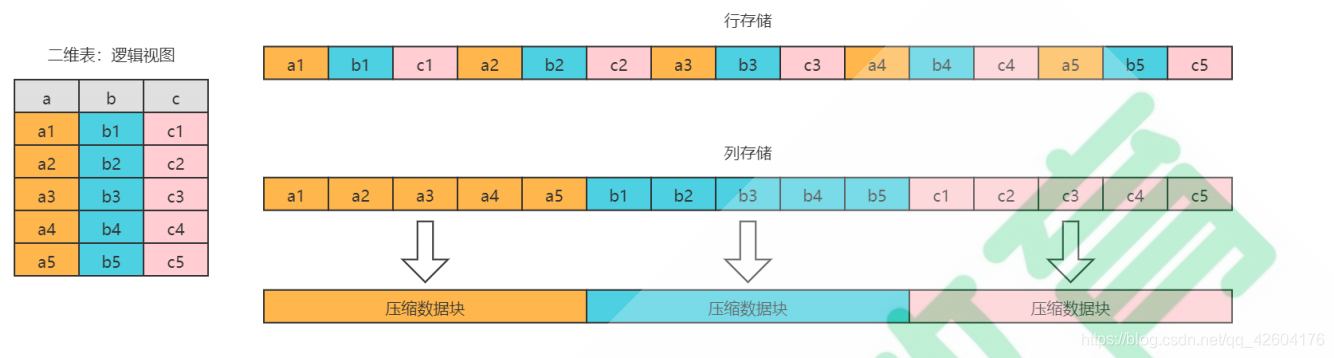
列式存儲和數據壓縮,對于一款高性能數據庫來說是必不可少的特性。一個非常流行的觀點認為,如果你想讓查詢變得更快,最簡單且有效的方法是減少數據掃描范圍和數據傳輸時的大小,而列式存儲和數據壓縮就可以幫助我們實現上述兩點。列式存儲和數據壓縮通常是伴生的,因為一般來說列式存儲是數據壓縮的前提。
按列存儲與按行存儲相比,前者可以有效減少查詢時所需掃描的數據量,這一點可以用一個示例簡單說明。假設一張數據表A擁有50個字段A1~A50,以及100行數據。現在需要查詢前5個字段并進行數據分析,則可以用如下SQL實現:
SELECT A1,A2,A3,A4,A5 FROM A
如果數據按行存儲,數據庫首先會逐行掃描,并獲取每行數據的所有50個字段,再從每一行數據中返回A1~A5這5個字段。不難發現,盡管只需要前面的5個字段,但由于數據是按行進行組織的,實際上還是掃描了所有的字段。如果數據按列存儲,就不會發生這樣的問題。由于數據按列組織,數據庫可以直接獲取A1~A5這5列的數據,從而避免了多余的數據掃描。
按列存儲相比按行存儲的另一個優勢是對數據壓縮的友好性。
數據中的重復項越多,則壓縮率越高;壓縮率越高,則數據體量越小;而數據體量越小,則數據在網絡中的傳輸越快,對網絡帶寬和磁盤IO的壓力也就越小。既然如此,那怎樣的數據最可能具備重復的特性呢?答案是屬于同一個列字段的數據,因為它們擁有相同的數據類型和現實語義,重復項的可能性自然就更高。
列式存儲
對于 OLAP 技術來說,一般都是這對大量行少量列做聚合分析,所以列式存儲技術基本可以說是 OLAP 必用的技術方案。列式存儲相比于行式存儲,列式存儲在分析場景下有著許多優良的特性。
1、分析場景中往往需要讀大量行但是少數幾個列。在行存模式下,數據按行連續存儲,所有列的數據都存儲在一個block中,不參與計算的列在IO時也要全部讀出,讀取操作被嚴重放大。而列存模式下,只需要讀取參與計算的列即可,極大的減低了IO cost,加速了查詢。
2、同一列中的數據屬于同一類型,壓縮效果顯著,壓縮比高。列存往往有著高達十倍甚至更高的壓縮比,節省了大量的存儲空間,降低了存儲成本。
3、更高的壓縮比意味著更小的data size,從磁盤中讀取相應數據耗時更短。
4、自由的壓縮算法選擇。不同列的數據具有不同的數據類型,適用的壓縮算法也就不盡相同。可以針對不同列類型,選擇最合適的壓縮算法。
5、高壓縮比,意味著同等大小的內存能夠存放更多數據,系統cache效果更好。
6、列式存儲除了降低IO和存儲的壓力之外,還為向量化執行做好了鋪墊。
下面這張圖很形象地展現了列存優勢:
下面來講講壓縮算法:以ClickHouse為例
數據壓縮
ClickHouse 的數據存儲文件 column.bin 中存儲是一列的數據,由于一列是相同類型的數據,所以方便高效壓縮。在進行壓縮的時候,請
注意:一個壓縮數據塊由頭信息和壓縮數據兩部分組成,頭信息固定使用 9 位字節表示,具體由 1 個 UInt8(1字節)整型和 2 個 UInt32(4字節)整型組成,分別代表使用的壓縮算法類型、壓縮后的數據大小和壓縮前的數據大小。每個壓縮數據塊的體積,按照其壓縮前的數據字節大小,都被嚴格控制在64KB~1MB,其上下限分別由 min_compress_block_size(默認65536=64KB)與 max_compress_block_size(默認1048576=1M)參數指定。具體壓縮規則:
原理的說法:每 8192 條記錄,其實就是一條一級索引 一個索引區間 壓縮成一個數據塊。
1、單個批次數據 size < 64KB:如果單個批次數據小于 64KB,則繼續獲取下一批數據,直至累積到size >= 64KB時,生成下一個壓縮數據塊。如果平均每條記錄小于8byte,多個數據批次壓縮成一個數據塊
2、單個批次數據 64KB <= size <=1MB:如果單個批次數據大小恰好在 64KB 與 1MB 之間,則直接生成下一個壓縮數據塊。
3、單個批次數據 size > 1MB:如果單個批次數據直接超過 1MB,則首先按照 1MB 大小截斷并生成下一個壓縮數據塊。剩余數據繼續依照上述規則執行。此時,會出現一個批次數據生成多個壓縮數據塊的情況。如果平均每條記錄的大小超過 128byte,則會把當前這一個批次的數據壓縮成多個數據塊。
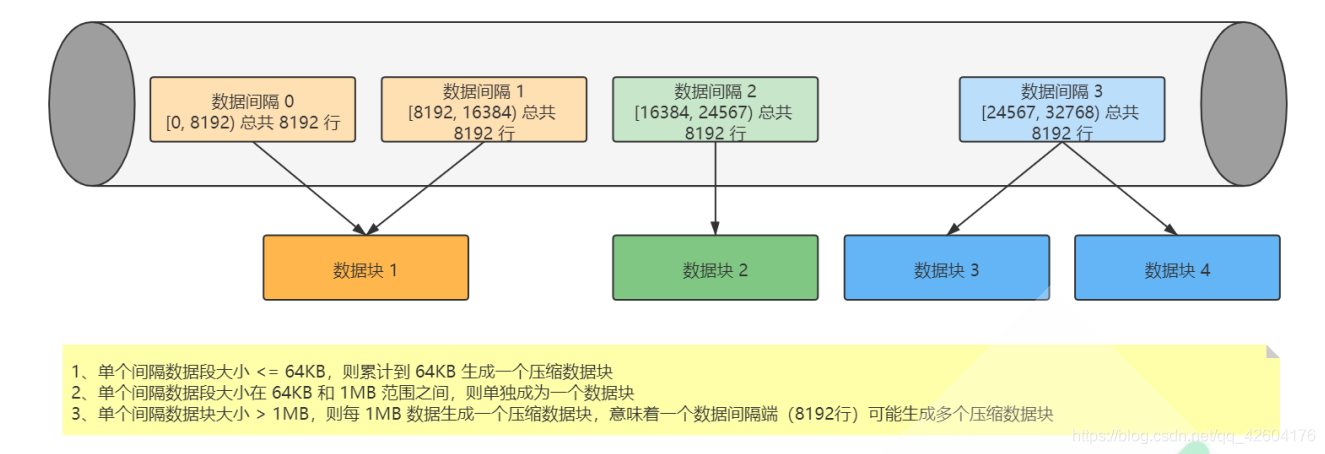
總結:在一個 xxx.bin 字段存儲文件中,并不是一個壓縮塊對應到一條一級索引,而是每 8192 條數據,構建一條一級索引。
總結:一個 [Column].bin 其實是由一個個的壓縮數據塊組成的。每個壓縮塊的大小在:64kb - 1M 之間。

參考
1、ClickHouse到底是什么?憑啥這么牛逼!
2、奈學pdf

)

方法,帶示例)


)


)

打印矢量/矩陣元素的雙曲正切值 使用Python的線性代數)






| 套裝1)
