論文地址:CVPR 2016 Open Access Repository
https://arxiv.org/pdf/1512.03385.pdf

?
Abstract

- 翻譯
????????深層的神經網絡越來越難以訓練。我們提供了一個殘差學習框架用來訓練那些非常深的神經網絡。我們重新定義了網絡的學習方式,讓網絡可以直接學習輸入信息與輸出信息的差異(即殘差),而不必學習一些無關的信息。我們提供了全面的證據來說明這種殘差網絡更加容易進行優化,而且隨著網絡層數的增加,準確率也就增加。在ImageNet的數據集中,我們證實了在深度達到152層的殘差網絡上(相當于VGG net的8倍),網絡仍然有著較低的復雜度。這些殘差網絡的合集在 ImageNet的測試集上進行評測,達到了3.57%的錯誤率,這一結果贏得?ILSVRC 2015?分類比賽的第一名。我們同時也提供了在CIFAR-10數據集上對于100層和1000層殘差網絡的分析。
????????對于許多的視覺檢測目標來說,網絡的深度是一個非常重要的因素。僅僅是通過對于網絡深度的增加,讓我們在COCO 目標檢測數據集上獲得了28%的性能提升。深度的殘差網絡是我們在?ILSVRC 和 COCO 2015兩個比賽中所提交的模型的基礎。我們也同時獲得了ImageNet 檢測,COCO檢測和分割比賽的第一名。
- 精讀
一.Introduction

?
???????? ?
?
?????????
?
 ?
?
?
-
翻譯
????????深度卷積神經網絡的應用在圖像分類領域已經引發了一系列的突破。深度網絡很自然地集成了圖像中的低/中/高級別的特征信息和分類器,并且是以端到端的形式完成的。與此同時,不同級別的特征信息可以通過增加網絡堆疊(層數)的方式來進行豐富。最近的研究也表明網絡的深度是非常重要的一部分,例如在ImageNet數據集的挑戰中,排名靠前的結果無一不是使用了非常深的網絡來完成的(從16層到30層)。許多其他的非常著名的視覺識別任務也從深度網路中收益很多。
????????由于’深度‘對于網絡的重要意義,一個問題開始出現:學習深度的網絡就是簡單的堆疊網絡的層數嗎?眾所周知的一個障礙是梯度的消失/爆炸問題,他們都會影像深度網路的收斂。當然,這兩個已經被網絡參數的初始標準化以及網絡中間層的標準化兩個方法有效的解決了,讓擁有著數十層深度的網絡都可以通過隨機梯度下降的方法進行反向傳播。
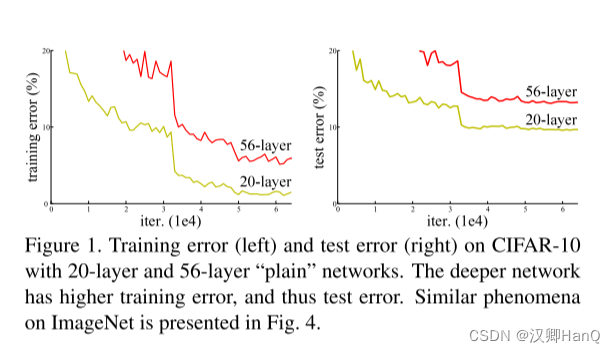
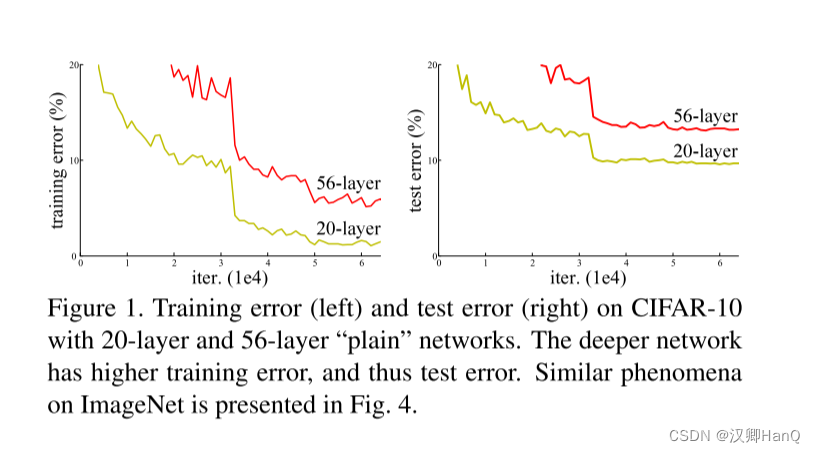
????????當網絡的深度變得越來越深的時候,一個關于網絡‘退化’的問題又顯現出來了,即隨著網路層數的增加,模型的準確性開始飽和,然后迅速退化。然而令人意外的是這些退化并不是來源于“過擬合”,而且向一個適度的神經網絡中增加更多的層還會導致更高的訓練誤差,這一點在論文[11, 42]以及我們自己的實驗中都有證明。圖1也展示了這樣的例子。
?
????????網絡訓練精度的退化問題讓我們意識到并不是所有的網絡都可以比較容易的進行優化。首先,讓我們來考慮一個淺層的網絡和在它的一個對照組,即在它的結構的基礎上增加了一些深層的網絡。對于更深的網絡的一種構建方式為所增加的層都是恒等層,另外其他的層則完全復制淺層網絡。這種結構的直觀感受是我們所構建的深層網路的訓練誤差應該不會高于之前的淺層網絡。然而實驗的結果卻告訴我們,我們所構建的深層網絡在訓練時很難得到跟淺層網絡一樣的或者高于淺層網絡的結果(或者說無法在可控的一個時間范圍內完成)。
????????注:恒等即H(x)=x,這里所說的恒等層即圖像進入網絡前跟從網絡出來后是一樣的,也就是所增加的層中,所有的權重都是1. 這樣就構成了文章中所說的恒等層
????????在這篇文章中,我們通過引入一種叫做’殘差‘的學習框架來解決上面所提到的訓練退化的問題。相對于之前的期望這些在淺層網路中增加的’新層‘可以直接擬合我們所說的恒等映射,我們讓這些層直接去擬合一個殘差映射。通過公式來表示的話:我們把開始期望擬合映射示為H(x),那么現在我們想讓這些新加的層去擬合另外一個映射,我們把它示為F(x):= H(X) -X。那么開始期望擬合的映射H(x)= F(x) + x。我們假設這種殘差映射相對于原始的映射是更加容易進行優化的。我們可以設想下如果這個恒等映射可以被優化出來,那么讓殘差變為0應該比讓那些新堆疊進去的非線性的層的權重都變為1要容易的多。
?
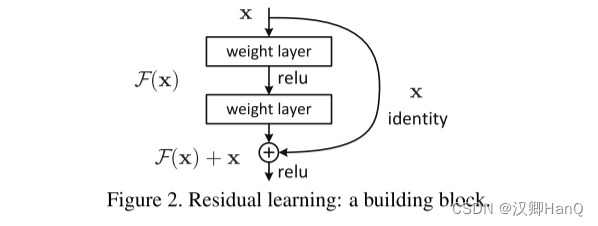
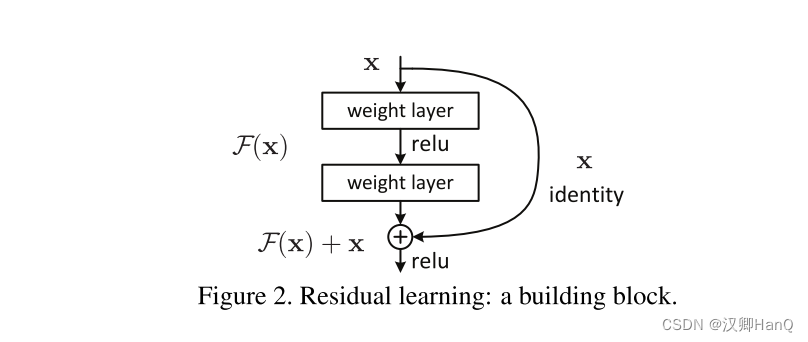
????????F(x) + x這種形式很容易在網路中通過 ’shorcut connections‘的形式來實現(如圖2所示)。’shorchut connection‘ 可以跳過一層或者多層來進行。在我們的示例中,’shorchut connection‘ 很容易的完成了恒等映射,同時,把這些輸出添加到新堆疊層的輸出中(如圖2所示)。通過這種方式進行添加一方面沒有增加額外的參數,另一方面也沒有增加計算的復雜度。同時,整個網絡仍然可以使用SGD和通用的訓練框架進行端到端的訓練。
????????我們在ImageNet的數據集上詳細的展示了訓練退化問題以及我們的解決方法。我們展示了:1) 當網絡深度增加的時候,普通的網絡體現出更高的訓練誤差,而殘差網路則表現的非常容易進行優化。2)隨著網路層數的增加,殘差網絡可以很容易的獲得較好的準確率,并且準確率還會高于之前的網路。我們同時還在CIFAR-10的數據集上進行了實驗,以此來說明訓練退化和我們的解決方法并不是只適用于一些特定的數據集。我們成功的在這個數據集上訓練了超過100層的神經網絡,最高的層數到達了1000層。
????????我們的算法也在ImageNet 分類的數據集上獲得了很高的成績。盡管我們的152層的殘差網絡是迄今為止在ImageNet數據集上使用的最深的網絡,它的負責度還是要比VGG Net要低。我們在ImageNet測試集上整體上的錯誤率為3.57%(屬于top5的范疇),同時也贏得了ILSVRC 2015 分類比賽的冠軍。這個極其深的網絡也在其他的比賽中有著出色的表現,讓我們贏得了很多比賽的冠軍,比如: ImageNet detection, ImageNet localization, CoCo detection, 和 COCO segmentation。這些證據都表明殘差網絡的方法有著很好的適用性,我們期望它可以被應用在其他的視覺/非視覺的領域。
- 精讀
二.Related Work

?
?
?
- 翻譯
????????殘差表示:在圖像識別中,VLAD用來表示字典被殘差編碼后的結果, Fisher VLAD用來表示VLAD的概率形式。他們都可以被用來非常直接的表述圖像的檢索和分類問題。在對圖像進行向量化表示的時候,通過殘差進行表示已經被證明比直接通過原始圖像進行表示有著更高的效率。
????????在low-level的計算機視覺和計算圖形學中,為了解決求偏導的問題,廣泛的使用Multigrid 方法,將問題解構成不同尺度的子問題,每一個子問題則用不同粒度(從粗粒度到細粒度)的殘差向量來進行表示。Multigrid的一種代替方案是層次化預處理, 它也依賴于那種用兩種尺度殘差表示的參數。論文[3,45,46]都證明了這種殘差的方法比那么沒有意識到殘差性質的方法能夠更快的得到收斂的結果。這些方法都表明一個好的變換或者預處理方法可以簡化優化器。
????????捷徑連接(Shortcut connection):?促成捷徑連接的理論和時間已經被研究了很長一段時間了。其中最早的實踐是在訓練多層感知機(MLPs)的時候,在輸入和輸出之間添加一個線性的連接。在論文[44, 24]中,為了解決梯度消失/梯度爆炸的問題, 一小段中間層被直接連接到輔助的分類器上。論文[39, 38, 31, 47]為了解決層間相應,梯度和傳播錯誤問題,同樣也使用了捷徑連接的方法。在論文[44]中,初始層是有一個捷徑連接和幾個更深的分支組成的。
????????在我們寫論文的同時,’高速網絡‘還提供了一個帶有門功能的捷徑連接。當然相對于我們這里的這種不需要額外參數的恒等捷徑連接,帶有門功能的捷徑連接是需要依賴于數據本身和特殊參數的。比如,當門關閉的時候,整個’高速網路‘更加相當于一個沒有殘差的網絡。相對來說,我們的方式則需要總是去學習殘差,并且我們的恒等網絡是不會關閉的,因此所有的信息都會通過殘差網絡別學習到。另外,高速網絡并沒有去論證在網絡非常深的情況下,其準確率是否可以提升。
- 精讀
三.Deep Residual Learning
3.1Residual Learning

?
- 翻譯
????????讓我們把H(X)當成在截取的一小段網絡中的最基礎的映射,X表示這小段網絡最頂層的輸入。如果假設多個非線性的層可以近似成一個復雜函數,那么也就可以假設他們同樣可以近似擬合殘差函數H(X) -X(假設輸入和輸出有著相同的維度)。所以相對于期望這段網絡可以去擬合H(X), 我們則明確的讓網絡去擬合一個殘差函數F(x):=H(x) -x. 那么原始的方程則變成了F(x) +x. 盡管兩種方式應該都可以逐漸的擬合期望函數,但是他們的難易程度應該是不同的。
????????這種變換方式的靈感來自于對于退化問題的反直覺現象(如圖1,左側)。正如我們在’介紹‘中所討論的,如果所添加的層可以被構造成恒等映射,那么更深的網路的學習誤差應該會不高于淺層網絡的訓練誤差。但是訓練退化問題讓我們了解到網絡應該很難讓所添加的這些非線性的層訓練成恒等映射。但是在殘差網路的框架下,如果恒等映射是最優的結果,那么網絡應該可以簡單的去驅動新增加的非線性層的權重都變為0,從而達到擬合恒等映射的目的。
????????在實際的例子中,恒等映射或許并不是最優的結果,但是我們的方法卻有助于解決訓練退化的問題。如果最優函數相對于一個全是0的映射更接近一個恒等映射,那么相對于去擬合一個新的函數,我們的這種操作更容易讓求解器根據所輸入的恒等映射去發現擾動。我們通過實驗(圖7)表明通常情況下學習殘差網路會比學習普通的網絡有很小的調整標準差,這也表明我們使用的恒等映射提供了很好的模型預處理。
- 精讀
3.2Identity Mapping by Shortcuts

?
?
- 翻譯
????????我們將殘差學習應用到每一個小的模塊中。一個模塊的示例如圖2所示。使用公式表示這個小模塊的話:

?
????????其中x 和y為模塊的輸入和輸出向量。函數F(x,{wi})為網絡需要學習的殘差映射。例如圖2中所示,該模塊含有兩層, F = W2σ(W1x), 其中σ表示ReLu, 為了簡化假設,biases也被省略。關于F +x 的操作,則通過捷徑連接的方式實現,進行對應位置像素的加和操作。我們在加和操作結束后,再進行第二次的非線性激活。
????????在公式1中的捷徑連接操作,即沒有增加新的參數,也沒有增加計算復雜度。這不僅在實際應用中具有很強的應用性,而且對于我們所進行的普通網絡和殘差網絡的對比實驗也是很重要的。因為這樣的話,我們就可以公平的比較具有相同的參數,深度,寬度和計算復雜度的普通網絡和殘差網絡。
????????在公式1中,x和F的維度一定要一樣,如果不一樣(例如當我們改變了輸入/輸出的通道數),我們可以通過線性投影的方式來讓他們的維度相互匹配:
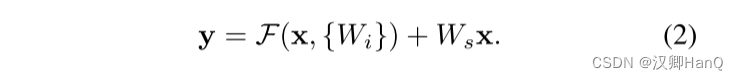
?
????????我們也可以在公式1中使用一個平方矩陣Ws。 但是我們的實驗結果表明使用恒等映射對于解決訓練退化的問題是足夠的,而且他還比較經濟,因此Ws只會在當輸入和輸出的維度不匹配的時候才使用。
????????函數F的形式是非常靈活的。在本文的實驗中,我們分別使用了2層和3層網絡來進行(如圖5所示),于此同時,更多的層數也是可以的。當然如果F只有一層的話,那么公式1則近似為一個線性層: y =W1X + X, 對此我們還沒有觀察到他的優點。
????????我們需要說明的是盡管上面的所有的表述都是用的全連接層舉例,但是這是為了方便起見,他們是可以被部署在卷積層上的。元素的相加是被應用在兩個特征圖像上的,他們在對應的通道上進行加和操作。
- 精讀
3.3NetWork Architectures

?
- 翻譯
????????我們在多個神經網絡以及其對應的殘差網絡上進行了測試,他們都得到了一致的結果。為了提供實際的例證,接下來我們將使用兩個在ImageNet上訓練的網絡進行講解。
????????普通網絡:我們的普通網絡的架構(圖3,中間)主要受到VGGnet(圖3,左)的啟發。其中的卷積層更多的使用3x3的過濾器,并且緊跟著兩個簡單的設計規則:(i)對于輸出和輸入相同的特征圖,那么層具有相同數量的過濾器;(ii)如果特征圖的尺寸減半,那么過濾器的數量則需要翻倍,用來保證層的時間復雜性。我們的下采樣直接通過使用步長為2的卷積來實現。在網絡的末尾連接了一個全局平均池化層和經過softmax的1000個參數的全連接層。網絡的總體層數是34層(如圖3,中間)所示。
????????值得注意的是,我們的網絡相對于VGGnet有更少的過濾器和更小的復雜度(圖3,左)。我們的34層基礎模型有36億浮點運算次數(乘法和加法),這只有VGG-19(196億浮點運算次數)模型參數的18%。
????????殘差網絡:?基于上述的普通網路,我們在其中插入殘差部分(如圖3,右),則把該網絡轉換成了他的對照組殘差網絡。當輸入和輸出的尺寸一致的時候,shortcut(公式1)可以被直接使用(圖3中實線部分)。當維度增加的時候(圖3中虛線部分),我們考慮了兩種方案:(A)shortcut部分仍然使用恒等映射,但是對于新增加的維度則全部使用0來代替。這種方案不增加任何的參數。(B)通過公式2中所提供的線性投影的方式來匹配增加的維度(通過使用1x1的卷積的方式來實現)。對于這兩種方案,當兩個特征圖的尺寸不一致時,都用過使用步長為2的卷積來讓他們統一。
- 精讀
3.4Implementation

- 翻譯
????????我們在ImageNet上的部署參考了論文[21, 41]的方式。圖像被進行隨機縮放,縮放的方式為讓它的短邊在[256,480]之間進行隨機采樣。然后將圖像隨機裁剪出224x224大小,并進行隨機水平方向的旋轉,最后將所有的像素點減去均值。論文[21]中的標準顏色增廣也被用到。我們在每次卷積和激活之間都添加了批量標準化操作。我們按照論文[13]的方法初始化了網絡權重,并從頭開始訓練普通網絡/殘差網絡。我們使用了SGD作為優化器,并把最小批量設置為256. 我們的學習率從0.1開始,當訓練誤差不減小的時候,我們將之前的學習率縮小10倍,直到模型進行了60x10的4次方的迭代數量。我們所使用的權重衰減系數為0.0001,動量為0.9.我們沿用了論文[16]的方法,即沒有在訓練過程中使用dropout。
????????在測試時,為了進行比較研究,我們采用了標準的10-crop的測試方法。為了獲得最佳的結果,我們采用了如論文[41,13]一樣的全卷積的方式,并使用了多尺度圖像的平均值作為結果(圖像的短邊會被縮放到{224,256,384,480,640})。
- 精讀
四.Experiments
4.1ImageNet Classification

?
 ?
?
 ?
?
 ?
?
?

 ?
?
 ?
?
- 翻譯
????????我們在ImageNet 2012的分類數據集上評測了我們的結果,這個數據集含有1000個類別。模型使用了128萬張訓練圖片,并且使用了5萬張圖片進行驗證。最后使用10萬張圖片在測試服務器上進行測試,獲得了最終的結果。我們評估了從top-1到top-5的錯誤率。
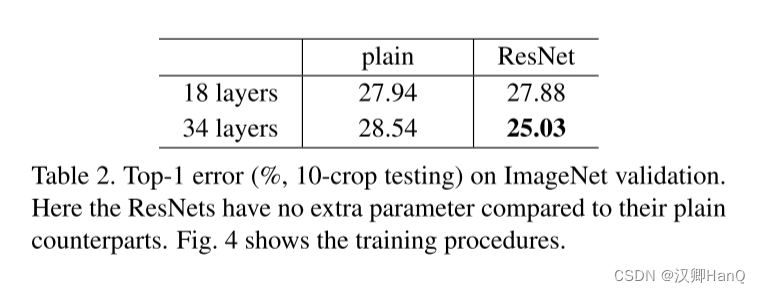
????????普通網絡:我們首先評估了18層和34層的普通網絡。34層的普通網絡如圖3(中)所示。18層的普通網絡也會相類似的結構。表1有詳細的結構。
表2中的結果表明了更深的34層的網絡相比如18層的網絡有著更高的驗證誤差。為了揭示這個原因,(如圖4, 左)我們對比了他們在整個訓練過程中的訓練/驗證誤差。我們已經觀察到訓練退化的問題-在整個訓練過程中34層網路表現出了更高的訓練誤差,盡管18層的網絡的求解空間其實只是34層的一個空間子集。
????????我們認為這種優化難題不太可能是由于梯度消失引起的。因為普通的網絡在訓練過程中都使用了批量標準化操作,這確保了參數在正向傳播的時候不會出現為0方差的情況。我們同樣驗證了由于批量標準化的使用,模型在反向傳播的過程中所展示出來的梯度也是健康的。所以無論是正向傳播還是反向傳播都沒有顯示出梯度消失的問題。事實上,34層的普通網絡仍然可以達到一個有競爭力的精度(如圖3),這表明在一定程度上求解器還是有效果的。我們猜測,或許是由于本身更深的普通網絡就具有指數級的更低的收斂速度,這或許影響了訓練誤差的減小。這種優化困難的原因將在未來進行研究。
????????殘差網絡。接下來,我們開始驗證18層和34層的殘差網絡(ResNets). 同樣,網絡的基礎架構跟上面的普通網絡是類似的,于此同時在每一對3x3的過濾器中添加了捷徑連接(如圖3,右). 在第一組比較中(表2和圖4 右), 對于所有的捷徑,我們使用了恒等映射,對于所增加的維度,我們使用了0進行填充(方案A). 所以相對于普通網絡,并沒有增加新的參數。
????????在表2和圖4中,我們有3個主要的發現。首先,形勢隨著殘差學習的引入發生了逆轉- 34層的殘差網絡的錯誤率要由于18層殘差網絡2.8%。更重要的是,34層殘差網絡展示了相當低的訓練誤差,并且可以泛化到驗證集。這表明了訓練退化問題通過這種設置得到了很好的解決,我們可以通過增加網絡深度來獲得準確率。
????????第二,相比對照組的普通網絡,34層的殘差網成功的降低了訓練誤差(圖4.右VS左),絡減少了top-1錯誤率3.5%(表2)。這個對照試驗驗證了殘差在極度深的網路上的有效性。
????????最后,我們也注意到18層的普通網絡/殘差網絡的準確率是相當的,但是18層殘差網絡的收斂更加迅速(圖4 右VS左)。當網絡不是非常深的時候(例如這里的18層),對于普通的網絡,現在所使用的SGD求解器還是可以找到一個較好的結果。在這種情況下,殘差網絡可以簡化優化過程,因為它可以比較快的在早期的階段就找到結果。
????????恒等捷徑VS投影捷徑. 我們已經證明了無參數的恒等映射可以幫助訓練。接下來,我們將調查投影映射(公式2)。在表3中,我們對比了三種方案:(A)通過使用0來填充捷徑中所增加的維度,那么這種方法無需增加任何參數(和表2,圖4右,所說的一致);(B)投影捷徑用于所增加的那部分維度,而其他的部分保持恒等映射不變;(C)所有的捷徑都采用投影捷徑。
????????表3顯示了這三種方式都要優于普通網絡的對照組。其中方案B稍微好于方案A. 我們認為這是由于通過0填充的維度確實沒有進行殘差學習所造成的。方案C勉強比方案B好一些。我們把它歸因于通過投影映射引入了額外的參數。但是方案A/B/C間的微小的差異證明了投影映射并不能從本質上解決訓練退化問題。所以為了減少內存使用,時間的復雜度和模型的大小,我們在文章的余下部分的實驗中并沒有使用方案C的方法。恒等映射對于下面即將要介紹的這種沒有增加復雜性的瓶頸結構是非常重要的。
????????深度瓶頸結構.?接下來,我們講介紹在ImageNet數據集上所使用的更深的網絡結構。考慮到可以負擔得起的訓練時間,我們把殘差塊的結構修改成一種瓶頸的結構。對于每一個殘差函數F,我們使用了一個三層的堆疊來代替之前的兩層堆疊(如圖5)。這個三層的卷積分別是1X1, 3X3, 1X1, 其中1X1的卷積層用來減小/擴大維度,使得3x3層成為輸入/輸入較小維度的瓶頸。圖5顯示了一個示例,其中這兩種設計具有相似的時間復雜度。
????????無參數的恒等映射對于瓶頸結構來說尤其重要。因為如果恒等映射(圖5,右)被替換成投影映射,那么時間復雜度和模型的大小將成倍增加。因為捷徑連接到的是兩個高維度的末端。所以恒等映射的捷徑對于瓶頸模塊來說更加高效。
????????50層殘差網絡.?在34層的網絡中,我們用3層的堆疊塊代替了2層的堆疊塊,最終形成的50層殘差網路的結果如表1.我們使用了方案B來增加維度。這個模型擁有38億浮點運算次數。
????????101層和152層殘差網絡.?我們使用了更多的3層堆疊塊,來構成了101層和152層的殘差網絡(表1)。值得注意的是,盡管網絡的深度已經明顯的增加了很多。152層的殘差網絡(113億浮點運算次數)仍然有著比VGG16/19(153/196億次浮點運算次數)更小的時間復雜度。
????????50/101/152層的殘差網絡有著比34層高很多的準確率(表3,4)。由于沒有了訓練退化問題,因此我們可以通過增加網絡的深度來獲得更高的準確性。 深度增加的好處在所有的評估指標上都顯現了出來。
????????與最先進方法的比較.?在表4中,我們對比了之前最好的單一模型的結果。我們的34層基準模型已經可以獲得非常有競爭力的準確率了。我們152層的殘差網絡的單模型具有4.49%的top-5驗證錯誤率。這個單模型的性能已經超過了之前所有模型的綜合結果(表5)。我們將六種不同深度的模型組合到一起(當時提交的時候只有兩個152層的模型)。這個組合在測試集上獲得了3.57%的top-5錯誤(表5)。這個模型獲得了ILSVRC 2015比賽的第一名。
- 精讀
4.2CIFAR-10 and Analysis
 ?
?

?
- 翻譯
????????我們也在CIFAR-10數據集上進行了研究,這個數據集分為10個類別,其中包括5萬個訓練圖片,1萬個測試圖片。我們進行實驗,在訓練數據集上訓練,在測試數據集上進行測試。由于我們的關注點是網絡在極度深的情況下的表現,而不是一定要達到最高的準確率,所以我們刻意選擇了結構較為簡單的模型來進行實驗。
????????普通網路和殘差網路的結構如圖3,中,右所示。模型的輸入為每個像素點減去均值后的32X32大小的圖片。網絡的第一層為一個3X3的卷積。然后我們分別在{32, 16, 8}不同尺寸的特征圖上使用了一個6n層的3x3卷積構成的堆疊,每個特征圖的尺寸為2n層。他們所對應的過濾器尺寸分別為{16, 32, 64}. 通過使用步長為2的卷積來完成下采樣過程。網絡的最后是一個全局的平均池化,然后再接一個使用了softmax的10分類的全連接層。這里有6n+2個堆疊的權重層。下面的表格匯總了這種結構:

????????當捷徑連接被使用時,他們總共連接3x3個層對(共3n個捷徑)。在這個數據集上,我們在所有的實驗中都使用了恒等映射(即方案A),所以我們的殘差網絡相對于普通網絡有著相同的深度,寬度和參數數量。
?
????????我們使用的權重衰減系數為0.0001,動量為0.9。使用了論文13中的初始化方法和批量標準化,但是沒有使用dropout。這個模型在兩塊GPU上進行訓練,所使用的最小批量為128.我們開始使用的學習率為0.1,在第3.2萬次和4.8萬次迭代的時候,分別縮小了之前學習率的10倍。最終在第6.4萬次迭代的時候結束了訓練。網絡是在4.5萬/5千的訓練集/驗證集上進行的。我們使用了論文24的數據增廣的方法:每個邊padding4個像素,然后在pandding后的圖像或者他的水平翻轉圖像上隨機截取32x32的圖像。在測試集上,我們只使用了原始的32x32的圖像進行測試。
????????我們對比了n={3, 5, 7, 9},即20/32/44/56層的神經網絡。圖6,左顯示了普通網絡的效果。隨著網路的加深,普通網絡出現了訓練退化問題。這種現象和在ImageNet上或者MNIST上是一致的,以此可以說明訓練退化問題是一個普遍存在的問題。
????????圖6,中顯示了殘差網絡的結果。同樣和在ImageNet上的表現是一致的(圖4.右),我們的殘差網絡突破了這一優化問題,并且隨著網絡深度的增加,可以獲得較好的結果。
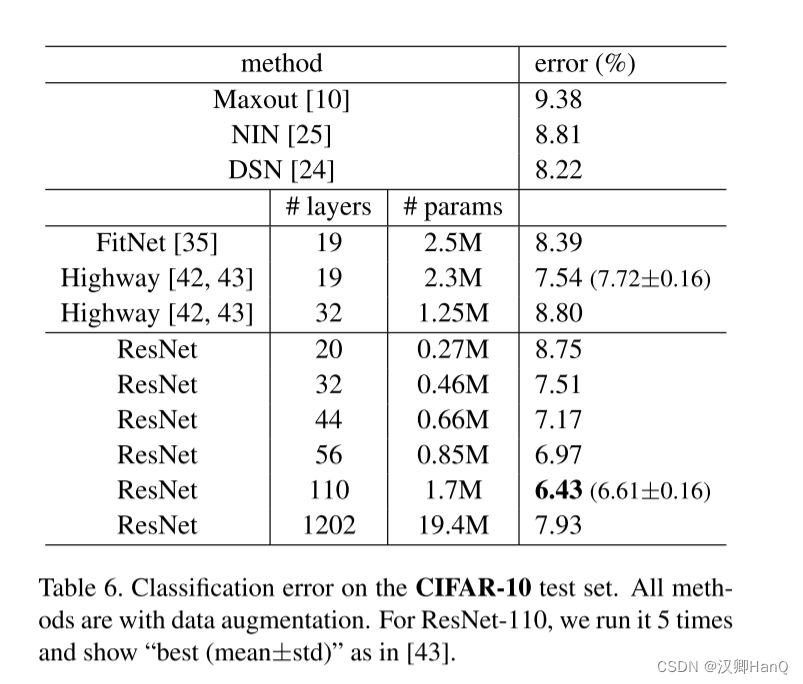
????????我們進一步的拓展n=18,以此來獲得一個110層的殘差網絡。在這種情況下,我么發現開始的0.1的學習率對于模型的收斂稍微有點大了。所以我們先是使用了0.01的學習率來預熱模型,直到訓練誤差低于80%(大約400個迭代后),然后我們把學習率調整回0.1,再繼續訓練。剩余的學習則跟之前講的是一致的。最后這個110層的神經網絡得到了較好的收斂(圖6,中)。相對于其他更深和細的網路來說(如FitNet,Highway),它有著更少的參數,然而這確實最好的結果之一(6.43%, 表6)

?
????????層響應分析.?圖7顯示了層響應的標準差。這里的響應是指每一個3x3的卷積在進行批量標準化后,以及激活函數之前的值。對于殘差網絡來說,這個分析揭示了殘差函數的響應強度。圖7顯示了殘差網絡相對于普通網絡有著更小的響應強度。這個結果也佐證了我們最初的動機(3.1節所述),殘差函數可能相對于非殘差函數更加接近于0.我們還注意到更深的網絡有著更小的響應幅度,如圖7中的ResNet20/56和110層的對照。當層數增多時候,殘差網路中單一的一個層往往趨向于減小對于參數的修改。
????????開發大于1000層的網絡.?我們開發了一個大于1000層的網絡。我們把n設置成200,因此得到了一個1202層的網絡,然后使用上面所述的方法進行訓練。我們的方法顯示在訓練這個1000多層的網絡的時候沒有遇到訓練退化的問題,并且他的訓練誤差小于0.1%(圖6,右)。它的測試誤差也相當的好(7.93%,表6)
????????但是這種極度深的網絡仍然存在一些問題。盡管1202層網絡的訓練誤差和110層網絡是相似的,但是它的測試結果卻要差于110層的網絡。我們猜測可能是由于過擬合造成的。因為對于這樣的一個小數據集,也許并不需要一個有著1202層的網路進行訓練。因為使用強化正則方法(maxout,dropout)后,可以在這個數據集上獲得一個較好的結果。在這篇文章中,我們沒有使用 maxout/dropout, 只是通過設計簡單的深度和薄的架構來進行正則,因為我們不想失去對于優化困難這個問題的聚焦。但是結合強有力的正則化后續會提升結果,這些我們未來會去做。
- 精讀
4.3Object Detection on PASCAL and MS COCO
 ?
?
?????????我們的算法在其他的識別任務上也有著很好的泛化能力。表7和8展示了目標檢測在ASCAL VOC 2007和2012以及COCO上的基準結果。我們使用faster R-CNN 作為檢測的方法。這里我們的興趣點在與使用ResNet101來代替VGG16后的改進。對于這兩種模型的部署是相同的,所以收益只能歸因于模型的結構。值得慶幸的是,在COCO數據集的挑戰中,我們比COCO的標準指標(mAP[.5,.95])提升了6%,這相當于有了28%的提升。這個結果完全歸功于所學習到的特征。
????????根據深度殘差網絡,我們在ILSVRC &COCO 2015的多個比賽中獲得了第一名: ImageNet 檢測,ImageNet 定位, COCO檢測和COCO分割。
?
?









![pwm接喇叭搞整點報時[keyestudio的8002模塊]](http://pic.xiahunao.cn/pwm接喇叭搞整點報時[keyestudio的8002模塊])

)
)
)





