文本挖掘與貝葉斯網絡方法識別化學品安全風險因素
- 1. Introduction
- 現實意義
- 理論意義
- 提出方法,目標
- 2. 材料與方法
- 2.1 數據集
- 2.2 數據預處理
- 2.3 關鍵字提取
- 2.3.1 TF-IDF
- 2.3.2 改進的BM25——BM25W
- BM25
- BM25W
- 2.3.3 關鍵詞的產生(相關系數)
- 2.4 關聯規則分析
- 2.5 貝葉斯網絡分析
1. Introduction
本研究旨在提出一種改進的文本挖掘方法來分析大量的化學品事故報告。設計了一個建立和更新分詞詞庫的工作流。關聯規則挖掘和貝葉斯網絡分析的結果能夠清晰地揭示安全風險因素之間的相互關系。本研究的方法可以快速有效地從事件報告中提取關鍵信息,為管理者提供新的見解和建議。
現實意義
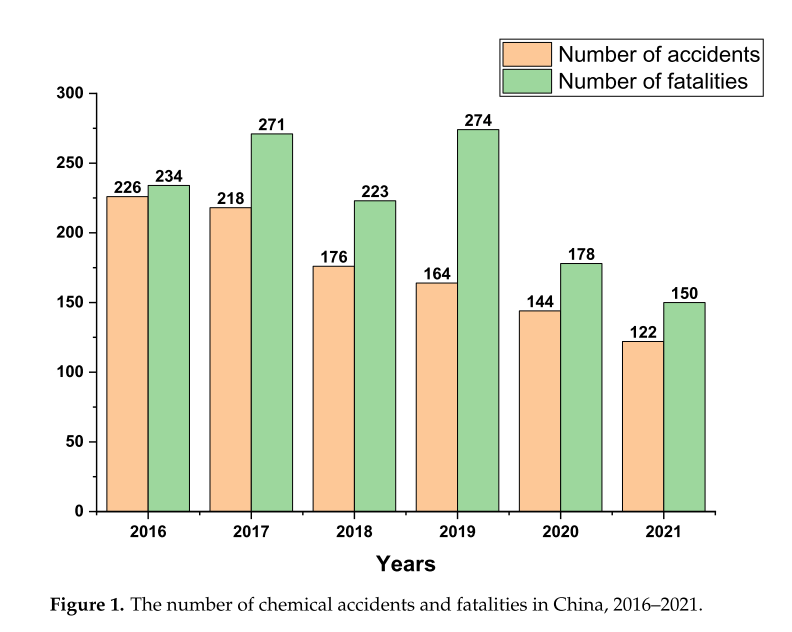
圖1顯示了2016年至2021年全國每年發生的化學品事故及死亡人數。化工事故1050起,死亡1330人,化工安全生產形勢依然十分嚴峻。因此,在保證化工產品穩定供應的同時,提高安全生產水平具有重要的現實意義。
約80%的事故發生是由人為引起的,因此識別事故因素,挖掘內在聯系,是很有必要的一件事。
理論意義
之前的化學事故研究更多的致力于安全評價方法,而不是分析原因;現有的分析方法是基于專家經驗和依賴于人為的過程,以致分析不全面。此外,該化學品的事故報告也沒有統一的標準格式,報告的內容是高度非結構化的。計算機無法直接處理這類信息,同時人為過程是耗時的,且會存在差錯的過程。因此,需要一種自動安全風險識別方法來解決處理大型文本數據集的挑戰。
一種常見的聚類方法是潛在Dirichlet分配(LDA)。LDA方法有助于有效地提高文本分類任務,這在許多高級專家和智能系統中是必不可少的,特別是在標記文本稀缺的情況下。Zhong等人[23]利用LDA模型生成的34類主題,為建筑行業的各種事故建立了深度學習(DL)和TM的框架,分析事故危害。Chen等人[24]構建了利益相關者分類體系,并利用LDA模型完成話題聚類,揭示了輿論場中利益相關者的話題焦點和演化路徑。但是,他們檢索的結果是以文字的形式來表示相應的信息,具有很高的不確定性。特別是在事故報告等大型文本中,一些詞頻很高的詞并未指明具體的危險因素,但仍被提取為關鍵詞。根據語料庫和提取目的的不同,傳統的文本挖掘已經不能有效識別安全風險因素,需要改進。
提出方法,目標
鑒于文本挖掘在化工安全研究中的應用較少,本文創造性地將文本挖掘、關聯規則挖掘和貝葉斯網絡相結合,應用于化工事故分析。
首先,在數據預處理中分別構建和更新域詞典、同義詞詞典和中斷詞詞典。然后我們改進了關鍵字提取方法,提出了BM25W模型。利用距離公式和社會技術系統對相關系數進行歸一化處理,識別出安全風險因子。
然后,利用關聯規則挖掘方法找到安全風險因素之間的強關聯規則,并發現關鍵原因之間的關聯。
最后,基于關聯規則挖掘結果進行貝葉斯網絡分析,找出化學品事故的重要因素、關鍵原因路徑、高頻因素和高度集中因素。并對這些結果進行了理論分析。
本研究不同于以往的知識驅動或模型驅動的研究,以數據驅動的方式分析文本數據的直接不可見模式和復雜關聯。我們的目標是通過提供強有力的自動分析事故原因和優化安全策略來減少事故數量。
2. 材料與方法
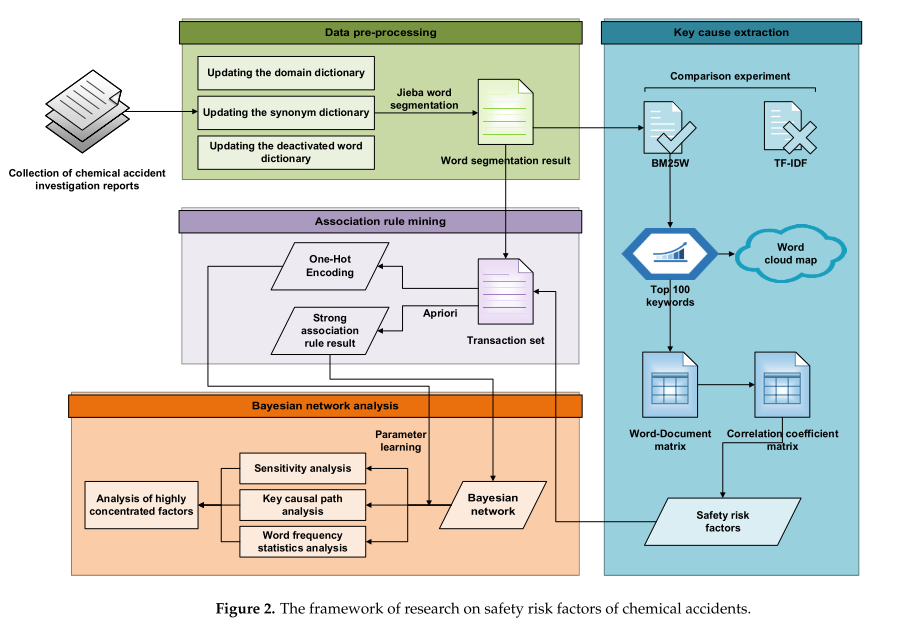
本研究主要包括數據預處理、關鍵原因提取、關聯規則挖掘和貝葉斯網絡分析四個部分,如圖2所示。這四部分將在接下來的章節中逐一介紹
2.1 數據集
化工生產領域的事故調查報告是本文分析的原始語料庫。這些報告是由安全管理領域的專家在事故發生后通過研究和分析來撰寫的。獲取事故調查報告的來源有很多。Esmaseili et al.[25]獲得了美國國家職業安全與健康研究所(NIOSH)的事故報告,Rodrigues et al.[26]獲得并分析了歐洲航空安全局(EASA)的事故報告,其他一些學者[27-29]也分別從相關官員那里獲得了所需的數據。
中國的“化工企業生產安全事故報告和調查制度”規定,對涉及人員傷亡的事故,必須進行完整、準確、及時的記錄和保存,任何單位和個人不得隱瞞。事故報告的內容應包括事故的原因、損失、責任、糾正措施等。與其他國家一樣,中國也有專門的安全生產管理部門,即中華人民共和國應急管理部(https://www.mem.gov.cn/(2022年8月2日訪問))和全國各省市應急管理部門。為保證數據來源的可靠性,共下載2011年至2022年上半年化工、危險化學品事故調查報告665份。
之后,我們對數據進行過濾,剔除不符合要求的數據,在化工生產領域留下330份事故調查報告。上述事故的級別和類型也被計算在內,如圖3和4所示。
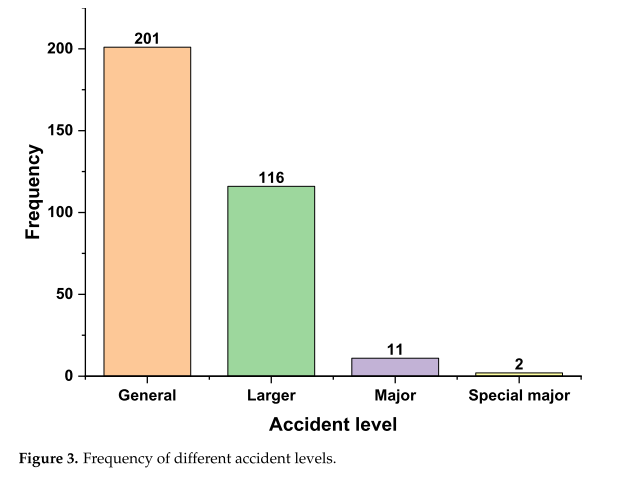
從圖3可以看出,絕大多數事故是一般事故和較大事故。雖然這些事故造成的傷亡或損失的數量很少,但它們經常發生,而且仍然是非常嚴重的。
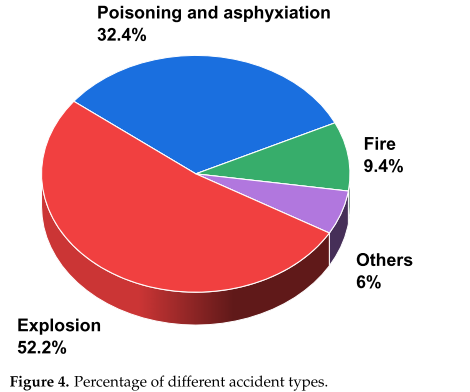
從圖4可以看出,超過一半的事故類型是爆炸,其次是中毒和窒息。這是因為大多數化工生產領域涉及易燃易爆或有毒有害氣體,容易造成混合氣體爆炸或人中毒、窒息。
2.2 數據預處理
數據預處理是一個非常重要但繁瑣的過程,因為原始語料庫中含有大量不規則或無意義的詞。最重要的任務之一是將原始中文文本分割成類似于用空格分隔的英文文本的格式,以便進行下一步的文本挖掘分析。
本研究中使用的文本分割工具是python3中的Jieba分割工具。我們觀察到,化學品生產事故的原因一般由名詞和動詞或簡單名詞組成。因此,本研究僅選取普通名詞、機構名、其他專名、普通動詞、動名詞進行分詞。通過這種方式,Jieba在分詞時自動排除了剩下的詞匯分詞結果。JiebaWSS分詞系統包含三種詞典,即領域詞典、同義詞詞典和斷詞詞典。
-
領域詞典:雖然JiebaWSS提供了一個詞典,包含了大部分常用的詞(如反應器、管道等)用于切分詞,但也有很多行業專用詞無法識別,如蒸餾塔、中間操作室、蒸汽閥、氣體檢測器等。當涉及到這些詞時,JiebaWSS可以將整個專有詞分割成兩個或多個詞。這需要事先將這些特定于行業的單詞集成到域字典中,并將字典添加到JiebaWSS中。
-
同義詞詞典:事故調查報告中的同義詞很多,大量的同義詞會使分詞結果過于離散。我們可以用一個詞來替換所有的同義詞;例如,管道、管道、蒸汽管道、壓力管道等,都可以用管道代替
-
停止詞詞典:事故調查報告中還含有大量無意義的詞、數字和符號,如“我們”、“實際上”、“exactly”、“3”、“6”、“,”。“!”等等。這些詞對于本研究的分析沒有實際意義,可以添加到停止詞詞典中進行排除。
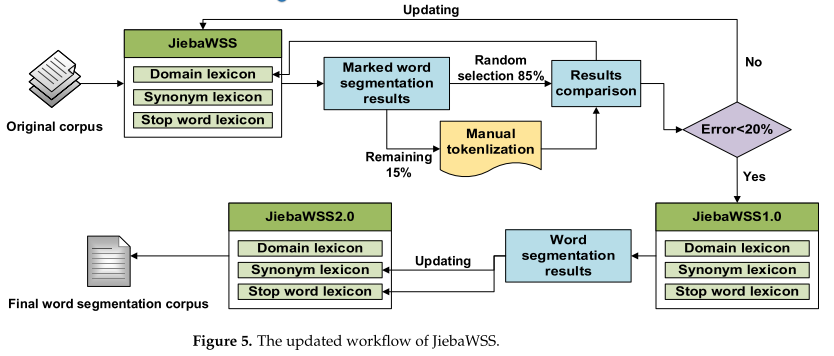
這三種詞匯對分詞結果有著直接的影響,而分詞結果又對后續的分析產生了層疊效應。因此,有必要對這三個詞匯進行更新,形成一個與本研究一致的JiebaWSS。本研究借鑒了esmaiili、Hallowell和Xu等人的詞匯開發思想,設計了一種詞匯更新方法。圖5顯示了該方法的工作流。
2.3 關鍵字提取
原語料庫拆分結果的內容非常大,難以對事故進行直接的關鍵原因分析。關鍵詞是能夠表達文獻關鍵內容的詞,計算機系統中常用來引用論文的內容特點,進行信息檢索,系統收集供讀者查閱。
2.3.1 TF-IDF
關鍵詞抽取是文本挖掘領域的一個分支,是文本檢索、文檔比較、摘要生成、文檔分類、聚類[32]等文本挖掘研究的基礎。傳統的關鍵字提取方法主要有詞頻TF (word frequency)和詞頻逆文檔頻率TF- idf (word frequency - inverse document frequency)兩種,使用簡單方便。TF認為一個單詞出現的頻率越高,它對文檔的貢獻就越大。然而,對于事故調查報告來說,并不是簡單地假設一個表示安全風險因素的詞在文件中出現的頻率越高,這個詞就越重要。由于每一份事故調查報告的長度不同,一些不重要的詞可能會在較長的文件中重復出現。為了減少高頻的影響,TF-IDF在TF后乘以IDF,如式(2)所示。
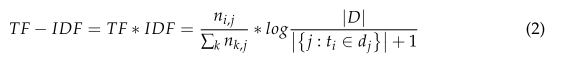
其中nij為單詞ti在文檔dj中出現的次數;
∑k nk,j表示文檔dj中所有單詞出現次數之和;
**|D|**表示整個語料庫中的文檔總數;
{j: ti∈dj}表示包含單詞ti的文檔數量。
但是TF- idf忽略了文檔長度,其中單詞ti的臨界度得分仍然與詞頻TF線性相關。例如,如果一個1000字的文檔有100字的a,而另一個5000字的文檔有100字的a,那么很明顯,單詞a在這兩個文檔中的重要性是不同的。單詞在長文檔中的頻率通常更高,這最終導致TF-IDF臨界性評分仍然過于有利于長文檔。為了改善這一問題,研究者提出了BM25模型[33],如式(3)所示。
2.3.2 改進的BM25——BM25W
BM25
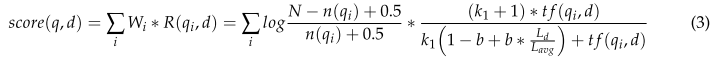
其中N為語料庫中的文檔總數; **n(qi)**是包含“qi”字的文獻數量;
tf(qi, d)是文檔d中qi出現的頻率; Ld是文檔的長度;
Lavg是整個語料庫中所有文檔的平均長度; k1和b是可自由調節的超參數;
一般情況下k1∈[1.2,2.0],b = 0.75。R(qi, d)對t f(qi, d)的函數是一個飽和遞增函數,使得文檔詞頻的增長與關鍵字得分的增長呈非線性相關。因此,本研究提出了一些基于BM25模型的改進,并用于關鍵詞的提取。
BM25W
TF-IDF和BM25都考慮了單詞和文檔之間的關系,但沒有考慮單詞本身的語義對關鍵字提取的影響。對于表示安全風險因素的詞語,一方面,我們一般認為詞語越長,表示的信息越清晰、越專業,如device、safety device、safety interlock device[34,35]。特別是,我們希望能夠提取出能夠更清楚地表明安全風險因素的詞語。另一方面,之前的領域詞典的專有詞都是由領域專家從文檔中仔細檢查和選擇的,因此它們的語義表示更加清晰和專門化。因此,本文根據單詞本身的語義對BM25模型進行加權。
首先,根據單詞長度計算權重的公式如式(4)所示。
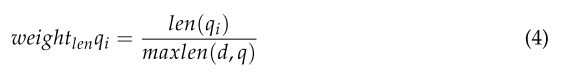
其中len(qi)表示單詞qi的長度,maxlen(d, q)表示文檔d中最長單詞的長度。
其次,基于領域字典的權值計算公式如式(5)所示
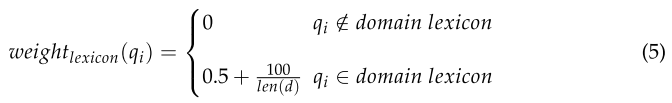
式(5)表示如果單詞qi若不在領域詞典中,則權重為0;否則,基礎值設為0.5,再將文檔d分詞結果中每100個單詞與單詞個數的比值相加,將這兩個權重的總和作為基于單詞語義的權重,計算BM25模型的加權得分,如式(6)所示。
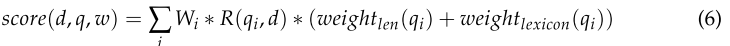
與式(3)對比:
在本研究中,這個新的模型稱為BM25W,用于關鍵字提取。
2.3.3 關鍵詞的產生(相關系數)
由于所提取的關鍵詞只是單一的名詞或動詞,不能完全反映事故發生的原因,如專用設備、有毒有害氣體、監督管理等。這是因為這些詞可能有一些語義重復,或者可能沒有具體反映一個隱藏的問題[36]。這些關鍵字需要標準化。**本研究首先將所有特征詞通過計算機向量化為word-document matrix (TDM),如式(7)所示。**TDM是一個m x n的二維稀疏矩陣。
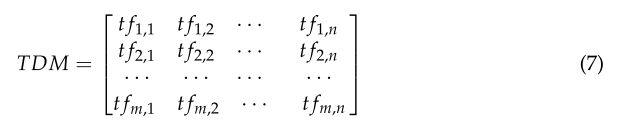
每一行表示一個文檔dj, j∈m;每列表示一個特征詞ti, i ∈ n;
t fm,n表示特征詞tn在文件dm中的出現次數
通過這種方式,可以將高度非結構化的事件報告轉換為結構化的數值類型數據。然后利用TDM計算特征項之間的相關系數,如式(8)所示。
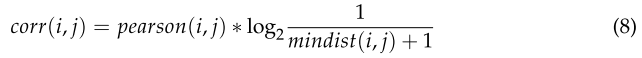
pearson(i, j):特征詞i、j的皮爾遜相關系數;
mindist(i, j) :指代在所有文檔中兩個詞之間的最短距離;
如果兩個特性術語同時出現在文檔中,但位置相距很遠,那么很明顯,在表示隱藏的問題時,這兩個特性術語并不相關。TDM只表示特征詞數量在整個語料庫空間中的分布,而不反映特征詞在文檔中的位置關系。因此,本研究采用log2 {1/ mindist(i,j)+1} 作為兩個特征項的距離權重,與Pearson相關系數相乘作為最終的相關系數。
2.4 關聯規則分析
關聯規則挖掘首先是由Agrawal在超市購物籃分析中提出的,它是一種研究數據庫中項目集之間潛在相互關系的方法。它是目前數據挖掘領域最活躍的研究方向之一。關聯規則可以從大量的事故數據中發現導致事故發生的不確定因素的關聯特征,從而識別出因素之間的因果關系,幫助管理者進行決策。
因此,本研究在通過文本挖掘識別安全風險因素的基礎上,采用關聯規則挖掘的方法,獲得安全風險因素之間的強關聯規則,為后續的化學品安全風險因素分析和貝葉斯網絡結構的構建奠定了基礎。關聯規則挖掘定義如下::
設:I = {i1, i2,…,in}是一個由n個稱為items的二進制屬性組成的集合,D = {t1, t2,…, tn}是一組稱為數據庫的事務。D中的每個事務都有一個唯一的事務ID,和包含I中項的一個子集。一條規則被描述為X?Y(由x可推得y),其中X, Y?I。
每條規則都由兩個不同的項集組成,也稱為項集X和Y,其中X稱為先行項或左手邊項(left-hand-side;LHS), Y稱為后件項或右手邊項(right-hand-side;RHS)。**為了從所有可能的集合規則中選擇感興趣的規則,使用了對不同意義和興趣度量的約束。**最著名的約束是支持度和置信度的最小閾值。
-
設X是一個項目集,X?Y是一個關聯規則,T是一個給定數據庫的事務集。
-
支持度表明項目集在數據集中出現的頻率,隨著數據集的增長,項目集的先決條件變得更有限制性,而不是更具包容性。
-
X對T的支持定義為事務t在包含項目集X的數據集中所占的比例,計算方法如下:
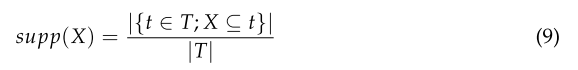
-
置信度表示該規則被發現為正確的頻率,表示為:
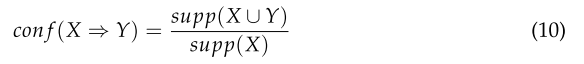
-
X?Y對一組交易T的置信值是包含X的交易中同時包含Y的交易所占的比例。如果conf (X?Y)的值等于1,則X?Y的規則是不可避免的。
關聯規則需要同時滿足最小支持度和最小置信度。在大多數情況下,關聯規則的生成分為兩個獨立的步驟:
第一步應用最小支持閾值來查找數據庫中的所有頻繁項目集,
第二步應用最小置信約束來獲取這些頻繁項目集以形成規則。
-
安全風險因子最初并沒有出現在文獻中,而是通過標準化關鍵詞得到的。因此,當一對關鍵字和非關鍵特征項同時出現在一個文檔中,且距離不大于10時,我們認為這兩個詞歸一化的安全風險因子在本文檔中也存在。這樣就可以得到關聯規則挖掘所需的事務集,即上述事務數據集。
傳統的關聯規則挖掘算法主要有Apriori算法和FP-growth算法。
Apriori算法對事務數據庫進行多次掃描,每次使用候選頻繁集生成頻繁集;
而FP-growth算法采用樹形結構直接獲取頻繁集,不生成候選頻繁集,大大減少了事務數據庫的掃描次數,提高了算法的效率。
因此,FP-growth只能用于挖掘單維布爾關聯規則。但由于安全風險因素之間的因果關系錯綜復雜,且多集關聯規則數量眾多,因此本研究采用Apriori算法進行關聯規則挖掘。
2.5 貝葉斯網絡分析
貝葉斯網絡又稱置信網絡,是貝葉斯的延伸,是目前不確定知識表示和推理領域最有效的理論模型之一。自1988年Pearl提出貝葉斯網絡以來,貝葉斯網絡已成為近年來的研究熱點。貝葉斯網絡是由表示變量的節點和連接這些節點的有向邊組成的有向無環圖(DAG),如圖6所示。
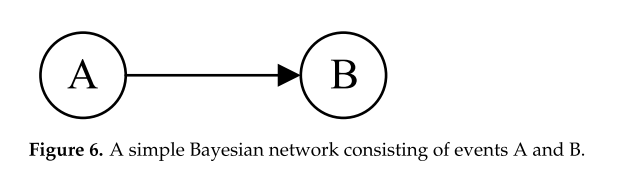
當事件A的發生影響到事件B的發生時,有如下關系(條件概率):

式(11)稱為貝葉斯公式,其中P(A)和P(B)分別為事件A和事件B的先驗概率;P(A|B)為后驗概率(條件概率),即事件A發生時事件B發生的概率;P(B|A)表示似然概率,表示假設結果發生時,對原因發生的可能性的描述。對于任意隨機變量,其聯合概率可由各自的局部條件概率分布相乘得到,如式(12)所示。
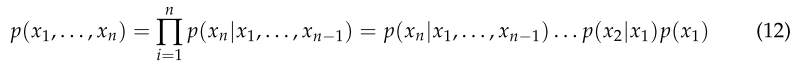
本文構建和分析化工事故因果關系網絡的目的是通過定量分析明確化工安全生產系統的關鍵風險因素,從而提出更有針對性的事故預防策略。因此,本研究基于關聯規則挖掘的結果構建了貝葉斯網絡結構,并將事務集轉化為One-Hot Encoding,用于貝葉斯網絡的參數學習。然后對安全風險因素進行敏感性、關鍵原因路徑和頻次統計分析。
本研究采用GeNIe4.0軟件進行貝葉斯網絡分析。GeNIe Modeler是一個用于構建圖形決策理論模型的開發環境。由于它們的通用性和可靠性,GeNIe和SMILE已經非常受歡迎,并成為學術界的事實上的標準,同時也受到許多政府、軍事和商業用戶的歡迎,而且GeNIe已經在許多教學、研究和商業環境[45]中進行了廣泛的測試。







)







)


)
