我們的JCG合作伙伴之一Tomasz Nurkiewicz最近寫了一篇非常不錯的文章, 介紹如何使用異步處理來提高服務器的吞吐量 。 讓我們找出他是如何做到的。
(注意:對原始帖子進行了少量編輯以提高可讀性)
Java servlet容器并不特別適合處理大量并發用戶,這不是秘密。 通用的每請求線程數模型有效地將并發連接數限制為JVM可以處理的并發運行線程數。 而且,由于每個新線程都會顯著增加內存占用量和CPU利用率(上下文切換),因此處理100-200個以上的并發連接在Java中似乎是一個荒謬的想法。 至少在Servlet 3.0之前的時代。
在本文中,我們將編寫一個具有速度限制的可伸縮且健壯的文件服務器。 在第二個版本中,利用Servlet 3.0異步處理功能,我們將能夠使用更少的線程來處理10倍大的負載。 無需額外的硬件,只需做出一些明智的設計決策即可。
令牌桶算法
建立文件服務器,我們必須自覺地管理我們的資源,尤其是網絡帶寬。 我們不希望單個客戶端消耗全部流量,我們甚至可能希望根據用戶,一天中的時間等在運行時動態限制下載限制-當然,所有操作都在高負載下發生。 開發人員喜歡重新發明輪子,但是我們的所有要求已經通過簡單的令牌桶算法解決了 。
Wikipedia中的解釋非常好,但是由于我們會根據需要對算法進行一些調整,因此這里的描述更加簡單。 首先有一個水桶。 在這個桶里有統一的令牌。 每個令牌價值20 kiB(我將使用我們應用程序中的實際值)的原始數據。 客戶端每次請求文件時,服務器都會嘗試從存儲桶中獲取一個令牌。 如果成功,他將20 kiB發送給客戶端。 重復最后兩個句子。 如果服務器由于存儲桶已經為空而無法獲取令牌,該怎么辦? 他在等。
那么代幣從哪里來呢? 后臺進程不時充滿水桶。 現在變得清楚了。 如果此后臺進程每100毫秒(每秒10次)添加100個新令牌,每個令牌價值20 kiB,則服務器最多可以發送20 MiB / s(100乘以20 kiB乘以10),在所有客戶端之間共享。 當然,如果存儲桶已滿(1000個令牌),則將忽略新令牌。 這非常好用–如果存儲桶為空,則客戶正在等待下一個存儲桶填充周期; 通過控制存儲桶容量,我們可以限制總帶寬。
言歸正傳,我們對令牌桶的簡化實現是從一個接口開始的(整個源代碼可在GitHub的global-bucket分支中找到):
public interface TokenBucket {int TOKEN_PERMIT_SIZE = 1024 * 20;void takeBlocking() throws InterruptedException;void takeBlocking(int howMany) throws InterruptedException;boolean tryTake();boolean tryTake(int howMany);}takeBlocking()方法同步等待令牌可用,而tryTake()僅在令牌可用時接受令牌,如果采用則立即返回true,否則返回false。 幸運的是,術語存儲桶只是一個抽象:因為令牌是無法區分的,我們需要實現的所有操作都是存儲桶,它是一個整數計數器。 但是,由于存儲桶本質上是多線程的,并且涉及一些等待,因此我們需要更復雜的機制。 信號量似乎幾乎是理想的:
@Service
@ManagedResource
public class GlobalTokenBucket extends TokenBucketSupport {private final Semaphore bucketSize = new Semaphore(0, false);private volatile int bucketCapacity = 1000;public static final int BUCKET_FILLS_PER_SECOND = 10;@Overridepublic void takeBlocking(int howMany) throws InterruptedException {bucketSize.acquire(howMany);}@Overridepublic boolean tryTake(int howMany) {return bucketSize.tryAcquire(howMany);}}信號量完全符合我們的要求。 bucketSize表示存儲桶中當前的令牌數量。 另一方面,bucketCapacity限制了存儲桶的最大大小。 它是易變的,因為可以通過JMX對其進行修改(可見性):
@ManagedAttribute
public int getBucketCapacity() {return bucketCapacity;
}@ManagedAttribute
public void setBucketCapacity(int bucketCapacity) {isTrue(bucketCapacity >= 0);this.bucketCapacity = bucketCapacity;
}如您所見,我正在使用Spring及其對JMX的支持。 Spring框架在此應用程序中不是絕對必要的,但是它帶來了一些不錯的功能。 例如,實現一個定期填充存儲桶的后臺進程如下所示:
@Scheduled(fixedRate = 1000 / BUCKET_FILLS_PER_SECOND)
public void fillBucket() {final int releaseCount = min(bucketCapacity / BUCKET_FILLS_PER_SECOND, bucketCapacity - bucketSize.availablePermits());bucketSize.release(releaseCount);
}這段代碼包含主要的多線程錯誤,出于本文的目的,我們可以將其忽略。 假設將水桶裝滿最大值–它會一直工作嗎?
此外,這是使@Scheduled批注起作用所需的XML代碼段(applicationContext.xml):
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"xmlns:context="http://www.springframework.org/schema/context"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:task="http://www.springframework.org/schema/task"xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-3.0.xsdhttp://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsdhttp://www.springframework.org/schema/task http://www.springframework.org/schema/task/spring-task-3.0.xsd"><context:component-scan base-package="com.blogspot.nurkiewicz.download" /><context:mbean-export/><task:annotation-driven scheduler="bucketFillWorker"/><task:scheduler id="bucketFillWorker" pool-size="1"/></beans>具有令牌桶抽象和非常基本的實現,我們可以開發實際的servlet返回文件。 我總是返回大小幾乎為200 kiB的相同固定文件):
@WebServlet(urlPatterns = "/*", name="downloadServletHandler")
public class DownloadServlet extends HttpRequestHandlerServlet {}@Service
public class DownloadServletHandler implements HttpRequestHandler {private static final Logger log = LoggerFactory.getLogger(DownloadServletHandler.class);@Resourceprivate TokenBucket tokenBucket;@Overridepublic void handleRequest(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {final File file = new File("/home/dev/tmp/ehcache-1.6.2.jar");final BufferedInputStream input = new BufferedInputStream(new FileInputStream(file));try {response.setContentLength((int) file.length());sendFile(request, response, input);} catch (InterruptedException e) {log.error("Download interrupted", e);} finally {input.close();}}private void sendFile(HttpServletRequest request, HttpServletResponse response, BufferedInputStream input) throws IOException, InterruptedException {byte[] buffer = new byte[TokenBucket.TOKEN_PERMIT_SIZE];final ServletOutputStream outputStream = response.getOutputStream();for (int count = input.read(buffer); count > 0; count = input.read(buffer)) {tokenBucket.takeBlocking();outputStream.write(buffer, 0, count);}}
}這里使用了HttpRequestHandlerServlet 。 盡可能簡單:讀取20 kiB的文件,從存儲桶中獲取令牌(如果不可用,則等待),將塊發送到客戶端,重復直到文件結束。
信不信由你,這實際上有效! 無論有多少個(或幾個)客戶端同時訪問該servlet,總的傳出網絡帶寬都不會超過20 MiB! 該算法有效,希望您對如何使用它有一些基本的了解。 但是,讓我們面對現實吧-全局限制太不靈活,有點of腳-單個客戶端實際上可以消耗您的整個帶寬。
那么,如果我們為每個客戶有一個單獨的存儲桶怎么辦? 而不是一個信號量–地圖? 每個客戶端都有單獨的獨立帶寬限制,因此沒有饑餓的風險。 但是還有更多:
一些客戶可能有更大的特權,甚至沒有更大的限制,甚至根本沒有限制,
有些可能被列入黑名單,從而導致連接被拒絕或吞吐量非常低
禁止IP,要求身份驗證,Cookie /用戶代理驗證等。 我們可能會嘗試關聯來自同一客戶端的并發請求,并對所有請求使用相同的存儲桶,以免通過打開多個連接而作弊。 我們也可能拒絕后續連接 以及更多…
我們的存儲桶接口不斷增長,允許實現利用新的可能性(請參閱分支per-request-synch ):
public interface TokenBucket {void takeBlocking(ServletRequest req) throws InterruptedException;void takeBlocking(ServletRequest req, int howMany) throws InterruptedException;boolean tryTake(ServletRequest req);boolean tryTake(ServletRequest req, int howMany);void completed(ServletRequest req);
}public class PerRequestTokenBucket extends TokenBucketSupport {private final ConcurrentMap<Long, Semaphore> bucketSizeByRequestNo = new ConcurrentHashMap<Long, Semaphore>();@Overridepublic void takeBlocking(ServletRequest req, int howMany) throws InterruptedException {getCount(req).acquire(howMany);}@Overridepublic boolean tryTake(ServletRequest req, int howMany) {return getCount(req).tryAcquire(howMany);}@Overridepublic void completed(ServletRequest req) {bucketSizeByRequestNo.remove(getRequestNo(req));}private Semaphore getCount(ServletRequest req) {final Semaphore semaphore = bucketSizeByRequestNo.get(getRequestNo(req));if (semaphore == null) {final Semaphore newSemaphore = new Semaphore(0, false);bucketSizeByRequestNo.putIfAbsent(getRequestNo(req), newSemaphore);return newSemaphore;} else {return semaphore;}}private Long getRequestNo(ServletRequest req) {final Long reqNo = (Long) req.getAttribute(REQUEST_NO);if (reqNo == null) {throw new IllegalAccessError("Request # not found in: " + req);}return reqNo;}}實現非常相似( 此處為全類),只不過單個信號量已被map取代。 由于各種原因,我沒有將請求對象本身用作映射鍵,而是在接收新連接時手動分配的唯一請求號。 調用completed()非常重要,否則映射將持續增長,從而導致內存泄漏。 總而言之,令牌桶的實現沒有太大變化,下載servlet幾乎相同(除了將請求傳遞給令牌桶)。 我們現在準備進行壓力測試!
吞吐量測試
為了進行測試,我們將JMeter與這套出色的插件結合使用 。 在20分鐘的測試過程中,我們對服務器進行預熱,每6秒啟動一個新線程(并發連接),以在10分鐘后達到100個線程。 在接下來的十分鐘內,我們將保持100個并發連接,以查看服務器的工作穩定性。 以下是一段時間內的活動線程:

重要說明 :在Tomcat(已測試7.0.10)中,我人為地將HTTP工作線程的數量減少到10 。 這與實際配置相差甚遠,但是我想強調一些與服務器功能相比在高負載下發生的現象。 使用默認池大小,我將需要幾臺運行分布式JMeter會話的客戶端計算機以生成足夠的流量。 如果您在云中有一個服務器場或幾個服務器(與我3歲的筆記本電腦相對),我將很高興在更現實的環境中看到結果。
記住Tomcat中有多少個HTTP工作線程可用,隨著時間的推移響應時間就遠遠不能令人滿意:
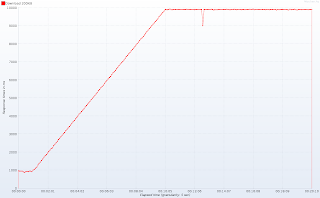
請注意測試開始時的平穩期:大約一分鐘后(提示:當并發連接數超過10時),響應時間激增,在10分鐘(并發連接數達到100)后穩定在10秒左右。 再次:100個工作線程和1000個并發連接會發生相同的行為–這只是規模問題。 響應延遲圖(發送請求和接收響應的第一行之間的時間)消除了任何疑問:

在神奇的10個線程數量以下,我們的應用程序幾乎立即響應。 這對于客戶端來說確實很重要,因為僅接收標頭(尤其是Content-Type和Content-Length)可以使標頭更準確地告知用戶正在發生的事情。 那么Tomcat等待響應的原因是什么? 真的沒有魔術。 我們只有10個線程,每個連接都需要一個線程,因此Tomcat(和其他任何其他Servlet 3.0之前的容器)處理10個客戶端,而其余90個正在排隊。 當十個幸運者之一完成時,就從隊列中獲得一個連接。 這解釋了平均9秒鐘的延遲,而Servlet僅需要1秒鐘即可處理請求(200 kiB,限制為20 kiB / s)。 如果您仍然不確定,Tomcat提供了不錯的JMX指示器,可顯示占用了多少線程以及有多少請求排隊:

使用傳統的servlet,我們無能為力。 吞吐量太可怕了,但是增加線程總數是不可行的(想想:從100增加到1000)。 但是您實際上并不需要探查器來發現線程并不是這里的真正瓶頸。 仔細查看DownloadServletHandler,您認為大部分時間都花在哪里? 正在讀取文件? 將數據發送回客戶端? 不,servlet等待……然后等待更多。 非有效地掛在信號量上–幸運的是,CPU并未受到損害,但是如果使用繁忙的等待時間來實現呢? 幸運的是,Tomcat 7終于支持了……
Servlet 3.0異步處理
我們已經接近將服務器容量增加一個數量級,但是需要進行一些不重要的更改(請參閱master分支)。 首先,需要將下載servlet標記為異步(好的,這仍然很簡單):
@WebServlet(urlPatterns = "/*", name="downloadServletHandler", asyncSupported = true)
public class DownloadServlet extends HttpRequestHandlerServlet {}主要變化發生在下載處理程序中。 我們不是將整個文件發送到涉及大量等待(takeBlocking())的循環中,而是將循環分為多個單獨的迭代,每個迭代都包裝在Callable中。 現在,我們將利用一個小的線程池,該線程池將由所有等待的連接共享。 池中的每個任務非常簡單:它不等待令牌,而是以非阻塞方式(tryTake())進行請求。 如果令牌可用,則將文件的一部分發送給客戶端(sendChunkWorthOneToken())。 如果令牌不可用(存儲桶為空),則不會發生任何事情。 無論令牌是否可用,任務都會將自己重新提交到隊列中以進行進一步處理(這本質上是非常花哨的多線程循環)。 因為只有一個池,所以該任務降落在隊列的末尾,允許服務其他連接。
@Service
public class DownloadServletHandler implements HttpRequestHandler {@Resourceprivate TokenBucket tokenBucket;@Resourceprivate ThreadPoolTaskExecutor downloadWorkersPool;@Overridepublic void handleRequest(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {final File file = new File("/home/dev/tmp/ehcache-1.6.2.jar");response.setContentLength((int) file.length());final BufferedInputStream input = new BufferedInputStream(new FileInputStream(file));final AsyncContext asyncContext = request.startAsync(request, response);downloadWorkersPool.submit(new DownloadChunkTask(asyncContext, input));}private class DownloadChunkTask implements Callable<Void> {private final BufferedInputStream fileInputStream;private final byte[] buffer = new byte[TokenBucket.TOKEN_PERMIT_SIZE];private final AsyncContext ctx;public DownloadChunkTask(AsyncContext ctx, BufferedInputStream fileInputStream) throws IOException {this.ctx = ctx;this.fileInputStream = fileInputStream;}@Overridepublic Void call() throws Exception {try {if (tokenBucket.tryTake(ctx.getRequest())) {sendChunkWorthOneToken();} elsedownloadWorkersPool.submit(this);} catch (Exception e) {log.error("", e);done();}return null;}private void sendChunkWorthOneToken() throws IOException {final int bytesCount = fileInputStream.read(buffer);ctx.getResponse().getOutputStream().write(buffer, 0, bytesCount);if (bytesCount < buffer.length)done();elsedownloadWorkersPool.submit(this);}private void done() throws IOException {fileInputStream.close();tokenBucket.completed(ctx.getRequest());ctx.complete();}}}我將保留Servlet 3.0 API的詳細信息,整個Internet上有許多不太復雜的示例。 只需記住調用startAsync()并使用返回的AsyncContext而不是簡單的請求和響應即可。
BTW使用Spring創建線程池非常簡單(與Executors和ExecutorService相比,我們得到了不錯的線程名稱):
沒錯,一個線程足以服務一百個并發客戶端。 自己看看(HTTP工作線程的數量仍然是10,是的,規模以毫秒為單位)。
隨著時間的響應時間

隨著時間的響應延遲
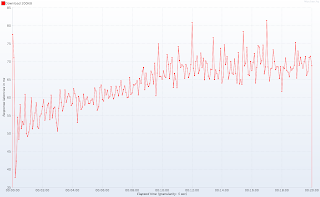
如您所見,與幾乎沒有負載的系統相比,一百個客戶端同時下載文件時的響應時間僅高5%。 同樣,響應延遲不會因增加負載而特別受到損害。 由于硬件資源有限,我無法進一步推動服務器運行,但是我有理由相信這個簡單的應用程序可以處理甚至兩倍以上的連接:整個測試過程中,HTTP線程和下載工作線程均未得到充分利用。 這也意味著我們甚至不使用所有線程就將服務器容量增加了10倍!
希望您喜歡這篇文章。 當然,并不是每個用例都可以如此輕松地擴展,但是下次您會注意到Servlet主要在等待–不要浪費HTTP線程,而應考慮Servlet 3.0異步處理。 并測試,測量和比較! 完整的應用程序源代碼可用(請查看不同的分支),包括JMeter測試計劃。
改進領域
還有幾個地方需要關注和改進。 如果愿意,請毫不猶豫地進行分叉,修改和測試:
- 在進行概要分析時,我發現在80%以上的執行中,DownloadChunkTask不會獲取令牌,而只會重新計劃自身。 這非常浪費CPU時間,可以很輕松地解決(如何?)
- 考慮在工作線程而不是HTTP線程中打開文件并發送內容長度(在啟動異步上下文之前)
- 如何在每個請求的帶寬限制之上實現全局限制? 您至少有兩個選擇:限制下載工作程序池隊列的大小并拒絕執行,或者用重新實現的GlobalTokenBucket(裝飾器模式)包裝PerRequestTokenBucket
- TokenBucket.tryTake()方法確實違反了命令查詢分離原則。 您能否建議遵循它的外觀? 為什么這么難?
- 我知道我的測試會不斷讀取相同的小文件,因此對I / O性能的影響很小。 但是在現實生活中,某些緩存層肯定會應用于磁盤存儲之上。 因此區別并不大(現在應用程序使用的內存量非常小,很多地方用于緩存)。
得到教訓
- 回送接口并非無限快。 實際上,在我的計算機上,本地主機無法處理80 MiB / s以上的速度。
- 我不使用普通請求對象作為bucketSizeByRequestNo中的鍵。 首先,對此接口的equals()和hashCode()沒有保證。 更重要的是–閱讀下一點...
- 使用Servlet 3.0處理請求時,必須顯式調用completed()刷新和關閉連接。 顯然,在調用此方法之后,請求和響應對象是無用的。 Tomcat(在請求對象(池)和其中一些內容用于后續連接)中重用了(這并不明顯(我知道為什么很難))。 這意味著以下代碼不正確且危險,可能導致訪問/破壞其他請求的屬性,甚至會話(?!?)
ctx.complete();
ctx.getRequest().getAttribute("SOME_KEY");而已。 我們的JCG合作伙伴之一Tomasz Nurkiewicz 使用Servlet 3.0異步處理提高服務器吞吐量的非常不錯的教程。 別忘了分享!
相關文章:
- 帶有Spring和Maven教程的JAX–WS
- GWT EJB3 Maven JBoss 5.1集成教程
- Tomcat 7上具有RESTeasy JAX-RS的RESTful Web服務-Eclipse和Maven項目
- 正確記錄應用程序的10個技巧
- 每個程序員都應該知道的事情
翻譯自: https://www.javacodegeeks.com/2011/03/servlet-30-async-processing-for-tenfold.html


)




)

)

----調整屏幕的寬高比)


)
用戶管理命令)


)
