1 為什么要使用垃圾回收機制?
“垃圾收集”暗示程序不再需要的對象就是垃圾,可以被丟棄。更精確,更新的說法是“內存回收”。
1.1 新對象的使用
當一個對象不再被程序所引用時,他所使用的堆空間可以被回收,以便于被后續的新的對象使用。垃圾回收必須能判斷哪些對象是不再被引用的,并且能夠把他們所占據的堆空間釋放出來,在釋放不再被引用的對象的過程中,垃圾收集器運行將要被釋放的對象的終結方法(finalizer)
1.2 處理堆碎片
除了釋放不再被引用的對象之外,垃圾收集器還要處理堆碎片。堆碎片實在正常程序運行過程中產生的。新的對象分配了空間,不再被引用的對象被釋放,所以堆碎塊的空間位置介于活動的對象之間。請求分配新對象時可能不得不增大堆空間的大小,雖然可以使用的總空間是足夠的。因為,堆中沒有連續的空閑放得下新的對象。在一個虛擬機內存系統中,增長的堆所需要的額外分頁(或交換)空間會影響運行程序的性能。
1.3 使用垃圾收集的有點和缺點
優點:把用戶從釋放占用內存的重擔中解放出來
? ? ? ? 在一定程序上幫助程序保持完整性(是java安全策略一個重要的組成部分)
缺點:加大了程序的負擔,可能會影響性能。虛擬機在追蹤哪些對象被正在執行的程序所引用,并且動態的終結不再被使用的對象。和明確釋放不再被使用的內存比起來,這個活動會需要更多的CPU時間。
2 垃圾收集算法
? ? ? 任何垃圾收集算法都必須完成倆件事情,首先,他必須檢測出垃圾對象。其次,他必須回收垃圾對象所使用的堆空間并且還給程序。
? ? ? 垃圾檢測通常通過建立一個根對象的集合并且檢查從這些根對象開始的可觸及性來實現。(可觸及性:如果正在執行的程序可以訪問到的根對象和某個對象之間存在引用路徑)。對于程序來說,根對象總是可以被訪問的。從這些根對象開始,任何可以被觸及的對象都被認為是“活動”的對象。無法觸及的對象被認為是垃圾,因為他們不再影響程序的未來執行。
區分活動對象和垃圾的基本方法是引用計數和跟蹤。
2.1 引用計數收集器
在這種方法中,堆中每一個對象都有一個引用計數。當一個對象唄創建了,并且指向該對象的引用被分配了一個變量,這個對象的引用計數被置為1。當其他任何變量被賦值為對這個對象的引用時,計數加1.當一個對象的引用超過了生存期或者被設置一個新的值時,對象的引用計數減1。任何引用計數為0的對象都可以當成垃圾進行回收。當一個對象被垃圾收集的時候,他引用的任何對象計數值減1。這種方法中,一個對像被垃圾回收之后可能會導致后續其他對象的垃圾收集行動。
優缺點:可以很快的執行,交織在程序的運行之中。這個特性對于程序不能被長時間打斷的實時環境很有利。壞處就是,引用計數無法檢測出循環(倆個對象或者更多對象的相互引用)。目前該技術已經不為人接受了
2.2 跟蹤收集器
跟蹤收集器追蹤從根節點開始的對象引用圖。在追蹤過程中遇到的對象以某種方式打上標記。總的來說,要么在對象本身設置標記,要么用一個隊里的位圖來設置標記。當追蹤結束時,未被標記的對象就知道是無法觸及的,從而被收集。
基本的追蹤算法被稱作“標記并清除”。在標記階段,垃圾收集器遍歷引用樹,標記每一個遇到的對象。在清除階段,未被標記的對象被釋放,使用的內存被返回到正在執行的程序。清除步驟 必須包括對象的終結。
2.3 壓縮收集器
這種方法用來簡化消除堆碎塊的工作,但是每一次對象訪問都會帶來性能的損失。
標記并清除收集器通常使用的倆種策略是壓縮和拷貝。這倆種方法都是快速的移動對象來減少碎塊。壓縮收集器吧活動的對象越過空間滑動到堆的一端,在這個過程中,堆的另一端就會出現一個大的連續空閑區,所有被移動的對象的引用會被更新,指向新的位置。
2.4 拷貝收集器
拷貝收集器吧所有的活動對象移動到一個新的區域。再考唄過程中,他們緊挨著布置,所以可以消除原本他們在就區域的空隙。原有的區域被認為都是空閑區。這種方法的好處是對象可以在從跟對象開始的遍歷過程中隨著發現而被拷貝,不再有標記和清除的區分。
一般的拷貝收集器算法被稱為“停止并拷貝”。
2.5 按代收集的收集器
在非常早的時候,我們看到過許多“分配慢”的意見 —— 因為就像早期 JVM 中的一切一樣,它確實慢 —— 而性能顧問提供了許多避免分配的技巧,例如對象池。(公共服務聲明:除了對最重量的對象之外,對象池現在對于所有對象都是嚴重的性能損失,而且要在不造成并發瓶頸的情況下使用對象池也很需要技巧。)但是,從 JDK 1.0 開始已經發生了許多變化;JDK 1.2 中引入的分代收集器(generational collector)支持簡單得多的分配方式,可以極大地提高性能。
特征:
按代收集的收集器通過把對象按照壽命來分組解決這個效率低下的問題,更多的收集那些短暫出現的年幼對象,而非壽命較長的對象。在這種方法里,堆被劃分為兩個或者更多的子堆,每一個子堆為一“代”對象服務。最年幼的那一代進行最頻繁的垃圾收集。因為大多數對象都是短促出現的,只有很小部分的年幼對象可以在它們經歷第一次收集后存活。如果一個最年幼的對象經歷了好幾次垃圾收集后仍然存活,那么這個對象就成長為壽命更高的一代;它被轉移到另外一個子堆中去。年齡更高的每一代的收集都沒有年輕的那一些來的頻繁。每當對象在它所屬的年齡層(代)中變得成熟(逃過了多次垃圾收集)之后,它們就被轉移到更高的年齡層中去。
2.6 自適應收集器
自適應收集器利用如下事實:在某種情況下某些垃圾收集算法工作的更好,而另外一些收集算法在另外的情況下工作更好。自適應算法監視堆中的情形,并且對應的調整為合適的垃圾收集技術。核心在于不同的情況下,使用這些算法最擅長的場景使用。
3 火車算法
垃圾收集算法和明確釋放對象比起來有一個潛在的缺點,即垃圾收集算法中程序員對安排CPU時間進行內存回收缺乏控制。
火車算法是分代收集器所用的算法,目的是在成熟對象空間中提供限定時間的漸進收集。那么為什么要使用漸進收集呢?因為大范圍的垃圾回收會占用大量的資源和時間,可能會導致暫停和無法滿足系統實時性的要求,因此使用漸進收集。
車廂,火車和火車站
火車算法把成熟對象空間劃分為固定長度的內存塊,算法每次在一個塊中單獨執行。每個塊屬于一個集合。
塊被叫車廂,集合被叫做火車,成熟對象空間是火車站。
火車被排序,塊被附加到火車的尾部
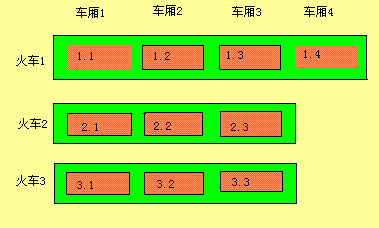
這種方式表示出了成熟對象空間內所有塊的總體排序。
車廂收集
火車算法執行的時候,要么收集最小數字火車中的最小數字車廂,要么收集整個最小數字火車。
如果整個火車都是垃圾對象,那么整個火車都被收集。否則,收集最小數字車廂。
收集最小數字車廂時,如果發現該車廂內部有被其他車廂引用對象則會轉移到引用的車廂,如此循環,最后收集整個車廂。
收集最小數字火車時,如果發現該火車內有被其他火車引用對象則會轉移到引用的火車,如此循環,最后收集整個火車。
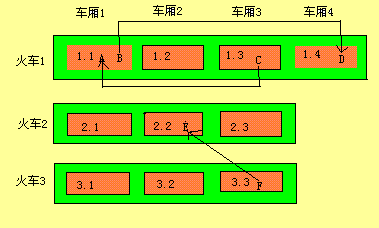
?

?
記憶集合和流行對象
為了促進收集過程,火車算法使用了記憶集合。一個記憶集合是一個數據結構,包含所有對一節車廂或者一列火車的外部引用。一個空的記憶集合表明車廂或者火車中的對象都不再被車廂或者火車外的任何變量引用,可以被垃圾收集。
?


)
















