Linux 性能分析之iostat命令詳解
iostat命令是IO性能分析的常用工具,其是input/output statistics的縮寫。本文將著重于下面幾個方面介紹iostat命令:
- iostat的安裝
- iostat命令行選項說明
- iostat輸出內容分析
- 如何確定磁盤IO的瓶頸
- iostat實際案例
命令的安裝
iostat位于sysstat包中,使用yum可以對其進行安裝。
yum install sysstat -y
iostat命令行選項說明
iostat命令的基本格式如下所示:
iostat <options> <device name>
- -c: 顯示CPU使用情況
- -d: 顯示磁盤使用情況
- –dec={ 0 | 1 | 2 }: 指定要使用的小數位數,默認為 2
- -g GROUP_NAME { DEVICE […] | ALL } 顯示一組設備的統計信息
- -H 此選項必須與選項 -g 一起使用,指示只顯示組的全局統計信息,而不顯示組中單個設備的統計信息
- -h 以可讀格式打印大小
- -j { ID | LABEL | PATH | UUID | … } [ DEVICE […] | ALL ] 顯示永久設備名。選項 ID、LABEL 等用于指定持久名稱的類型
- -k 以 KB 為單位顯示
- -m 以 MB 為單位顯示
- -N 顯示磁盤陣列(LVM) 信息
- -n 顯示NFS 使用情況
- -p [ { DEVICE [,…] | ALL } ] 顯示磁盤和分區的情況
- -t 打印時間戳。時間戳格式可能取決于 S_TIME_FORMAT 環境變量
- -V 顯示版本信息并退出
- -x 顯示詳細信息(顯示一些擴展列的數據)
- -y 如果在給定的時間間隔內顯示多個記錄,則忽略自系統啟動以來的第一個統計信息
- -z 省略在采樣期間沒有活動的任何設備的輸出
常見的命令行的使用如下所示:
iostat -d -k 1 10 #查看TPS和吞吐量信息(磁盤讀寫速度單位為KB),每1s收集1次數據,共收集10次
iostat -d -m 2 #查看TPS和吞吐量信息(磁盤讀寫速度單位為MB),每2s收集1次數據
iostat -d -x -k 1 10 #查看設備使用率(%util)、響應時間(await)等詳細數據, 每1s收集1次數據,總共收集10次
iostat -c 1 10 #查看cpu狀態,每1s收集1次數據,總共收集10次
iostat輸出內容分析
在linux命令行中輸入iostat,通常將會出現下面的輸出:
[root@localhost ~]# iostat
Linux 5.14.0-284.11.1.el9_2.x86_64 (localhost.localdomain) 08/07/2023 _x86_64_ (4 CPU)avg-cpu: %user %nice %system %iowait %steal %idle0.31 0.01 0.44 0.02 0.00 99.22Device tps kB_read/s kB_wrtn/s kB_dscd/s kB_read kB_wrtn kB_dscd
dm-0 3.19 72.63 35.90 0.00 202007 99835 0
dm-1 0.04 0.84 0.00 0.00 2348 0 0
nvme0n1 3.36 93.22 36.64 0.00 259264 101903 0
sr0 0.02 0.75 0.00 0.00 2096 0 0
首先第一行:
Linux 5.14.0-284.11.1.el9_2.x86_64 (localhost.localdomain) 08/07/2023 _x86_64_ (4 CPU)
Linux 5.14.0-284.11.1.el9_2.x86_64是內核的版本號,localhost.localdomain則是主機的名字, 08/07/2023當前的日期, _x86_64_是CPU的架構, (4 CPU)顯示了當前系統的CPU的數量。
接著看第二部分,這部分是CPU的相關信息,其實和top命令的輸出是類似的。
avg-cpu: %user %nice %system %iowait %steal %idle0.31 0.01 0.44 0.02 0.00 99.22
cpu屬性值說明:
- %user:CPU處在用戶模式下的時間百分比。
- %nice:CPU處在帶NICE值的用戶模式下的時間百分比。
- %system:CPU處在系統模式下的時間百分比。
- %iowait:CPU等待輸入輸出完成時間的百分比。
- %steal:管理程序維護另一個虛擬處理器時,虛擬CPU的無意識等待時間百分比。
- %idle:CPU空閑時間百分比。
這里對iowait這個指標進行講解,這個指標很容易被誤解。
首先要有這樣一個概念,%iowait是%idle的一個子集,其計算方法是這樣的:
如果 CPU 此時處于 idle 狀態,內核會做以下檢查
- 1、是否存在從該 CPU 發起的一個未完成的本地磁盤IO請求
- 2、是否存在從該 CPU 發起的網絡磁盤掛載的操作
如果存在以上任一情況,則 iowait 的計數器加 1,如果都沒有,則 idle 的計數器加 1。
例如假如間隔時間是 1s,則共有 100 個時鐘,假如 sys 計數為 2, user 計數為 3,ncie計數為0,iowait 計數為 1 ,steal計數為0, idle 計數為 94,則 它們的百分比依次為:2%、 %3、 0%、 1%、0%、94%。
知道了iowait的計算方法后,下面講解一下iowait常見的一些誤解:
-
iowait 表示等待IO完成,在此期間 CPU 不能接受其他任務
從上面 iowait 的定義可以知道,iowait 表示 CPU 處于空閑狀態并且有未完成的磁盤 IO 請求,也就是說,iowait 的首要條件就是 CPU 空閑,既然空閑就能接受任務,只是當前沒有可運行的任務,才會處于空閑狀態的,為什么沒有可運行的任務呢? 有可能是正在等待一些事件,比如:磁盤IO、鍵盤輸入或者等待網絡的數據等 -
iowait 高表示 IO 存在瓶頸
由于 Linux 文檔對 iowait 的說明不多,這點很容易產生誤解,iowait 第一個條件是 CPU 空閑,也即所有的進程都在休眠,第二個條件是 有未完成的 IO 請求。這兩個條件放到一起很容易產生下面的理解:進程休眠的原因是為了等待 IO 請求完成,而 %iowait 變高說明進程因等待IO 而休眠的時間變長了,或者因等待IO而休眠的進程數量變多了 初一聽,似乎很有道理,但實際是不對的。
iowait 升高并不一定會導致等待IO進程的數量變多,也不一定會導致等待IO的時間變長,我們借助下面的圖來理解:

在這三張圖的變化中,IO沒有發生任何變化,僅僅是CPU的空閑時間發生了變化,iowait的值就發生了很大的變化,因此僅根據 %iowait 不能判斷出IO存在瓶頸。
下面回到iostat,看第三部分的輸出結果。
Device tps kB_read/s kB_wrtn/s kB_dscd/s kB_read kB_wrtn kB_dscd
dm-0 3.19 72.63 35.90 0.00 202007 99835 0
dm-1 0.04 0.84 0.00 0.00 2348 0 0
nvme0n1 3.36 93.22 36.64 0.00 259264 101903 0
sr0 0.02 0.75 0.00 0.00 2096 0 0
其每一列的含義如下所示:
- Device:/dev 目錄下的磁盤(或分區)名稱
- tps:該設備每秒的傳輸次數。一次傳輸即一次 I/O 請求,多個邏輯請求可能會被合并為一次 I/O 請求。一次傳輸請求的大小是未知的
- kB_read/s:每秒從磁盤讀取數據大小,單位KB/s
- kB_wrtn/s:每秒寫入磁盤的數據的大小,單位KB/s
- kB_dscd/s: 每秒磁盤的丟塊數,單數KB/s
- kB_read:從磁盤讀出的數據總數,單位KB
- kB_wrtn:寫入磁盤的的數據總數,單位KB
- kB_dscd: 磁盤總的丟塊數量
需要注意的是,如果使用iostat -dk 2這樣的命令,每2s收集一次數據,則kB_wrtn的含義是2s內寫入磁盤的數據總數,而kB_read的含義是2s內從磁盤讀出的數據總數,kB_dscd的含義則是2s內磁盤塊的丟塊數量。
如果沒有時間間隔參數,例如iostat -dk,則kB_wrtn的含義是從開機以來的寫入磁盤的數據總量,kB_read的含義是從開機以來的從磁盤讀出的數據總數,kB_dscd的含義則是開機以來的磁盤塊的丟塊數量。
除此以外,iostat 可以使用-x輸出一些擴展列,例如下面的輸出:
Device r/s rkB/s rrqm/s %rrqm r_await rareq-sz w/s wkB/s wrqm/s %wrqm w_await wareq-sz d/s dkB/s drqm/s %drqm d_await dareq-sz f/s f_await aqu-sz %util
dm-0 2.16 47.69 0.00 0.00 0.56 22.06 0.88 25.70 0.00 0.00 2.66 29.16 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.25
dm-1 0.02 0.49 0.00 0.00 0.30 23.72 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
nvme0n1 2.28 59.76 0.01 0.38 0.54 26.18 0.74 26.13 0.15 17.11 1.89 35.12 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.26
sr0 0.01 0.44 0.00 0.00 0.56 38.81 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
讀指標:
- r/s:每秒向磁盤發起的讀操作數
- rkB/s:每秒讀K字節數
- rrqm/s:每秒這個設備相關的讀取請求有多少被Merge了(當系統調用需要讀取數據的時候,VFS將請求發到各個FS,如果FS發現不同的讀取請求讀取的是相同Block的數據,FS會將這個請求合并Merge);
- %rrqm: 合并讀請求占的百分比
- r_await:每個讀操作平均所需的時間;不僅包括硬盤設備讀操作的時間,還包括了在kernel隊列中等待的時間
- rareq-sz:平均讀請求大小
寫指標:
- w/s:每秒向磁盤發起的寫操作數
- wkB/s:每秒寫K字節數
- wrqm/s:每秒這個設備相關的寫入請求有多少被Merge了。
- %wrqm:合并寫請求占的百分比
- w_await:每個寫操作平均所需的時間;不僅包括硬盤設備寫操作的時間,還包括了在kernel隊列中等待的時間
- wareq-sz:平均寫請求大小
拋棄指標:
- d/s:每秒設備完成的拋棄請求數(合并后)。
- dkB/s:從設備中每秒拋棄的kB數量
- drqm/s: 每秒排隊到設備中的合并拋棄請求的數量
- %drqm:拋棄請求在發送到設備之前已合并在一起的百分比。
- d_await: 發出要服務的設備的拋棄請求的平均時間(以毫秒為單位)。 這包括隊列中的請求所花費的時間以及為請求服務所花費的時間。
- dareq-sz: 發出給設備的拋棄請求的平均大小(以千字節為單位)。
其他指標:
- aqu-sz:平均請求隊列長度
- %util: 一秒中有百分之多少的時間用于 I/O 操作,即被io消耗的cpu百分比,向設備發出I/O請求的經過時間百分比(設備的帶寬利用率)。當串行服務請求的設備的該值接近100%時,將發生設備飽和。 但是對于并行處理請求的設備(例如RAID陣列和現代SSD),此數字并不反映其性能限制。這個指標高說明IO基本上就到瓶頸了,但是低也不一定IO就不是瓶頸。一般%util大于70%,I/O壓力就比較大. 同時可以結合vmstat查看查看b參數(等待資源的進程數)和wa參數(I/O等待所占用的CPU時間的百分比,高過30%時I/O壓力高)
實際測試案列
在測試時,使用dd命令來模擬磁盤的讀寫
dd if=/dev/zero of=./a.dat bs=8k count=1M oflag=direct
- if=文件名:輸入文件名,默認為標準輸入。即指定源文件。
- of=文件名:輸出文件名,默認為標準輸出。即指定目的文件。
- bs=bytes:同時設置讀入/輸出的塊大小為bytes個字節。
- count=blocks:僅拷貝blocks個塊,塊大小等于ibs指定的字節數。
上述命令將向a.dat文件中寫入8G的數據。
打開另一個窗口,使用iostat進行監控。
首先看看iostat -kx 1的數據。
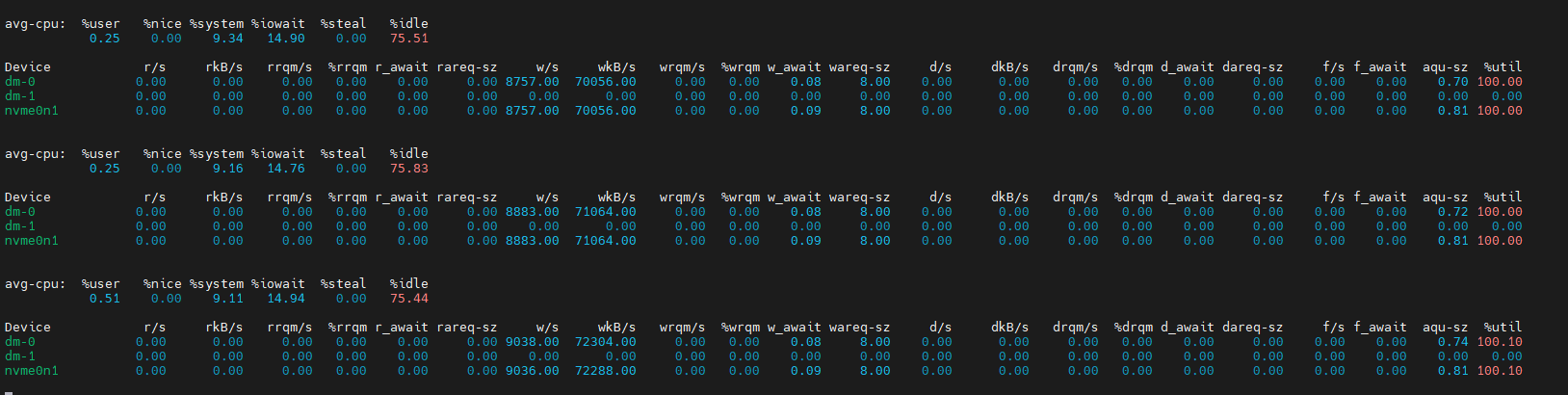
從wkB指標得知,現在磁盤的寫入速度在70M左右。從%util指標得知,目前磁盤的使用率已經高達100%,滿負荷運行。此時iowait的值為15%左右。
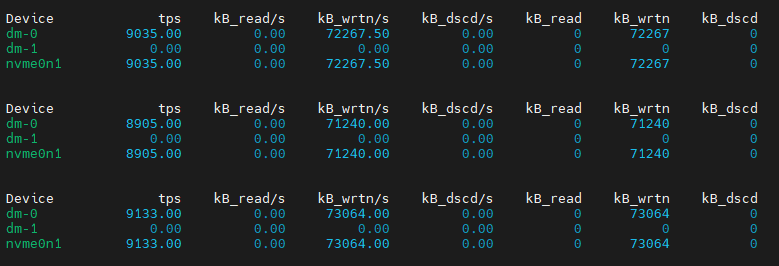
再看看iostat -dk 1的輸出:
從kB_read/s指標得知,目前磁盤的寫入速度在70M左右。
參考文章
https://blog.csdn.net/qq_35965090/article/details/116503427
https://www.modb.pro/db/46145
https://cloud.tencent.com/developer/article/1843341(iowait的解析)
https://www.cnblogs.com/sparkdev/p/10354947.html(stress命令)



加入永磁同步電機發電控制仿真模型研究(Matlab代碼實現))







枚舉 JAVA)







