本篇文章主要是對深度學習中運用多GPU進行訓練的一些基本的知識點進行的一個梳理
文章中的內容都是經過認真地分析,并且盡量做到有所考證
拋磚引玉,希望可以給大家有更多的啟發,并能有所收獲
介紹
大多數時候,梯度下降算法的訓練需要較大的Batch Size才能獲得良好性能。而當我們選擇比較大型的網絡時候,由于GPU資源有限,我們往往要減少樣本數據的Batch Size。
當GPU無法存儲足夠的訓練樣本時,我們該如何在更大的batch size上進行訓練?
面對這個問題,事實上我們有幾種工具、技巧可以選擇,它們也是下文中將介紹的內容。
在這篇文章中,我們將探討:
- 多GPU訓練和單GPU訓練有什么區別
- 如何最充分地使用多GPU機器
- 如何進行多機多卡訓練?
更多關于多機多卡的分布式訓練的詳細架構理解和實踐請參考我的下一篇文章:
Zhang Bin:深度學習分布式訓練相關介紹 - Part 2 詳解分布式訓練架構PS-Worker與Horovod?zhuanlan.zhihu.com
本文章介紹的內容在框架間是通用的,代碼示例為:在不借助外部框架的情況下,將單GPU訓練TensorFlow代碼改為支持多GPU的訓練代碼
單GPU訓練 vs 多GPU訓練
單GPU訓練 一般代碼比較簡單,并且能滿足我們的基本需求,通常做法是設定變量CUDA_VISIBLE_DEVICES的值為某一塊GPU來Mask我們機器上的GPU設備,雖然有時當我們忘了設定該變量時程序會自動占用所有的GPU資源,但如果沒有相應的代碼去分配掌控GPU資源的使用的話,程序還是只會利用到第一張卡的計算資源,其他的資源則僅是占用浪費狀態。
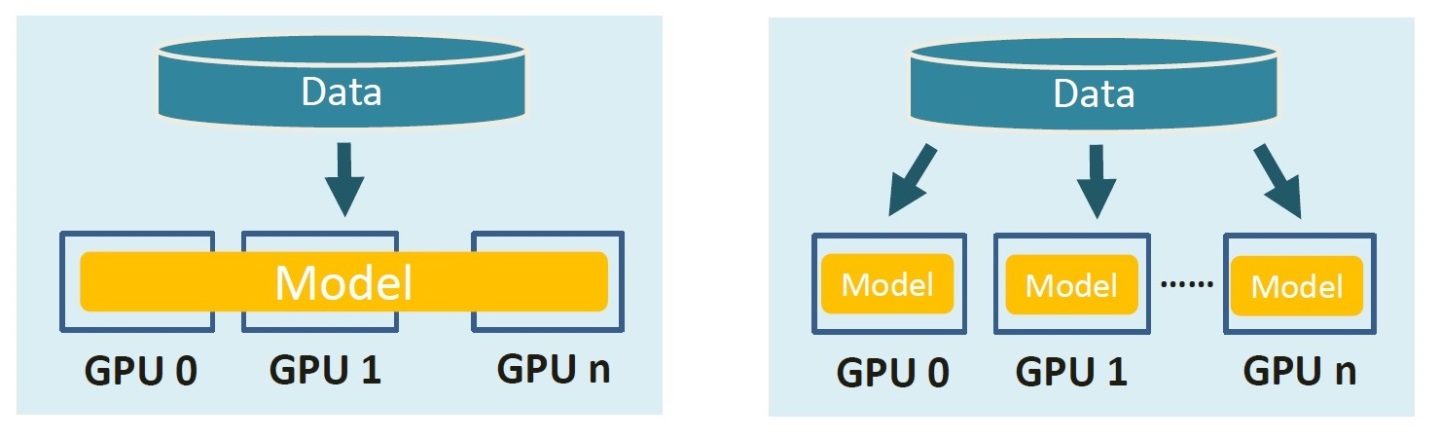
多GPU訓練 則可以從兩個方面提升我們模型訓練的上限:1. 超過單卡顯存上限的模型大小, 2. 更大的Batch Size和更快訓練速度。相應的,目前各大主流框架的多GPU訓練一般存在兩種模式:
- 模型并行 :分布式系統中的不同GPU負責網絡模型的不同部分,進而可以 構建超過單卡顯存容量大小的模型 。比如,可以將神經網絡的不同層分配到不同的GPU設備,或者將不同的參數變量分配到不同的GPU設備。
- 數據并行 :不同的 GPU設備有同一模型的多個副本,將數據分片并分配到每個GPU上,然后將所有GPU的計算結果按照某種方式合并,進而可以增加訓練數據的Batch Size。
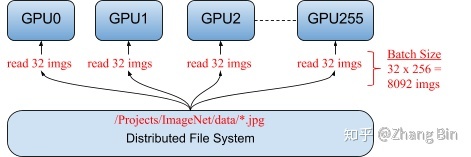
此外,從主機的數量的角度來講還存在 單機多卡和多機多卡(分布式)的區別:
- 單機多卡:只需運行一份代碼,由該代碼分配該臺機器上GPU資源的使用
- 多機多卡:每臺機器上都需要運行一份代碼,機器之間需要互相通信傳遞梯度,并且模型參數的更新也存在同步訓練模式和異步訓練模式的區別
多GPU機器的充分利用
這一節,將詳細探討一下多GPU的機器該如何利用。
對于多GPU訓練,一般我們需要用數據并行的模式比較多,通過增大 Batch Size 并輔以較高的 Learning Rate 可以加快模型的收斂速度。
由于我們模型是通過若干步梯度反向傳播來迭代收斂模型的參數,而每一步的梯度由一個Batch內樣本數據的損失情況(Loss)得到,因此當 Batch Size 比較大時, 可以減少 Batch樣本的分布和整體樣本的分布偏差太大的風險,進而使得每一步的梯度更新方向更加準確。
比如,單卡訓練 InceptionResNet 網絡最大Batch Size為100, 學習率為0.001。采用4張卡去訓練時,可以設置Batch Size為400, 學習率為 0.002。在代碼中對每一個Batch 400 切分成 4*100,然后給到不同GPU卡上的模型上去訓練。
下面主要介紹一下單機多卡訓練的細節及部分Tensorflow代碼:
- 數據切片
- 模型構建
- 梯度反傳
1. 數據分片
對于多GPU訓練,我們首先要做的就是對訓練數據進行分片,對于單機多卡模型,其數據的分片可以在代碼的內部進行, 而對于多機多卡模型,多機之間沒有必要進行數據切分方面的通信,建議的做法是先在本地做好數據的分配,然后再由不同的機器讀取不同的數據。
Tensorflow 單機多卡的數據切片代碼如下,其中 training_iterator 為采用tf.data.Dataset 構建的訓練數據pipeline, num_tower 為當前機器上可見的(CUDA_VISIBLE_DEVICES)GPU數量。
tower 指模型的副本。
mnist_input, mnist_label = training_iterator.get_next()
tower_inputs = tf.split(mnist_input, num_towers)
tower_labels = tf.split(mnist_label, num_towers)通過 tf.split 函數,將輸入的數據按照GPU的數量平分。
2. 構建模型
有了分好的數據,下一步驟則是需要將模型放置在我們所有的GPU上,并將切片好的數據傳入。
Tensorflow可以指定將不同的任務分配到不同的設備上, GPU支持大量并行計算, 因此可以將模型的運算、梯度的計算分配到GPU上來,而變量的存儲、梯度的更新則可以由CPU來執行,如下圖所示
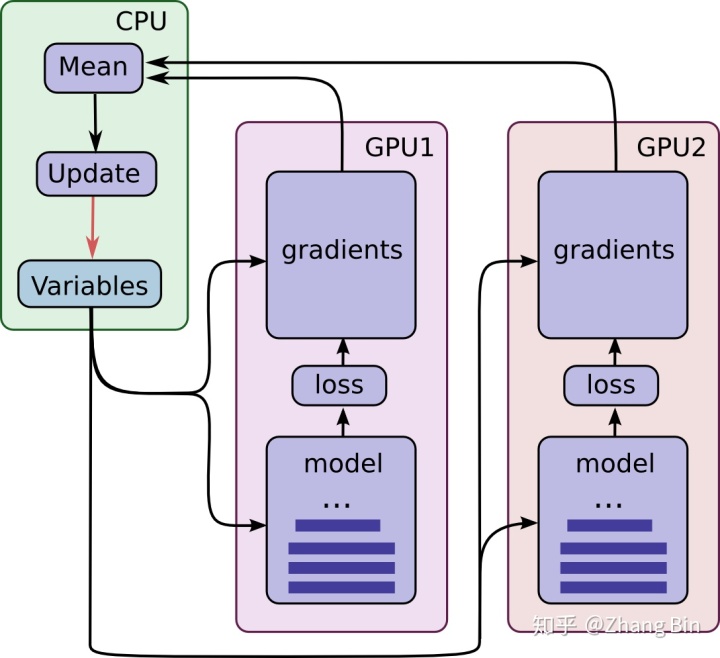
下面我們來看一下TensorFlow的相關代碼
最外層的 for i in range(num_towers): 使我們需要構建模型 num_towers次。
下一層的 with tf.device(device_string % i): 代表著每次我們構建模型時,模型放置的設備名稱, 如果為GPU機器device_string = '/gpu:%d' ,如果為CPU機器 device_string = '/cpu:%d'
再下一層 with (tf.variable_scope(("tower"), reuse=True if i > 0 else None)): 通過 scope 的reuse 使得我們再后續放置模型的時候,不同GPU之間的模型參數共享。
最后一層 with (slim.arg_scope([slim.model_variable, slim.variable], device="/cpu:0" if num_gpus != 1 else "/gpu:0")): 使得我們將構建模型中的變量放到CPU上來, 而運算則仍保留在該GPU上。
tower_gradients = []
tower_predictions = []
tower_label_losses = []
optimizer = tf.train.AdamOptimizer(learning_rate=1E-3)for i in range(num_towers):with tf.device(device_string % i):with (tf.variable_scope(("tower"), reuse=True if i > 0 else None)):with (slim.arg_scope([slim.model_variable, slim.variable],device="/cpu:0" if num_gpus != 1 else "/gpu:0")):x = tf.placeholder_with_default(tower_inputs[i], [None, 224,224,3], name="input")y_ = tf.placeholder_with_default(tower_labels[i], [None, 1001], name="label")# logits = tf.layers.dense(x, 10)logits = build_model(x)predictions = tf.nn.softmax(logits, name="predictions")loss = tf.losses.softmax_cross_entropy(onehot_labels=y_, logits=logits)grads = optimizer.compute_gradients(loss)tower_gradients.append(grads)tower_predictions.append(predictions)tower_label_losses.append(loss)3. 梯度反傳
上一步已經得到了各個tower上的梯度,下面則需要將這些梯度結合起來并進行反向傳播以更新模型的參數。
梯度結合的代碼可以參考下面的函數
def combine_gradients(tower_grads):"""Calculate the combined gradient for each shared variable across all towers.Note that this function provides a synchronization point across all towers.Args:tower_grads: List of lists of (gradient, variable) tuples. The outer listis over individual gradients. The inner list is over the gradientcalculation for each tower.Returns:List of pairs of (gradient, variable) where the gradient has been summedacross all towers."""filtered_grads = [[x for x in grad_list if x[0] is not None] for grad_list in tower_grads]final_grads = []for i in range(len(filtered_grads[0])):grads = [filtered_grads[t][i] for t in range(len(filtered_grads))]grad = tf.stack([x[0] for x in grads], 0)grad = tf.reduce_sum(grad, 0)final_grads.append((grad, filtered_grads[0][i][1],))return final_grads通過 combine_gradients 來計算合并梯度,再通過 optimizer.apply_gradients 對得到的梯度進行反向傳播
merged_gradients = combine_gradients(tower_gradients)
train_op = optimizer.apply_gradients(merged_gradients, global_step=global_step)最后再通過 sess.run(train_op) 對執行。
多機多卡 分布式訓練
多機多卡相比較于單機多卡,其使得模型訓練的上限進一步突破。一般我們一臺服務器只支持8張GPU卡,而采用分布式的多機多卡訓練方式,可以將幾十甚至幾百臺服務器調度起來一起訓練一個模型。
但相比于單機多卡,多機多卡分布式訓練方式的配置更復雜一些,不僅要保證多臺機器之間是可以互相通信的,還需要配置不同機器之間的角色以及不同機器之間梯度傳遞。
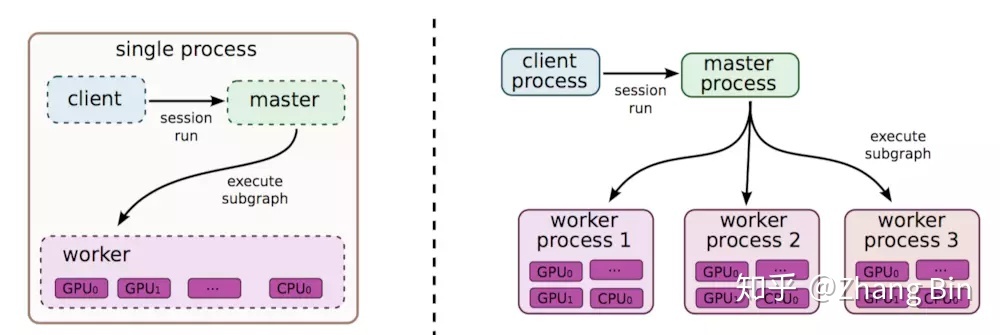
- TensorFlow 原生 PS架構
在Parameter server架構(PS架構)中,集群中的節點被分為兩類:parameter server和worker。其中parameter server存放模型的參數,而worker負責計算參數的梯度。在每個迭代過程,worker從parameter sever中獲得參數,然后將計算的梯度返回給parameter server,parameter server聚合從worker傳回的梯度,然后更新參數,并將新的參數廣播給worker。 - Uber 開發的Horovod架構 - 支持 TensorFlow, Keras, PyTorch, and Apache MXNet
Horovod 是一套面向 TensorFlow 的分布式訓練框架,由 Uber 構建并開源,目前已經運行于 Uber 的 Michelangelo 機器學習即服務平臺上。Horovod 能夠簡化并加速分布式深度學習項目的啟動與運行。
Horovod架構采用全新的梯度同步和權值同步算法,叫做 ring-allreduce。此種算法各個節點之間只與相鄰的兩個節點通信,并不需要參數服務器。因此,所有節點都參與計算也參與存儲。
關于分布式訓練的更多介紹,請參考我的下一篇文章
Zhang Bin:深度學習分布式訓練相關介紹 - Part 2 詳解分布式訓練架構PS-Worker與Horovod?zhuanlan.zhihu.com相關參考鏈接
TensorFlow - Multi GPU Computation
分布式tensorflow(一)
TensorFlow分布式全套(原理,部署,實例)
distributeTensorflowExample





—— hstack/column_stack,linalg.eig/linalg.eigh)













)