英偉達最近發布了一個新的GPUDirect Storage,暫且叫做GPU直連存儲,讓GPU直接連到NVMe存儲設備上。這一方案用到了RDMA設備來把數據從閃存存儲轉移到GPU本地的內存里,無需經過CPU還有系統內存。
如果這一舉措順利的話,英偉達就能擺脫對于CPU的依賴開辟一片全新的領地,全新的市場,比如數據科學和機器學習市場,這一市場將造就每年200億到250億美金的服務器市場,跟HPC和深度學習市場加起來的市場規模差不多一樣大。
英偉達在拼命的把要做的事情往GPU里放,去年十月份,英偉達發布了RAPIDS,這是一個開源的工具庫,用于幫助人們用GPU做分析和機器學習。RAPIDS可以對Apache Arrow, Spark等數據科學類的工具提供GPU加速,將GPU放入大數據企業應用的生態,這一領域現如今仍舊是以基于CPU的Hadoopp和Mapreduce這種方案。
RAPIDS涵蓋了機器學習的所有方面,包括監督式和無監督式的機器學習,還有各種數據處理方面的內容,但是,這一做法也遭到了一些懷疑。
GPU現在越做越大,連接性也越來越好,從應用的角度來看,GPU的通用也很好。與此同時,數據分析越來越負載,機器學習經常會集成到工作流程中,這樣一來,對TB級數據進行千萬億次計算的應用程序也會越來越多。
想做好這點必須有很好的可擴展性,通過NVLink和NVSwitch等技術可以連接多個GPU,組成一個巨大的加速器,該技術最初是為DGX架構設計的,這一架構主要也是為了解決規模更大,更復雜的神經網絡訓練問題。英偉達想把GPU的計算能力用于大數據的想法是說的通的,但唯獨就是缺少快速的數據存儲路徑。
通常,在GPU加速系統當中,所有的IO操作都會先經過主機端,也就是需要經過CPU指令把數據傳到主機內存里,然后才會到達GPU,CPU通常會通過“bounce buffer”來實現數據傳輸,“bounce buffer”是系統內存中的一塊區域,數據在傳輸到GPU之前會在這里保存一個副本。很明顯,這種中轉會引額外延遲和內存消耗,降低運行在GPU上的應用程序的性能,還會占用CPU資源,這就是GPUDirect Storage要解決的問題。
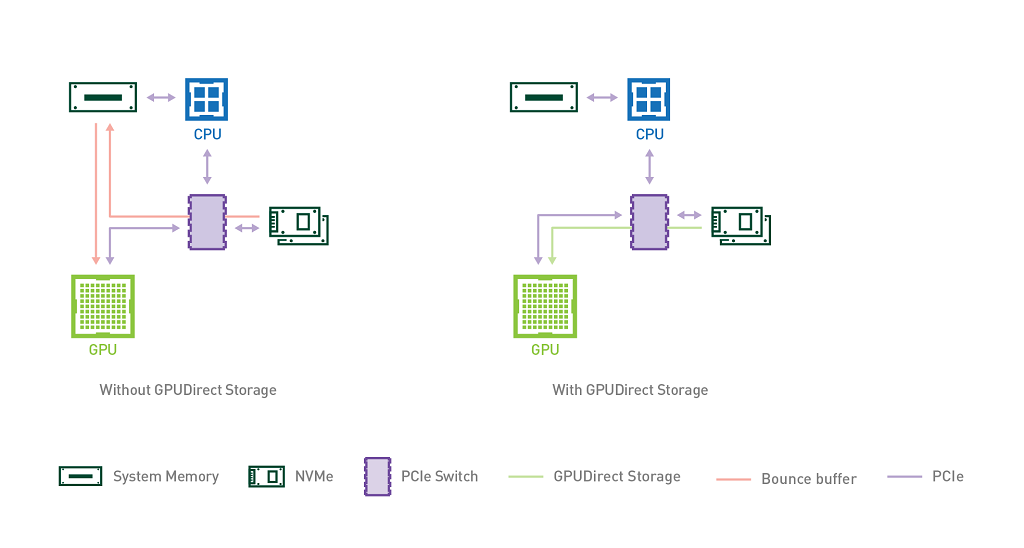
英偉達方面表示這一技術能提升50%的IO帶寬,延遲能降低3.8倍。如果通過NVMeoF技術的話,GPU就能連上PB級別的存儲資源池,更厲害的是,英偉達聲稱數據存取的效率比內存的頁面緩存速度還要快。
英偉達表示,如果你的DGX-2系統里有16個GPU,主機端有1.5TB內存的話,GPUDirect Storage的吞吐帶寬能提升8倍(跟原來不支持GPUDirect Storage的DGX-2系統相比)。這是因為,DGX-2的吞吐帶寬能達到大約200GB/s,而原來依靠主機端內存的話,最多也就50GB/s。
多出來的這150GB/s傳輸速度對于數據分析型工作負載的提升將非常可觀,對于像深度學習這種文件密集型應用程序,對于傳統的HPC也將會帶來很大改觀。
英偉達的這一做法讓GPU直連到存儲,直接拿到原始數據,意味著GPU也可以對文件進行解壓縮和解碼操作,解放CPU。目前,GPUDirect Storage支持各種常見的文件格式進行操作。
GPUDirect Storage方案用到了兩項高端技術,一個是RDMA,一個是NVMe(NVMe-oF),其中,RDMA被封裝在GPUDirect的協議中,依靠各種網絡適配器工作(比如Mellanox的NIC),既可以訪問遠程的存儲也可以訪問本地的存儲設備。
目前,GPUDirect Storage只面向少數合作伙伴提供,預計今年十月份將推出beta版本。
在譯者看來,這是英偉達跟英特爾競爭的又一大舉措,可以看做是對英特爾再度進軍GPU市場的一個回應。
繞開CPU,開辟一片新的生態,這在理論上是可行的,也確實有明顯的需求場景,最后能否在市場上推行開來,還得看方案構建的水平,包括方案的易用性,穩定性,場景的優化水平,當然,最重要的還是不要對現有軟件架構帶來太多變化,控制用戶的使用成本和購置成本。


—— hstack/column_stack,linalg.eig/linalg.eigh)













)


